-
neo4j查询两节点之间所有路径/关系
目录
数据源

查询两节点有效的路径
路径长度(5个节点之内),一般都会做限制,否则数据库一但内容过多就会卡死
所有路径(不准确)
最容易想到的就是这样写,但是结果是不准确的。
- match p = (a)-[r*..5]-(b)
- where a.name = '刘备' and b.name='刘禅'
- return p

为什么不准确?
可以看到,刘禅与关羽、张飞、糜夫人、糜芳、糜竺 关系不是很大,因为他们是刘备的关系群
那为何还是能搜到呢?
因为我们设置了最大路径是5
因此张飞出现的原因就是这样的路径
- 刘备-张飞-刘备-刘禅
- 刘备-张飞-关羽-刘备-刘禅
可以看到,刘备(目标节点)在一条路径中出现了两次,所以导致一些不相关的节点出现了,其他节点(糜夫人、糜芳、糜竺)也是类似问题。
问题验证
我们可以把每条路径中的节点名称抽取出来看看
- match p = (a)-[r*..5]-(b)
- where a.name = '刘备' and b.name='刘禅'
- return extract(n in nodes(p)| n.name)
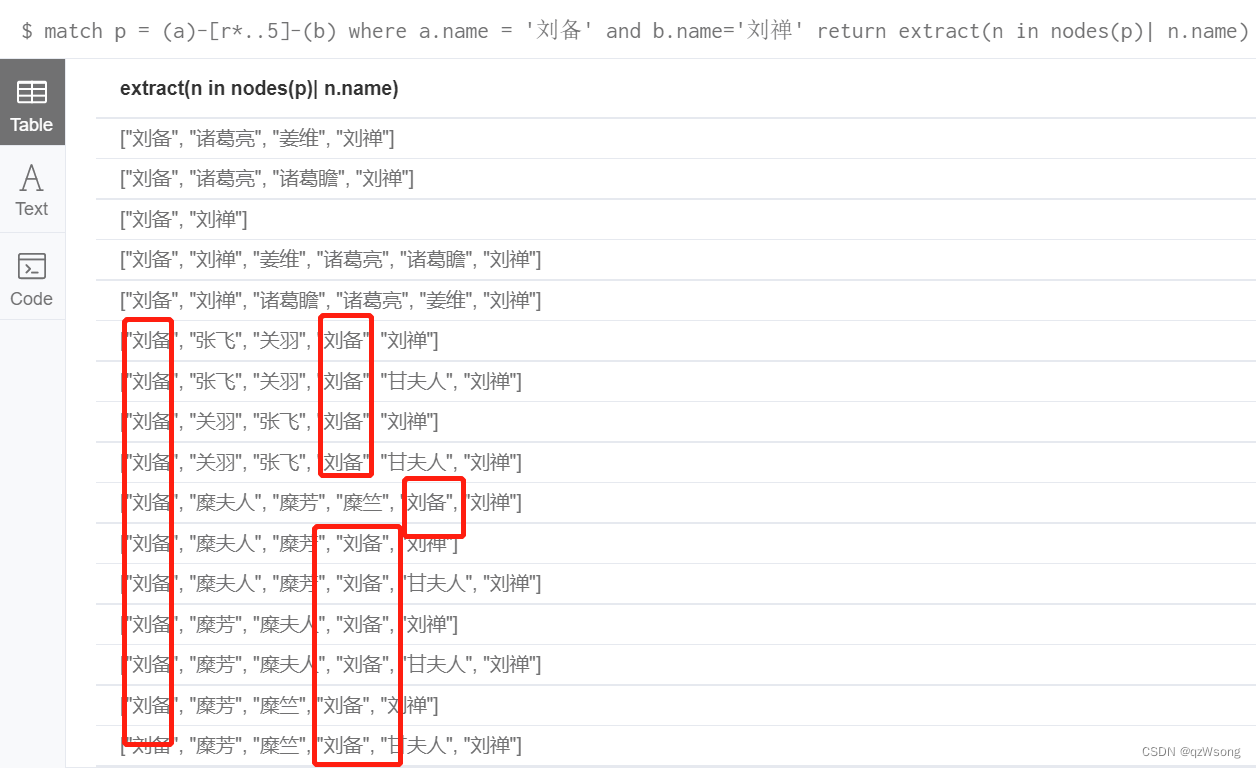
与我们想的结果一致
如何解决这个问题?
问题就是在一条路径(p)中,有重复人员的出现
那么解决方案就是,去掉路径(p)中有重复人员的路径(p)
- // 相当于遍历nodes, 每得到一个node就在nodes中找一下他自己有几个,如果不等于1就不要了
- and ALL( n1 in nodes(p) where size(filter(n2 in nodes(p) where id(n1) = id(n2)))=1 )
- // 新版本neo4j 不支持fliter函数 用[]代替
- and ALL( n1 in nodes(p) where size([n2 in nodes(p) where id(n1) = id(n2)])=1 )
有效路径(准确)
最终方案
- match p = (a)-[r*..5]-(b)
- where a.name = '刘备' and b.name='刘禅'
- and ALL( n1 in nodes(p) where size(filter(n2 in nodes(p) where id(n1) = id(n2)))=1 )
- return p
- // 新版
- match p = (a)-[r*..5]-(b)
- where a.name = '刘备' and b.name='刘禅'
- and ALL( n1 in nodes(p) where size([n2 in nodes(p) where id(n1) = id(n2)])=1 )
- return p


查询两节点之间最短路径
// TODO 还可以设置最短路径权重
- match p = shortestpath((a)-[r*0..4]-(b))
- where a.name = '刘备' and b.name='刘禅'
- return p
查询两节点之间所有的最短路径
最短路径如果不加权重的话,不如用所有最短路径,因为你没有规定最短路径的含义。
这个也经常用,但是如果梳理两个节点关系的时候 这样写会漏掉长的路径,导致结果不完全。
- match p = allshortestpaths((a)-[r*0..4]-(b))
- where a.name = '刘备' and b.name='刘禅'
- return p
-
相关阅读:
外包干了3个月,技术退步明显。。。。。
Qt——对话框简介
RPMBUILD 打包
SpringBoot中@ConfigurationProperties注解的常见使用(学习笔记)
nodejs+vue 网上招聘系统elementui
【CV学习笔记】tensorrtx-yolov5 逐行代码解析
Text2SQL之不装了,我也是RAG
【云服务器 ECS 实战】云服务器新手指南(配置+使用详解)
【思考总结】数列收敛和级数收敛的联系与区别【概念辨析】
正则表达式:整数
- 原文地址:https://blog.csdn.net/java_creatMylief/article/details/127664455