-
函数参数传递过程分析及可变长参数列表的使用
函数参数传递过程分析及可变长参数列表的使用
tag : c
**note:**所有试验均在gcc编译器下进行,编译优化为-o0,调用规则为__cdecl,编译文件均为64位,cup为intel x64处理器。
1 普通的参数传递
先随便写一个函数,然后在main函数里面去调:
int aaaaaa(int b, int c, int d, int e0, int e1, int e2, int e3, int e4, int e5) { int a = e0 + e1 + e2 + e3 + e4 + e5; b = d + 1 + a; c = b + 1 + a; d = c + 1 + a; return d; } struct __my_s { size_t buff[100]; }; int main() { struct __my_s ss; ss.buff[0] = 7; ss.buff[0] = aaaaaa(ss.buff[0], ss.buff[1], ss.buff[2], ss.buff[3], ss.buff[4], ss.buff[5], ss.buff[6], ss.buff[7], ss.buff[8]); printf("%d, %p\r\n", ss.buff[0], &ss); return 0; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
对应的函数调用部分的汇编代码如下:
ss.buff[0] = 7; 00000000004016bb: movq $0x7,-0x30(%rbp) 108 ss.buff[0] = aaaaaa(ss.buff[0], ss.buff[1], ss.buff[2], ss.buff[3], ss.buff[4], ss.buff[5], ss.buff[6], ss.buff[7], ss.buff[8]); 00000000004016c3: mov 0x10(%rbp),%rax 00000000004016c7: mov %eax,%r11d 00000000004016ca: mov 0x8(%rbp),%rax 00000000004016ce: mov %eax,%r10d 00000000004016d1: mov 0x0(%rbp),%rax 00000000004016d5: mov %eax,%r9d 00000000004016d8: mov -0x8(%rbp),%rax 00000000004016dc: mov %eax,%r8d 00000000004016df: mov -0x10(%rbp),%rax 00000000004016e3: mov %eax,%ecx 00000000004016e5: mov -0x18(%rbp),%rax 00000000004016e9: mov %eax,%esi 00000000004016eb: mov -0x20(%rbp),%rax 00000000004016ef: mov %eax,%ebx 00000000004016f1: mov -0x28(%rbp),%rax 00000000004016f5: mov %eax,%edx 00000000004016f7: mov -0x30(%rbp),%rax 00000000004016fb: mov %r11d,0x40(%rsp) 0000000000401700: mov %r10d,0x38(%rsp) 0000000000401705: mov %r9d,0x30(%rsp) 000000000040170a: mov %r8d,0x28(%rsp) 000000000040170f: mov %ecx,0x20(%rsp) 0000000000401713: mov %esi,%r9d 0000000000401716: mov %ebx,%r8d 0000000000401719: mov %eax,%ecx 000000000040171b: callq 0x40163c- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 首先,栈是从高地址向低地址生长的,而堆是从低地址向高地址生长的,所以这里的栈底指针rbp的值大于栈顶指针rsp。
从“00000000004016bb”这一行可以看出buff[0]位于-0x30的位置,所以接下来的“00000000004016c3”行到“00000000004016f7”都是在取buff[n]的元素,正好取了9个,也就是后面要传递的参数个数。 - 这里可以看出来,虽然我的数组长度是100,但是如果你没有使用,那么编译器即使开o0,也会把这里的内存优化掉,也就是不为无用的定义去申请栈内存。至于为什么buff的最后一个元素会从0x10这个地址开始,这一点暂时没有查证,因为理论上0x10已经不属于这个函数的栈了,也可能这一段是给main函数传参预留的栈空间,所以虽然不是这个函数的,但是他依然可以去使用也说不定,这一点后面有机会再去研究,毕竟这个是特殊的main函数。
- 接着后面的“00000000004016fb”开始就是传参的过程了,但是仅仅只是一部分,这里我们可以发现编译器更喜欢用通用寄存器去传参,而不是栈内存,这一点虽然这个函数没有体现,但是如果我们降低参数量(为了体现栈的传参,我故意设置了很多参数),比如只有1个参数,那么这个时候就不会出现类似“00000000004016fb”这样的操作了,而是直接使用“0000000000401713”这样的操作,通过寄存器把参数传递给下一个函数。
