-
【阿旭机器学习实战】【18】KMeans聚类中的常见问题
【阿旭机器学习实战】系列文章主要介绍机器学习的各种算法模型及其实战案例,欢迎点赞,关注共同学习交流。
本文对机器学习中的KMeans聚类中常见的几个问题进行说明介绍。
KMeans聚类中的常见问题
使用make_blobs创建样本点
samples,targets = datasets.make_blobs(n_samples=150,n_features=2,centers=3,random_state=1)- 1
plt.scatter(samples[:,0],samples[:,1],c=targets)- 1
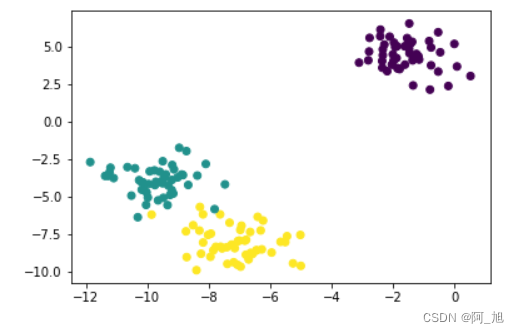
1、K值不合适
km = KMeans(n_clusters=2)- 1
km.fit(samples)- 1
KMeans(algorithm='auto', copy_x=True, init='k-means++', max_iter=300, n_clusters=2, n_init=10, n_jobs=1, precompute_distances='auto', random_state=None, tol=0.0001, verbose=0)- 1
- 2
- 3
y_ = km.predict(samples)- 1
metrics.adjusted_rand_score(targets,y_)- 1
0.5681159420289855- 1
metrics.silhouette_score(samples,km.labels_)- 1
0.7802809392385796- 1
一般综合考虑ARI指标和轮廓系数来决定划分几个聚类。
更多优质内容可关注公众号:
“阿旭算法与机器学习”,共同学习交流2、数据偏差较大
samples,target = datasets.make_blobs(n_features=2,n_samples=150,centers=3,random_state=5)- 1
plt.scatter(samples[:,0],samples[:,1],c=target)- 1
- 1
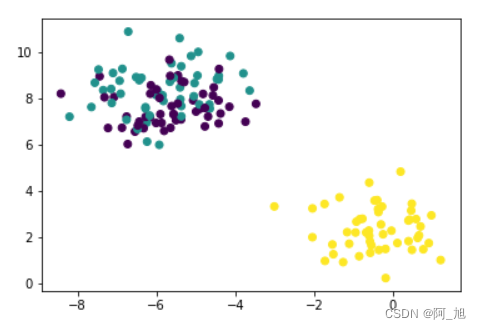
km = KMeans(n_clusters=2)- 1
y_ = km.fit_predict(samples)- 1
metrics.adjusted_rand_score(y_,target)- 1
0.5681159420289855- 1
metrics.silhouette_score(samples,km.labels_)- 1
0.7744057193895231- 1
对于偏差比较大的数据,可以引入一个修正矩阵来对特征进行修正
trans = np.array([[0.6,-0.6],[-0.4,0.8]])- 1
sam1 = np.dot(samples,trans)- 1
plt.scatter(sam1[:,0],sam1[:,1],c=target)- 1
- 1
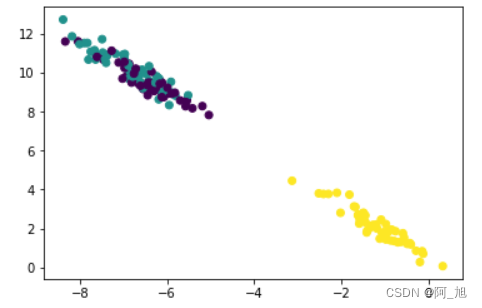
km = KMeans(n_clusters=2)- 1
y_ = km.fit_predict(sam1)- 1
metrics.adjusted_rand_score(y_,target)- 1
0.5681159420289855- 1
metrics.silhouette_score(sam1,km.labels_)- 1
0.8527525114558019- 1
3、各个类别内部数据的标准差差别很大
