-
【阿旭机器学习实战】【12】决策树基本原理及其构造与使用方法
【阿旭机器学习实战】系列文章主要介绍机器学习的各种算法模型及其实战案例,欢迎点赞,关注共同学习交流。
本文对机器学习中的
决策树基本原理及其构造与使用方法。决策树
【关键词】树,信息增益,信息熵
决策树的优缺点
优点:
计算复杂度不高,输出结果易于理解,对中间值的缺失不敏感,可以处理不相关特征数据;
既能用于分类,也能用于回归;
数据形式非常容易理解。缺点:可能会产生过度匹配问题
一、决策树的原理
一个决策树的游戏:【二十个问题的游戏】
游戏的规则很简单:参与游戏的一方在脑海里想某个事物,其他参与者向他提问题,只允许提20个问题,问题的答案也只能用对或错回答。问问题的人通过推断分解,逐步缩小待猜测事物的范围。决策树的工作原理与20个问题类似,用户输入一系列数据 ,然后给出游戏的答案。
我们经常使用决策树处理分类问题。近来的调查表明决策树也是最经常使用的数据挖掘算法。它之所以如此流行,一个很重要的原因就是使用者基本上不用了解机器学习算法,也不用深究它是如何工作的。
使用决策树找对象示例
如果以前没有接触过决策树,完全不用担心,它的概念非常简单。即使不知道它也可以通过简单的图形了解其工作原理。
决策树分类的思想类似于找对象。现想象一个女孩的母亲要给这个女孩介绍男朋友,于是有了下面的对话:
女儿:多大年纪了? 母亲:26。 女儿:长的帅不帅? 母亲:挺帅的。 女儿:收入高不? 母亲:不算很高,中等情况。 女儿:是公务员不? 母亲:是,在税务局上班呢。 女儿:那好,我去见见。- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
这个女孩的决策过程就是典型的分类树决策。相当于通过年龄、长相、收入和是否公务员对将男人分为两个类别:见和不见。假设这个女孩对男人的要求是:30岁以下、长相中等以上并且是高收入者或中等以上收入的公务员,那么这个可以用下图表示女孩的决策逻辑:
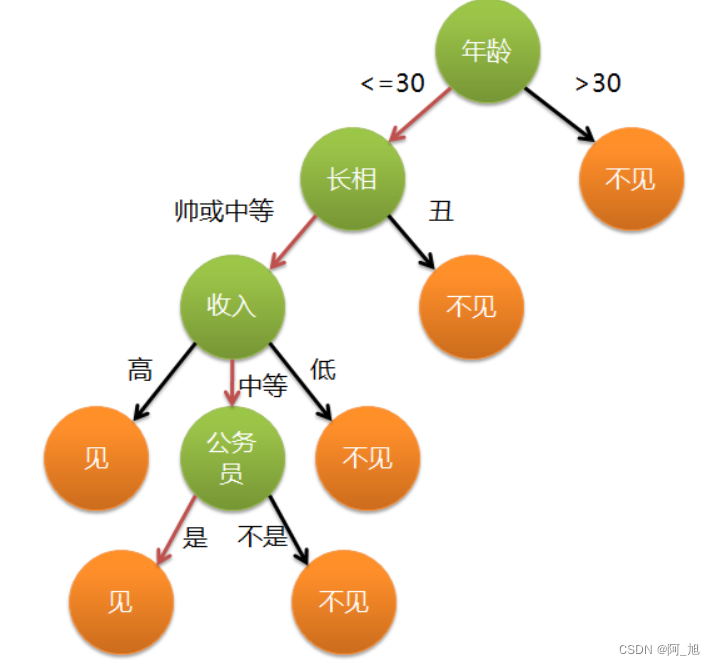
上图完整表达了这个女孩决定是否见一个约会对象的策略,其中绿色节点表示判断条件,橙色节点表示决策结果,箭头表示在一个判断条件在不同情况下的决策路径,图中红色箭头表示了上面例子中女孩的决策过程。
这幅图基本可以算是一颗决策树,说它“基本可以算”是因为图中的判定条件没有量化,如收入高中低等等,还不能算是严格意义上的决策树,如果将所有条件量化,则就变成真正的决策树了。
决策树定义
决策树(decision tree)是一个树结构(可以是二叉树或非二叉树)。
其每个非叶节点表示一个特征属性上的测试,每个分支代表这个特征属性在某个值域上的输出,而每个叶节点存放一个类别。使用决策树进行决策的过程就是从根节点开始,测试待分类项中相应的特征属性,并按照其值选择输出分支,直到到达叶子节点,将叶子节点存放的类别作为决策结果。可以看到,决策树的决策过程非常直观,容易被人理解。目前决策树已经成功运用于医学、制造产业、天文学、分支生物学以及商业等诸多领域。
决策树算法能够读取数据集合,构建类似于上面的决策树。决策树很多任务都是为了数据中所蕴含的知识信息,因此决策树可以使用不熟悉的数据集合,并从中提取出一系列规则,机器学习算法最终将使用这些机器从数据集中创造的规则。专家系统中经常使用决策树,而且决策树给出结果往往可以匹敌在当前领域具有几十年工作经验的人类专家。
知道了决策树的定义以及其应用方法,下面介绍决策树的构造算法。
二、决策树的构造
分类解决离散问题,回归解决连续问题
- 决策树:信息论
- 逻辑斯蒂回归、贝叶斯:概率论
决策树构造过程
不同于逻辑斯蒂回归和贝叶斯算法,决策树的构造过程不依赖领域知识,它使用属性选择度量来选择将元组最好地划分成不同的类的属性。
