-
大数据项目之电商数仓、Kafka安装(完整版)、Kafka命令行操作
文章目录
4. 用户行为数据采集模块
4.2 环境准备
4.2.4 Kafka安装
4.2.4.1 安装部署
4.2.4.1.1 集群规划
hadoop102 hadoop103 hadoop104 zk zk zk kafka kafka kafka 4.2.4.1.2 集群部署
4.2.4.1.2.1 官方下载地址
http://kafka.apache.org/downloads.html
4.2.4.1.2.2 解压安装包

[summer@hadoop102 software]$ tar -zxvf kafka_2.12-3.0.0.tgz -C /opt/module/- 1

4.2.4.1.2.3 修改解压后的文件名称
[summer@hadoop102 module]$ mv kafka_2.12-3.0.0/ kafka-3.0.0- 1

4.2.4.1.2.4 进入到/opt/module/kafka-3.0.0目录,修改配置文件
[summer@hadoop102 kafka-3.0.0]$ cd config/ [summer@hadoop102 config]$ vim server.properties- 1
- 2

输入以下内容:#broker的全局唯一编号,不能重复,只能是数字。 broker.id=0 #处理网络请求的线程数量 num.network.threads=3 #用来处理磁盘IO的线程数量 num.io.threads=8 #发送套接字的缓冲区大小 socket.send.buffer.bytes=102400 #接收套接字的缓冲区大小 socket.receive.buffer.bytes=102400 #请求套接字的缓冲区大小 socket.request.max.bytes=104857600 #kafka运行日志(数据)存放的路径,路径不需要提前创建,kafka自动帮你创建,可以配置多个磁盘路径,路径与路径之间可以用","分隔 log.dirs=/opt/module/kafka/datas #topic在当前broker上的分区个数 num.partitions=1 #用来恢复和清理data下数据的线程数量 num.recovery.threads.per.data.dir=1 # 每个topic创建时的副本数,默认时1个副本 offsets.topic.replication.factor=1 #segment文件保留的最长时间,超时将被删除 log.retention.hours=168 #每个segment文件的大小,默认最大1G log.segment.bytes=1073741824 # 检查过期数据的时间,默认5分钟检查一次是否数据过期 log.retention.check.interval.ms=300000 #配置连接Zookeeper集群地址(在zk根目录下创建/kafka,方便管理) zookeeper.connect=hadoop102:2181,hadoop103:2181,hadoop104:2181/kafka- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
这里面的参数只需要改我下面截图框住的参数
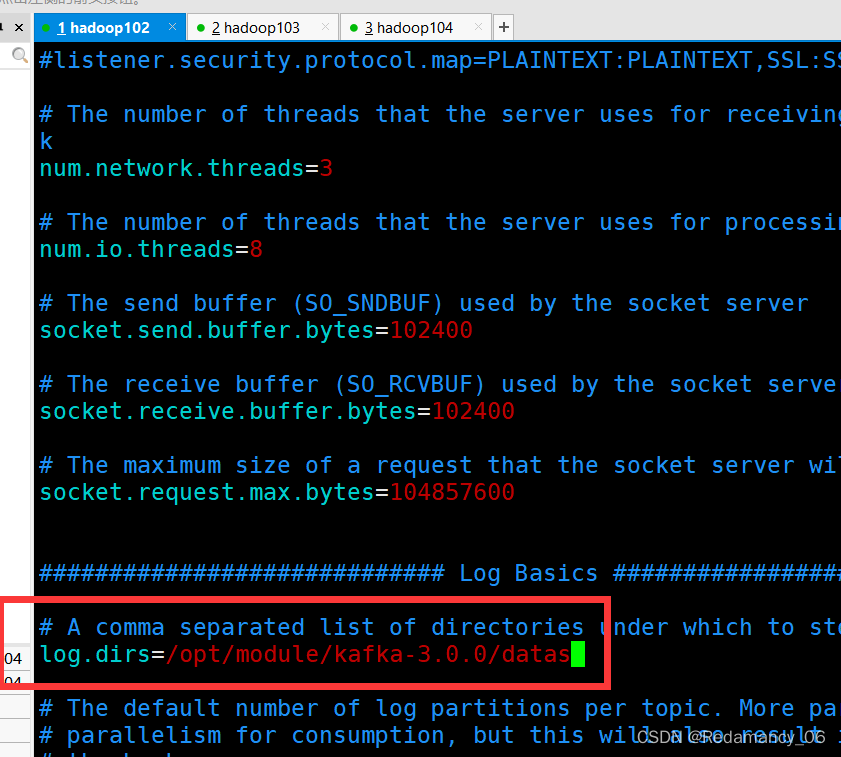
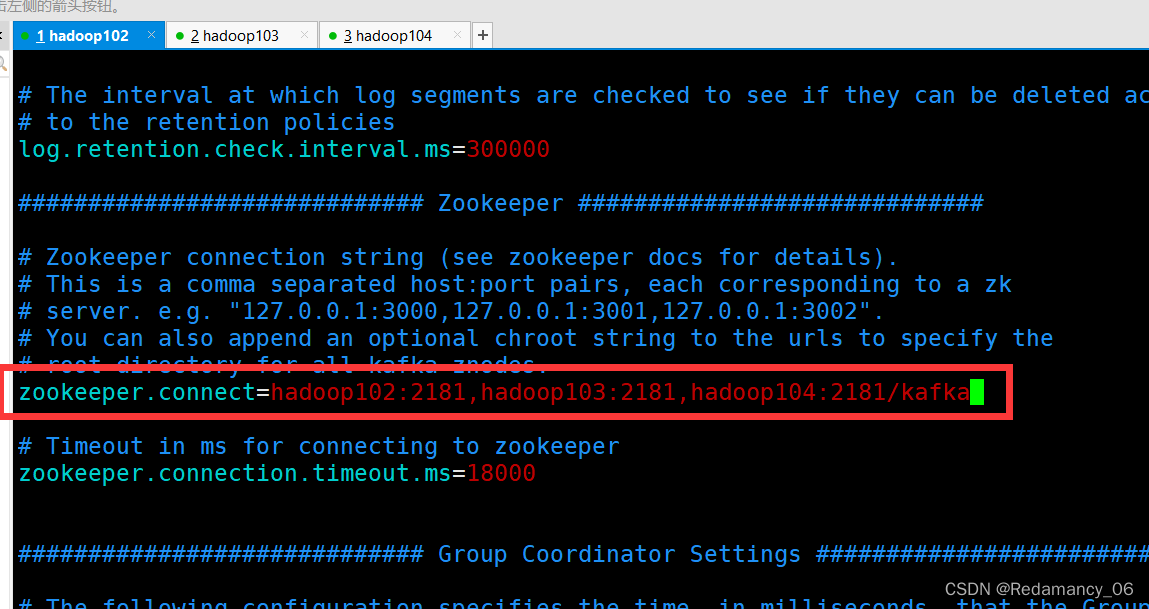
4.2.4.1.2.5 分发安装包
[summer@hadoop102 module]$ xsync kafka-3.0.0/- 1

