-
简单的人脸识别实战
简介
记录第一次个人实现人脸识别过程和流程,供今后方便参考,目前为止对神经网络的理论部分暂未学习,故因此本项目/实验仅是对官方的API文档学习后进行的简单逻辑拼凑
做的不好,仅供参考…
注:使用Jupyter运行代码效果更佳,下面给出的代码形式为一个个在Jupyter里的代码cell
项目/实验实现功能:目前为止能较为准确根据照片识别本人的人脸,调整训练集(用于训练的照片)可实现识别多个人脸(暂未进行大数据集测试,效果未知,仅供以后学习参考)
关键的库
face_recognition
load_image_file()
传入照片的路径,读取照片
face_locations()
传入load_image_file()的结果,可以提取出人脸 (不一定每次都能提取到)
返回的是人脸在图片中的位置list,[上,右,下,左],顺时针返回face_encodings()
传入face_locations()的结果
返回长度为128的一个列表,存放人脸128个特征信息tensorflow
使用了序贯模型,并且只有三层连接层
numpy
只需要把list转换成array
大致流程
- 从一组照片中提取出人脸和人脸对应的特征并打上标签,制作成训练集
- 从另一组照片中提取出人脸和人脸对应的特征并打上标签,制作成测试集
- 训练人脸识别模型
- 模型预测
代码
训练集构造
import glob from matplotlib import image import tensorflow as tf import face_recognition from PIL import Image import numpy as np from tensorflow import keras # 有多少种人脸 OUTPUT_NODE = 0 # 训练集数量 TRAIN_DATA_SIZE = 0 # 照片存放的文件夹 train_dir = "F:\project\人脸识别\Train_set\*.jpg" #导入照片提取里面所有的.jpg文件 file_list存放的是每一张图片的路径的list file_list = glob.glob(train_dir) # 测试集特征存储数组 datas = [] # 标签存储数组即有多少中人脸,如:甲乙丙 labels长度为 3 labels = [] count = 0 for image_path in file_list: # print(image_path) # 读取人脸照片 image = face_recognition.load_image_file(image_path) # 扣人脸 face_locations = face_recognition.face_locations(image) # print(face_location) for face_location in face_locations: # 找到人脸位置,返回根据顺时针返回位置:上右下左 # print("这张照片人脸的位置为上:{},下{},左{},右{}".format(top,bottom,left,right)) top,right,bottom,left = face_location # 构造人脸的矩阵 face_image = image[top:bottom, left:right] # 特征提取 face_encode = face_recognition.face_encodings(face_image) # 手动为每一张用于训练的照片打标签 if (len(face_encode) != 0): if (count == 2): datas.append(face_encode) labels.append(2) elif (count == 3): datas.append(face_encode) labels.append(3) else: datas.append(face_encode) labels.append(1) #下面标注的代码是检查人脸是否扣成功 # pil_image = Image.fromarray(face_image) # print(pil_image) # file_name = 'F:\project\人脸识别\TrainFace' # pil_image.save(open(file_name + '\人脸' + str(count) + '.png','wb'),'png') # pil_image.close() count += 1 TRAIN_DATA_SIZE = len(datas) OUTPUT_NODE = len(set(labels))- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
训练集转换成数组
def generate(): # list转换成数组 train_x,train_y = np.array(datas),np.array(labels) return train_x,train_y generate()- 1
- 2
- 3
- 4
- 5
- 6
构造测试集
与构造训练集代码类似
