-
orderby是如何工作的?
1. 引言
假设我们现在有一个市民表定义如下:
create table t( id int(11) not null, city varchar(16) not null, name varchar(16) not null, age int(11) not null, addr varchar(128) default null, primary key(id), key city(city) )ENGINE=InnoDB;- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
假设我们现在要查询城市是“杭州”的所有人的名字,并且排名按照姓名排序,返回前1000个人的姓名、年龄。那我们会写出如下的SQL语句:
select city,name,age from t where city='杭州' order by name limit 1000;- 1
下面我们来分析下这条语句的执行流程。
2.全字段排序
为了避免全表扫描,所以我们在city字段加上了索引。索引的示意图如下:
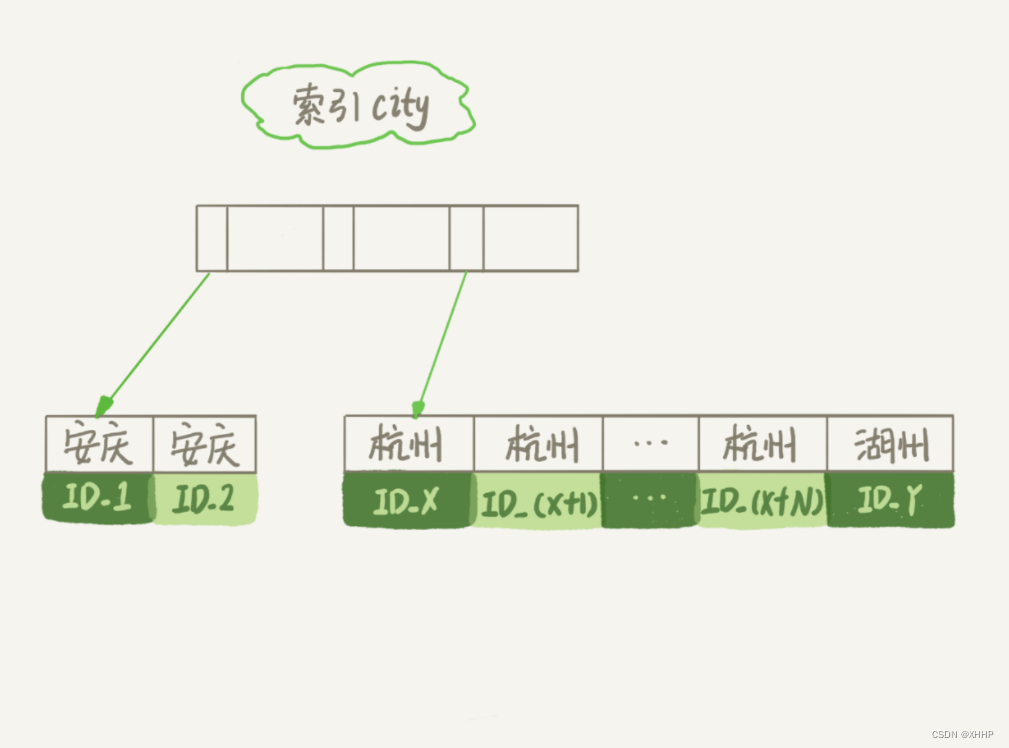
我们使用explain命令来看语句的执行情况:

我们在Extra字段里面看到Using filesort表示需要进行排序 ,MySQL会给每个线程分配一块内存用于排序,称为sort_buffer。
正常情况下,这个语句流程如下所示:
- 初始化sort_buffer,确定放入name,city,age三个字段
- 从索引city上找到第一个满足city="杭州"的叶子节点,然后回到主键id索引上取出name,city,age三个字段的值,存入sort_buffer中
- 不断重复上述过程,直到不满足查询条件为止
- 对sort_buffer中的数据按照字段name进行快速排序
- 取前1000行返回给客户端
这个排序过程,我们称为全字段排序。过程如下图:

对于字段的排序,可能在内存中直接完成,也可能使用外部排序,这取决于所需的内存和sort_buffer_size。sort_buffer_size是MySQL为排序开辟的内存。如果排序需要的内存小于sort_buffer_size,则直接在内存中排序。如果大于sort_buffer_size,则需要借助外部排序。
在这个算法里面,只对原表的数据读了一遍,剩下的操作都是在sort_buffer和磁盘文件中进行的。但是这个算法有个问题,如果这个查询要返回很多字段的话,那可能sort_buffer就放不下,就需要借用很多的磁盘文件进行外部排序。
3.rowid排序
那么,MySQL对于长度过长的行会如何进行处理?
我们可以通过设置max_length_for_sort_data来让MySQL换一个算法,如果长度超过max_length_for_sort_data就会换一个算法:SET max_length_for_sort_data = 16;- 1
新的算法中,只会将要排序的字段(name)和主键id放入sort_buffer中。流程会变成如下的样子:
- 初始化sort_buffer,确定放入name,id两个字段
- 从索引city上找到第一个满足city=“杭州”条件的主键id,到主键索引id上取出name和id两个字段,存入sort_buffer中;
- 不断重复上述过程,直到不满足查询条件为止
- 对sort_buffer中的数据按照字段name进行排序
- 遍历排序结果,取得前1000行,然后回到主键索引id中取出city、name和age三个字段返回给客户端
这种排序方式我们称为rowid排序,可以看到这种方式多访问了一遍主键索引id,但是可以减少排序所需要的内存。过程如下图所示:

4.全字段排序和rowid排序对比
MySQL的设计思想是:如果内存够,就要多利用内存,尽量减少磁盘访问。也就是如果MySQL实在担心内存太小,会影响到效率,才会使用rowid排序算法,因为全字段排序可以减少一次全表查询。
但是其实实际上也不是所有的order by语句都会进行排序操作的。MySQL之所以进行排序,是因为在city索引上,name是无序的。
那如果建立city和name的联合索引:
alter table t add index city_user(city , name);- 1

这就保证了在city相同的情况下,那么一定是有序的,就不需要进行排序了。查询流程就变成了下面的流程:
- 从索引(city , name)上找到第一个是city='杭州’的主键id,回到主键索引id上取出name,city,age字段,作为结果集的一部分
- 重复以上过程,直到不满足查询条件或到达1000条记录后直接返回结果集
流程如下图所示:
我们也可以通过explain语句来观察,发现using filesort没有了。

如果我们再结合之前覆盖索引的知识,建立(city,name,age)联合索引:
alter table t add index city_name_age(city,name,age)- 1
这样name字段是有序的,而且需要的字段也都有,都不需要回到主键索引中去查询。流程就变成了:
- 从(city , name,age)索引上找到第一个满足city=“杭州”的记录,并取出city,name,age添加到结果集中
- 重复以上过程,直到不满足查询条件或到达1000条记录后直接返回结果集
流程如下图所示:

来源:自己整理的MySQL实战45讲笔记
-
相关阅读:
[架构之路-58]:目标系统 - 平台软件 - 中间件软件(嵌入式)与中间件平台(中台)以及中间件的发展阶段与提供服务的方式
LeetCode 46. 全排列
LLVM系列第二十九章:写一个简单的常量加法“消除”工具(Pass)
WPF 控件专题 TreeView控件详解
Python对象序列化
山西电力市场日前价格预测【2023-10-13】
10-134 4-6 查询在具有最小内存容量的所有PC中具有最快处理器的PC制造商
带你着手「Servlet」
lodash源码
CentOS 7 下 SVN + Apache 对接 LDAP 服务
- 原文地址:https://blog.csdn.net/weixin_41799019/article/details/127676686