-
《设计模式:可复用面向对象软件的基础》——行为模式(3)(笔记)
五、行为模式
5.9 STRATEGY(策略)
1.意图
定义一系列的算法,把它们一个个封装起来,并且使它们可相互替换。本模式使得算法可独立于使用它的客户而变化。
笔者认为,它策略的封装内容彼此是可相互替换的。比如,页面样式之间的替换,页面皮肤一类的更改。
当然,也是可以用if-else和switch这类方式直接处理的。
状态模式是处理一个状态到另一个状态,中介者模式是处理模块之间复杂的引用。
2.别名
政策( Policy )
3.动机
有许多算法可对一个正文流进行分行。将这些算法硬编进使用它们的类中是不可取的,其原因如下:
- 需要换行功能的客户程序如果直接包含换行算法代码的话将会变得复杂,这使得客户程序庞大并且难以维护,尤其当其需要支持多种换行算法时问题会更加严重。
- 不同的时候需要不同的算法,我们不想支持我们并不使用的换行算法。
- 当换行功能是客户程序的一个难以分割的成分时,增加新的换行算法或改变现有算法将十分困难。
我们可以定义一些类来封装不同的换行算法,从而避免这些问题。一个以这种方法封装的算法称为一个策略(strategy),如下图所示。
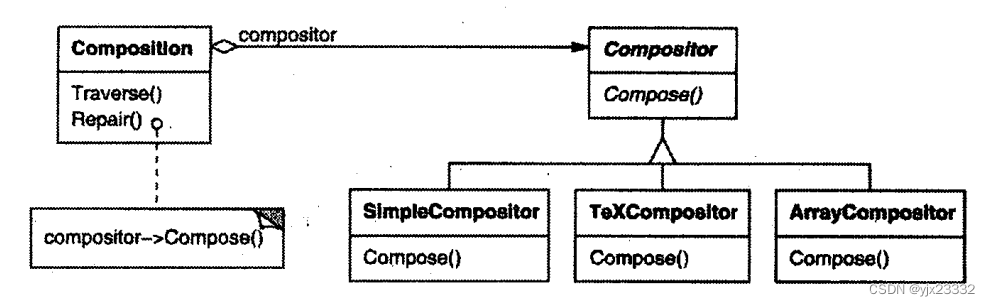
假设一个Composition类负责维护和更新一个正文浏览程序中显示的正文换行。换行策略不是Composition类实现的,而是由抽象的Compositor类的子类各自独立地实现的。Compositor各个子类实现不同的换行策略:
- SimpleCompositor实现一个简单的策略,它一次决定一个换行位置。
- TeXCompositor实现查找换行位置的TEX算法。这个策略尽量全局地优化换行,也就是,一次处理一段文字的换行。
- ArrayCompositor实现一个策略,该策略使得每一行都含有一个固定数目的项。例如,用于对一系列的图标进行分行。
Composition维护对Compositor对象的一一个引用。一旦Composition重新格式化它的正文,它就将这个职责转发给它的Compositor对象。Composition的客户指定应该使用哪一种Compositor的方式是直接将它想要的Compositor装人Composition中。
4.适用性
当存在以下情况时使用Strategy模式
- 许多相关的类仅仅是行为有异。“策略”提供了一种用多个行为中的-一个行为来配置一个类的方法。
- 需要使用一个算法的不同变体。例如,你可能会定义一些反映不同的空间/时间权衡的算法。当这些变体实现为-一个算法的类层次时,可以使用策略模式。
- 算法使用客户不应该知道的数据。可使用策略模式以避免暴露复杂的、与算法相关的数据结构。
- 一个类定义了多种行为,并且这些行为在这个类的操作中以多个条件语句的形式出现。将相关的条件分支移人它们各自的Strategy类中以代替这些条件语句。
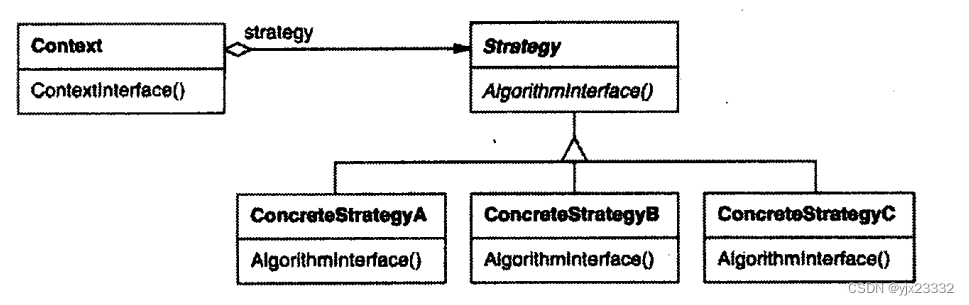
5.结构
6.参与者
-
Strategy(策略,如Compositor)
- 定义所有支持的算法的公共接口。Context使用这个接口来调用某ConcreteStrategy定义的算法。
-
ConcreteStrategy(具体策略,如SimpleCompositor, TeXCompositor, ArrayCompositor)
- 以Strategy接口实现某具体算法。
-
Context(上下文,如Composition)
- 用一个ConcreteStrategy对象来配置。
- 维护一个对Strategy对象的引用。
- 可定义一个接 口来让Stategy访问它的数据。
7.协作
- Strategy和Context相互作用以实现选定的算法。当算法被调用时,Context可以将该算法所需要的所有数据都传递给该Stategy。或者,Context可以将自身作为一个参数传递给Strategy操作。这就让Strategy 在需要时可以回调Context。
- Context将它的客户的请求转发给它的Strategy。客户通常创建并传递- - 个ConcreteStrategy对象给该Context;这样,客户仅与Context交互。通常有一系列的ConcreteStrategy类可供客户从中选择。
8.效果
Strategy模式有下面的一些优点和缺点:
- 相关算法系列
Strategy类层次为Context定义了一系列的可供重用的算法或行为。继承有助于析取出这些算法中的公共功能。
- 一个替代继承的方法
继承提供了 另一种支持多种算法或行为的方法。你可以直接生成一个Contex类的子类,从而给它以不同的行为。但这会将行为硬行编制到Context中,而将算法的实现与Context的实现混合起来,从而使Context难以理解、难以维护和难以扩展,而且还不能动态地改变算法。最后你得到一堆相关的类,它们之间的唯一差别是它们所使用的算法或行为。将算法封装在独立的Strategy类中使得你可以独立于其Context改变它,使它易于切换、易于理解、易于扩展。
- 消除了一些条件语句
Strategy模式提供 了用条件语句选择所需的行为以外的另一种选择。当不同的行为堆砌在一个类 中时,很难避免使用条件语句来选择合适的行为。将行为封装在一个个独立的Strategy类中消除了这些条件语句。
例如,不用Strategy,正文换行的代码可能是象下面这样
void Composition::Repair () { switch (_breakingStrategy) { case simplestrategy: ComposeWithSimpleCompositor(); break; case TeXStrategy: ComposeWithTexcompositor(); break; // ... } // merge results with existing composition, if necessary }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
Strategy模式将换行的任务委托给一个Strategy对象从而消除了这些case语句:
void Composition::Repair () { _compoaitor->Compose() ; // merge results with existing composition, if necessary }- 1
- 2
- 3
- 4
含有许多条件语句的代码通常意味着需要使用Strategy模式。
- 实现的选择
Strategy模式可以提供相同行为的不同实现。客户可以根据不同时间/空间权衡取舍要求从不同策略中进行选择。
- 客户必须了解不同的Strategy