4.2.4.1.2.6 分别在hadoop103和hadoop104上修改配置文件/opt/module/kafka/config/server.properties中的broker.id=1、broker.id=2
注:broker.id不得重复,整个集群中唯一。
[summer@hadoop103 module]$ vim kafka-3.0.0/config/server.properties- 1
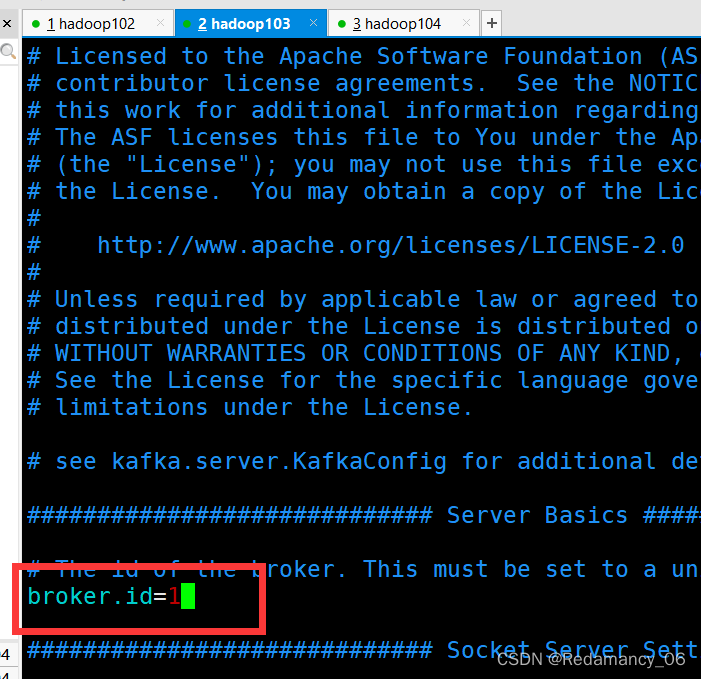
[summer@hadoop104 module]$ vim kafka-3.0.0/config/server.properties- 1