samples,target= datasets.make_blobs(n_features=2,n_samples=150,centers=3, cluster_std=[0.5,2,10])- 1
- 2
plt.scatter(samples[:,0],samples[:,1],c=target)- 1
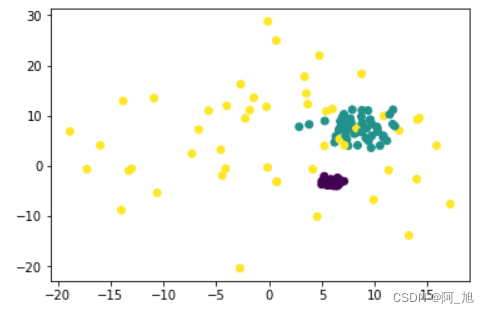
km = KMeans(n_clusters=3)- 1
y_ = km.fit_predict(samples)- 1
plt.scatter(samples[:,0],samples[:,1],c=y_)- 1
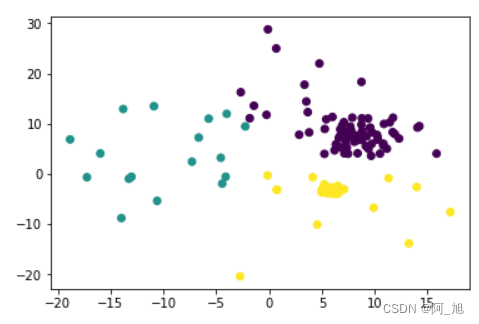
metrics.adjusted_rand_score(y_,target)- 1
0.530328438685834- 1
metrics.silhouette_score(samples,km.labels_)- 1
0.5932400629187524- 1
4、样本量差别很大
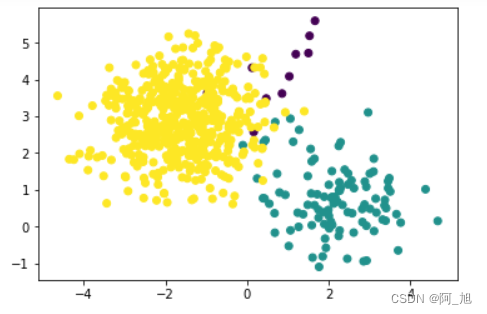
samples,target = datasets.make_blobs(n_samples=1500,n_features=2,centers=3,random_state=0)- 1
train1 = samples[target==0][:10] train2 = samples[target==1][:100] train3 = samples[target==2][:500] train = np.concatenate([train1,train2,train3])- 1
- 2
- 3
- 4
# 用train作为训练数据 train.shape- 1
- 2
(610, 2)- 1
# 生成标签 target = [0]*10 + [1]*100 + [2]*500- 1
- 2
plt.scatter(train[:,0],train[:,1],c=target)- 1
km = KMeans(n_clusters=3)- 1
y_ = km.fit_predict(train)- 1
plt.scatter(train[:,0],train[:,1],c=y_)- 1
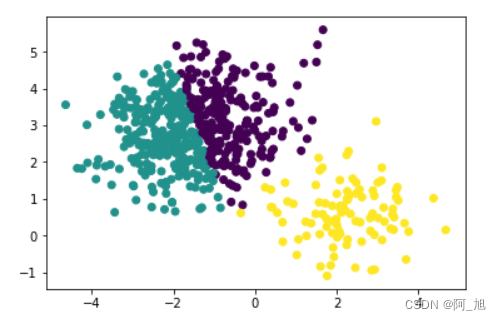
metrics.adjusted_rand_score(y_,target)- 1
0.3479149392627809- 1
metrics.silhouette_score(train,km.labels_)- 1
0.35994070955867- 1
如果内容对你有帮助,感谢记得点赞+关注哦!
更多干货内容持续更新中…
-
相关阅读:
XML配置文件解析与建模
maven的安装和使用
从NetSuite Payment Link杂谈财务自动化、数字化转型
Android的View绑定实现----编译时注解实现findViewById和setOnClickListener方式
FOXBORO FBM233 P0926GX控制脉冲模块
【Java】记录一次使用 Springboot + Liquibase 做数据库的变更同步、回滚
消息队列一文全解!!!
攻防世界数据逆向 2023
java调用科大讯飞离线语音合成SDK --内附完整项目
《10人以下小团队管理手册》推荐书评
- 原文地址:https://blog.csdn.net/qq_42589613/article/details/127670988