本模式有一个潜在的缺点,就是一个客户要选择一个合适的Strategy就必须知道这些Strategy到底有何不同。此时可能不得不向客户暴露具体的实现问题。因此仅当这些不同行为变体与客户相关的行为时,才需要使用Suralcgy模式。
- Strategy和Context之间的通信开销
无论各 个ConcreteStrategy实现的算法是简单还是复杂,它们都共享Strategy定义的接口。因此很可能某些ConcreteStrategy不会都用到所有通过这个接口传递给它们的信息;简单的ConcreteStrategy可能不使用其中的任何信息!这就意味着有时Context会创建和初始化一些永远不会用到的参数。如果存在这样问题,那么将需要在Strategy和Context之间更进行紧密的耦合。
- 增加了对象的数目
Strategy增加了 一个应用中的对象的数目。有时你可以将Strategy实现为可供各Contexi共享的无状态的对象来减少这一开销。 任何其余的状态都由Context维护。
Context在每一次对Strategy对象的请求中都将这个状态传递过去。共享的Stragey不应在各次调用之间维护状态。Flyweight(4.6)模式更详细地描述了这一方法。
9.实现.
考虑下面的实现问题:
- 定义Strategy和Context接口
Strategy和Context接 口必须使得ConcreteStrategy能够有效的访问它所需要的Context中的任何数据,反之亦然。
-
一种 办法是让Context将数据放在参数中传递给Strategy操作一也就是说, 将数据发送给Strategy。这使得Strategy和Context解耦。但另一方面,Context可能发送一些Strategy不需要的数据。
-
另一种办法是让Context将自身作为一个参数传递给Strategy,该Strategy再显式地向该Context请求数据。或者,Strategy 可以存储对它的Context的一个引用,这样根本不再需要传递任何东西。这两种情况下,Strategy都可以请求到它所需要的数据。但现在Context必须对它的数据定义一个更为精细的接口,这将Strategy和Context更紧密地耦合在一起。
- 将Strategy作为模板参数
在C++中, 可利用模板机制用一个Strategy来配置一个类。然而这种技术仅当下面条件满足时才可以使用
- 可以在编译时选择Strategy
- 它不需在运行时改变
在这种情况下,要被配置的类(如,Context) 被定义为以一个Strategy类作为一个参数的模板类:
template <class AStrategy> class Context { void operation() { thestrategy.DoAlgorithm(); } private: AStrategy theStrategy; };- 1
- 2
- 3
- 4
- 5
- 6
当它被例化时该类用一个Strategy类来配置:
class MyStrategy { public: void DoAlgorithm(); }; Context<MyStrategy> aContext;- 1
- 2
- 3
- 4
- 5
- 6
使用模板不再需要定义给Strategy定义接口的抽象类。把Strategy作为一个模板参数也使得可以将一个Strategy和它的Context静态地绑定在一起, 从而提高效率。
- 使Strategy对象成为可选的
如果即使在不使用额外的Strategy对象的情况下,Context也还有意义的话,那么它还可以被简化。Context在访问某Strategy 前先检查它是否存在,如果有,那么就使用它;如果没有,那么Context执行缺省的行为。这种方法的好处是客户根本不需要处理Strategy对象,除非它们不喜欢缺省的行为。
10.代码示例
我们将给出动机一节例子的高层代码,这些代码基于InterViews[LCI+92]中的Composition和Compositor类的实现。
Composition类维护一个Component实例的集合,它们代表一个文档中的正文和图形元素。Composition使用一个封装了某种分行策略的Compositor子类实例将Component对象编排成行。每一个Component都有相应的正常大小、可伸展性和可收缩性。可伸展性定义了该Component可以增长到超出正常大小的程度;可收缩性定义了它可以收缩的程度。Composition将这些值传递给一个Compositor,它使用这些值来决定换行的最佳位置。
class Composition { public: Composition (Compositor*) ; void Repair(); private: Compositor* _compositor; Component*_components;// the list of components int _componentCount;// the number of components int _linewidth; // the Composition's 1ine width int* _lineBreaks;// the position of linebreaks // in components int _lineCount; // the number of lines };- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
当需要一个新的布局时,Composition让它的Compositor决定 在何处换行。Compositon传递给Compositor三个数组,它们定义各Component的正常大小、可伸展性和可收缩性。它还传递Component的数目、线的宽度以及一个数组,让Compositor来 填充每次换行的位置。
Compositor返回计算得到的换行数目。Compositor接 口使得Compositon可传递给Compositor所有它需要的信息。此处是一个“将数据传给Strategy”的例子:
class Compositor { public: virtual int Compose(Coord natural[], Coord stretch[], Coord shrink[] ,int componentCount, int linewidth, int breaks[])=0; protected: Compositor(); };- 1
- 2
- 3
- 4
- 5
- 6
注意Compositor是一个抽象类,而其具体子类定义特定的换行策略。
Composition在它的Repair操作中调用它的Compositor。Repair首 先用每一个Component的正常大小、可伸展性和可收缩性初始化数组(为简单起见略去细节)。然后它调用Compositor得到换行位置并最终据以对Component进行布局(也省略了): .
