-
ElasticSearch集群部署
一、 准备工作
1.1、修改Linux句柄数
## 查看当前最大句柄数 sysctl -a | grep vm.max_map_count ## 修改句柄数 vi /etc/sysctl.conf ## 添加以下配置 vm.max_map_count=262144 ## 配置生效 sysctl -p- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
1.2、关闭swap
因为ES的数据大量都是常驻内存的,一旦使用了虚拟内存就会导致查询速度下降,一般需要关闭swap,但是要保证有足够的内存。
## 临时关闭 swapoff -a ## 永久关闭 vi /etc/fstab ## 注释掉swap这一行的配置 # # /etc/fstab # Created by anaconda on Tue Mar 29 14:50:22 2022 # # Accessible filesystems, by reference, are maintained under '/dev/disk' # See man pages fstab(5), findfs(8), mount(8) and/or blkid(8) for more info # /dev/mapper/centos-root / xfs defaults 0 0 UUID=fbd967b5-84cc-40a1-a913-cf7a96e5f290 /boot xfs defaults 0 0 #/dev/mapper/centos-swap swap swap defaults 0 0- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
1.3、修改最大线程数
因为ES运行期间可能创建大量线程,如果线程数支持较少可能报错。
vi /etc/security/limits.conf ## 在文件末尾添加如下配置 * soft nofile 65536 * hard nofile 131072 * soft nproc 2048 * hard nproc 4096 elsearch soft nproc 125535 elsearch hard nproc 125535- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
重新生效
reboot- 1
1.4、创建elsearch用户
## ElasticSearch不能以Root身份运行, 需要单独创建一个用户, 并赋予目录权限 groupadd elsearch useradd elsearch ## 输入密码为elasticsearch passwd elsearch chown -R elsearch:elsearch /home/elsearch- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
1.5、关闭防火墙
systemctl stop firewalld.service systemctl disable firewalld.service- 1
- 2
二、ElasticSearch安装
2.1、下载ElasticSearch服务
下载版本ElasticSearch7.17.5:https://www.elastic.co/cn/downloads/past-releases#elasticsearch
## 切换elsearch用户 su - elsearch ## 下载 wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-7.17.5-linux-x86_64.tar.gz- 1
- 2
- 3
- 4
- 5
2.2、解压安装包
tar -xvf elasticsearch-7.17.5-linux-x86_64.tar.gz- 1
2.3、修改配置文件
默认情况下会绑定本机地址, 外网不能访问, 这里要修改下:
vi elasticsearch-7.17.5/config/elasticsearch.yml # 数据目录位置 path.data: /home/elsearch/elasticsearch-7.10.2/data # 日志目录位置 path.logs: /home/elsearch/elasticsearch-7.10.2/logs # node名称 node.name: node-1 # 外网访问地址 network.host: 0.0.0.0 discovery.seed_hosts: ["node-1"] cluster.initial_master_nodes: ["node-1"]- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
2.4、启动ElasticSearch
启动,注意不要使用root用户启动。
## 切换到/home/elsearch/elasticsearch-7.17.5/bin/目录 cd /home/elsearch/elasticsearch-7.17.5/bin/ ## 以后台常驻方式启动,启动需要一会时间。 ./elasticsearch -d ## 查看过程 ps -ef | grep elasticserach- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
停止
## 先查找ElasticSearch的进程号 ps -ef | grep elasticsearch ## 杀死对应的进程 kill -9 67339- 1
- 2
- 3
- 4
- 5
- 6
2.5、访问验证
访问地址:http://192.168.0.101:9200/_cat/health

