-
python读取Excel指定范围并转为数组
📚博客主页:knighthood2001
✨公众号:认知up吧 (目前正在带领大家一起提升认知,感兴趣可以来围观一下)
🎃知识星球:【认知up吧|成长|副业】介绍
❤️感谢大家点赞👍🏻收藏⭐评论✍🏻,您的三连就是我持续更新的动力❤️
🙏笔者水平有限,欢迎各位大佬指点,相互学习进步!
最近需要读取Excel中的内容,然后进行后续操作,对于这块知识,博主以前以为自己不会涉及到,但是现在一涉及到,第一步就错了,搞了好久。真的心累。因此写了这篇博客。
目的:excel中存放着数据,如果要进行计算及其它操作,首先就要进行读取。
目录
我们先来看一下python中能操作Excel的库对比(一共九个库):
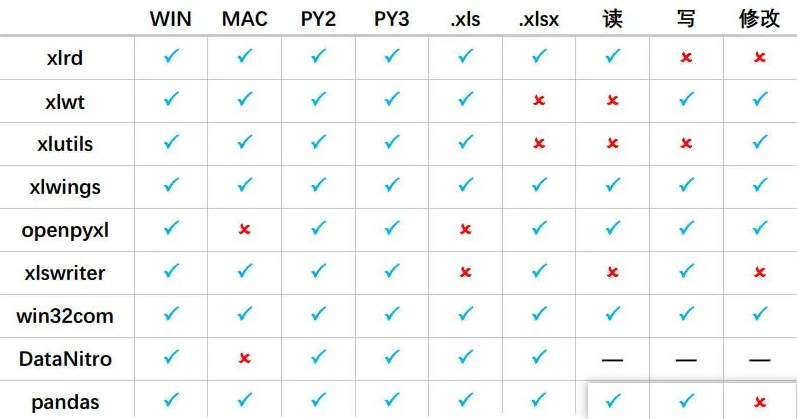
可以发现,还是挺多的
这里使用的是xlrd库。
安装
这里首先就是导入这个包,
pip install xlrd==1.2.0xlrd包版本最好是1.2.0,因为笔者使用2.多版本的xlrd时,代码出现了类似下面的报错,也就是说xlrd版本太高会导致无法支持读取xlsx后缀的excel。
xlrd.biffh.XLRDError: Excel xlsx file; not supported
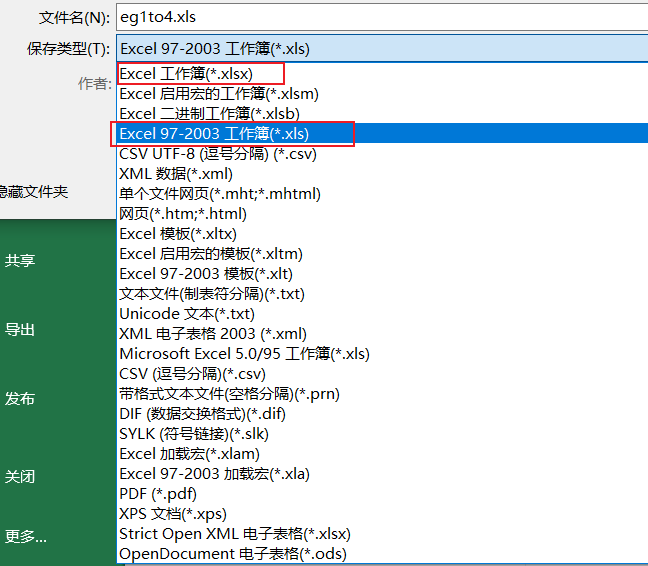
大家可以去试试将excel另存,看看保存类型。
目前笔者使用的是Excel2019版本的,默认保存类型为xlsx。
如果你之前已经安装xlrd高版本或更低版本了,建议先卸载一下,重新安装。
- pip uninstall xlrd
- pip install xlrd==1.2.0
实例
初阶