void Composition::Repair () { Coord* natural; Coord* stretchability; Coord* shrinkability; int componentCount; int* breaks; // prepare the arrays with the desired component sizes . // ... // determine where the breaks are: int breakCount; breakCount = _compositor->Compose (natural, stretchability,shrinkability,componentCount,_lineWidth, breaks); // lay out components according to breaks }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
现在我们来看各Compositor子类。SimpleCompositor一次检查一行Component, 并决定在那儿换行:
class simpleCompositor : public Compositor { public: SimpleCompositor(); virtual int Compose(Coord natural[], Coord stretch[], Coord shrink[],int componentCount, int lineWidth, int breaks[]); // ... };- 1
- 2
- 3
- 4
- 5
- 6
TexCompositor使用一个更为全局的策略。它每次检查一个段落( paragraph),并同时考虑到各Component的大小和伸展性。它也通过压缩Component之间的空白以尽量给该段落一个均匀的“色彩”。
class TeXCompositor:public Compositor { public: TeXCompositor(); virtual int Compose (Coord natural[], Coord stretch[], Coord shrink[], int componentCount,int lineWidth, int breaks[]); // ... };- 1
- 2
- 3
- 4
- 5
- 6
ArrayCompositor用规则的间距将构件分割成行。
class ArrayCompositor : public Compositor { public: ArrayCompositor (int interval); virtual int Compose (Coord natural[],Coord stretch[], Coord shrink[],int componentCount,int linewidth, int breaks[]) };- 1
- 2
- 3
- 4
- 5
这些类并未都使用所有传递给Compose的信息。SimpleCompositor忽 略Component的伸展性,仅考虑它们的正常大小; TeXCompositor使用所有传递给它的信息;而ArrayCompositor忽略所有的信息。实例化Composition时需把想要使用的Compositor传递给它:
Composition* quick = new Composition (new SimpleCompositor); Composition* slick = new Composition (new TexCompositor); Composition* iconic = new Composition (new ArrayCompositor(100));- 1
- 2
- 3
Compositor的接口须经仔细设计,以支持子类可能实现的所有排版算法。你不希望在生成一个新的子类不得不修改这个接口,因为这需要修改其它已有的子类。一般来说,Strategy和Context的接口决定了该模式能在多大程度上达到既定目的。
11.相关模式
Flyweight (4.6): Strategy对 象经常是很好的轻量级对象。
5.10 TEMPLATE METHOD(模板方法)
1.意图
定义一个操作中的算法的骨架,而将一些步骤延迟到子类中。
TemplateMethod使得子类可以不改变一个算法的结构即可重定义该算法的某些特定步骤。
就是为了延迟实现而使用,也就是我们常用的interface接口。抽象类通过使用接口决定了执行顺序,而子代通过重写(实现)的方式,决定每一个接口的执行内容。
2.动机
考虑一个提供Application和Document类的应用框架。Application类 负责打开一个已有的以外部形式存储的文档,如一个文件。一旦一个文档中的信息从该文件中读出后,它就由一个Document对象表示。
用框架构建的应用可以通过继承Application和Document来满足特定的需求。
例如,一个绘图应用定义Draw Application和DrawDocument子类;一个电子表格应用定义SpreadsheetApplication和SpreadsheetDocument子类,如下图所示。
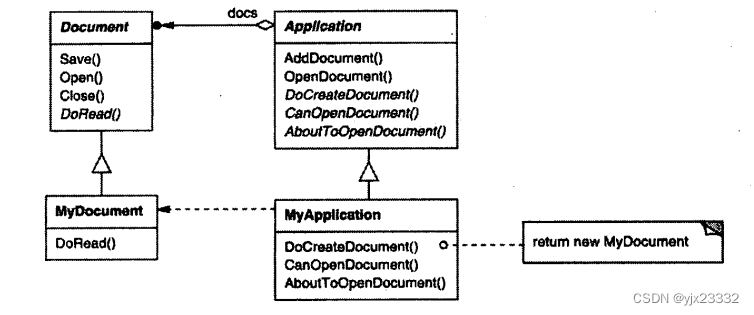
抽象的Application类在它的OpenDocument操作中定义了打开和读取一个文档的算法:
void Application::OpenDocument (const char* name) { if (!CanOpenDocument (name)){ // cannot handle this document return; } Document* doc = DoCreateDocument () ; if (doc) { _docs->AddDocument (doc) ; AboutToOpenDocument (doc) ; doc->Open() ; doc->DoRead () ; } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
OpenDocument定义了打开一个文档的每一个主要步骤。它检查该文档是否能被打开,创建与应用相关的Document对象,将它加到它人的文档集合中,并且从一个文件中读取该Document。
我们称OpenDocument为一个模板方法(template method)。一个模板方法用一些抽象的操作定义一个算法,而子类将重定义这些操作以提供具体的行为。Application的子类将定义检查一个文档是否能够被打开(CanOpenDocument )和创建文档( DoCreateDocument )的具体算法步骤。Document子类将定义读取文档( DoRead )的算法步骤。如果需要,模板方法也可定义一个操作( AboutToOpenDocument )让Application子类知道该文档何时将被打开。通过使用抽象操作定义一个算法中的一些步骤,模板方法确定了它们的先后顺序,但它允许Application和Document子类改变这些具体步骤以满足它们各自的需求。
