-
video caption with frame selection【论文阅读】
文章目录
- 1. Less Is More: Picking Informative Frames for Video Captioning
- 2.SBAT: Video Captioning with Sparse Boundary-Aware Transformer
- 3. Augmented Partial Mutual Learning with Frame Masking for Video Captioning
- 4. SWINBERT: End-to-End Transformers with Sparse Attention for Video Captioning
- 5. Enhancing the alignment between target words and corresponding frames for video captioning
- 6. KSF-ST: Video Captioning Based on Key Semantic Frames Extraction and Spatio-Temporal Attention Mechanism
- 7. An Efficient Keyframes Selection Based Framework for Video Captioning
- 8. Research on Video Captioning Method Based on Semantic Key Frame
1. Less Is More: Picking Informative Frames for Video Captioning
- 发表:ECCV 2018
- idea:等间隔采样会带来冗余和噪声信息,作者基于强化学习设计了PickNet选择合适的帧(奖励:从视觉层面能够保证特征的多样性;从语言层面能够为生成caption提供有效的信息)。此外PickNet是即插即用的,也可以迁移到其他网络中
1.1 PickNet
总体框架还是基于encoder-decoder的,PickNet用于选择合适的帧,然后送给Encoder-decoder生成caption。此外PickNet是在不了解global information的情况下选择信息丰富的frames,决策只能基于当前的观察和历史。
- 帧处理
对每个输入帧 z t z_t zt,将其转换为灰度图,然后resize得到 g t g_t gt,与上一次选择的frame g ~ \tilde{g} g~相减得到差值 d t d_t dt,经过两层全连接层输出Bernoulli distribution决定是否选择当前帧
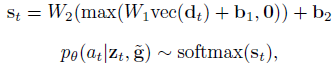
1.2 Rewards
- Language Reward:选择caption和annotations的Cider值作为reward(在翻译中常用)

- Visual Diversity Reward:由于仅使用语言奖励可能会错过一些重要的视觉信息,并且希望选择的帧能够更具多样性,使用pairwise的余弦距离作为奖励
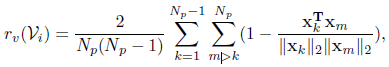
- Picks Limitation:对帧的数量进行限制。最小值 N m i n = 3 N_{min}=3 Nmin=3, N m a x N_{max} Nmax设置为视频帧数量的一半,随着迭代次数增加,减小 N m a x N_{max} Nmax直到达到阈值 τ \tau τ
- objective reward
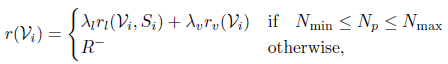
1.3 Training
训练分为三个阶段,分别是监督阶段,强化阶段以及联合训练
- Supervision Stage
传统的caption过程,使用交叉熵损失计算caption与annotation的分类损失
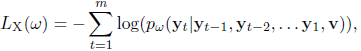
- Reinforcement Stage
固定encoder-decoder将其视为environment,使用强化学习优化PickNet。目标是最小化负奖励

经过一系列推导和求导得到最终的梯度表达式:(这里使用的是self-critical策略)

- Adaptation Stage
在训练encoder-decoder的时候是使用了所有帧,但是在强化学习阶段只使用了部分,因此联合训练以缩小gap是有必要的。
