-
InfluxDB学习记录(二)——influxdb的关键概念
专业术语

关键概念
示例数据
下图所示为
从2015年8月18日午夜到2015年8月18日6时12分,两位科学家(langstroth和perpetua)在两个地点(location 1和location 2)分别计数得出的butterflies和honeybees的数量。
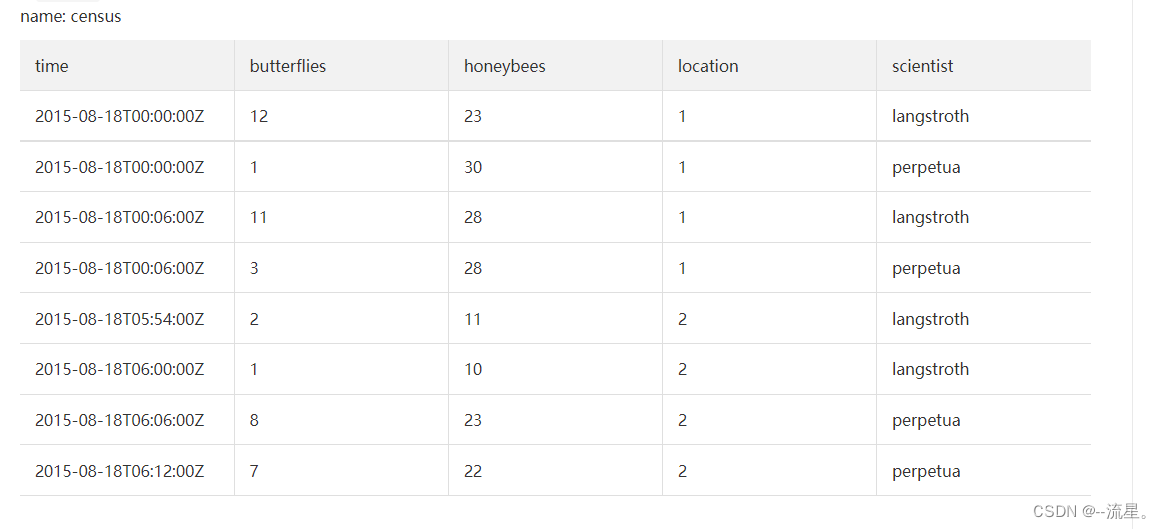
假设数据存储在名为my_database的数据(database),并受到数据保留策略(retention policy)autogen的约束。其中,census是measurement;time列中的是时间戳;butterflies和honeybees都是field key,butterflies列和honeybees列中的数据是field value,location和scientist都是tag key,location列和scientist列中的数据是tag value。
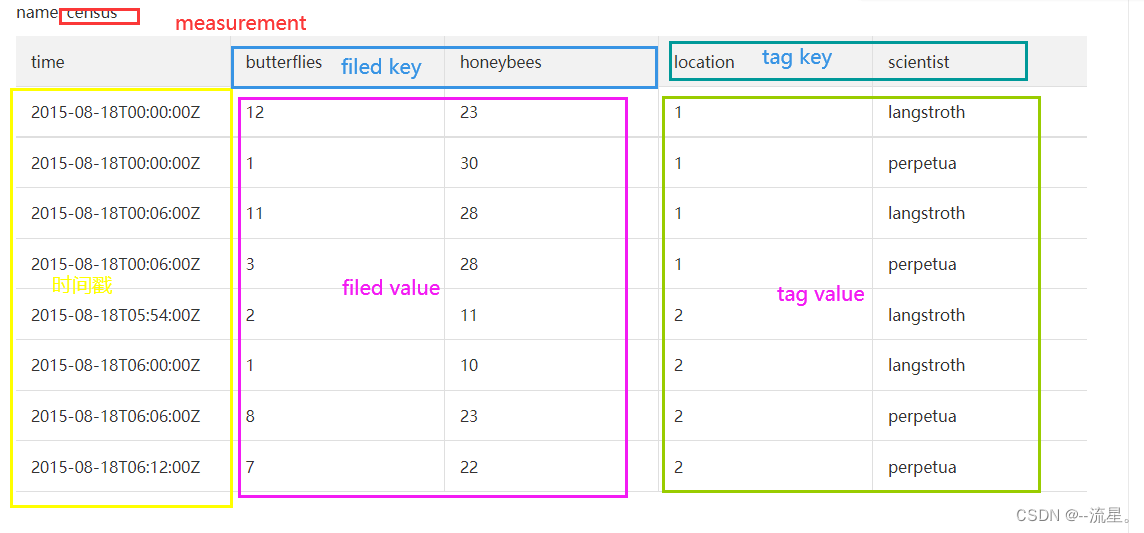
分析数据
-
time存储着时间戳,并且时间戳是以RFC3339 UTC格式展示与特定数据相关联的日期和时间。
-
field由field key和field value组成
-
- 其中,field key(butterflies和honeybees)是字符串,field key butterflies告诉我们蝴蝶的数量:从12到7,而field key honeybees告诉我们蜜蜂的数量:从23到22。
-
- field value是数据,它们可以是字符串、浮点数、整数或者布尔值。
-
field key-value对的集合组成一个field set

- field是InfluxDB数据结构中必要部分之一,在InfluxDB中不能没有field。
- field是没有索引的。如果使用field value作为过滤条件来进行查询,那么必须扫描完所有数据,才能找到与查询中的其它条件也都匹配的所有结果(相对于用tag作为过滤条件的查询来说,那些用field value作为过滤条件的查询性能会低很多)。
- 一般来说,field不应该包含经常被查询的元数据(metadata)。
-
tag由tag key和tag value组成。tag key和tag value都是字符串,并记录元数据。
-
- 示例数据中的tag key是location和scientist,