3.适用性
模板方法应用于下列情况:
- 一次性实现一个算法的不变的部分,并将可变的行为留给子类来实现。
- 各子类中公共的行为应被提取出来并集中到一个公共父类中以避免代码重复。这是Opdyke和Johnson所描述过的“重分解以一般化”的一个很好的例子。首先识别现有代码中的不同之处,并且将不同之处分离为新的操作。最后,用一个调用这些新的操作的模板方法来替换这些不同的代码。
- 控制子类扩展。模板方法只在特定点调用“hook” 操作(参见效果-节),这样就只允许在这些点进行扩展。
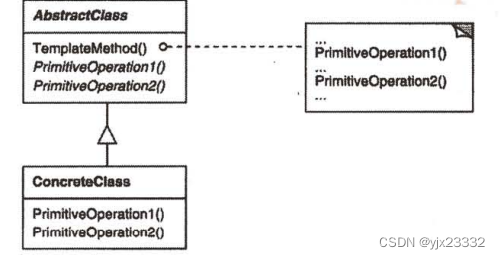
4.结构
5.参与者
- AbstractClass (抽象类,如Application )
- 定义抽象的原语操作( primitive operation ),具体的子类将重定义它们以实现一个算法的步骤一实现一个模板方法,定义一个算法的骨架。该模板方法不仅调用原语操作,也调用定义在AbstractClass或其他对象中的操作。
- ConcreteClass (具体类,如MyApplication )
- 实现原语操作以完成算法中与特定子类相关的步骤。
6.协作
- ConcreteClass靠AbstractClass来实现算法中不变的步骤。
7.效果
模板方法是一种代码复用的基本技术。它们在类库中尤为重要,它们提取了类库中的公共行为。
模板方法导致一种反向的控制结构,这种结构有时被称为“好莱坞法则”,即“别找我们,我们找你”。 这指的是一个父类调用一个子类的操作,而不是相反。
模板方法调用下列类型的操作:- 具体的操作( ConcreteClass或对客户类的操作)。
- 具体的AbstractClass的操作(即,通常对子类有用的操作)。
- 原语操作(即,抽象操作)。
- Factory Method (参见Factqry Method (3.5 ))。
- 钩子操作( hook operations ),它提供了缺省的行为,子类可以在必要时进行扩展。一个钩子操作在缺省操作通常是一个空操作。
很重要的一点是模板方法应该指明哪些操作是钩子操作(可以被重定义)以及哪些是抽象操作(必须被重定义)。要有效地重用一个抽象类,子类编写者必须明确了解哪些操作是设计为有待重定义的。
子类可以通过重定义父类的操作来扩展该操作的行为,其间可显式地调用父类操作。
void DerivedClass::operation () { ParentClass::operation(); // DerivedClass extended behavior }- 1
- 2
- 3
- 4
不幸的是,人们很容易忘记去调用被继承的行为。我们可以将这样一个操作转换为一个模板方法,以使得父类可以对子类的扩展方式进行控制。也就是,在父类的模板方法中调用钩子操作。子类可以重定义这个钩子操作:
void ParentClass::operation () { // ParentClass behavior Hookoperation() ; }- 1
- 2
- 3
- 4
ParentClass本身的HookOperation什么也不做:
void ParentClass::Hookoperation () { }- 1
子类重定义HookOperation以扩展它的行为:
void DerivedClass::Hookoperation () { // derived class extension }- 1
- 2
- 3
8.实现
有三个实现问题值得注意:
- 使用C++访问控制
在C++中,一个模板方法调用的原语操作可以被定义为保护成员。这保证它们只被模板方法调用。必须重定义的原语操作须定义为纯虚函数。模板方法自身不需被重定义;因此可以将模板方法定义为一个非虚成员函数。
- 尽量减少原语操作
定义模板方法的一个重要目的是尽量减少-个子类具体实现该算法时必须重定义的那些原语操作的数目。需要重定义的操作越多,客户程序就越冗长。
- 命名约定
可以给应被重定义的那些操作的名字加上一个前缀以识别它们。例如,用于Macintosh应用的MacAp框架[App89]给模板方法加上前缀“Do-”,如“DoCreateDocument”,“DoRead”,等等。
9.代码示例
下面的C++实例说明了一个父类如何强制其子类遵循一种不变的结构。这个例子来自于NeXT的AppKit。考虑一个支持在屏幕上绘图的类View。一个视图在进入“焦点”( focus )状态时才可设定合适的特定绘图状态(如颜色和字体),因而只有成为“焦点”之后才能进行绘图。
View类强制其子类遵循这个规则。我们用Display模板方法来解决这个问题。View定 义两个具体操作,SetFocus和ResetFocus,分别设定和清除绘图状态。View 的DoDisplay钩子操作实施真正的绘图功能。Display在DoDisplay前调用SetFocus以设定绘图状态; Display此后 调用ResetFocus以释放绘图
状态。void View::Disp1ay () { SetFocus () ; DoDisplay() ; ResetFocus() ; }- 1
- 2
- 3
- 4
- 5
为维持不变部分,View的客 户通常调用Display,而View的子类通常重定义DoDisplay。View本身的DoDisplay什么也不做:
void View::DoDisplay () {}- 1
子类重定义它以增加它们的特定绘图行为:
void MyView::DoDisplay () { // render the view's contents }- 1
- 2
- 3
10.相关模式
Factory Method模式(3.3)常被模板方法调用。在动机一节的例子中,DoCreateDocument就是一个Factory Methoud,它由模板方法OpenDocument调用。
Strategy (5.9):模板方法使用继承来改变算法的一部分。Strategy使用委托来改变整 个算
5.11 VISITOR (访问者)
1.意图
表示一个作用于某对象结构中的各元素的操作。它使你可以在不改变各元素的类的前提下定义作用于这些元素的新操作。
当我们为基类增添一些功能时,这将让我们将各个子类依次修改。这显然是很不好的。因此,访问者去添加。
2.动机
考虑一个编译器,它将源程序表示为一个抽象语法树。该编译器需在抽象语法树上实施某些操作以进行“静态语义”分析,例如检查是否所有的变量都已经被定义了。它也需要生成代码。因此它可能要定义许多操作以进行类型检查、代码优化、流程分析,检查变量是否在使用前被赋初值,等等。此外,还可使用抽象语法树进行优美格式打印、程序重构、codeinstrumentation以及对程序进行多种度量。
这些操作大多要求对不同的节点进行不同的处理。例如对代表赋值语句的结点的处理就不同于对代表变量或算术表达式的结点的处理。因此有用于赋值语句的类,有用于变量访问的类,还有用于算术表达式的类,等等。结点类的集合当然依赖于被编译的语言,但对于一个给定的语言其变化不大。.
