-
【推荐系统入门到项目实践】(四):Baseline和Slope one算法
【推荐系统入门到项目实践】(四):Baseline和Slope one算法
- 🌸个人主页:JOJO数据科学
- 📝个人介绍:统计学top3高校统计学硕士在读
- 💌如果文章对你有帮助,欢迎✌
关注、👍点赞、✌收藏、👍订阅专栏 - ✨本文收录于【推荐系统入门到项目实战】本系列主要分享一些学习推荐系统领域的方法和代码实现。
引言
在上一篇文章中我们介绍了矩阵分解和ALS算法,上面这种方法的一个缺点是只使用了
个性化推荐部分,没有考虑到物品和用户本身的整体情况。因此,下面介绍介绍两种用于反映一个整体情况推荐的方法。baseline算法
基本原理
Baseline算法:基于统计的基准预测线打分b u i b_{ui} bui 预测值
b u b_u bu 用户对整体的偏差
b i b_i bi 商品对整体的偏差
b u i = u + b u + b i b_{ui}=u+b_{u}+b_i bui=u+bu+bi以对泰坦尼克号评分为例,其中 b u i b_{ui} bui指的是预测值, u u u指的是所有电影的平均得分, b u b_{u} bu表示的是泰坦尼克号比其他电影平均多的评分(如果是负数则少的评分), b i b_i bi指的是用户的评分误差,假设他比较苛刻,可能比其他用户平均少打的分数
使用
ALS来估计Baseline算法Step1,固定bu,优化bi
Step2,固定bi,优化bu

实现方法
我们使用Surprise库来实现(https://surprise.readthedocs.io/en/stable/)
surprise包含了许多推荐算法的实现方法。常用的几种方法如下:算法 描述 NormalPredictor() 基于统计的推荐系统预测打分,假定用户打分的分布是基于正态分布的 BaselineOnly 基于统计的基准预测线打分 knns.KNNBasic 基本的协同过滤算法 knns.KNNWithMeans 协同过滤算法的变种,考虑每个用户的平均评分 knns.KNNWithZScore 协同过滤算法的变种,考虑每个用户评分的归一化操作 knns.KNNBaseline 协同过滤算法的变种,考虑每个用户评分的基线 matrix_factorzation.SVD SVD 矩阵分解算法 matrix_factorzation.SVDpp SVD++ 矩阵分解算法 matrix_factorzation.NMF 一种非负矩阵分解的协同过滤算法 SlopeOne SlopeOne 协同过滤算法 其中
baseline算法包含两个主要的方法**NormalPredictor和BaselineOnly**Normal Perdictor 认为用户对物品的评分是服从**
正态分布**的,从而可以根据已有的评分的均值和方差预测当前用户对其他物品评分的分数。BaselineOnly算法的思想就是设立基线,并引入
用户的偏差以及item的偏差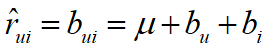
μ为所有用户对电影评分的均值
b u i b_{ui} bui:待求的基线模型中用户u给物品i打分的预估值
b u b_u bu:user偏差(如果用户比较苛刻,打分都相对偏低, 则bu<0;反之,bu>0);
b i b_i bi:item偏差,反映商品受欢迎程度
评估方法
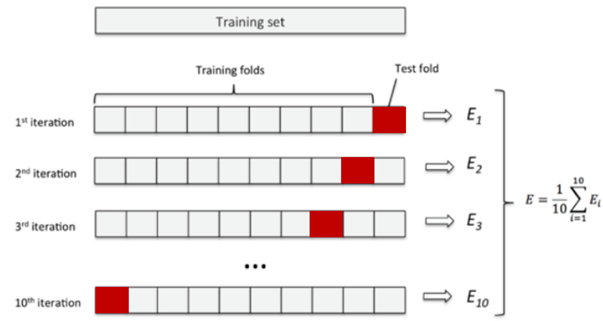
K折交叉验证
将训练集数据划分为K份,使用其中的K-1份作为训练集,剩余一份作为测试集
K次误差的平均值作为泛化误差。
所有数据都做过训练和测试,更好的利用数据
K越大,平均误差作为泛化误差的结果就越可靠,但花费的时间也时间也越长
Surprise中的评价指标
RMSE:均方根误差
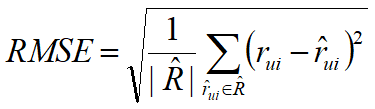
MAE:平均绝对误差
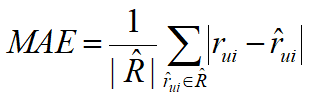
下面我们以RMSE为评估指标,使用baselines算法对评分数据集进行预测。
代码实现