一个excel中有如上数据,我们需要将其提取出来,方便python进行后续操作。
代码如下:
- def extract1(file,index=0):
- workbook = xlrd.open_workbook(file)
- worksheet = workbook.sheet_by_index(index)
- rows = worksheet.nrows
- all = []
- for i in range(rows):
- a = worksheet.row_values(i)[:]
- all.append(a)
- print(all)
- cc = np.array(all)
- print(cc)
- return cc
file是文件的路径及名称,index就是当前sheet表的索引。 下图就是具体的索引。

当然也可以根据sheet表的名称。
如下面代码第一行按照的是索引方式,第二行按照的是sheet名称。大家可自行选择
- worksheet = workbook.sheet_by_index(0)
- worksheet = workbook.sheet_by_name("sheet1")
rows = worksheet.nrows返回的是sheet表的行数,ncols则是列数
- all = []
- for i in range(rows):
- a = worksheet.row_values(i)[:]
- all.append(a)
首先定义一个空列表,然后遍历每行,将里面的数据写入列表中,
row_values()是用来返回给定行中单元格值的切片。
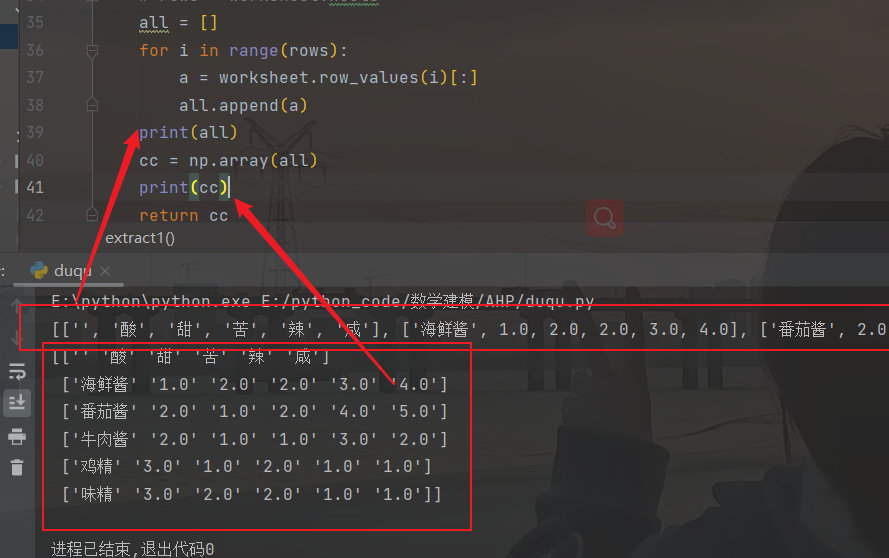
最后将其转换成数组类型即可。(按要求来,大家也可以不换)
下图是结果:
换个高级的写法,用推导式写(浓缩才是精华)
- def extract(file,index=0):
- workbook = xlrd.open_workbook(file)
- worksheet = workbook.sheet_by_index(index)
- rows = worksheet.nrows
- c = tuple(worksheet.row_values(i)[:] for i in range(rows))
- a = np.array(c)
- print(a)
- return a
代码行数瞬间缩短了。
最好调用一下函数即可
- file = r'C:\Users\knighthood\OneDrive\桌面\11.xlsx'
- extract1(file)
进阶1
要求:假如我excel只要图中框出来的区域。
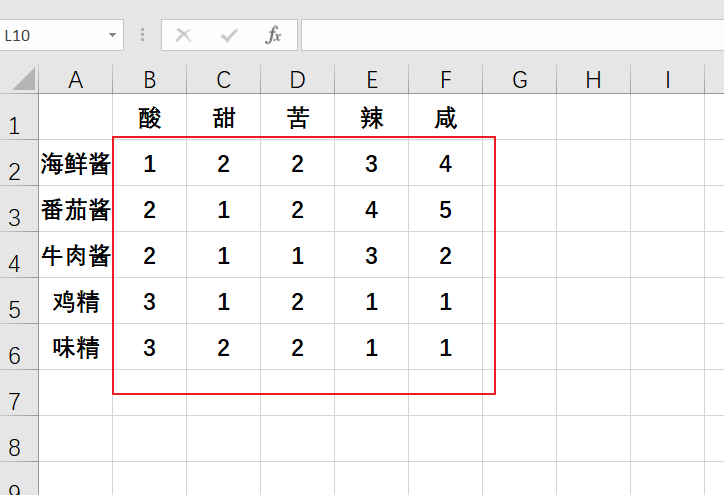
以下为了看的较为简便,我使用推导式的代码
- def confine_array(file,index=0):
- workbook = xlrd.open_workbook(file)
- worksheet = workbook.sheet_by_index(index)
- rows = worksheet.nrows
- c = tuple(worksheet.row_values(i)[1:] for i in range(1, rows))
- a = np.array(c)
- print(a)
- return a
如上,可以发现,代码变化之处就下面这一行。
c = tuple(worksheet.row_values(i)[1:] for i in range(1, rows))一步步讲解:
①for i in range(1, rows)
首先对于后面的for循环,i控制的就是获取的行,更改其范围就会更改获取到的行、行数。
如果是上面说的(1,rows),则对应着获取第二行到最后一行,(0表示第一行)
②worksheet.row_values(i)[1:]
最后的[1:](本来的代码中是没有或者是[:])表示的是i行的元素从第2列(个)获取到最后一行(个)。
因此我们只需要更改这两处就可以获得不同的内容矩阵(如下)。
- def flexible_array(file,index=0,row=1,col=1):
- workbook = xlrd.open_workbook(file)
- worksheet = workbook.sheet_by_index(index)
- rows = worksheet.nrows
- c = tuple(worksheet.row_values(i)[col:] for i in range(row,rows))
- a = np.array(c)
- print(a)
- return a
结果如下图