但是pick过程是不可微分的。这里我们在每个迭代中,前向过程生成frame picks;后向过程两种策略像平常一样优化过程。类似在时间序列中使用dropout一样。(这块不是很懂,待补充)
2.SBAT: Video Captioning with Sparse Boundary-Aware Transformer
- 发表:IJCAI 2020
- idea:主要是对attention进行改进,对于attention求得的注意力分数求导(离散求导:差值),选择导数值top-n的特征。在此基础上,保留原始logits较大的一些特征(对目标可能比较重要)
2.1 Sparse Boundary-Aware Pooling
- 求注意力的logits
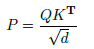
- 对logis求离散导数
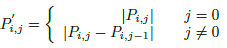
- 对应的softmax function
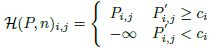
c i c_i ci是 P ′ P' P′中第n大的值 - 保留original logits中较大的值(重要性较高)
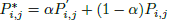
2.2 Local Correlation
由于引入了上述稀疏边界感知策略,连续帧之间的局部信息会被忽略。因此作者在多头注意力机制中设计了一个局部相关方案来弥补忽略的局部信息
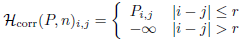
r r r表示两帧的最大距离2.3 Cross-Modal Scheme
- 将视频分为固定数量的chunk,每一个时间步提取的特征都是来自同一个chunk的
- 使用了cross attention在motion feature和appearance feature之间
2.4 experiments
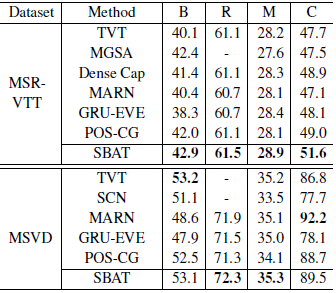
- 小结:这篇文章有一定的启发,相似帧的特征是相似的,因此在执行attention的时候会得到类似的分数,这其实对模型来讲确实是不好的(一方面是冗余,另一方面如果分数较高会削减其他特征的重要性),所以attention其实并不是真正的能学习到重要性,它还是在一定程度上基于先验(相似性)。所以有时候必要的公式推理是重要的。
3. Augmented Partial Mutual Learning with Frame Masking for Video Captioning
- 发表:AAAI 2021
- idea:(1)多模型联合训练还没有被充分探索。对于这个问题,作者使用一种相互学习+数据增强的方式(2)“one-to-many”映射问题,即一个视频对应多个annotation。针对这个问题,作者提出使用frame mask使得每个annotation对应的视频帧序列不同将问题转化为“one-to-one”问题
3.1 Multiple Encoders
主要用了三个Encoders。(1)global encoder:ECO网络(action 识别,主要是appearance && motion)。(2)local encoder:Faster R-CNN+GCN,主要用来提取object及其关系。(3)semantic encoder:没看懂,大致是选了Q个高频词作为属性然后和ECO的预测分布concatenate。最终的特征是三个concatenate
2.2 Multiple Decoders
-
Caption loss:

T表示序列长度,H表示一个视频对应的H个annotation; -
Mutual Learning:与其他m-1个decoder预测之间的KL散度
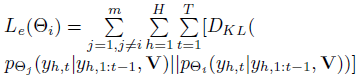
-
Augmented Partial Mutual Learning:对视频特征做数据增强K次,每个视频特征得到K个变体得到内部损失 L α L_\alpha Lα和外部损失 L e L_e Le

3.3 Frame Masking
- 将视频特征(上述特征接两层全连接层)和文本特征(bert)映射到同一空间,求均方误差d。
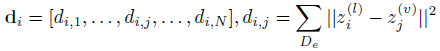 …
… 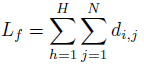