-
- 其中,location有两个tag value:1和2,scientist也有两个tag value:langstroth和perpetua。
-
tag set是所有tag key-value对的不同组合。

- 在InfluxDB中,tag不是必须要有的字段,不需要一定在数据结构中添加tag。
- 但是,tag是被索引的,这意味着以tag作为过滤条件的查询会更快,所以tag非常适合存储经常被查询的元数据。
InfluxDB自动创建autogen这个保留策略,它具有无限的存储时间并且复制系数设为1。
在InfluxDB中,序列(series)是有共同的保留策略、measurement和tag set的数据的集合。
以上示例数据中的共有4个序列:
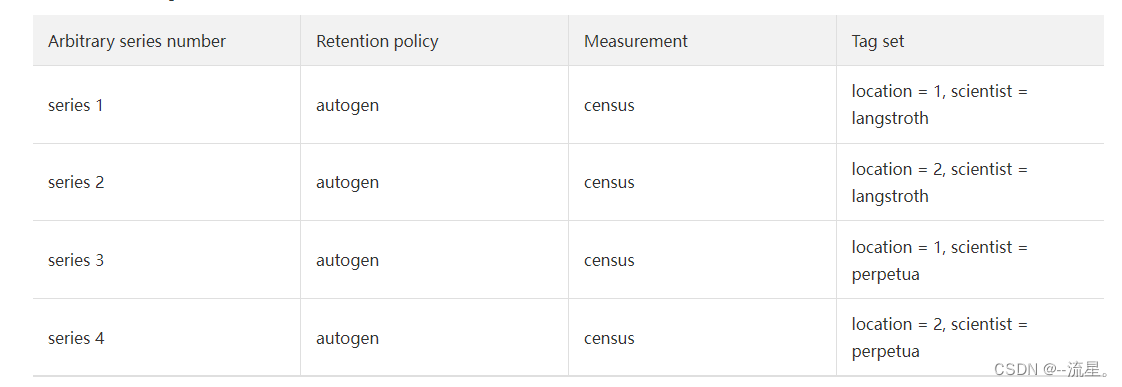
数据点(point)就是在相同序列里,具有相同时间戳的field set。

- InfluxDB数据库与传统数据库类似,并且作为用户、保留策略、连续查询和时序数据的逻辑容器。
- 数据库可以有多个用户、连续查询、保留策略和measurement。
- InfluxDB是一个schemaless(无模式)数据库,意味着随时可以轻松地添加新的measurement、tag和field。
- InfluxDB的设计宗旨就是能够很好地处理时序数据。
扩展
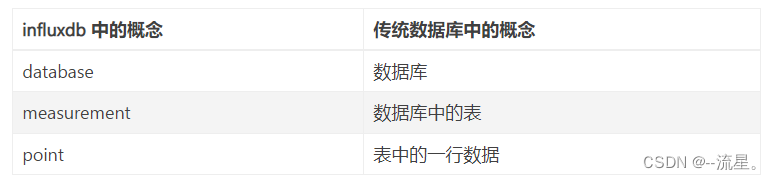
与传统数据库的对比
Shard
- Shard 在 influxdb中是一个比较重要的概念,它和 retention policy 相关联。
- 每一个存储策略下会存在许多shard,每一个 shard 存储一个指定时间段内的数据,并且不重复,例如 7点-8点 的数据落入 shard0中,8点-9点的数据则落入 shard1 中。
- 每一个 shard 都对应一个底层的 tsm 存储引擎,有独立的 cache、wal、tsm file。
这样做的目的就是为了可以通过时间来快速定位到要查询数据的相关资源,加速查询的过程,并且也让之后的批量删除数据的操作变得非常简单且高效。
存储引擎(Timestamp-Structure Merge Tree)
TSM是在LSM的基础上优化改善的,引入了serieskey的概念,对数据实现了很好的分类组织。 TSM主要由四个部分组成:cache、wal、tsm file、compactor:
- cache:插入数据时,先往 cache 中写入再写入wal中,可以认为 cache 是 wal 文件中的数据在内存中的缓存,cache 中的数据并不是无限增长的,有一个 maxSize 参数用于控制当 cache 中的数据占用多少内存后就会将数据写入 tsm
文件。如果不配置的话,默认上限为 25MB - wal:预写日志,对比MySQL的 binlog,其内容与内存中的 cache
相同,作用就是为了持久化数据,当系统崩溃后可以通过 wal 文件恢复还没有写入到 tsm 文件中的数据,当 InfluxDB 启动时,会遍历所有的 wal 文件,重新构造 cache。 - tsm file:每个 tsm 文件的大小上限是 2GB。当达到 cache-snapshot-memory-size,cache-max-memory-size 的限制时会触发将 cache 写入 tsm文件。
- compactor:主要进行两种操作,一种是 cache 数据达到阀值后,进行快照,生成一个新的 tsm文件。另外一种就是合并当前的 tsm 文件,将多个小的 tsm 文件合并成一个,减少文件的数量,并且进行一些数据删除操作。
这些操作都在后台自动完成,一般每隔 1 秒会检查一次是否有需要压缩合并的数据
存储目录
influxdb的数据存储有三个目录,分别是meta、wal、data:
- meta 用于存储数据库的一些元数据,meta 目录下有一个 meta.db 文件;
- wal 目录存放预写日志文件,以 .wal 结尾;
- data 目录存放实际存储的数据文件,以 .tsm 结尾。
附:参考资料
1、关键概念
2、influxdb基础(三)——influxdb按时间分片存储数据(shard和shard group)
3、InfluxDB 入门 -
-
相关阅读:
【重要!!】CSDN博客停止更新, 迁移至自建博客
最佳镜像搬运工 Skopeo 指南
毫米波雷达基础知识系列——FFT
图形库实战丨C语言扫雷小游戏(超2w字,附图片素材)
使用AndroidStudio调试Framework
死锁详解
LVS负载均衡集群
TCP三次握手与四次挥手详细解释与文献参考
【Kubernetes系列】Kubernetes组件介绍
2022-06-17 网工进阶(十)IS-IS-通用报头、邻接关系的建立、IIH报文、DIS与伪节点
- 原文地址:https://blog.csdn.net/weixin_45974176/article/details/127653474