启动状态有green、yellow和red。 green是代表启动正常。

三、Kibana服务安装
Kibana是一个针对Elasticsearch的开源分析及可视化平台,用来搜索、查看交互存储在Elasticsearch索引中的数据。
3.1、下载安装包
到官网下载, Kibana安装包, 与之对应7.10.2版本, 选择Linux 64位版本下载,并进行解压。
下载地址:https://www.elastic.co/cn/downloads/past-releases#kibana
## 切换/home/elsearch/目录下 cd /home/elsearch/ ## 下载 wget https://artifacts.elastic.co/downloads/kibana/kibana-7.17.5-linux-x86_64.tar.gz ## 解压 tar -xvf kibana-7.17.5-linux-x86_64.tar.gz ## 重命名为 kibana-7.10.2 mv kibana-7.17.5-linux-x86_64 kibana-7.17.5- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
3.2、修改配置文件
修改以下配置
vi kibana-7.17.5/config/kibana.yml # 服务端口 server.port: 5601 # 服务地址 server.host: "0.0.0.0" # elasticsearch服务地址 elasticsearch.hosts: ["http://192.168.0.101:9200"]- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
3.3、启动kibana
cd /home/elsearch/kibana-7.17.5/bin/ ## 前台运行 ./kibana -q ## 后台运行 nohup ./kibana > /dev/null 2>&1 & ## 查看进程 ps -ef | grep kibana- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
如果出现启动失败的情况, 要检查集群各节点的日志, 确保服务正常运行状态。
3.4、访问服务
四、集群部署
4.1、服务布局
准备三台虚拟机,分配如下
服务器 IP地址 服务名称 端口 内存限制 linux1 192.168.0.101 node1 9200, 9300 1G linux2 192.168.0.102 node2 9200, 9300 1G linux3 192.168.0.103 node3 9200, 9300 1G linux1 192.168.0.101 cerebro 9000 不限 linux1 192.168.0.101 kibana 5601 不限 4.2、准备工作
分别在三台服务器上执行
- 1.1、修改Linux句柄数
- 1.2、关闭swap
- 1.3、修改最大线程数
- 1.4、创建elsearch用户
- 1.5、关闭防火墙
4.3、下载解压
## 切换elsearch用户 [root@linux1 ~]# su - elsearch ## 下载 [elsearch@linux1 ~]$ wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-7.17.5-linux-x86_64.tar.gz ## 解压 [elsearch@linux1 ~]$ tar -xvf elasticsearch-7.17.5-linux-x86_64.tar.gz- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
linux2和linux3同上操作
4.4、改集群配置文件
- linux1
vi elasticsearch-7.17.5/config/elasticsearch.yml ## 集群名称 cluster.name: my-application ## 当前该节点的名称 node.name: node-1 ## 是不是有资格竞选主节点 node.master: true ## 是否存储数据 node.data: true ## 最大集群节点数 node.max_local_storage_nodes: 3 ## 数据存档位置 path.data: /home/elsearch/elasticsearch-7.17.5/data ## 日志存放位置 path.logs: /home/elsearch/elasticsearch-7.17.5/log ## 绑定IP地址 network.host: 0.0.0.0 ## 指定服务访问端口 http.port: 9200 ## 指定API端户端调用端口 transport.tcp.port: 9300 ## 集群发现默认值为127.0.0.1:9300,如果要在其他主机上形成包含节点的群集,如果搭建集群则需要填写 ## es7.x 之后新增的配置,写入候选主节点的设备地址,在开启服务后可以被选为主节点,也就是说把所有的节点都写上 discovery.seed_hosts: ["192.168.0.101","192.168.0.102","192.168.0.103"] ## 当你在搭建集群的时候,选出合格的节点集群,有些人说的太官方了, ## 其实就是,让你选择比较好的几个节点,在你节点启动时,在这些节点中选一个做领导者, ## 如果你不设置呢,elasticsearch就会自己选举,这里我们把三个节点都写上 cluster.initial_master_nodes: ["192.168.0.101","192.168.0.102","192.168.0.103"] ## 在群集完全重新启动后阻止初始恢复,直到启动N个节点 ## 简单点说在集群启动后,至少复活多少个节点以上,那么这个服务才可以被使用,否则不可以被使用, gateway.recover_after_nodes: 2 ## 禁用安全配置,否则查询的时候会提示警告 xpack.security.enabled: false ## 开启跨域访问支持,默认为false http.cors.enabled: true ## 跨域访问允许的域名, 允许所有域名 http.cors.allow-origin: "*"- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- linux2