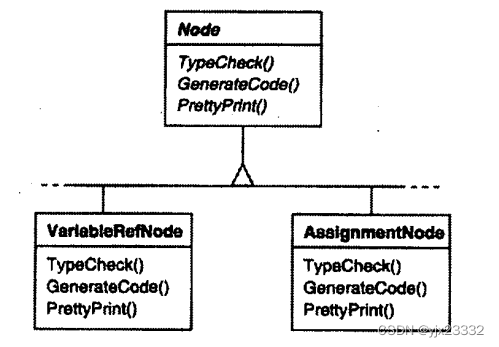
上面的框图显示了Node类层次的一部分。这里的问题是,将所有这些操作分散到各种结点类中会导致整个系统难以理解、难以维护和修改。将类型检查代码与优美格式打印代码或流程分析代码放在一起,将产生混乱。此外,增加新的操作通常需要重新编译所有这些类。
如果可以独立地增加新的操作,并且使这些结点类独立于作用于其上的操作,将会更好一些。
要实现上述两个目标,我们可以将每一个类中相关的操作包装在一个独立的对象(称为一个Visitor)中,并在遍历抽象语法树时将此对象传递给当前访问的元素。当一个元素“接受”该访问者时,该元素向访问者发送一个包含自身类信息的请求。该请求同时也将该元素本身作为一个参数。然后访问者将为该元素执行该操作一这一 操作以前是在该元素的类中的。
例如,一个不使用访问者的编译器可能会通过在它的抽象语法树上调用TypeCheck操作对一个过程进行类型检查。每一个结点将对调用它的成员的TypeCheck以实现自身的TypeCheck(参见前面的类框图)。如果该编译器使用访问者对一个过程进行类型检查,那么它将会创建一个TypeCheckingVisitor对象,并以这个对象为-一个参数在抽象语法树上调用Accept操作。每一个结点在实现Accept时将会回调访问者:一个赋值结点调用访问者的VisitAssignment操作,而一个变量引用将调用VisitVariableReference。以前类AssignmentNode的TypeCheck操作现在成为TypeCheckingVisitor的VisitAssignment操作。
为使访问者不仅仅只做类型检查,我们需要所有抽象语法树的访问者有一个抽象的父类NodeVisitor。NodeVisitor必须为每- 个结点类定义一个操作。 一个需要计算程序度量的应用将定义NodeVisitor的新的子类,并且将不再需要在结点类中增加与特定应用相关的代码。Visitor模式将每一个编译步骤的操作封装在一 个与该步骤相关的Visitor中(参见下图)。
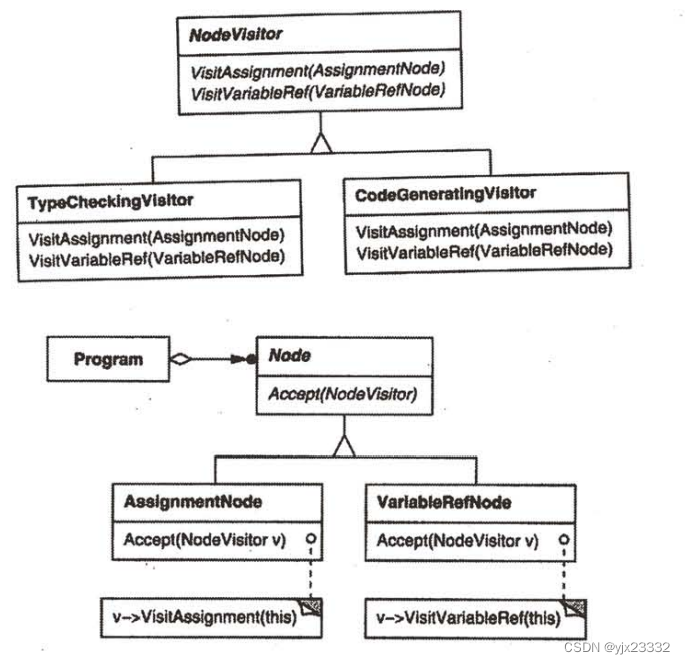
使用Visitor模式,必须定义两个类层次: -个对应于接受操作的元素( Node层次)另一个对应于定义对元素的操作的访问者( NodeVisitor层次)。给访问者类层次增加一个新的子类即可创建一个新的操作。只要该编译器接受的语法不改变(即不需要增加新的Node子类),我们就可以简单的定义新的NodeVisitor子类以增加新的功能。
3.适用性
在下列情况下使用Visitor模式:
- 一个对象结构包含很多类对象,它们有不同的接口,而你想对这些对象实施一些依赖于其具体类的操作。
- 需要对一个对象结构中的对象进行很多不同的并且不相关的操作,而你想避免让这些操作“污染”这些对象的类。Visitor使 得你可以将相关的操作集中起来定义在一个类中。当该对象结构被很多应用共享时,用Visitor模式让每 个应用仅包含需要用到的操作。
- 定义对象结构的类很少改变,但经常需要在此结构上定义新的操作。改变对象结构类需要重定义对所有访问者的接口,这可能需要很大的代价。如果对象结构类经常改变,那么可能还是在这些类中定义这些操作较好。
4.结构
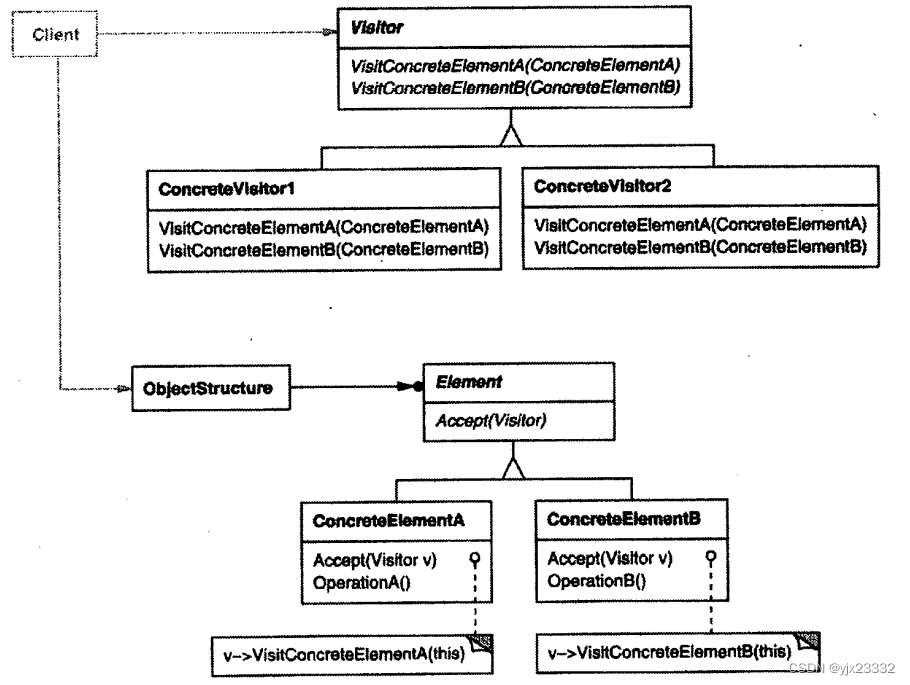
5.参与者
- Visitor (访问者,如NodeVisitor )
- 为该对象结构中ConcreteElement的每-一个类声明一个Visit操作。该操作的名字和特征标识了发送Visit请求给该访问者的那个类。这使得访问者可以确定正被访问元素的具体的类。这样访问者就可以通过该元素的特定接口直接访问它。
- ConcreteVisitor (具体访问者,如TypeCheckingVisitor )
- 实现每个由Visitor声明的操作。每个操作实现本算法的一部分,而该算法片断乃是对应于结构中对象的类。ConcreteVisitor为该算法提供了上下文并存储它的局部状态。
这一状态常常在遍历该结构的过程中累积结果。
- 实现每个由Visitor声明的操作。每个操作实现本算法的一部分,而该算法片断乃是对应于结构中对象的类。ConcreteVisitor为该算法提供了上下文并存储它的局部状态。
- Element(元素,如Node)
-定义一个Accept操作, 它以-一个访问者为参数。 - ConcreteElement (具体元素,如AssignmentNode, VariableRefNode )
- 实现Accept操作,该操作以-一个访问者为参数。
- ObjectStructure ( 对象结构,如Program )
- 能枚举它的元素。
- 可以提供一个高层的接口以允许该访问者访问它的元素。
- 可以是一个复合(参见Composite (4.3)) 或是一个集合,如一个列表或一个无序集合。
6.协作
- 一个使用Visitor模式的客户必须创建- -个ConcreteVisitor对象,然后遍历该对象结构,并用该访问者访问每一个元素。
- 当一个元素被访问时,它调用对应于它的类的Visitor操作。如果必要,该元素将自身作为这个操作的一个参数以便该访问者访问它的状态。
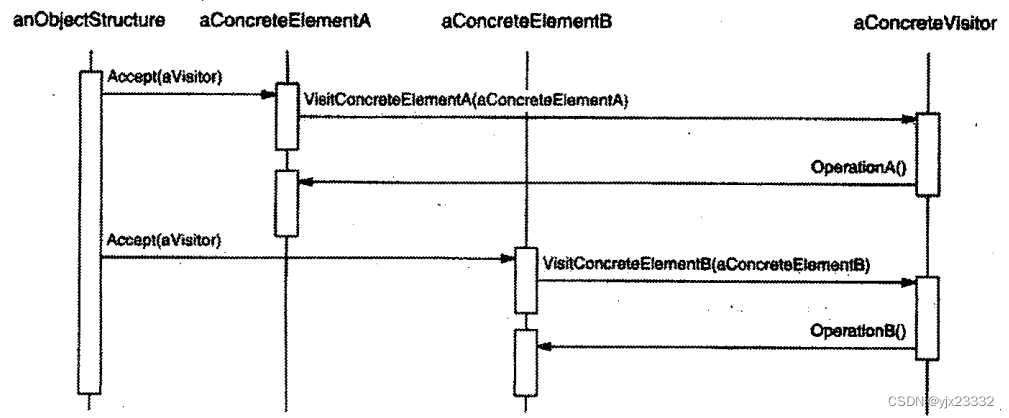
下面的交互框图说明了一个对象结构、一个访问者和两个元素之间的协作。
7.效果
下面是访问者模式的一些优缺点:
- 访问者模式使得易于增加新的操作
访问者使得增加依赖于复杂对象结构的构件的操作变得容易了。仅需增加一个新的访问者即可在一一个对象结构上定义-个新的操作。相反,如果每个功能都分散在多个类之上的话,定义新的操作时必须修改每一类。
- 访问者集中相关的操作而分离无关的操作
相关的行为不是分布在定义该对象结构的各个类上,而是集中在一个访问者中。无关行为却被分别放在它们各自的访问者子类中。这就既简化了这些元素的类,也简化了在这些访问者中定义的算法。所有与它的算法相关的数
据结构都可以被隐藏在访问者中。- 增加新的ConcreteElement类很困难
