-
CSP-J 2022 入门组/普及组
T1 乘方
【题目描述】
小文同学刚刚接触了信息学竞赛,有一天她遇到了这样一个题:给定正整数 a a a 和 b b b,求 a b a^b ab 的值是多少。
a b a^b ab 即 b b b 个 a a a 相乘的值,例如 2 3 2^3 23 即为 3 3 3 个 2 2 2 相乘,结果为 2 × 2 × 2 = 8 2 \times 2 \times 2 = 8 2×2×2=8
“简单!”小文心想,同时很快就写出了一份程序,可是测试时却出现了错误。
小文很快意识到,她的程序里的变量都是int类型的。在大多数机器上,int类型能表示的最大数为 2 31 − 1 2^{31} - 1 231−1,因此只要计算结果超过这个数,她的程序就会出现错误。由于小文刚刚学会编程,她担心使用
int计算会出现问题。因此她希望你在 a b a^b ab 的值超过 10 9 {10}^9 109 时,输出一个-1进行警示,否则就输出正确的 a b a^b ab 的值。然而小文还是不知道怎么实现这份程序,因此她想请你帮忙。
【输入格式】
输入共一行,两个正整数 a , b a, b a,b。【输出格式】
输出共一行,如果 a b a^b ab 的值不超过 10 9 {10}^9 109 ,则输出 a b a^b ab 的值,否则输出-1。【输入输出样例】
输入 #110 9- 1
输出 #1
1000000000- 1
输入 #2
23333 66666- 1
输出 #2
-1- 1
【数据范围】
对于 10 % 10 \% 10% 的数据,保证 b = 1 b = 1 b=1。
对于 30 % 30 \% 30% 的数据,保证 b ≤ 2 b \le 2 b≤2。
对于 60 % 60 \% 60% 的数据,保证 b ≤ 30 , a b ≤ 10 18 b \le 30,a^b \le {10}^{18} b≤30,ab≤1018
对于 100 % 100 \% 100% 的数据,保证 1 ≤ a , b ≤ 10 9 1 \le a, b \le {10}^9 1≤a,b≤109T1分析
乍一看可能会以为需要快速幂,但是题目说如果超过 1 0 9 10^9 109 就直接
-1,那么最小的非 1 1 1 正整数是 2 2 2,显然 2 3 0 2^30 230 就已经超过 1 0 9 10^9 109 了,所以其实直接暴力循环也不会超过 30 30 30 次,直接循环即可,超过 1 0 9 10^9 109 就输出-1然后 b r e a k break break仅有的坑点就是注意特判一下 a = 1 a = 1 a=1 的情况
#include#include using namespace std; int main(){ long long a, b; cin >> a >> b; long long number = 1; if (a == 1){ b = 1; } for (int i = 0; i < b; ++i){ number *= a; if (number > 1000000000){ number = -1; break; } } cout << number << endl; return 0; } - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
T2 解密
【题目描述】
给定一个正整数 k k k,有 k k k 次询问,每次给定三个正整数 n i , e i , d i n_i, e_i, d_i ni,ei,di ,求两个正整数 p i , q i p_i, q_i pi,qi ,使 n i = p i × q i n_i = p_i \times q_i ni=pi×qi 、 e i × d i = ( p i − 1 ) ( q i − 1 ) + 1 e_i \times d_i = (p_i - 1)(q_i - 1) + 1 ei×di=(pi−1)(qi−1)+1【输入格式】