vi elasticsearch-7.17.5/config/elasticsearch.yml ## 集群名称 cluster.name: my-application ## 当前该节点的名称 node.name: node-2 ## 是不是有资格竞选主节点 node.master: true ## 是否存储数据 node.data: true ## 最大集群节点数 node.max_local_storage_nodes: 3 ## 数据存档位置 path.data: /home/elsearch/elasticsearch-7.17.5/data ## 日志存放位置 path.logs: /home/elsearch/elasticsearch-7.17.5/log ## 绑定IP地址 network.host: 0.0.0.0 ## 指定服务访问端口 http.port: 9200 ## 指定API端户端调用端口 transport.tcp.port: 9300 ## 集群发现默认值为127.0.0.1:9300,如果要在其他主机上形成包含节点的群集,如果搭建集群则需要填写 ## es7.x 之后新增的配置,写入候选主节点的设备地址,在开启服务后可以被选为主节点,也就是说把所有的节点都写上 discovery.seed_hosts: ["192.168.0.101","192.168.0.102","192.168.0.103"] ## 当你在搭建集群的时候,选出合格的节点集群,有些人说的太官方了, ## 其实就是,让你选择比较好的几个节点,在你节点启动时,在这些节点中选一个做领导者, ## 如果你不设置呢,elasticsearch就会自己选举,这里我们把三个节点都写上 cluster.initial_master_nodes: ["192.168.0.101","192.168.0.102","192.168.0.103"] ## 在群集完全重新启动后阻止初始恢复,直到启动N个节点 ## 简单点说在集群启动后,至少复活多少个节点以上,那么这个服务才可以被使用,否则不可以被使用, gateway.recover_after_nodes: 2 ## 禁用安全配置,否则查询的时候会提示警告 xpack.security.enabled: false ## 开启跨域访问支持,默认为false http.cors.enabled: true ## 跨域访问允许的域名, 允许所有域名 http.cors.allow-origin: "*"- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- linux3
vi elasticsearch-7.17.5/config/elasticsearch.yml ## 集群名称 cluster.name: my-application ## 当前该节点的名称 node.name: node-3 ## 是不是有资格竞选主节点 node.master: true ## 是否存储数据 node.data: true ## 最大集群节点数 node.max_local_storage_nodes: 3 ## 数据存档位置 path.data: /home/elsearch/elasticsearch-7.17.5/data ## 日志存放位置 path.logs: /home/elsearch/elasticsearch-7.17.5/log ## 绑定IP地址 network.host: 0.0.0.0 ## 指定服务访问端口 http.port: 9200 ## 指定API端户端调用端口 transport.tcp.port: 9300 ## 集群发现默认值为127.0.0.1:9300,如果要在其他主机上形成包含节点的群集,如果搭建集群则需要填写 ## es7.x 之后新增的配置,写入候选主节点的设备地址,在开启服务后可以被选为主节点,也就是说把所有的节点都写上 discovery.seed_hosts: ["192.168.0.101","192.168.0.102","192.168.0.103"] ## 当你在搭建集群的时候,选出合格的节点集群,有些人说的太官方了, ## 其实就是,让你选择比较好的几个节点,在你节点启动时,在这些节点中选一个做领导者, ## 如果你不设置呢,elasticsearch就会自己选举,这里我们把三个节点都写上 cluster.initial_master_nodes: ["192.168.0.101","192.168.0.102","192.168.0.103"] ## 在群集完全重新启动后阻止初始恢复,直到启动N个节点 ## 简单点说在集群启动后,至少复活多少个节点以上,那么这个服务才可以被使用,否则不可以被使用, gateway.recover_after_nodes: 2 ## 禁用安全配置,否则查询的时候会提示警告 xpack.security.enabled: false ## 开启跨域访问支持,默认为false http.cors.enabled: true ## 跨域访问允许的域名, 允许所有域名 http.cors.allow-origin: "*"- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
4.5、启动集群节点
分别启动三个ES服务
## linux1 [elsearch@linux1 ~]$ /home/elsearch/elasticsearch-7.17.5/bin/elasticsearch -d ## linux2 [elsearch@linux2 ~]$ /home/elsearch/elasticsearch-7.17.5/bin/elasticsearch -d ## ## linux3 [elsearch@linux3 ~]$ /home/elsearch/elasticsearch-7.17.5/bin/elasticsearch -d- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
4.6、访问验证
访问linux1:http://192.168.0.101:9200/_cat/health
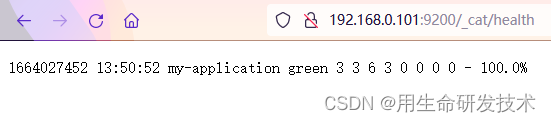
访问linux2:http://192.168.0.102:9200/_cat/health
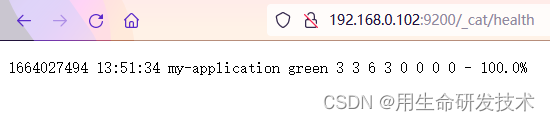
访问linux3:http://192.168.0.103:9200/_cat/health