4.2.4.1.2.7 配置环境变量
(1)在/etc/profile.d/my_env.sh文件中增加kafka环境变量配置
[summer@hadoop104 module]$ sudo vim /etc/profile.d/my_env.sh- 1
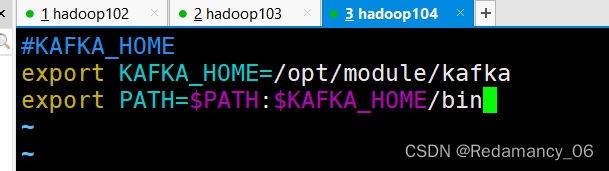
增加如下内容:#KAFKA_HOME export KAFKA_HOME=/opt/module/kafka export PATH=$PATH:$KAFKA_HOME/bin- 1
- 2
- 3
(2)刷新一下环境变量
[summer@hadoop104 module]$ source /etc/profile.d/my_env.sh- 1

(3)分发环境变量文件到其他节点,并source
[summer@hadoop104 module]$ sudo /home/summer/bin/xsync /etc/profile.d/my_env.sh- 1
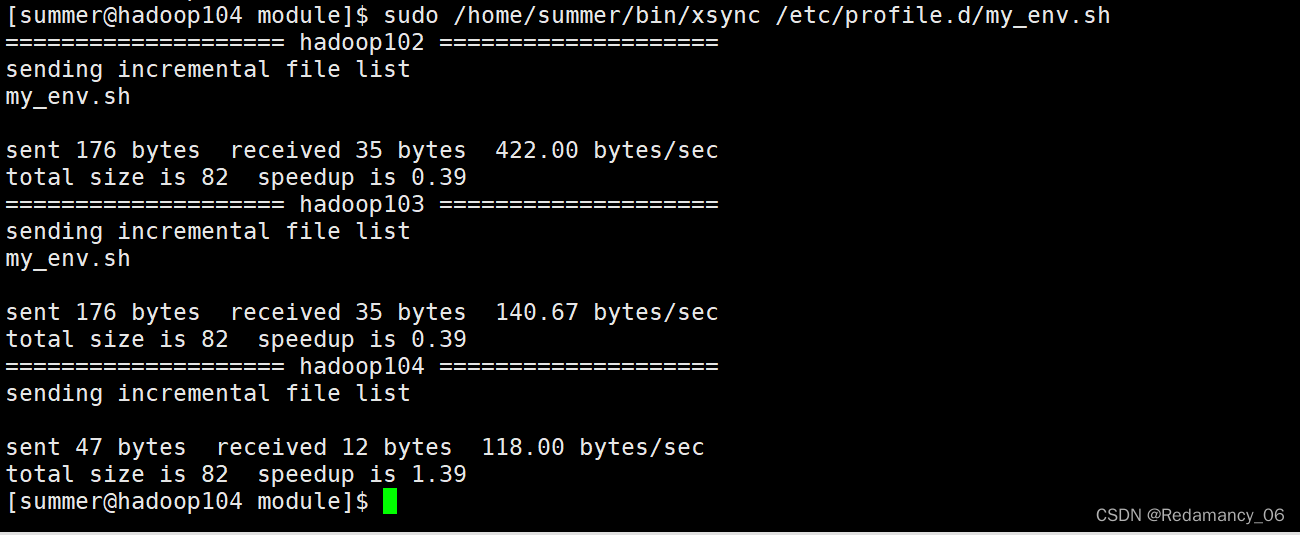
[summer@hadoop103 module]$ source /etc/profile.d/my_env.sh- 1