第一行一个正整数 k k k,表示有 k k k 次询问。接下来 k k k 行,第 i i i 行三个正整数 n i , d i , e i n_i, d_i, e_i ni,di,ei
【输出格式】
输出 k k k 行,每行两个正整数 p i , q i p_i, q_i pi,qi 表示答案。为使输出统一,你应当保证 p i ≤ q i p_i \leq q_i pi≤qi,如果无解,请输出
NO。【输入输出样例】
输入 #110 770 77 5 633 1 211 545 1 499 683 3 227 858 3 257 723 37 13 572 26 11 867 17 17 829 3 263 528 4 109- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
输出 #1
2 385 NO NO NO 11 78 3 241 2 286 NO NO 6 88- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
【数据范围】

T2分析
很多同学不会做这道题,不知道该如何思考,这里就要提到,很多时候要注意仔细观察数据范围
数据范围里的很多限制不会凭空给出来的
比如这道题的数据范围中存在一个 m = n − e ∗ d + 2 m = n - e * d + 2 m=n−e∗d+2 这个限制,那如果你的计算过程中没有碰到这个,显然就是计算出错了,同时这其实也是在提示你怎么做了…显然就是要你尝试去解方程
先把题目中给出的 e ∗ d = ( p − 1 ) ( q − 1 ) + 1 e * d = (p - 1)(q-1) + 1 e∗d=(p−1)(q−1)+1 展开
可以得到 e ∗ d = p ∗ q − p − q + 1 e * d = p * q - p - q + 1 e∗d=p∗q−p−q+1
代入 n = p ∗ q n = p * q n=p∗q 可以得到 e ∗ d = n − p − q + 1 e * d = n - p - q + 1 e∗d=n−p−q+1
左右移项可以得到 p + q = n − e ∗ d + 2 p + q = n - e * d + 2 p+q=n−e∗d+2,如果计算到这一步,就可以发现数据范围里的这个式子不是凭空给出的了
记 m = n − e ∗ d + 2 m = n - e * d + 2 m=n−e∗d+2
那么总结上式可以得到一个方程组
p + q = m p + q = m p+q=m
p ∗ q = n p * q = n p∗q=n
这是一个经典的高中数学题,现在我们需要解这个方程
( p + q ) 2 = p 2 + q 2 + 2 ∗ p ∗ q (p + q)^2 = p^2 + q^2 + 2 * p * q (p+q)2=p2+q2+2∗p∗q
( p + q ) 2 − 4 ∗ p ∗ q = p 2 + q 2 + 2 ∗ p ∗ q − 4 ∗ p ∗ q = p 2 + q 2 − 2 ∗ p ∗ q = ( p − q ) 2 (p + q)^2 - 4 * p * q = p^2 + q^2 + 2 * p * q - 4 * p * q = p^2 + q^2 - 2 * p * q = (p - q)^2 (p+q)2−4∗p∗q=p2+q2+2∗p∗q−4∗p∗q=p2+q2−2∗p∗q=(p−q)2
那么可以得到 ( p − q ) 2 = m 2 − 4 ∗ n (p-q)^2 = m^2 - 4 * n (p−q)2=m2−4∗n
记 d e l = m 2 − 4 ∗ n del = m^2 - 4 * n del=m2−4∗n