from surprise import Dataset from surprise import Reader from surprise import BaselineOnly, KNNBasic, NormalPredictor from surprise import accuracy from surprise.model_selection import KFold #import pandas as pd # 数据读取 reader = Reader(line_format='user item rating timestamp', sep=',', skip_lines=1) data = Dataset.load_from_file('MovieLens/ratings.csv', reader=reader) train_set = data.build_full_trainset() # ALS优化 bsl_options = {'method': 'als','n_epochs': 5,'reg_u': 12,'reg_i': 5} # SGD优化 #bsl_options = {'method': 'sgd','n_epochs': 5} algo = BaselineOnly(bsl_options=bsl_options) #algo = BaselineOnly() #algo = NormalPredictor()#大家也可以试一下这个方法 # 定义K折交叉验证迭代器,K=3 kf = KFold(n_splits=3) for trainset, testset in kf.split(data): # 训练并预测 algo.fit(trainset) predictions = algo.test(testset) # 计算RMSE accuracy.rmse(predictions, verbose=True) uid = str(196) iid = str(302) # 输出uid对iid的预测结果 pred = algo.predict(uid, iid, r_ui=4, verbose=True)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
Estimating biases using als... RMSE: 0.8635 Estimating biases using als... RMSE: 0.8644 Estimating biases using als... RMSE: 0.8636 user: 196 item: 302 r_ui = 4.00 est = 4.07 {'was_impossible': False}- 1
- 2
- 3
- 4
- 5
- 6
- 7
est为我们的预测值, r u i r_{ui} rui为真实值。可以看出预测的结果还不错,但是其实这种方法没有利用到用户和物品之间的交互信息,更多的是从一个某个用户或者某个商品的总体情况来进行预测,当数据质量较好时,这种方法的效果还不错。下面我们再来介绍一种更简单的方法。SlopeOne算法
基本原理
Slope One是一系列应用于协同过滤的算法的统称。由 Daniel Lemire和Anna Maclachlan于2005年发表的论文中提出。有争议的是,该算法堪称基于项目评价的协同过滤算法最简洁的形式。该系列算法的简洁特性使它们的实现简单而高效,而且其精确度与其它复杂费时的算法相比也不相上下。 该系列算法也被用来改进其它算法。它最大优点在于算法很简单, 易于实现, 效率高且推荐准确度较高。为什么说他简单呢?因为在本质上,它其实是运用了一个回归表达式 f ( x ) = x + b f(x)=x+b f(x)=x+b,其中只有一个单一的自由参数b。我想这也是它的名字来源吧,slope我们知道是斜率的意思,slope one也就是斜率为1。该自由参数只不过就是两个项目评分间的平均差值。甚至在某些实例当中,它比线性回归的方法更准确,而且该算法只需要一半(甚至更少)的存储量。
下面我们来看看具体是怎么计算的。
用户 商品1评分 商品2 A 5 3 B 4 3 C 4 ? 我们现在有三个用户对两个商品的评分矩阵,如上表所示,但是**c对商品2的评分我们是未知的**,那么我们怎么估计它呢?