[summer@hadoop102 module]$ source /etc/profile.d/my_env.sh- 1

4.2.4.1.2.8 启动集群
(1)先启动Zookeeper集群,然后启动Kafka
[summer@hadoop102 kafka-3.0.0]$ zk.sh start- 1
(2)依次在hadoop102、hadoop103、hadoop104节点上启动Kafka
[summer@hadoop102 kafka-3.0.0]$ bin/kafka-server-start.sh -daemon config/server.properties [summer@hadoop103 kafka-3.0.0]$ bin/kafka-server-start.sh -daemon config/server.properties [summer@hadoop104 kafka-3.0.0]$ bin/kafka-server-start.sh -daemon config/server.properties- 1
- 2
- 3



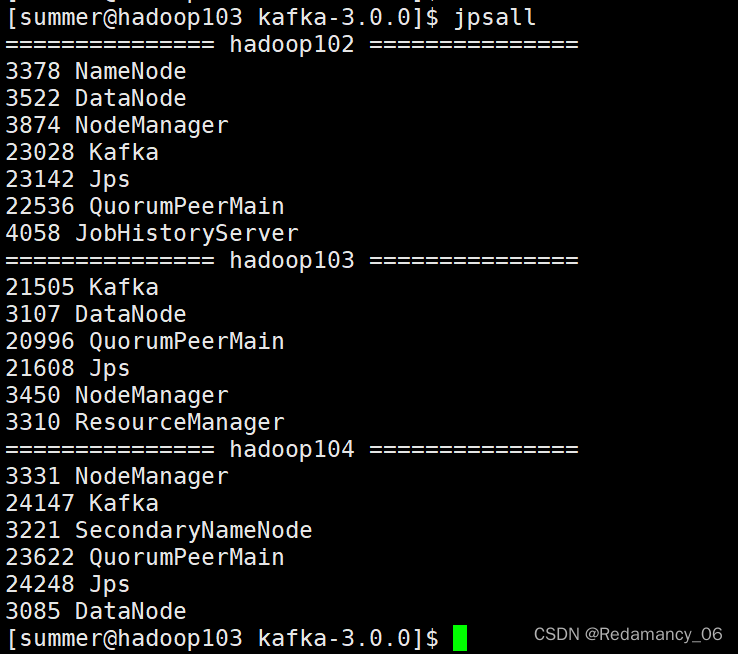
注意:配置文件的路径要能够到server.properties。
4.2.4.1.2.9 关闭集群
[summer@hadoop102 kafka-3.0.0]$ bin/kafka-server-stop.sh [summer@hadoop103 kafka-3.0.0]$ bin/kafka-server-stop.sh [summer@hadoop104 kafka-3.0.0]$ bin/kafka-server-stop.sh- 1
- 2
- 3
4.2.4.1.3 集群启停脚本
4.2.4.1.3.1 在/home/summer/bin目录下创建文件kf.sh脚本文件
[summer@hadoop102 bin]$ vim kf.sh- 1


脚本如下:#! /bin/bash case $1 in "start"){ for i in hadoop102 hadoop103 hadoop104 do echo " --------启动 $i Kafka-------" ssh $i "/opt/module/kafka-3.0.0/bin/kafka-server-start.sh -daemon /opt/module/kafka-3.0.0/config/server.properties" done };; "stop"){ for i in hadoop102 hadoop103 hadoop104 do echo " --------停止 $i Kafka-------" ssh $i "/opt/module/kafka-3.0.0/bin/kafka-server-stop.sh " done };; esac- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
4.2.4.1.3.2 添加执行权限
[summer@hadoop102 bin]$ chmod 777 kf.sh- 1