Visitor模式使得 难以增加新的Element的子类。每添加一个新的ConcreteElement都要在Vistor中添加一个新的抽象操作,并在每一个ConcretVisitor类中实现相应的操作。有时可以在Visitor中提供一个缺省的实现,这一实现可以被大多数的ConcreteVisitor继承,但这与其说是一个规律还不如说是一种例外。
所以在应用访问者模式时考虑关键的问题是系统的哪个部分会经常变化,是作用于对象结构上的算法呢还是构成该结构的各个对象的类。如果老是有新的ConcretElement类加入进来的话,Vistor类层次将变得难以维护。在这种情况下,直接在构成该结构的类中定义这些操作可能更容易一些。如果Element类层 次是稳定的,而你不断地增加操作获修改算法,访问者模
式可以帮助你管理这些改动。- 通过类层次进行访问
一个迭代器( 参见Iterator (5.4))可以通过调用节点对象的特定操作来遍历整个对象结构,同时访问这些对象。但是迭代器不能对具有不同元素类型的对象
结构进行操作。例如,定义在第5章的Iterator接口只能访问类型为Item的对象:template <class Item> class Iterator { Item CurrentItem() const; };- 1
- 2
- 3
- 4
这就意味着所有该迭代器能够访问的元素都有一一个共同的父类Item。访问者没有这种限制。它可以访问不具有相同父类的对象。可以对一个Visitor接口增加任何类型的对象。例如,在
class Visitor { public: //. ... void VisitMyType (MyType*); void VisitYourType (YourType*); }- 1
- 2
- 3
- 4
- 5
- 6
中,MyType和YourType可以完全无关,它们不必继承相同的父类。
- 累积状态
当访问者访问对象结构中的每一 个元素时,它可能会累积状态。如果没有访问者,这一状态将作为额外的参数传递给进行遍历的操作,或者定义为全局变量。
- 破坏封装
访问者方法假定ConcreteElement接口的功能足够强,足以让访问者进行它
们的工作。结果是,该模式常常迫使你提供访问元素内部状态的公共操作,这可能会破坏它的封装性。8.实现
每一个对象结构将有一个相关的Visitor类。 这个抽象的访问者类为定义对象结构的每一个ConcreteElement类声明一个VisitConcreteElement操作。每一个Visitor. 上的Visit操作声明它的参数为一个特定的ConcreteElement,以允许该Visitor直接访问ConcreteElement的接口。
ConcreteVistor类重定义每一个Visit操作,从而为相应的ConcreteElement类实现与特定访问者相关的行为。
在C++中,Visitor类可 以这样定义:class Visitor { public: virtual void VisitEl ementA (E1 ementA*); virtual void VisitEl ementB (E1 ementB*); // and so on for other concrete elements protected: Visitor(); };- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
每个ConcreteElement类实现一个Accept操作,这个操作调用访问者中相应于本ConcreteElement类的Visit…的操作。这样最终得到调用的操作不仅依赖于该元素的类也依赖于访问者的类。
具体元素声明为:class Element { public: virtual ~Element(); virtual void Accept(Visitor&) = 0; protected: E1ement() ; }; class ElementA:public Element { public: ElementA() ; virtual void Accept (Visitor& v) { v.VisitElementA(this);} }; class ElementB : public Element { public: ElementB(); virtual void Accept (Visitor& v) { v.VisitElementB(this); } };- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
一个CompositeElement类可能象这样实现Accept:
class CompositeElement:public Element { public: virtual void Accept (Visitor&); private: List <Element*>* _children; }; void CompositeE1ement::Accept(Visitor& v){ List Iterator<Element*> i (_children); for (i.First(); !i.IsDone(); i.Next()){ i.CurrentItem()->Accept(v); } v.VisitCompositeElement(this); }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
下面是当应用Visitor模式时产生的其他两个实现问题:
- 双分派( Double-dispatch )
访问者模式允许你不改变类即可有效地增加其上的操作。为达到这一效果使用了一种称为双分派( double-dispatch )的技术。这一种很著名的技术。
事实上,一些编程语言甚至直接支持这一技术(例如,CLOS )。而象C++和Smalltalk这样的语言支持单分派( single-dispatch )。在单分派语言中,到底由哪一种操作将来实现一个请求取决于两个方面:该请求的名和接收者的类型。
例如,一个GenerateCode请求将会调用的操作决定于你请求的结点对象的类型。在C++中,对一个VariableRefNode实例调用GenerateCode将调用VariableRefNode::GenerateCode (它生成一个变量引用的代码 )。而对一个AssignmentNode调 用GenerateCode将调用Assignment::GenerateCode (它生成一个赋值操作的代码)。所以最终哪个操作得到执行依赖于请求和接收者的类型两个方面。