- Masking:两种方式(1)soft masking:
1
d
\frac{1}{d}
d1作为frame的权重;(2)阈值界定,选择top F帧。第二种方式更好。
ps:frame的选择只是在训练阶段使用,在测试阶段是使用全部帧,因为测试的时候没有annotation。 - overall loss:
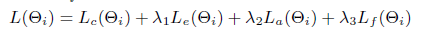
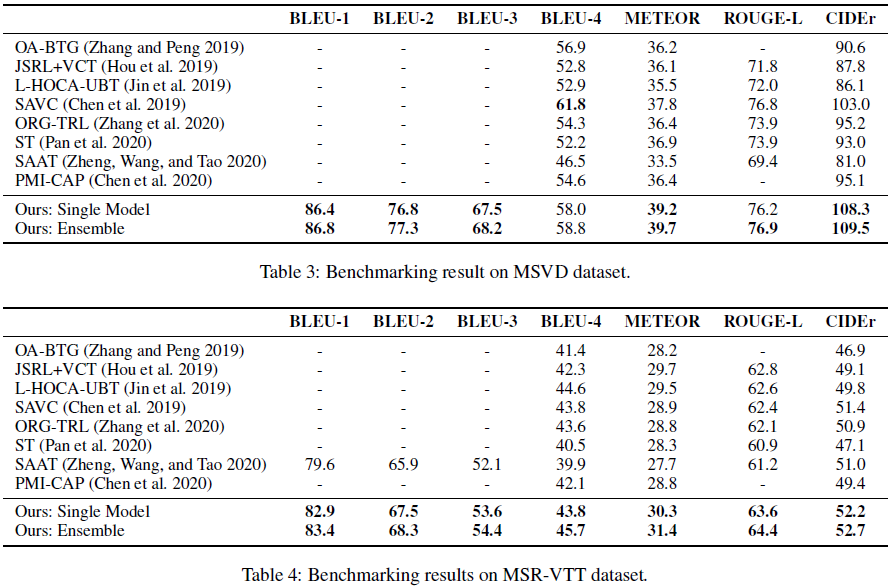
3.4 experiments
4. SWINBERT: End-to-End Transformers with Sparse Attention for Video Captioning
- 发表:CVPR 2022
- idea:主体框架基于transformer,先用video swin transformer提取视频特征,然后和文本特征一起输入transformer encoder中生成caption,训练时使用mlm任务。作者在实验过程中发现,密集采样能够让性能提升,但是为了减少连续帧之间的冗余,提出一种可学习的sparse attention mask。
- 全文解读戳论文阅读【SWINBERT: End-to-End Transformers with Sparse Attention for Video Captioning】
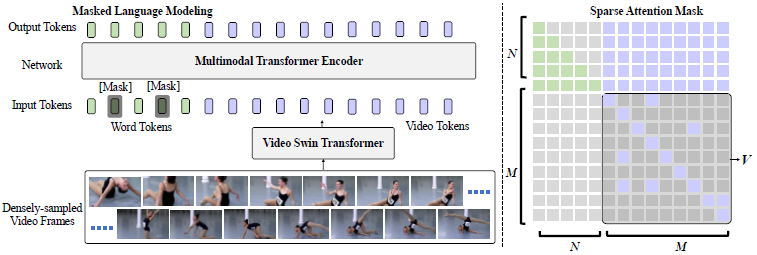
4.1 Sparse Attention Mask
其实就是对视频特征( M × M M \times M M×M)进行mask,mask的部分设置为参数,可学习。稀疏性作为损失进行限制
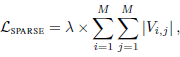
- objective loss
L = L M L M + L S P A R S E L=L_{MLM}+L_{SPARSE} L=LMLM+LSPARSE
ps:这里在训练的时候decoder的word token也是使用了sequence mask。
5. Enhancing the alignment between target words and corresponding frames for video captioning
- 发表:Pattern Recognition 2021
- 代码:Enhancing the alignment between target words and corresponding frames for video captioning
- idea:作者主要是想改进视频帧序列和caption单词序列的对齐问题。他认为之前的方法直接使用生成的词汇对frames进行选择有一定难度。一方面视觉和语言的鸿沟难以跨越;另一方面句子中绝大多数的单词都是非视觉词汇,因此能够提供的信息较少。
- method:基于上述问题,作者提出使用visual tags来连接视觉和语言,因为visual tag既关联了图片中的一定视觉区域,又属于语言的一部分(可是这不是Oscar提出的吗?)。简单来讲就是由原来的通过之前生成的句子(具体是指hidden state h t h_t ht)指导frame选择变成了 h t h_t ht指导选择visual tags,然后visual tags加入指导frame选择。
5.1 visual tags
- Visual tag vocabulary:这里用的是Visual Genome dataset中的3000个类别作为词表,因为发现它包含了MSR-VTT中的视觉词汇。
- Visual tag detector:使用 M a s k X R − C N N Mask^X R-CNN MaskXR−CNN框架,backbone为ResNet-101- FPN
- Visual tag extraction:对每帧图像,检测其中的object并挑出其中置信度大于0.5的,然后对所有帧中的object按照出现频率排序,选择高频top-n,不足n补
5.2 decoder
基于LSTM,2D feature v = v 1 , v 2 , . . . , v k v={v_1,v_2,...,v_k} v=v1,v2,...,vk
-
Textual Attention: h t − 1 h_{t-1} ht−1对tags进行注意(ps:我觉得这里不应该叫选择,而是注意/聚合/加权)
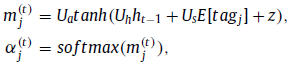