- 当然,上面也说了,这个只是传参的一部分,因为类似“0000000000401713”这样的操作并不是不进栈,只是等到被调用的函数体内再去进栈的,这一点估计和编译优化相关,毕竟这种明显费力不讨好的事情做起来感觉划不来,明明可以一次做完的,非要做几次。另外,我们可以看到使用栈传参的时候并不是使用的rbp作为基地址,而是使用的rsp作为基地址,也就是所有的值都是以rsp作为偏移的,这一点在后面进入被调用的函数体内了比较有用。
被调用函数的最开始一段汇编代码如下:
93 int aaaaaa(int b, int c, int d, int e0, int e1, int e2, int e3, int e4, int e5) { aaaaaa: 000000000040163c: push %rbp 000000000040163d: mov %rsp,%rbp 0000000000401640: sub $0x10,%rsp 0000000000401644: mov %ecx,0x10(%rbp) 0000000000401647: mov %edx,0x18(%rbp) 000000000040164a: mov %r8d,0x20(%rbp) 000000000040164e: mov %r9d,0x28(%rbp) 94 int a = e0 + e1 + e2 + e3 + e4 + e5; 0000000000401652: mov 0x28(%rbp),%edx 0000000000401655: mov 0x30(%rbp),%eax 0000000000401658: add %eax,%edx 000000000040165a: mov 0x38(%rbp),%eax 000000000040165d: add %eax,%edx 000000000040165f: mov 0x40(%rbp),%eax 0000000000401662: add %eax,%edx 0000000000401664: mov 0x48(%rbp),%eax 0000000000401667: add %eax,%edx 0000000000401669: mov 0x50(%rbp),%eax 000000000040166c: add %edx,%eax 000000000040166e: mov %eax,-0x4(%rbp) ... 000000000040169e: add $0x10,%rsp 00000000004016a2: pop %rbp 00000000004016a3: retq- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 进入到了被调用函数,一进来这里会有一个push操作,也就是先把上一个函数的rbp,也就是栈底指针保存下来,等调用完了函数回到原函数时再把这个值还回去,rsp的还原通过代码可以观察到在“0000000000401640”行时为函数分配了该函数的栈大小,在“000000000040169e”行时释放了该函数的栈内存,所以rsp也就还原了。
- 接着就是前面说到的,在调用这个函数的外层函数里面传参只做了一部分数据的进栈,而另一部分就是在“0000000000401644”到“000000000040164e”行做的。这里有个点比较有趣,这里进栈的位置都是rbp的上部,也就是说使用的是外层函数的栈空间,同时因为这里的rbp其实就是外层函数的rsp,再结合前面讲到的外层函数在进栈的时候都是用的rsp作为基地址,所以这两者就统一起来了,其实这里的rbp和外层的rsp都是用的同一个基地址在存储,而外层函数在存储参数的时候正好把这个函数要用的一段栈给空出来了,这里我们可以看看外层函数入栈的地址:
00000000004016fb: mov %r11d,0x40(%rsp) 0000000000401700: mov %r10d,0x38(%rsp) 0000000000401705: mov %r9d,0x30(%rsp) 000000000040170a: mov %r8d,0x28(%rsp) 000000000040170f: mov %ecx,0x20(%rsp)- 1
- 2
- 3
- 4
- 5
也就是说外层函数使用了0x200x40这一段空间,那么被调用函数则可使用0x000x18这段空间了,正好可以存4个参数,也就是被调用函数中需要进栈的4个参数。
但是这里出现了一个问题,被调用函数进栈使用的空间如下:0000000000401644: mov %ecx,0x10(%rbp) 0000000000401647: mov %edx,0x18(%rbp) 000000000040164a: mov %r8d,0x20(%rbp) 000000000040164e: mov %r9d,0x28(%rbp)- 1
- 2
- 3
- 4
- 其使用的是0x100x28,而不是我们期待的0x000x18,但是程序执行的却又没问题,这里对不上那肯定是我们忽略了什么。
- 再看到“000000000040163c”行,push操作会让rsp增加一个单位长度,64位处理器里面就是0x08,所以这里的rbp看来还并不是外层函数的rsp,因为push之后rsp+8了,感觉问题找到了,但是好像还是对不上,还差了0x08。这个0x08后来发现是在执行“000000000040171b”这一行,也就是callq的时候加上的,这里为什么会增加0x08后面有空看看能不能找到具体的芯片手册再看看原因。总之,现在对上了,基本的传参过程也就清楚了。
2 结构体参数传递
前面分析了一下基本的参数传递,那么如果是结构体作为参数呢?比如说一个结构体几百个字节,这个时候参数列表的内存使用又是什么样的?如果是传递的结构体指针,参数列表又是什么样的?