可以得到 d d = s q r t ( d e l ) dd= sqrt(del) dd=sqrt(del),首先这里要有一个正整数解,那么必须要保证 d e l del del 开方后是整数,否则无解
如果有解则可以得到
p + q = m p + q = m p+q=m
p − q = d d p - q = dd p−q=dd
那么很容易得到 2 ∗ p = m + d d 2*p=m + dd 2∗p=m+dd 则 p = ( m + d d ) / 2 p = (m + dd) / 2 p=(m+dd)/2, q = m − p q = m - p q=m−p
最后输出注意判断一下 p p p 和 q q q 的大小关系即可#include#include #include using namespace std; int main(){ int T;scanf("%d", &T); while(T--){ long long n, e, d; scanf("%lld%lld%lld", &n, &e, &d); long long m = n - e * d + 2; long long del = m * m - 4 * n; long long dd = sqrt(del); if (dd * dd != del){ printf("NO\n"); continue; } long long p = (m + dd) / 2; long long q = m - p; if (p > q){ swap(p, q); } printf("%lld %lld\n", p, q); } return 0; } - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
T3 逻辑表达式
【题目描述】
逻辑表达式是计算机科学中的重要概念和工具,包含逻辑值、逻辑运算、逻辑运算优先级等内容。在一个逻辑表达式中,元素的值只有两种可能: 0 0 0(表示假)和 1 1 1(表示真)。元素之间有多种可能的逻辑运算,本题中只需考虑如下两种:“与”(符号为
&)和“或”(符号为|)。其运算规则如下:0 & 0 = 0 & 1 = 1 & 0 = 0 , 1 & 1 = 1 0 \& 0 = 0 \& 1 = 1 \& 0 = 0,1 \& 1 = 1 0&0=0&1=1&0=0,1&1=1
0 ∣ 0 = 0 , 0 ∣ 1 = 1 ∣ 0 = 1 ∣ 1 = 1 0 | 0 = 0, 0 | 1 = 1|0=1|1=1 0∣0=0,0∣1=1∣0=1∣1=1在一个逻辑表达式中还可能有括号。规定在运算时,括号内的部分先运算;两种运算并列时,
&运算优先于|运算;同种运算并列时,从左向右运算。比如,表达式
0|1&0的运算顺序等同于0|(1&0);表达式0&1&0|1的运算顺序等同于((0&1)&0)|1。此外,在 C++ 等语言的有些编译器中,对逻辑表达式的计算会采用一种“短路”的策略:在形如
a&b的逻辑表达式中,会先计算a部分的值,如果 a = 0 a = 0 a=0,那么整个逻辑表达式的值就一定为 0 0 0,故无需再计算b部分的值;同理,在形如a|b的逻辑表达式中,会先计算a部分的值,如果 a = 1 a = 1 a=1,那么整个逻辑表达式的值就一定为 1 1 1,无需再计算b部分的值。现在给你一个逻辑表达式,你需要计算出它的值,并且统计出在计算过程中,两种类型的“短路”各出现了多少次。需要注意的是,如果某处“短路”包含在更外层被“短路”的部分内则不被统计,如表达式
1|(0&1)中,尽管0&1是一处“短路”,但由于外层的1|(0&1)本身就是一处“短路”,无需再计算0&1部分的值,因此不应当把这里的0&1计入一处“短路”。【输入格式】
输入共一行,一个非空字符串 s s s 表示待计算的逻辑表达式。【输出格式】
输出共两行,第一行输出一个字符0或1,表示这个逻辑表达式的值;第二行输出两个非负整数,分别表示计算上述逻辑表达式的过程中,形如a&b和a|b的“短路”各出现了多少次。【输入输出样例】