双分派意味着得到执行的操作决定于请求的种类和两个接收者的类型。Accept是一个double dispatch操作。它的含义决定于两个类型: Visitor的类 型和Element的类型。双分派使得访问者可以对每一个类元的素请求不同的操作。
这是Visitor模式的关键所在:得到执行的操作不仅决定于Visitor的类型还决定于它访问的Element的类型。可以不将操作静态地绑定在Element接口中,而将其安放在一个Visitor中,并使用Accept在运行时进行绑定。扩展Element接 口就等于定义一个新的Visitor子类而不是多个新的Element子类。
- 谁负责遍历对象结构
一个访问者必须访问这个对象结构的每一个元素。问题是,它怎样做?我们可以将遍历的责任放到下面三个地方中的任意一个:对象结构中,访问者中,或一个独立的迭代器对象中( 参见Iterator (5.4))。
通常由对象结构负责迭代。一个集合只需对它的元素进行迭代,并对每一个元素调用Accept操作。而一个复合通常让Accept操作遍历该元素的各子构件并对它们中的每一个递归地调用Accept。
另一个解决方案是使用一个迭代器来访问各个元素。在C++中,既可以使用内部迭代器也可以使用外部迭代器,到底用哪一个取决于哪一个可用和哪一个最有效。在Smaltalk中, 通常使用一个内部迭代器,这个内部迭代器使用do:和一个块。因为内部迭代器由对象结构实现,使用一个内部迭代器很大程度上就像是让对象结构负责迭代。
主要区别在于一个内部迭代器不会产生双分派一它将 以该元素为一个参数调用访问者的一个操作而不是以访问者为参数调用元素的一个操作。不过,如果访问者的操作仅简单地调用该元素的操作而无需递归的话,使用一个内部迭代器的Visitor模式很容易使用。甚至可以将遍历算法放在访问者中,尽管这样将导致对每一个聚合ConcreteElement,在每一个ConcreteVisitor中都要复制遍历的代码。将该遍历策略放在访问者中的主要原因是想实现一个特别复杂的遍历,它依赖于对该对象结构的操作结果。我们将在代码示例一节给出这
种情况的一个例子。9.代码示例
因为访问者通常与复合相关,我们将使用在Composite ( 4.3)代码示例一节中定义的Equipment类来说明Visitor模式。我们将使用Visitor定义一些用于计算材料存货清单和单件设备总花费的操作。Equipment类非常简 单,实际上并不一定要使用Visitor。但我们可以从中很容易地看出实现该模式时会涉及的内容。
这里是Composite (4.3)中的Equipment类。我们给它添加一个Accept操作,使其可与一个访问者一起工作。
class Equipment { public; virtual ~Equipment() ; const char* Name() { return_ name; } virtual watt Power (); virtual Currency NetPrice (); virtual Currency DiscountPrice() ; virtual void Accept (EquipmentVisitor&); protected: Equipment(const char*); . private: const char* name; };- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
各Equipment操作返回设备的属性,例如它的功耗和价格。对于特定种类的设备(如,底盘、发动机和平面板)子类适当地重定义这些操作。
如下所示,所有设备访问者的抽象父类对每一个设备子类都有一个虚函数。所有的虚函数的缺省行为都是什么也不做。
class EquipmentVisitor { public: virtual ~EquipmentVisitor(); virtual void VisitFloppyDisk (FloppyDisk*); virtual void VisitCard(Card*); virtual void VisitChassis (Chassis") : virtual vold VisitBus(Bus*); // and so on for other concrete subclasses of Equipment protected: EquipmentVisitor(); };- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
Equipment子类以基本相同的方式定义Accept:调用EquipmentVisitor中的对应于接受Accept请求的类的操作,如:
void FloppyDisk::Accept (EquipmentVisitor& visitor) { visitor.VisitFloppyDisk(this); }- 1
- 2
- 3
包含其他设备的设备(尤其是在Composite模式中CompositeEquipment的子类)实现Accept时,遍历其各个子构件并调用它们各自的Accept操作,然后对自己调用Visit操作。例如,Chassis::Accept可 象如下这样遍历底盘中的所有部件:
void Chassis::Accept (EquipmentVisitor& viaitor) ( for(ListIterator<Bquipment*> i(_parta);!i.IsDone();i.Next()){ i.CurrentItem()->Accept(visitor); visitor.VisitChassis(this) ; } }- 1
- 2
- 3
- 4
- 5
- 6
EquipmentVisitor的子类在设备结构上定义了特定的算法。PricingVisitor计算该设 备结构的价格。它计算所有的简单设备(如软盘)的实价以及所有复合设备(如底盘和公共汽车)打折后的价格。