4.2.4.1.3.3 启动集群命令
[summer@hadoop102 bin]$ kf.sh start- 1

4.2.4.1.3.4 停止集群命令
[summer@hadoop102 bin]$ kf.sh stop- 1
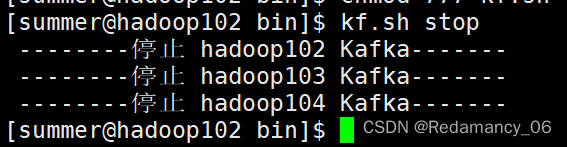
注意:停止Kafka集群时,一定要等Kafka所有节点进程全部停止后再停止Zookeeper集群。因为Zookeeper集群当中记录着Kafka集群相关信息,Zookeeper集群一旦先停止,Kafka集群就没有办法再获取停止进程的信息,只能手动杀死Kafka进程了。
4.2.4.1.3.5 分发集群命令

4.2.4.2 Kafka命令行操作
4.2.4.2.1 主题命令行操作
4.2.4.2.1.1 查看操作主题命令参数
[summer@hadoop102 kafka-3.0.0]$ bin/kafka-topics.sh- 1
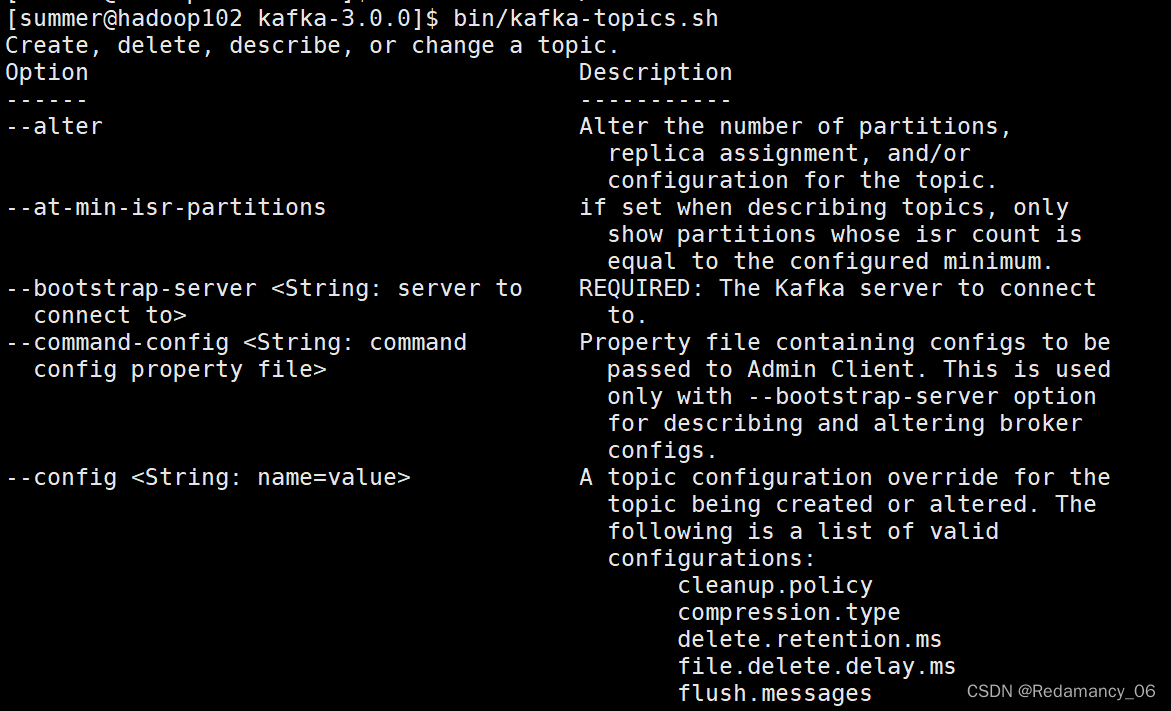
参数 描述 –bootstrap-server 连接的Kafka Broker主机名称和端口号。 –topic 操作的topic名称。 –create 创建主题。 –delete 删除主题。 –alter 修改主题。 –list 查看所有主题。 –describe 查看主题详细描述。 –partitions 设置分区数。 –replication-factor 设置分区副本。 –config 更新系统默认的配置。 4.2.4.2.1.2 查看当前服务器中的所有topic
[summer@hadoop102 kafka-3.0.0]$ bin/kafka-topics.sh --bootstrap-server hadoop102:9092 --list- 1

