-
java实现边查边导出功能
java实现边查边导出功能
功能背景
边查边导(简单明了,也不知道该叫什么名),顾名思义,就是需要浏览器与后台实现发送请求后,该请求会马上返回下载提示框,下载得文件内容在持续写入,直至最后得数据写入完毕,前台生成最终得文件。
目前系统现状比较多得就是请求发送后,回到数据库进行查询,数据量过于大得情况下,会使用多线程,但是最终得效果都是需要等待所有得数据查询完毕,才会生成最终得文件,然后使用poi或者easyexcel 进行生成表格,将文件返回给前端。查数据期间,前端会无限期得等待,直至有文件流返回。这样就容易造成前端得假死现象,以为没反应,会多次点击,造成不必要得后台和数据库压力。边查边导,个人感觉就是对这个问题的最好解决。
功能实现历程
其实最早的想法是增加一个注解,每次页面的请求会返回页面显示的几十条的分页数据,注解的作用就是将该请求条件作用到导出接口上,将所有的数据查询,然后请求条件作为key,所有的数据作为value,放置缓存里。当点导出的时候,先去查缓存数据,缓存如果还没弄好,就正常的导出,需要等个几分钟,如果缓存已经有key了,那直接把数据拿出来导出即可。想法美好,但是实际运用起来,还是有些问题的,试了千百遍也不是很理想,所以就萌生了边查边导的想法。
边查边导,想法是很简单,无非就是数据不是等全返回来,反回多少,就往里写入多少。但是事实确实是能写入,但是写入第一页的就断了,虽然后台还在跑,但是返回的文件流已经返回了。搜了好多文章也没搜到有用的东西。因为之前关注过一篇文章,是持续输出文本的
https://blog.csdn.net/nature_fly088/article/details/54633168?locationNum=15&fps=1- 1
就想着应该和这个意思差不多,万万没想到啊,改成poi或者easyexcel ,是一步一个坑啊,搞了快一周了,也没有实质性的进展,要么文件挺大,打开就是文件损坏,要么就是0k的文件。各种更改,各种问题。
然后某一天,受到别人的一个点醒,说是
数据库导出的是csv格式的表格
这句话突然间就点醒了,我隐约记得在数据库导出数据时候,会提示导出csv json xml html sql等等格式,然后还有什么分隔符,转义之类的。这样把csv的输出和上边持续输出文本的相结合,好像应该感觉就可以了。以下才是本文的重中之重,高光之点。
持续输出文件流整合导出csv
想整合,首先必须的看懂代码,首先来看持续输出的
上边的博文代码,大致意思就是将要输出文本转为字节流,然后又转为了字节数组输入流,进入到readwrite里,将字节输入流转成不断读取到输出流里 ,这样不断的写入写出,就能实现前端提示下载后,文本会持续的写入文字。最后一个输出完,就完成了文件的传输。
持续输出的研究完,接着看导出csv的。
搜了下csv 的导出,大概就是csv格式的表格 ,其实是假的表格,

他就是一个文本,用其他的软件打开就是纯纯的文本,也没啥复杂的东西,无非就是需要注意分隔符,换行符之类的
https://blog.csdn.net/dj7858177/article/details/106786253/- 1
导出csv 的 可以参考这位博主的,写的也挺好,简单明了,一看就会那种,
前期的 准备工作就是研读这两篇博客,研读透了,整合就方便多了
然后就是这边的整合工作首先 还是开头的 api 这个不用多说就需要 HttpServletResponse 就可以了 入参自己看着加
然后请求最好是get 而且还得在拦截器过滤器里将此地址放过,保证能直接在浏览器打开就行@GetMapping(value = "/excel") Result excel(HttpServletResponse response);- 1
- 2
其次是设置返回流的信息 包括返回的格式,以及返回的文件名(中文的话需要另行增加utf8参数)
response.reset(); response.setContentType("application/octet-stream"); response.setContentType("Content-type:application/vnd.ms-excel;charset=UTF-8"); response.setHeader("Content-Disposition", "attachment;filename=\"" + filename + ".csv\"");- 1
- 2
- 3
- 4
返回流完毕后 开始定义一些输出的类
//循环输出 ServletOutputStream out = response.getOutputStream(); BufferedInputStream bis = null; BufferedOutputStream bos = null; //定义反参 Class<Response> clazz = Response.class; Field[] fieldsGet = clazz.getDeclaredFields(); //定义反参属性,以及输出的字符 StringBuilder budTitle = new StringBuilder(); List<String> propertyNameList = new ArrayList<>(); // 组装表头 for (Field field : fieldsGet) { String annotationValue = field.getAnnotation(ExcelPropertyName.class).value(); budTitle.append(annotationValue).append(CSV_COLUMN_SEPARATOR); String propertyName = field.getName(); propertyNameList.add(propertyName); } // 组装表头完毕换行 budTitle.append(CSV_ROW_SEPARATOR); // 优先输出表头 byte[] contentByteTitle = (budTitle.toString()).getBytes(); InputStream isTitle = new ByteArrayInputStream(contentByteTitle); readWrite(isTitle, out, bis, bos);- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
这里的反射 是为了提取反参的所有属性,用于后续的比对后放值