class PricingVisitor : public EquipmentVisitor { pub1ic: PricingVisitor(); Currency& GetTotalPrice() : virtual void visitFloppyDiak(FloppyDisk*); virtual void VisitCard(Card*); virtual void VisitChassis (Chassis*); virtual vold VisitBus(Bug*); // ... private: Currency _total; }; void PricingVisitor::VisitFloppyDisk (FloppyDisk* e) { _total += e->NetPrice(); } void PricingVisitor::VisitChassis (Chassis* e) { _total += e->DiscountPrice() ; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
PricingVisitor将计算设备结构中所有结点的总价格。注意PricingVisitor在 相应的成员函数中为一类设备选择合适的定价策略。此外,我们只需改变PricingVisitor类即可改变一个设备结构的定价策略。
我们可以象这样定义一个计算存货清单的类:
class InventoryVisitor : public EquipmentVisitor { public: InventoryVisitor(); Inventory& GetInventory(); virtual void VisitFloppyDisk (FloppyDisk*); virtual void VisitCard (Card*); virtual void VisitChassis (Chassis*) ; virtual void VisitBus (Bus*) ; private: Inventory_ inventory; );- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
InventoryVisitor为对象结构中的每一种类型的设备累计总和。InventoryVisitor使用一个Inventory类,Inventory类定义了 一个接口用于增加设备(此处略去)。
void InventoryVisitor::VisitFloppyDisk (FloppyDisk* e) { _inventory.Accumulate(e); } void InventoryVisitor: :VisitChassis (Chassis* e) { _inventory.Accumulate(e); }- 1
- 2
- 3
- 4
- 5
- 6
下面是如何在一个设备结构上使用InventoryVisitor:
Equipment* component; InventoryVisitor visitor; component->Accept (visitor) ; cout << "Inventory"<< component->Name()<< visitor.GetInventory();- 1
- 2
- 3
- 4
现在我们将说明如何用Visitor模式实现Interpreter模式中那个Smalltalk的例(5.3)。 像上面的例子一样,这个例子非常小,Visitor 可能并不能带给我们很多好处,但是它很好地说明了如何使用这个模式。此外,它说明了一种情况,在此情况下迭代是访问者的职责。
该对象结构( 正则表达式)由四个类组成,并且它们都有一个accept:方法,它以某访问者为一个参数。在类SequenceExpression中,accept方法是:
accept :aVisitor ^aVisitor visitSequence: self- 1
- 2
在类RepeatExpression中,accept:方 法发送visitRepeat消息;在类AlternationExpression中,它发送visitAlternation:消息;而在类LiteralExpression中,它发送visitLiteral:消息。这四个类还必须有可供Vistor使用的访问函数。对于SequenceExpression这些函数是expression1和expression2;对于AlternationExpression这些函数是alternative1和alternative2;对于RepeatExpression是repetition;而对于LiteralExpression则是component。
具体的访问者是REMatchingVisitor。因为它所需要的遍历算法是不规则的,因此由它自己负责进行遍历。其最大的不规则之处在于RepeatExpression要重复遍历它的构件。REMatchingVisitor类有一个实例变量inputState。它的各个方法除了将名字为inputState的参数替换为匹配的表达式结点以外,与Interpreter模式中表达式类的match:方法基本上是一样的。它们还是返回该表达式可以匹配的流的集合以标识当前状态。

10.相关模式
Composite ( 4.3):访问者可以用于对一个由Composite模式定义的对象结构进行操作。
Interpreter (5.3):访问者可以用于解释。
资料
[1]《设计模式:可复用面向对象软件的基础》(美) Erich Gamma Richard Helm、Ralph Johnson John Vlissides 著 ; 李英军、马晓星、蔡敏、刘建中 等译; 吕建 审校
-
相关阅读:
【精讲】微信小程序 基础内容(组件) 轮播图及滚动菜单等
Qt 简约又简单的加载动画 第七季 音量柱风格
02-uboot启动内核前到底做了哪些必要工作
08.URL调度器示例
Redis实现消息队列
通过API接口进行商品价格监控,可以按照以下步骤进行操作
云程发轫,万里可期 | 云扩科技再次入选Gartner《2022年中国ICT技术成熟度曲线报告》
python基于php+MySQL的网络精品课程教学平台
MyBatis入门学习一(引入配置、体验CURD)
【公司UI自动化学习】
- 原文地址:https://blog.csdn.net/weixin_46949627/article/details/127641322