所谓决策树的构造就是进行属性选择度量确定各个特征属性之间的拓扑结构。构造决策树的关键步骤是分裂属性。所谓分裂属性就是在某个节点处按照某一特征属性的不同划分构造不同的分支,其目标是让各个分裂子集尽可能地“纯”。尽可能“纯”就是尽量让一个分裂子集中待分类项属于同一类别。分裂属性分为三种不同的情况:
1、属性是离散值且不要求生成二叉决策树。此时用属性的每一个划分作为一个分支。 2、属性是离散值且要求生成二叉决策树。此时使用属性划分的一个子集进行测试,按照“属于此子集”和“不属于此子集”分成两个分支。 3、属性是连续值。此时确定一个值作为分裂点split_point,按照>split_point和<=split_point生成两个分支。- 1
- 2
- 3
- 4
- 5
构造决策树的关键性内容是进行属性选择度量,属性选择度量是一种选择分裂准则,它决定了拓扑结构及分裂点split_point的选择。属性选择度量算法有很多,一般使用自顶向下递归分治法,并采用不回溯的贪心策略。这里介绍常用的ID3算法。
ID3算法
划分数据集的大原则是:
将无序的数据变得更加有序。我们可以使用多种方法划分数据集,但是每种方法都有各自的优缺点。组织杂乱无章数据的一种方法就是使用信息论度量信息,信息论是量化处理信息的分支科学。我们可以在划分数据之前使用信息论量化度量信息的内容。
在划分数据集之前之后信息发生的变化称为信息增益,知道如何计算信息增益,我们就可以计算每个特征值划分数据集获得的信息增益,获得信息增益最高的特征就是最好的选择。
在可以评测哪种数据划分方式是最好的数据划分之前,我们必须学习如何计算信息增益。集合信息的度量方式称为香农熵或者简称为熵,这个名字来源于信息论之父克劳德•香农。
熵entropy与信息增益
熵定义为信息的期望值,在明晰这个概念之前,我们必须知道信息的定义。如果待分类的事务可能划分在多个分类之中,则符号x的信息定义为:
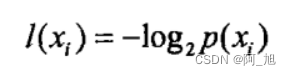
其中p(x)是选择该分类的概率
为了计算熵,我们需要计算所有类别所有可能值包含的信息期望值,通过下面的公式得到:
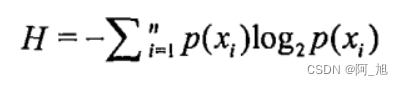
其中n是分类的数目。
在决策树当中,设D为用类别对训练元组进行的划分,则D的熵(entropy)表示为:
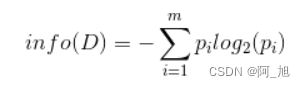
其中pi表示第i个类别在整个训练元组中出现的概率,可以用属于此类别元素的数量除以训练元组元素总数量作为估计。熵的实际意义表示是D中元组的类标号所需要的平均信息量。
现在我们假设将训练元组D按属性A进行划分,则A对D划分的期望信息为:
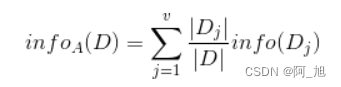
而信息增益即为两者的差值:
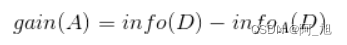
ID3算法就是在每次需要分裂时,计算每个属性的增益率,然后选择增益率最大的属性进行分裂。下面我们继续用SNS社区中不真实账号检测的例子说明如何使用ID3算法构造决策树。为了简单起见,我们假设训练集合包含10个元素: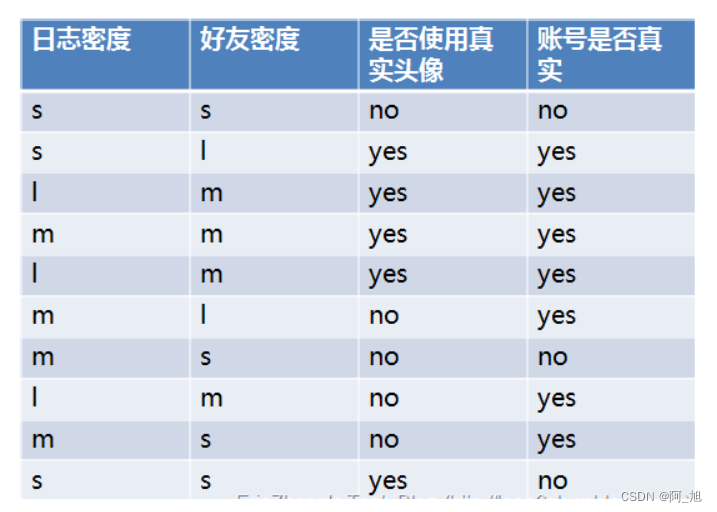
其中s、m和l分别表示小、中和大。
设L、F和H表示日志密度、好友密度、是否使用真实头像,下面计算各属性的信息增益。
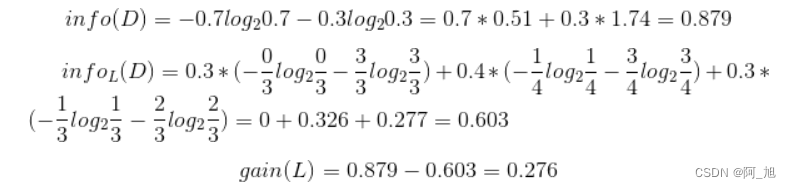
因此
日志密度的信息增益是0.276。用同样方法得到
F和H的信息增益分别为0.553和0.033。因为