指针参数
先来看一下传递结构体指针的情况:
struct __my_s { size_t buff[100]; }; int bbb(struct __my_s *ss) { ss->buff[0] = 99; printf("%d\r\n", ss->buff[0]); return 0; } int main() { struct __my_s ss; ss.buff[0] = 7; bbb(&ss); printf("%d, %p\r\n", ss.buff[0], &ss); return 0; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
函数调用处的汇编代码如下:
103 ss.buff[0] = 7; 00000000004016bb: movq $0x7,-0x60(%rbp) 112 bbb(&ss); 00000000004016c3: lea -0x60(%rbp),%rax 00000000004016c7: mov %rax,%rcx 00000000004016ca: callq 0x401606- 1
- 2
- 3
- 4
- 5
- 6
被调用函数入口处的汇编代码如下:
0000000000401606: push %rbp 0000000000401607: mov %rsp,%rbp 000000000040160a: sub $0x20,%rsp 000000000040160e: mov %rcx,0x10(%rbp) 88 ss->buff[0] = 99; 0000000000401612: mov 0x10(%rbp),%rax- 1
- 2
- 3
- 4
- 5
- 6
从上面代码来看,和我们再第一节中分析的是一致的,这里“00000000004016c3”行把参数的栈地址传给了rcx寄存器,再通过rcx寄存器传给被调用函数,被调用函数将其地址放到自己的栈中,并进行使用,自始至终最终操作的内存都是外层函数的那一段栈内存,被调用函数只是获得了一个指针,这一点和指针传递的意义完全相同。
结构体参数
再来看看传结构体的情况,根据一般的描述,如果直接把结构体传给被调用函数,相当于把传递的结构体拷贝了一份给被调用函数,那么这里面就有个问题了,结构体是把自己拷贝到了参数列表里面还是说结构体把自己拷贝到一块其他的内存里面,然后参数列表还是传递指针?理论上这两个方法都可以实现功能,但是对于取参数的操作又有些区别,这个区别其实主要体现在了变长参数的使用时,这一点后面再详细展开,先研究传递到底是怎么进行的。
两种方式用图表示的话如下:
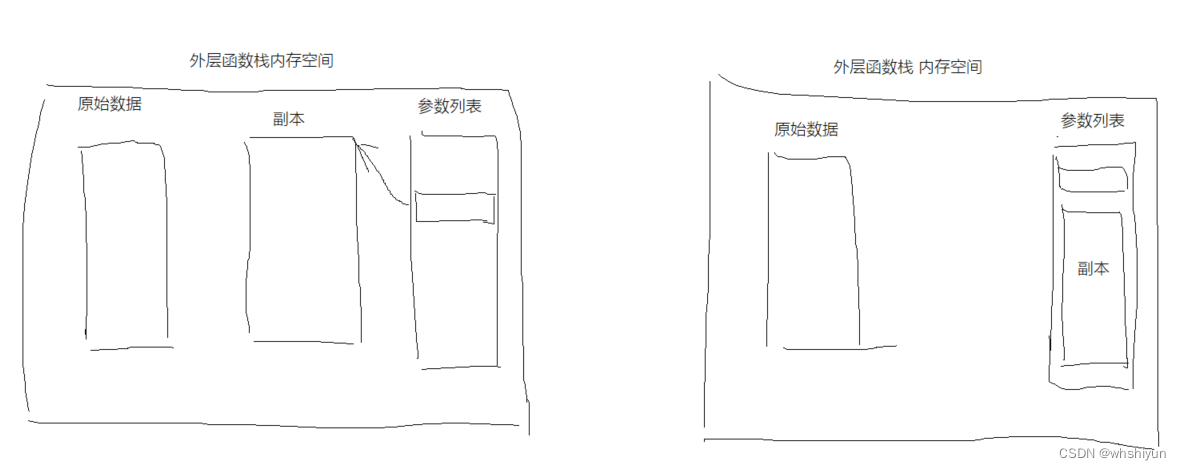
相关代码如下:
struct __my_s { size_t buff[100]; }; int bbb(struct __my_s ss) { ss.buff[0] = 99; printf("%d\r\n", ss.buff[0]); return 0; } int main() { struct __my_s ss; ss.buff[0] = 7; bbb(ss); printf("%d, %p\r\n", ss.buff[0], &ss); return 0; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
外层函数调用处的汇编代码如下:
103 ss.buff[0] = 7; 00000000004016b9: movq $0x7,0x2c0(%rbp) 112 bbb(ss); 00000000004016c4: lea -0x60(%rbp),%rax 00000000004016c8: lea 0x2c0(%rbp),%rdx 00000000004016cf: mov $0x320,%ecx 00000000004016d4: mov %rcx,%r8 00000000004016d7: mov %rax,%rcx 00000000004016da: callq 0x402c1000000000004016df: lea -0x60(%rbp),%rax 00000000004016e3: mov %rax,%rcx 00000000004016e6: callq 0x401606 - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
被调用函数入口处代码如下:
0000000000401606: push %rbp 0000000000401607: push %rbx 0000000000401608: sub $0x28,%rsp 000000000040160c: lea 0x80(%rsp),%rbp 0000000000401614: mov %rcx,%rbx 88 ss.buff[0] = 99; 0000000000401617: movq $0x63,(%rbx)- 1
- 2
- 3
- 4
- 5
- 6
- 7
可以看到“00000000004016da”行进行了数据拷贝,拷贝的源地址存在rdx寄存器,值是0x2c0,目的地址存在rcx寄存器,值是-0x60,拷贝的长度存在r8寄存器,值为800。而最后把拷贝后的目的地址作为参数传给了被调用函数。也就是说在传递结构体时是采用的上图中左边的那种方式。