4.7、安装kibana
安装方式同上,修改配置文件
vi /home/elsearch/kibana-7.17.5/config/kibana.yml ## 监听端口 server.port: 5601 ## 服务地址 server.host: "0.0.0.0" ## 服务名称 server.name: "kibana" ## kibana访问es服务器的URL,就可以有多个,以逗号","隔开 elasticsearch.hosts: ["http://192.168.0.101:9200","http://192.168.0.102:9200","http://192.168.0.103:9200"] ## kibana访问Elasticsearch的账号与密码(如果ElasticSearch设置了的话) elasticsearch.username: "kibana" elasticsearch.password: "kibana" ## kibana日志文件存储路径 logging.dest: stdout ## 此值为true时,禁止所有日志记录输出 logging.silent: false ## 此值为true时,禁止除错误消息之外的所有日志记录输出 logging.quiet: false ## 此值为true时,记录所有事件,包括系统使用信息和所有请求 logging.verbose: false ## 设置采样系统和进程性能的时间间隔(毫秒) ops.interval: 5000 ## kibana web语言 i18n.locale: "zh-CN"- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
启动kibana
## 切换到/home/elsearch/kibana-7.17.5/bin/目录 cd /home/elsearch/kibana-7.17.5/bin/ ## 后台启动 nohup ./kibana > /dev/null 2>&1 &- 1
- 2
- 3
- 4
- 5
测试
访问:http://192.168.0.101:5601

4.8、cerebro
Cerebro是Elasticsearch插件 Elasticsearch Kopf 的演变,可以通过图形界面查看分片分配和执行常见的索引操作。完全开源,需要依赖 Java 1.8 或更高版本才能运行。
## 切换要目录 cd ~ ## 下载 wget https://github.com/lmenezes/cerebro/releases/download/v0.9.4/cerebro-0.9.4.tgz ## 解压 tar -zxvf cerebro-0.9.4.tgz ## 启动 cd /home/elsearch/cerebro-0.9.4/bin nohup ./cerebro > /dev/null 2>&1 &- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
测试,访问:http://192.168.0.101:9000,输入:http://192.168.0.101:9200


4.9、elasticsearch-head插件安装
这里以Chrome为例,浏览器输入: chrome://extensions/,选择扩展程序。

搜索
Multi Elasticsearch Head
连接elasticsearch测试

-
相关阅读:
不经意传输扩展(OTE)-不经意伪随机函数(OPRF)-隐私集合求交(PSI)
sklearn混淆矩阵的计算和seaborn可视化
【华为IP阶段OSPF3】--- 四类特殊区域及OSPF协议特性
Jetpack DataBinding使用--Jetpack系列
《深度学习进阶 自然语言处理》第八章:Attention介绍
商业银行如何构建一体化监控
CNN基础与LeNet框架
计算机毕业设计(附源码)python语言学习系统
【STM32】RTC(实时时钟)
NumLevels
- 原文地址:https://blog.csdn.net/qq_37242720/article/details/126993382