我们根据A,B用户对**两个商品的评分差值**来进行估计。
**用户A:**商品1-商品2=(5-3)=2
**用户B:**商品1-商品2=4-3=1
那么我们认为商品1平均比商品2评分要高(1+2)/2=1.5。那么我们就可以计算出用户C对商品2的评分
C对商品2的评分=4-((5-3)+(4-3))/2=2.5
那么我们现在来看看slopeOne算法的一般步骤
Step1,计算Item之间的评分差的均值,记为评分偏差(两个item都评分过的用户)
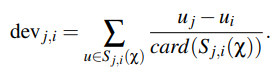
Step2,根据Item间的评分偏差和用户的历史评分,预测用户对未评分的item的评分
Step3,将预测评分排序,取
topN对应的item推荐给用户下面我们来看一个更复杂的具体的案例:
a b c d A 5 3.5 B 2 5 4 2 C 4.5 3.5 1 4 我们要补全上面这个评分矩阵
Step1,计算Item之间的评分差的均值
b与a:((3.5-5)+(5-2)+(3.5-4.5))/3=0.5/3
c与a:((4-2)+(1-4.5))/2=-1.5/2
d与a:((2-2)+(4-4.5))/2=-0.5/2
c与b:((4-5)+(1-3.5))/2=-3.5/2
d与b:((2-5)+(4-3.5))/2=-2.5/2
d与c:((2-4)+(4-1))/2=1/2
将上面计算结果写成矩阵的形式,如下所示,我们称为
评分偏差矩阵,以0.17为例,表示商品b比a平均高0.17分a b c d a b 0.17 c -0.75 -1.75 d -0.25 -1.25 0.5 Step2,预测用户A对商品c和d的评分
A对c评分=((-0.75+5)+(-1.75+3.5))/2=3
A对d评分=((-0.25+5)+(-1.25+3.5))/2=3.5
a b c d A 5 3.5 3 3.5 B 2 5 4 2 C 4.5 3.5 1 4 Step3,将预测评分排序,推荐给用户
推荐顺序为{d, c}
加权算法 Weighted Slope One
如果有100个用户对Item1和Item2都打过分, 有1000个用户对Item3和Item2也打过分,显然这两个rating差的权重是不一样的,因此计算方法为:
(100*(Rating 1 to 2) + 1000(Rating 3 to 2)) / (100 + 1000)
SlopeOne算法的特点
适用于item更新不频繁,数量相对较稳定
item数<
算法简单,易于实现,执行效率高
依赖用户行为,存在
冷启动问题和稀疏性问题用户 商品1评分 商品2 X 5 3 Y 4 3 Z 4 ? 代码实现
from surprise import SVD from surprise import Dataset from surprise.model_selection import cross_validate #from surprise import evaluate, print_perf from surprise import Reader from surprise import BaselineOnly, KNNBasic, KNNBaseline, SlopeOne from surprise import accuracy from surprise.model_selection import KFold import pandas as pd import io import pandas as pd # 读取物品(电影)名称信息 def read_item_names(): file_name = ('./movies.csv') data = pd.read_csv('./movies.csv') rid_to_name = {} name_to_rid = {} for i in range(len(data['movieId'])): rid_to_name[data['movieId'][i]] = data['title'][i] name_to_rid[data['title'][i]] = data['movieId'][i] return rid_to_name, name_to_rid # 数据读取 reader = Reader(line_format='user item rating timestamp', sep=',', skip_lines=1) data = Dataset.load_from_file('MovieLens/ratings.csv', reader=reader) train_set = data.build_full_trainset() # 使用SlopeOne算法 algo = SlopeOne() algo.fit(train_set) # 对指定用户和商品进行评分预测 uid = str(196) iid = str(302) pred = algo.predict(uid, iid, r_ui=4, verbose=True)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
user: 196 item: 302 r_ui = 4.00 est = 4.32 {'was_impossible': False}- 1
可以看出,使用
slopeone算法得到的预测结果为4.32,效果似乎相对于baseline算法要差一些,其实这也不难猜到,因为我们毕竟用的是一个太简单的模型。但是他对于数据量相对没那么敏感总结
介绍了
baseline算法和slopeOne算法。baseline算法的核心思想是将用户评分分解成**三个部分**
- u u u:平均评分
- b u b_u bu:用户评分偏差
- b i b_i bi:物品评分偏差
然后使用ALS方法进行求解
SlopeOne算法的核心思想根据
用户对不同商品评分的差异来预测某一商品的评分。大家记得那个具体的案例即可。下一章我们将讨论SVD矩阵分解以及一些拓展的模型。
-
相关阅读:
JavaScript设计模式快速参考指南
《Operating Systems: Three Easy Pieces》 操作系统【一】 虚拟化 CPU
51单片机的基础知识汇总
如何实现硬件和软件的统一?(从物理世界到电子电路再到计算机科学)
(原创)基于springboot,vue宠物商城定制版v3.0
vue3: 1.如何利用 effectScope 自己实现一个青铜版pinia 一 state篇
【德哥说库系列】-Oracle 19C RAC 应用RU19补丁
【LeetCode】【简单】【2】20. 有效的括号
【Linux】Nignx的入门&使用负载均衡&动静分离(前后端项目部署)---超详细
一次搞懂SpringBoot核心原理:自动配置、事件驱动、Condition
- 原文地址:https://blog.csdn.net/weixin_45052363/article/details/127623889