3 关于可变长参数列表的参数获取问题
那么现在如果说有一个可变参数函数,希望在另一个可变长参数的函数中调用该函数,同时把可变长参数部分原封不动的传递下去:
void fun0(int arg_num, ...) { } void fun1(int arg_num, ...) { fun0(int arg_num, ...);/* 在不借助汇编的情况下这里的参数没法自动填充 */ }- 1
- 2
- 3
- 4
- 5
- 6
这个目的在不借助汇编的情况下是实现不了的,因为在fun1中动态根据arg_num获取的参数没法静态传入fun0中,因为函数的传参是在代码编写的时候就固定了的,不能动态改变传参的个数,所以上述这个功能不借助汇编的话是无法实现的。但是借助了汇编就局限了code的移植性,也就是在不同的处理器架构上都要重写这里的函数调用(因为函数调用的过程需要用汇编来编写)。
最后关于可变长参数读取的时候有个细节需要注意一下,避免出错。
void fun0(int arg_num, ...) { size_t *p_var = ((size_t *)&arg_num) + 1; size_t var0 = *p_var; size_t var1 = *(p_var + 1); ... }- 1
- 2
- 3
- 4
- 5
- 6
这里要注意的是解析出来的参数只是参数的地址,需要取*号才是参数的值,这一点在传递指针的时候有时会出错,比如说前面提到的如果传递了一个结构体类型的变量:
void fun0(int arg_num, ...) { size_t *p_var = ((size_t *)&arg_num) + 1; struct __my_s ss = *((struct __my_s *)(*p_var)); } int main() { struct __my_s ss; ss.buff[0] = 7; fun0(1, ss); return 0; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
这一点在传递结构体类型的参数时很容易弄错,因为直观上感觉我们是传递了ss这一个结构体的值过去了,而被调用函数中解析出来的p_var实际上是一个指向指针的指针,这一点原因在于结构体参数章节所分析,因为我们以为传递的结构体ss,在参数列表中实际上是存储的一个指针值而已。但是如果我们的被调用参数如果直接定义成
void fun0(int arg_num, struct __my_s ss),虽然参数列表上面传递的是一个指针值,但是在代码中使用的时候是直接把他当成了结构体参数在使用,也就是ss.buff[]这样使用而不是ss->buff[]。从汇编代码来看:
结构体传递push %rbp 0000000000401654: push %rbx 0000000000401655: sub $0x28,%rsp 0000000000401659: lea 0x80(%rsp),%rbp 0000000000401661: mov %rcx,%rbx 91 ss.buff[2] = 99; 0000000000401664: movq $0x63,0x10(%rbx)- 1
- 2
- 3
- 4
- 5
- 6
- 7
指针传递
0000000000401653: push %rbp 0000000000401654: mov %rsp,%rbp 0000000000401657: sub $0x20,%rsp 000000000040165b: mov %rcx,0x10(%rbp) 91 ss->buff[2] = 99; 000000000040165f: mov 0x10(%rbp),%rax 0000000000401663: movq $0x63,0x10(%rax)- 1
- 2
- 3
- 4
- 5
- 6
- 7
可以看出其实指针传递和结构体传递其实都是传递的结构体指针,但是指针传递时多一步存储操作,这里具体的原因暂时不清楚,但可以发现两者虽然同样是传递地址,汇编的行为确实不一样。
在传递结构体的时候,无论怎么样,这个结构体的数据拷贝(也就是传递的参数)一定在栈内存中,而作为指针传递时,指针所指向的内存可能在栈内存中,也可能不在。
关于这一点以后有机会分析编译器的时候再研究了。当然上述解析可变长参数列表也可以用c语言库定义的一些宏作为辅助:
va_start; va_arg; va_end;,其实原理和上述是一样的。最后如果非要实现可变长参数嵌套,那么要么重新打包成数组(参数列表保存成数组),然后再把数组作为一个参数传递,这样被调用的函数也就是定长参数列表了。另一种方法是设置一个变长参数上限,然后把被调用函数固定传递最大个数的参数。除此之外在不使用汇编的情况下别无他法。(至少目前没想到更好的方法)
附0:关于float类型的传递问题0
在64位计算机上如果有
void fun(int arg_num, ...) { size_t *p_var = ((size_t *)&arg_num) + 1; size_t var0 = *p_var; } int main() { float a = 5.0f; fun(1, a); }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