输入 #10&(1|0)|(1|1|1&0)- 1
输出 #1
1 1 2- 1
- 2
输入 #2
(0|1&0|1|1|(1|1))&(0&1&(1|0)|0|1|0)&0- 1
输出 #2
0 2 3- 1
- 2
【说明/提示】
【样例解释 #1】该逻辑表达式的计算过程如下,每一行的注释表示上一行计算的过程:
0&(1|0)|(1|1|1&0) =(0&(1|0))|((1|1)|(1&0)) //用括号标明计算顺序 =0|((1|1)|(1&0)) //先计算最左侧的 &,是一次形如 a&b 的“短路” =0|(1|(1&0)) //再计算中间的 |,是一次形如 a|b 的“短路” =0|1 //再计算中间的 |,是一次形如 a|b 的“短路” =1- 1
- 2
- 3
- 4
- 5
- 6
【数据范围】
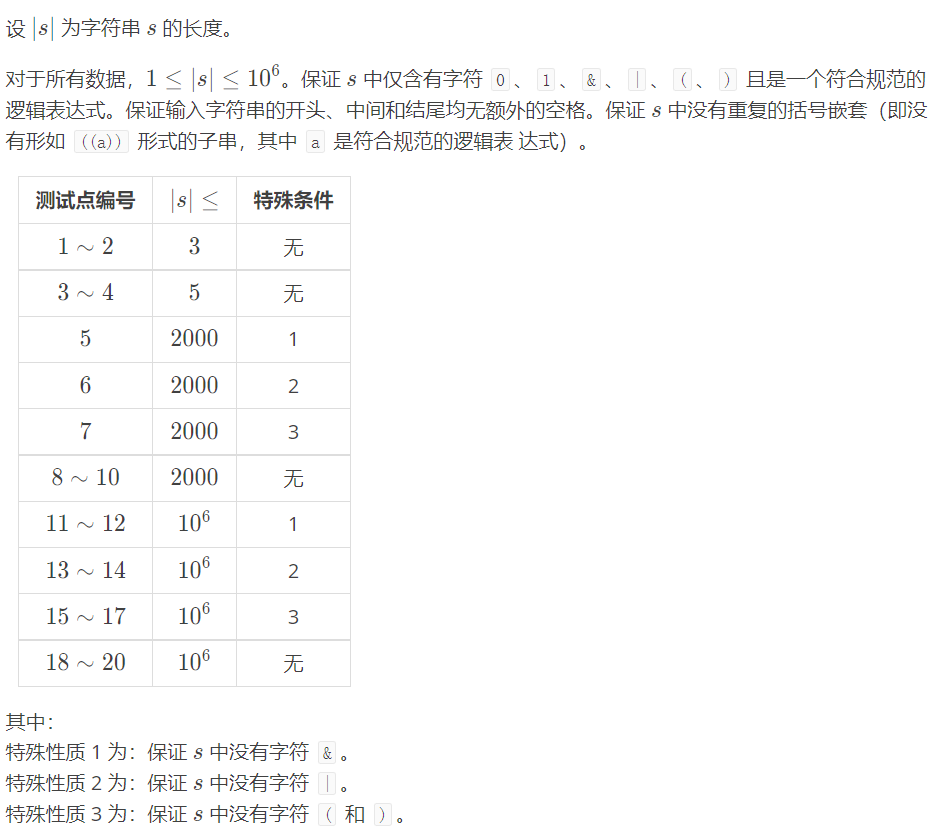
T3分析
一看题目就知道是个模拟题,如果在比赛时先花大量时间在这道题上,很有可能导致来不及做第四题,但是其实第四题更加好写,那么这里也是要注意比赛策略,在比赛开始1小时左右应该已经将四道题目都大致看过并且心里给出一个大致的难度,排好序去做题
当然,这道题虽然是个模拟题,但是本身难度并不算特别高
一看就可以发现就是一道表达是求值的题目,而且相对于表达式求值来说,难度也不算高,因为这道题的数字只有 0 0 0 和 1 1 1,那么难点在于除了计算答案,题目还要求计算短路的次数
带着表达式求值的思路去思考,很容易想到最基础的做法就是两个栈,一个op记录操作,一个number记录数字
根据优先级求解即可,大致步骤如下:- 碰到左括号,直接入栈
- 碰到右括号,一直弹出 o p . t o p ( ) op.top() op.top() 进行计算直到碰到左括号
- 碰到
&,因为&的优先级比|高,所以如果 o p . t o p ( ) op.top() op.top() 也是&则先处理栈顶的&,然后将&入栈 - 碰到
|,因为|优先级比&低,所以需要处理栈顶所有的运算符,直到碰到左括号或者栈为空 - 碰到数字,直接入栈
- 最后处理栈中剩余的操作
这种方式能算出答案,很难在计算过程中统计
短路次数,所以这道题可以考虑直接把表达式树给建出来
在进行操作的时候同时建树即可,即每一个计算操作对应到左右两边的计算,也就是一个节点对应到左右子树,那么如果左子树短路,则忽略右子树的计算即可这道题没什么大坑,注意处理细节即可
#includeusing namespace std; char s[1000100], a[1000100]; stack<char> op; stack<int> number; int cnt, ans, ans1, ans2; int G[1000100][2]; void work(){ a[cnt] = op.top(); op.pop(); G[cnt][1] = number.top(); number.pop(); G[cnt][0] = number.top(); number.pop(); number.push(cnt++); } int dfs(int now){ if (a[now] == '1' || a[now] == '0'){ return a[now] - '0'; } if (a[now] == '&'){ if (dfs(G[now][0]) == 0){ ans1++; return 0; } return dfs(G[now][1]); } if (a[now] == '|'){ if (dfs(G[now][0]) == 1){ ans2++; return 1; } return dfs(G[now][1]); } } int main(){ scanf("%s", s); for (int i = 0; s[i] != '\0'; ++i){ if (s[i] == '('){ op.push('('); } else if (s[i] == ')'){ while (op.top() != '('){ work(); } op.pop(); } else if (s[i] == '&'){ while (op.size() && op.top() == '&'){ work(); } op.push('&'); } else if (s[i] == '|'){ while (op.size() && op.top() != '('){ work(); } op.push('|'); } else { a[cnt] = s[i]; number.push(cnt++); } } while (op.size()){ work(); } ans = dfs(cnt - 1); printf("%d\n%d %d\n", ans, ans1, ans2); return 0; } - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
T4 上升点列
【题目描述】
在一个二维平面内,给定 n n n 个整数点 ( x i , y i ) (x_i, y_i) (xi,yi),此外你还可以自由添加 k k k 个整数点。你在自由添加 k k k 个点后,还需要从 n + k n + k n+k 个点中选出若干个整数点并组成一个序列,使得序列中任意相邻两点间的欧几里得距离恰好为 1 1 1 而且横坐标、纵坐标值均单调不减,即 x i + 1 − x i = 1 , y i + 1 = y i x_{i+1} - x_i = 1, y_{i+1} = y_i xi+1−xi=1,yi+1=yi 或 y i + 1 − y i = 1 , x i + 1 = x i y_{i+1} - y_i = 1, x_{i+1} = x_i yi+1−yi=1,xi+1=xi。请给出满足条件的序列的最大长度。
【输入格式】
第一行两个正整数 n , k n, k n,k 分别表示给定的整点个数、可自由添加的整点个数。接下来 n n n 行,第 i i i 行两个正整数 x i , y i x_i, y_i xi,yi 表示给定的第 ii 个点的横纵坐标。
【输出格式】
输出一个整数表示满足要求的序列的最大长度。【输入输出样例】
输入 #18 2 3 1 3 2 3 3 3 6 1 2 2 2 5 5 5 3- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
输出 #1
8- 1
输入 #2
4 100 10 10 15 25 20 20 30 30- 1
- 2
- 3
- 4
- 5
输出 #2
103- 1
【数据范围】
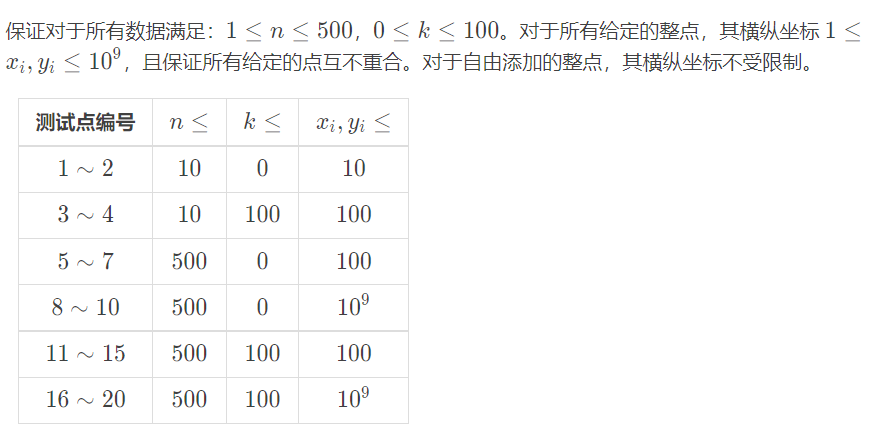
T4 分析
这种题目乍一看就能想到是 d p dp dp 或者二分,从哪个先开始考虑都没问题
思考二分最后会发现不知道该从何入手,如果是二分长度,那不知道起点,二分起点,那也没有意义
再配合数据范围只有 500 500 500,这种数据范围大概率就是 d p dp dp
那么来思考 d p dp dp
很容易想到 d p [ i ] [ k ] dp[i][k] dp[i][k] 表示到第 i i i 个节点,已经用掉了 k k k 个可添加点的最大长度
状态有了,转移应该也很容易想到,对于第 i i i 个节点,无非就是枚举其他节点 j j j,如果 i i i 在 j j j 的左下方即可进行转移,计算 d e l = a [ j ] . x − a [ i ] . x + a [ j ] . y − a [ i ] . y − 1 del = a[j].x - a[i].x + a[j].y - a[i].y - 1 del=a[j].x−a[i].x+a[j].y−a[i].y−1 即 i i i 到 j j j 需要使用 d e l del del 个可添加点