def initTestSet(): test_dir = "F:\project\人脸识别\Test_set\*.jpg" file_test_list = glob.glob(test_dir) # ans存放扣好的人脸 ans = [] for image_path in file_test_list: image = face_recognition.load_image_file(image_path) face_locations = face_recognition.face_locations(image) print(face_locations) # print(face_location) for face_location in face_locations: # 找到人脸位置,返回根据顺时针返回位置:上右下左 # print("这张照片人脸的位置为上:{},下{},左{},右{}".format(top,bottom,left,right)) top,right,bottom,left = face_location # 构造人脸的矩阵 face_image = image[top:bottom, left:right] print(face_encode) ans.append(face_image) return ans test_image = initTestSet()- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
训练模型
def train_face(): # 获取训练集 train_x, train_y = generate() # 将训练集转换为张量,可放入显卡计算加快运行速度,前提tenserflow为GPU版 dataset = tf.data.Dataset.from_tensor_slices((train_x,train_y)) print(dataset) # 数据打包 dataset = dataset.batch(32) # 数据集重复一次,也可多次按需填 dataset = dataset.repeat() # 序贯模型 多个网络层的线性叠加(暂时不知原理) model = keras.Sequential([ # 实现全连接层,输入第一个参数与encoding结果一致即128 # 第二个参数为激活函数(暂时不知原理)这里的激活函数为线性整流函数作用:小于0变为0,大于0不变 keras.layers.Dense(128,activation=tf.nn.relu), keras.layers.Dense(128,activation=tf.nn.relu), # 输出类别是从0开始计算,由于label我是从1开始算,所以需要加1 keras.layers.Dense(OUTPUT_NODE + 1,activation=tf.nn.softmax) # softmax 多分类函数 ]) # 配置训练方法时告知优化器、损失函数和准确率 model.compile(optimizer="adam",loss='sparse_categorical_crossentropy',metrics=['accuracy']) # 训练模型 model.fit(dataset,epochs=10,steps_per_epoch = 30) # 保存模型,也可不存 model.save('model/face_model.h5') train_face()- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
训练结果
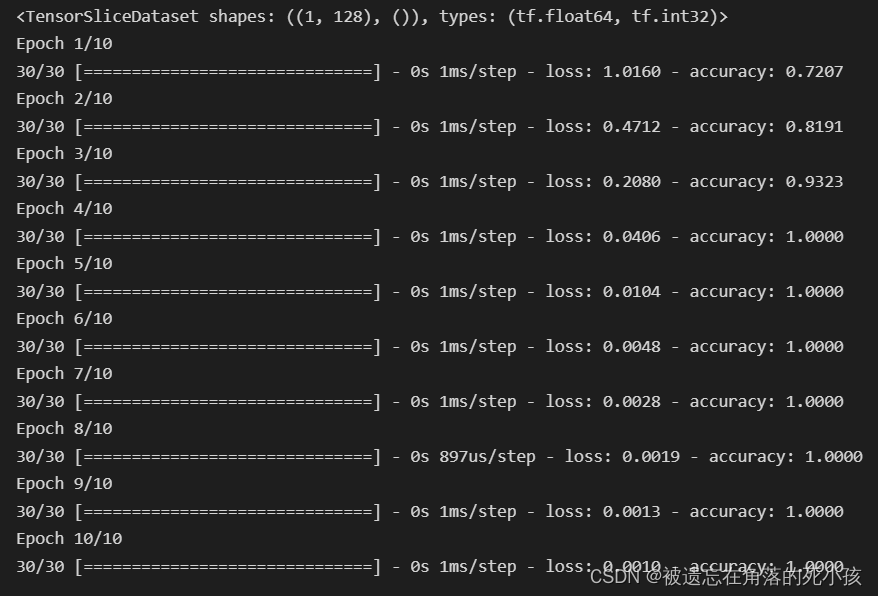
预测人脸
def predict_image(image): # 载入已经保存好的模型,没存可以忽略这一步 model = tf.keras.models.load_model('model/face_model.h5') # 遍历测试集 for it in image: # 特征提取 face_encode = face_recognition.face_encodings(it) # 人脸识别,也能说预测这张照片里的人脸属于哪一类 # 在最新的ts中,只有predict没有predict_classes # predict只会得到相关的矩阵,应该可以写成下面这样代替 ''' predictions1 = model.predict(np.array(face_encode[j]).reshape(1, 128)) print(predictions1) if np.max(predictions1[0]) > 0.90: print(np.argmax(predictions1[0]).dtype) ''' prediction = model.predict_classes(np.array(face_encode)) # 输出结果 print(prediction) print(len(test_image)) # 传入测试集 里面装的是人脸的矩阵 predict_image(test_image)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
输出结果

-
相关阅读:
现代数据栈:高效开发数据,辅助企业决策
C++中的继承
基于监督学习的多模态MRI脑肿瘤分割,使用来自超体素的纹理特征(Matlab代码实现)
【软考软件评测师】第二十三章 系统安全设计(认证与加密)
行为型模式-迭代器模式
架火炬市场现状及未来发展趋势分析
健身房信息管理系统/健身房管理系统
vue实现自定义树形穿梭框功能
2021 Lifelong learning(李宏毅
http与https的区别
- 原文地址:https://blog.csdn.net/weixin_50026222/article/details/127669655