这个时候存在一个问题,a虽然是float类型的,但是var0却是以double类型存储的,所以这个时候虽然var0在数值上等于a,但实际内存中存储的值是不同的,a=0x0000000040a00000;var0=0x4014000000000000
这里就让这种变长参数传递值的时候,如果需要观察内存内容的情况下会出现问题,因为两个值的内存值是不同的。附1: 关于float类型的传递问题1
在64位计算机上如果有
typedef void (*FUN_TYPE)(int arg_num, ...); void fun1(int arg_num, float var0, float var1, float var2, float var3, float var4, float var5) { ... } FUN_TYPE fun = fun1; void fun0(int arg_num, ...) { size_t *p_var = ((size_t *)&arg_num) + 1; size_t var[6]; for(int i = 0; i < arg_num; i ++) { var[i] = p_var[i]; } fun(arg_num, var[0], var[1], var[2], var[3], var[4], var[5]); } int main() { float a[6] = {5.0f, 6.0f, 7.0f, 8.0f, 9.0f, 10.0f}; fun0(1, a[0], a[1], a[2], a[3], a[4], a[5]); }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
根据附录0,我们可以知道fun0中的var值都已经是double类型了,而不是float类型,这个时候调用fun1,fun1中的varX就全是错的了,因为这里系统自动截取了低32bit作为varX的值,而这里实际上传递的是一个64bit的值,只是fun1里面还不知道,因为他自己定义的是一个32bit的值,所以他自己只会截取低32bit的数据来使用。根据上述现象,把代码改一下:
typedef void (*FUN_TYPE)(int arg_num, ...); void fun1(int arg_num, float var0, float var1, float var2, float var3, float var4, float var5) { ... } FUN_TYPE fun = fun1; void fun0(int arg_num, ...) { size_t *p_var = ((size_t *)&arg_num) + 1; size_t var[6]; for(int i = 0; i < arg_num; i ++) { var[i] = p_var[i]; } fun(arg_num, var[0], var[1], var[2], var[3], var[4], var[5]); } int main() { float a[6] = {5.0f, 6.0f, 7.0f, 8.0f, 9.0f, 10.0f}; fun0(1, *((size_t *)&a[0]), *((size_t *)&a[1]), *((size_t *)&a[2]), *((size_t *)&a[3]), *((size_t *)&a[4]), *((size_t *)&a[6])); }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
思路很简单,就是把float类型的二进制数值传递下去,这样fun1中取低32bit使用时就是原始传递的float值了。
然而……还是不对,这里发现后面三个值是对的,前面三个值是错的……
检查一下汇编:00007FF6BF6F599D mov eax,8 00007FF6BF6F59A2 imul rax,rax,9 00007FF6BF6F59A6 mov ecx,8 00007FF6BF6F59AB imul rcx,rcx,8 00007FF6BF6F59AF mov edx,8 00007FF6BF6F59B4 imul rdx,rdx,7 00007FF6BF6F59B8 mov r8d,8 00007FF6BF6F59BE imul r8,r8,6 00007FF6BF6F59C2 mov r9d,8 00007FF6BF6F59C8 imul r9,r9,5 00007FF6BF6F59CC mov r10d,8 00007FF6BF6F59D2 imul r10,r10,4 00007FF6BF6F59D6 mov r11d,8 00007FF6BF6F59DC imul r11,r11,3 00007FF6BF6F59E0 mov ebx,8 00007FF6BF6F59E5 imul rbx,rbx,2 00007FF6BF6F59E9 mov edi,8 00007FF6BF6F59EE imul rdi,rdi,1 00007FF6BF6F59F2 mov esi,8 