4.2.4.2.1.3 创建first topic
[summer@hadoop102 kafka-3.0.0]$ bin/kafka-topics.sh --bootstrap-server hadoop102:9092 --create --partitions 1 --replication-factor 3 --topic first- 1
 选项说明:
选项说明:
–topic 定义topic名
–replication-factor 定义副本数
–partitions 定义分区数4.2.4.2.1.4 查看first主题的详情

[summer@hadoop102 kafka-3.0.0]$ bin/kafka-topics.sh --bootstrap-server hadoop102:9092 --describe --topic first Topic: first TopicId: 6qHd_8laRYuy9jblKAsdZg PartitionCount: 1 ReplicationFactor: 3 Configs: segment.bytes=1073741824 Topic: first Partition: 0 Leader: 1 Replicas: 1,0,2 Isr: 1,0,2- 1
- 2
- 3
4.2.4.2.1.5 修改分区数(注意:分区数只能增加,不能减少)
[summer@hadoop102 kafka-3.0.0]$ bin/kafka-topics.sh --bootstrap-server hadoop102:9092 --alter --topic first --partitions 3- 1
4.2.4.2.1.6 再次查看first主题的详情

[summer@hadoop102 kafka-3.0.0]$ bin/kafka-topics.sh --bootstrap-server hadoop102:9092 --alter --topic first --partitions 3 [summer@hadoop102 kafka-3.0.0]$ bin/kafka-topics.sh --bootstrap-server hadoop102:9092 --describe --topic first Topic: first TopicId: 6qHd_8laRYuy9jblKAsdZg PartitionCount: 3 ReplicationFactor: 3 Configs: segment.bytes=1073741824 Topic: first Partition: 0 Leader: 1 Replicas: 1,0,2 Isr: 1,0,2 Topic: first Partition: 1 Leader: 2 Replicas: 2,1,0 Isr: 2,1,0 Topic: first Partition: 2 Leader: 0 Replicas: 0,2,1 Isr: 0,2,1- 1
- 2
- 3
- 4
- 5
- 6
4.2.4.2.1.7 删除topic(自己演示)
[summer@hadoop102 kafka-3.0.0]$ bin/kafka-topics.sh --bootstrap-server hadoop102:9092 --delete --topic first- 1

4.2.4.2.2 生产者命令行操作
4.2.4.2.2.1 查看操作生产者命令参数
[summer@hadoop102 kafka-3.0.0]$ bin/kafka-console-producer.sh- 1

参数 描述 –bootstrap-server 连接的Kafka Broker主机名称和端口号。 –topic 操作的topic名称。 4.2.4.2.2.2 发送消息
[summer@hadoop102 kafka-3.0.0]$ bin/kafka-console-producer.sh --bootstrap-server hadoop102:9092 --topic first >ha >nihao >hadoop103- 1
- 2
- 3
- 4

4.2.4.2.3 消费者命令行操作
4.2.4.2.3.1 查看操作消费者命令参数
参数 描述 –bootstrap-server 连接的Kafka Broker主机名称和端口号。 –topic 操作的topic名称。 –from-beginning 从头开始消费。 –group 指定消费者组名称。 4.2.4.2.3.2 消费消息
(1)消费first主题中的数据

(2)把主题中所有的数据都读取出来(包括历史数据)
[summer@hadoop103 kafka-3.0.0]$ bin/kafka-console-consumer.sh --bootstrap-server hadoop102:9092 --from-beginning --topic first- 1

-
相关阅读:
C++ lambda技术点应用
Linux进程的程序内存分析
将ECharts图表插入到Word文档中
django 项目基本配置
Learning C++ No.30 【lambda表达式实战】
函数和变量总结
15-基于Nginx构建Tomcat集群
c++视觉处理----固定阈值操作:Threshold()函数,实时处理:二值化,反二值化,截断,设为零,反向设为零
大模型产业化有四个关键,昇腾AI推动“AI+遥感”打了个样
运维 之 一键部署Tomcat
- 原文地址:https://blog.csdn.net/Redamancy06/article/details/127477817