那么枚举 d p [ j ] [ k ] dp[j][k] dp[j][k],即可得到方程 d p [ i ] [ k + d e l ] = m a x ( d p [ j ] [ k ] + d e l + 1 ) dp[i][k + del] = max(dp[j][k] + del + 1) dp[i][k+del]=max(dp[j][k]+del+1)
最后答案即为 a n s = m a x ( d p [ i ] [ j ] + K − j ) ans = max(dp[i][j] + K - j) ans=max(dp[i][j]+K−j) 这里注意一个小细节,如果总共有 K K K 个可添加点,只用了 j j j 个,多出来的 K − j K - j K−j 个直接加在最后即可,不要忘记这个,不过这个坑在第二组 s a m p l e sample sample 里就给出来了,基本不会有人踩
检查一下复杂度,是 O ( n 2 K ) O(n^2K) O(n2K),显然没有问题这里可以做一个简单的优化,按照 x + y x + y x+y 从小到大排序,也就是我们斜着去枚举所有点,这样的话对于第 i i i 个点我们只要枚举 0 ∼ i − 1 0 \sim i-1 0∼i−1 就可以了,当然这个优化并不会使得复杂度发生变化,但是快肯定是会快一点
#include#include #include #include using namespace std; struct XX{ int x, y; }a[550]; bool cmp(const XX&x, const XX&y){ if (x.x + x.y != y.x + y.y){ return x.x + x.y < y.x + y.y; } } int dp[550][110]; int main(){ int n, m; scanf("%d%d", &n, &m); for (int i = 0; i < n; ++i){ scanf("%d%d", &a[i].x, &a[i].y); } sort(a, a + n, cmp); int ans = 0; for (int i = 0; i < n ; ++i){ for (int k = 0; k <= m; ++k){ dp[i][k] = 1; } for (int j = 0; j < i; ++j){ if (a[i].x >= a[j].x && a[i].y >= a[j].y){ int del = a[i].x - a[j].x + a[i].y - a[j].y - 1; for (int k = 0; k <= m - del; ++k){ dp[i][k + del] = max(dp[i][k + del], dp[j][k] + del + 1); ans = max(ans, dp[i][k + del] + m - k - del); } } } } printf("%d\n", ans); return 0; } - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
-
相关阅读:
【苹果家庭推送】群发安装软件命令的格式错误; 0xA2 : 无效参数
产品生命周期有哪些
Sprinig Boot优雅实现接口幂等性
腾讯云对象存储的在Java使用步骤介绍
SQL必需掌握的100个重要知识点:插入数据
【3D 图像分类】基于 Pytorch 的 3D 立体图像分类4(多人标注的结节立体框合并和特征等级投票)
常用hivesql记录
【操作系统】I/O 管理(一)—— I/O 管理概述
操作系统——并发相关问题
常用 时间类型的相互转化
- 原文地址:https://blog.csdn.net/jnxxhzz/article/details/127668931