进阶2
要求:能不能更简化一点,根据我从哪个位置要数据,如第二行第二列开始,将这后面的数据进行读取。每次这样对来对去,容易出错,还是根据行列开始计算比较方便。
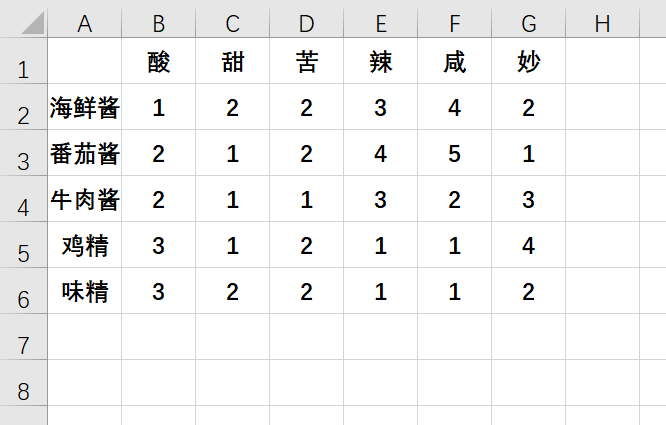
这里为了防止行列一样,我就多加了一列。
- def flexible1_array(file,index=0,row=1,col=1):
- workbook = xlrd.open_workbook(file)
- worksheet = workbook.sheet_by_index(index)
- rows = worksheet.nrows
- c = tuple(worksheet.row_values(i)[col-1:] for i in range(row-1,rows))
- a = np.array(c)
- print(a)
- return a
代码也主要变化了这一行
c = tuple(worksheet.row_values(i)[col-1:] for i in range(row-1,rows))这里笔者就不多解释了。
 现在就可以根据需要的起始单元格所在的行列进行选取所要的内容。
现在就可以根据需要的起始单元格所在的行列进行选取所要的内容。进阶3
要求:不需要最后一列

这里的话,笔者就设置了最后需要的行和列作为结束的读取。
- def flexible2_array(file,index=0,row=1,col=1,end_row=None,end_col=None):
- workbook = xlrd.open_workbook(file)
- worksheet = workbook.sheet_by_index(index)
- rows = worksheet.nrows
- if end_row is None:
- c = tuple(worksheet.row_values(i)[col-1:end_col] for i in range(row-1, rows))
- else:
- c = tuple(worksheet.row_values(i)[col - 1:end_col] for i in range(row - 1, end_row))
- a = np.array(c)
- print(a)
- return a
上述代码意思是,如果不输入结束的行和列,读取到的是包含数据的行列,如果输入了行和列(或者其中一个),就读取相应的内容。由于end_row放在range()函数中,因此需要加个if判断。
结果如下:

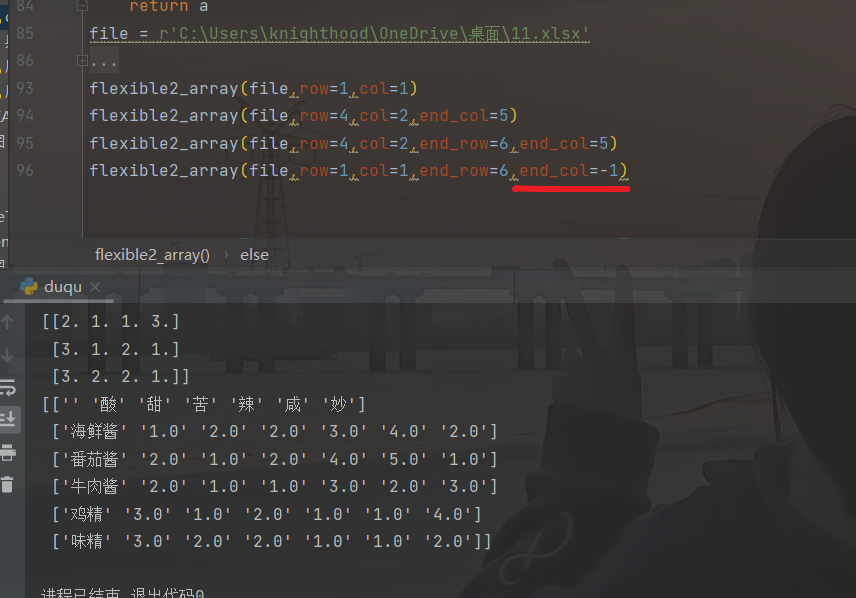
此外,我还发现,end_col由于放在[]中,可输入负数(不懂的可以去看看python列表负索引)。
不过这里的-1,其实际是排除了最后一列,从你输入的行列到,你输入的结束行和倒数第二列。
有些人可能会觉得别扭(比如我,更喜欢-1表示从起始列到最后一列,-2表示从起始列到倒数第二列)
- def flexible3_array(file,index=0,row=1,col=1,end_row=None,end_col=None):
- workbook = xlrd.open_workbook(file)
- worksheet = workbook.sheet_by_index(index)
- rows = worksheet.nrows
- if end_row is None:
- c = tuple(worksheet.row_values(i)[col-1:end_col if end_col > 0 else end_col+1] for i in range(row-1, rows))
- else:
- c = tuple(worksheet.row_values(i)[col-1:end_col if end_col > 0 else end_col+1] for i in range(row - 1, end_row))
- a = np.array(c)
- print(a)
- return a
这里,代码中将判断end_col是否为负,使用了if-else写在一行。减少了很多代码判断量,使看起来更简洁。

这里看个人喜好是否使用这个方法。
还有一个end_col参数使用负数的原因是,end_row由于在excel中对应的是行,其用的是数字表示,而excel中列用字母表示,因此如果当数据列数太多的时候(如下图),去数列还是挺麻烦的

总结
上述内容是一步一步进行修改添加的,对应着平时要求的逐渐添加,功能的逐渐完善。
笔者在上篇构建层次分析法,用到的数据矩阵,可以和这篇一起结合,通过excel读取转为数组,然后进行层次分析法的操作。
-
相关阅读:
什么是递归、迭代(类比解释)
《Java基础知识》Java ArrayList源码分析4
(附源码)springboot金融新闻信息服务系统 毕业设计651450
深入了解JUC并发(一)什么是JUC
ubuntu18.04服务器双网口配置上外网
Nacos源码系列—关于服务注册的那些事
VUE3学习小记(2)- ref 与 reactive
【2023年11月第四版教材】软考高项极限冲刺篇笔记(1)
MySQL的用户管理
FoneDog iOS Unlocker(ios解锁工具) 适用macos电脑
- 原文地址:https://blog.csdn.net/knighthood2001/article/details/127534635