00007FF6BF6F59F7 imul rsi,rsi,0 00007FF6BF6F59FB mov rbp,qword ptr [t_cb] 00007FF6BF6F5A03 mov rax,qword ptr [rax+rbp+20h] 00007FF6BF6F5A08 mov qword ptr [rsp+50h],rax 00007FF6BF6F5A0D mov rax,qword ptr [t_cb] 00007FF6BF6F5A15 mov rax,qword ptr [rax+rcx+20h] 00007FF6BF6F5A1A mov qword ptr [rsp+48h],rax 00007FF6BF6F5A1F mov rax,qword ptr [t_cb] 00007FF6BF6F5A27 mov rax,qword ptr [rax+rdx+20h] 00007FF6BF6F5A2C mov qword ptr [rsp+40h],rax 00007FF6BF6F5A31 mov rax,qword ptr [t_cb] 00007FF6BF6F5A39 mov rax,qword ptr [rax+r8+20h] 00007FF6BF6F5A3E mov qword ptr [rsp+38h],rax 00007FF6BF6F5A43 mov rax,qword ptr [t_cb] 00007FF6BF6F5A4B mov rax,qword ptr [rax+r9+20h] 00007FF6BF6F5A50 mov qword ptr [rsp+30h],rax 00007FF6BF6F5A55 mov rax,qword ptr [t_cb] 00007FF6BF6F5A5D mov rax,qword ptr [rax+r10+20h] 00007FF6BF6F5A62 mov qword ptr [rsp+28h],rax 00007FF6BF6F5A67 mov rax,qword ptr [t_cb] 00007FF6BF6F5A6F mov rax,qword ptr [rax+r11+20h] 00007FF6BF6F5A74 mov qword ptr [rsp+20h],rax 00007FF6BF6F5A79 mov rax,qword ptr [t_cb] 00007FF6BF6F5A81 mov r9,qword ptr [rax+rbx+20h] 00007FF6BF6F5A86 mov rax,qword ptr [t_cb] 00007FF6BF6F5A8E mov r8,qword ptr [rax+rdi+20h] 00007FF6BF6F5A93 mov rax,qword ptr [t_cb] 00007FF6BF6F5A9B mov rdx,qword ptr [rax+rsi+20h] 00007FF6BF6F5AA0 mov rax,qword ptr [t_cb] 00007FF6BF6F5AA8 mov rcx,qword ptr [rax+8] 00007FF6BF6F5AAC mov rax,qword ptr [t_cb] 00007FF6BF6F5AB4 call qword ptr [rax+10h]- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
这里的汇编和前面的代码不是同一段,但是原理相同,只是实际的参数个数和名称定义不同。
这里可以看到,前面三个参数通过rdx、r8、r9三个寄存器存储了,其余的进栈了,这里和前面分析的函数调用是一致的。接下来看被调用函数开头的汇编,理论上应该就是把这三个寄存器入栈。00007FF6BFDF6500 movss dword ptr [denominator0],xmm3 00007FF6BFDF6506 movss dword ptr [rsp+18h],xmm2 00007FF6BFDF650C movss dword ptr [rsp+10h],xmm1 00007FF6BFDF6512 mov qword ptr [rsp+8],rcx 00007FF6BFDF6517 sub rsp,0A8h- 1
- 2
- 3
- 4
- 5
和预想的完全一样,只不过这里换成了xmmX这个玩意了,这个玩意从资料来看对应的作用就和rcx/rdx/r8/r9寄存器类似,这里和前面好像可以对上了,但是这里有一个问题就是,前面传递参数的时候不知道是要传浮点,所以把值放到了r8、r9这些寄存器里面了,而被调用函数认为他是传递float类型值,所以从xmmX中去取值了,从而导致了这里的错误……
-
相关阅读:
基于python找到并显示100以内的素数
addr2line 回复“问号”问题的解决和一些发现
【svg和canvas的区别】
【Linux】动静态库
Spring中AOP使用场景
【设计模式】【创建型5-4】【建造者模式】
Minimum Varied Number Codeforces 1714C
MySQL如何保证主备一致?
图解:Go Mutext
重学前端-面向对象
- 原文地址:https://blog.csdn.net/whshiyun/article/details/127670374