F具有最大的信息增益,所以第一次分裂选择F为分裂属性,分裂后的结果如下图表示: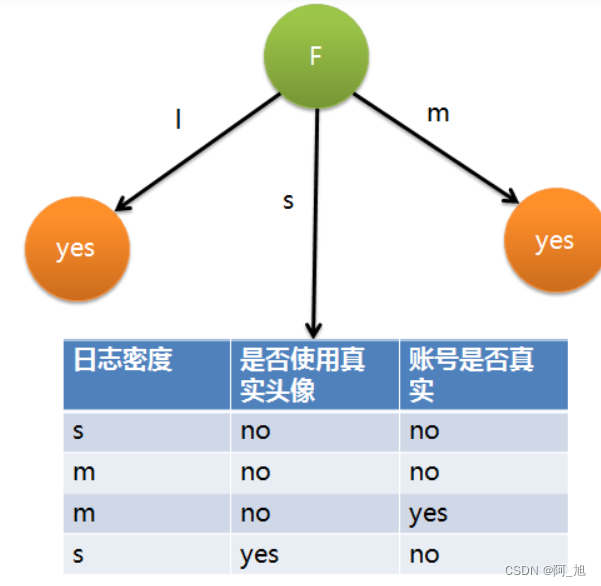
在上图的基础上,再递归使用这个方法计算子节点的分裂属性,最终就可以得到整个决策树。
练习—计算第二层决策树节点
计算上图的第二层节点的信息熵,确定下一个分类的特征
import numpy as np- 1
info_D = 0.75*(-np.log2(0.75) ) + 0.25*(-np.log2(0.25)) info_D- 1
- 2
0.8112781244591328- 1
# L--日志密度 ; H--是否使用真实头像 info_D_L = 0.5 * (-np.log2(1)) + 0.5 * (-0.5*np.log2(0.5) - 0.5*np.log2(0.5)) info_D_L- 1
- 2
- 3
0.5- 1
# L--日志密度 ; H--是否使用真实头像 info_D_H = 0.75 * (-2/3*np.log2(2/3)-1/3*np.log2(1/3)) + 0.25 * (-1*np.log2(1)) info_D_H- 1
- 2
- 3
0.6887218755408672- 1
print(info_D - info_D_L) print(info_D - info_D_H)- 1
- 2
0.31127812445913283 0.12255624891826566- 1
- 2
因为L具有最大的信息增益,所以第二次分裂选择L为分裂属性.
三、决策树实战—iris数据集
from sklearn import datasets- 1
iris = datasets.load_iris()- 1
data = iris.data target = iris.target- 1
- 2
from sklearn.model_selection import train_test_split- 1
x_train,x_test,y_train,y_test = train_test_split(data,target,test_size=0.2)- 1
# 导入决策树分类器 from sklearn.tree import DecisionTreeClassifier- 1
- 2
# max_depth表示最大深度 dt = DecisionTreeClassifier(max_depth=5)- 1
- 2
# 训练模型 dt.fit(x_train,y_train)- 1
- 2
dt.score(x_test,y_test)- 1
1.0- 1
如果内容对你有帮助,感谢记得点赞+关注哦!
欢迎关注我的公众号:
阿旭算法与机器学习,共同学习交流。
更多干货内容持续更新中… -
相关阅读:
Log4j 漏洞引发全球修补漏洞行动;KeePassX 停止开发;.NET 6 网络改进 | 开源日报
Web开发-新建Spring Boot项目
80、【backtrader基金策略】实现上证50ETF和创业板ETF轮动交易策略(2022-07-17更新)
docker中安装RabbitMQ(DelayExchange)插件
Pro2:修改div块的颜色
棋盘格测距-单目相机(OpenCV/C++)
【Learing from data】2.1.2 Bounding the Growth Function 第47页
企业架构LNMP学习笔记44
高等数学第七章微分方程
java栈和自定义栈
- 原文地址:https://blog.csdn.net/qq_42589613/article/details/127653130