这里自定义了一个 注解 ,是为了自动获取该属性的中文说明

然后将所有反参的中文进行拼接,作为表的表头输出,最好不要用复杂的表头,暂时不支持
分隔符,换行符 都是用的博主的 没有进行更改
/** * CSV文件列分隔符 */ private static final String CSV_COLUMN_SEPARATOR = ","; /** * CSV文件行分隔符 */ private static final String CSV_ROW_SEPARATOR = "\r\n";- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
readWrite 也是上边博主的
public void readWrite(InputStream is, ServletOutputStream out, BufferedInputStream bis, BufferedOutputStream bos) { try { bis = new BufferedInputStream(is); bos = new BufferedOutputStream(out); byte[] buff = new byte[2048]; int bytesRead; // Simple read/write loop. while (-1 != (bytesRead = bis.read(buff, 0, buff.length))) { bos.write(buff, 0, bytesRead); } bos.flush(); } catch (final IOException e) { e.printStackTrace(); } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
到这里表头就算是完成了 然后就是表数据的组装
for (int i = 0; i < 10000000; i++) { StringBuilder bud = new StringBuilder(); //业务sql查数据 List<Response> searchHistoryVOS = new ArrayList<>(); Response res= new Response(); res.setSno(i); res.setSname("name---" + i); res.setAge(i); res.setAddress("address" + i); res.setPost("post" + i); res.setPhone("phone" + i); searchHistoryVOS.add(res); //业务sql查数据后遍历属性 组装返回的数据 if (CollectionUtils.isNotEmpty(searchHistoryVOS)) { for (Object obj : searchHistoryVOS) { Field[] fields = obj.getClass().getDeclaredFields(); for (String property : propertyNameList) { for (Field field : fields) { field.setAccessible(true); if (property.equalsIgnoreCase(field.getName())) { bud.append(field.get(obj).toString().replace(":", "-").replace("/", "-")); bud.append(CSV_COLUMN_SEPARATOR); continue; } } } bud.append(CSV_ROW_SEPARATOR); } } //输出组装好的数据 byte[] contentByte = (bud.toString()).getBytes(); InputStream is = new ByteArrayInputStream(contentByte); readWrite(is, out, bis, bos); }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
这里就是简单的循环,实际应用可能得改成查库就行
循环一个之后 将数据和之前反射得属性去做对比,一样得话 将数据放入对应得里边 并拼接 , 用于分列 ,当整个对象完成后,拼接换行符号,如此循环往复,
最后得str 同表头,进行byte转换,然后输出,输出后又紧接着开始下一次得数据写入,
这样循环,循环,再循环。直至最后得数据写完,整个文件也就完成了,
别忘了 关闭两个流//输出完毕关闭流 if (bis != null) { bis.close(); } if (bos != null) { bos.close(); }- 1
- 2
- 3
- 4
- 5
- 6
- 7
到这里就算是整合完毕了,
效果就是这样得 只是表头不支持个性得设置了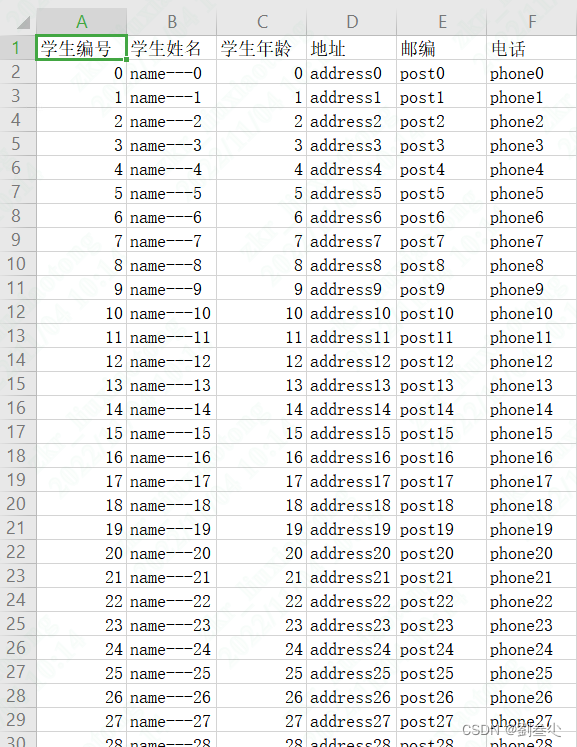
到此,边查边导就算是完成了,虽然不能和poi以及easyexcel一样设置不一样得表头信息,但是起码能实时返回了 ,不需要前端过多得等待时间。
总结
遇到问题,解决问题。其实好多问题都是有解决方式得,只是自己没有还没有研究到而已。多搜搜多看看,有点印象得方法都能用上,自己琢磨琢磨,修修改改,变通变通没准就成了问题得钥匙,因人而解了。后续还得看看怎么给csv增加sheet页,以及高级表头。
边查边导,到此结束,后续有有新得研究会持续更新。喜欢,有帮助得就点个赞,收藏一下吧。万一以后用到呢 毕竟码了5000个字,也是不容易啊。
-
相关阅读:
“传统技术”快速搭建AI产品的利器——LLM技术
手把手教你Nginx常用模块详解之ngx_http_rewrite_module(十)
java毕业设计财务管理系统的设计与实现Mybatis+系统+数据库+调试部署
2022年最新Android面试题整理,全网都在看,史上最全面试攻略
DBS note4:Buffer Management
出自阿里P8的Java面试神册,涵盖30个技术栈扛住面试官的狂轰乱炸
网页翻译软件-网页翻译软件排行榜
C++(Qt)软件调试---GCC编译参数学习-程序检测(13)
前端基础(Vue Router路由的使用)
About 8.7 This Week
- 原文地址:https://blog.csdn.net/qq_43021813/article/details/127681910