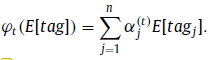
-
Temporal Attention:过程类似,只是指导不同,变成了 h t − 1 h_{t-1} ht−1和 enhanced tag对frames进行注意
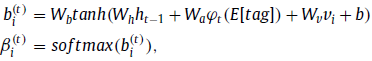
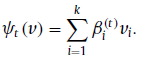
-
最后将所有特征concatenate再映射到voc纬度得到预测单词
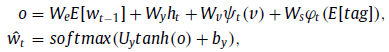
5.3 experiments
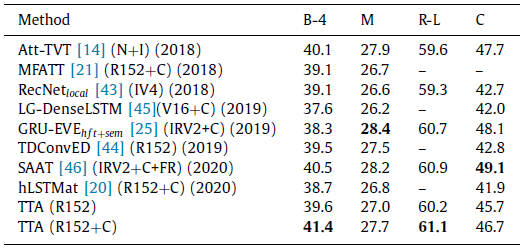
- 小结:感觉就是用了Oscar的idea,而且后面的聚合也是前人的方式。关键是这篇文章都没有提及Oscar。。。
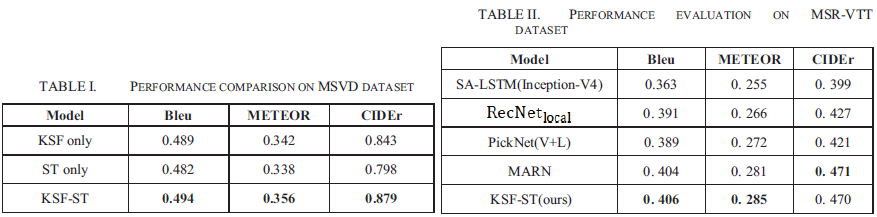
6. KSF-ST: Video Captioning Based on Key Semantic Frames Extraction and Spatio-Temporal Attention Mechanism
- 发表:IWCMC 2020
- idea:也是为了解决等间隔采样的问题。核心思想是采用knowledge graph筛选key frames;然后在decoder部分使用spatial-temporal attention
6.1 Key Semantic Frames Extraction
没看懂。。。大致是用来LSTM来编码语言信息,然后CNN来编码视频信息。
- named entity recognition (NER) module
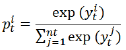
y t i y_t^i yti为LSTM的输出, p t i p_t^i pti标准化后的实体标签概率 - relation classification (RC) module
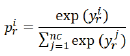
y r i y_r^i yri为CNN的输出, p r i p_r^i prisentence描述关系i的概率
然后基于实体和关系构建了一个graph
6.2 Extraction of Key Semantic Frames:
- 预处理:使用灰度直方图除去冗余帧,差值小于阈值去除
- tag检测:使用了Faster R-CNN检测的tag,并使用top-5 tags
- 搜索和筛选:使用语义树搜索找到与词典中的单词相关的实体及与其相连的实体,计算单词与实体s之间的相似度,若相似度之和大于阈值则选择当前帧
6.3 Spatial-Temporal attention
- spatial attention:CBAM模块(前人提出的):CBAM模块结合了空间和通道两个维度的注意机制,其效果优于单一的空间注意机制。这里将CBAM添加到ResNet中
- temporal attention:时间特征的提取和视频字幕的生成是通过使用与LSTM相结合的时间注意力机制来实现的
- caption generation:经过空间注意的特征输入到decoder(LSTM with temporal feature extraction netword)
6.4 experiments
比较的方法都偏老
7. An Efficient Keyframes Selection Based Framework for Video Captioning
- 发表:NLPAI 2021
- idea:类似想改进等间隔采样。但是选择关键帧的方法比较古老,是基于颜色直方图。decoder部分感觉方法不太具有条理性和逻辑性。。。
7.1 Boundary detection and keyframe selection phase
- 将视频分块。对每一帧计算颜色直方图,并计算相邻两帧的差值。若差值超过阈值 γ = m e a n ( d i ) + k × s t d ( d i ) \gamma=mean(d_i)+k\times std(d_i) γ=mean(di)+k×std(di)则表明需要分块。
- 关键帧选择:在每一块视频段中选择一帧图像与段中其他图像的差值之和最小
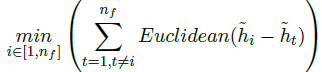
7.2 Description generation phase
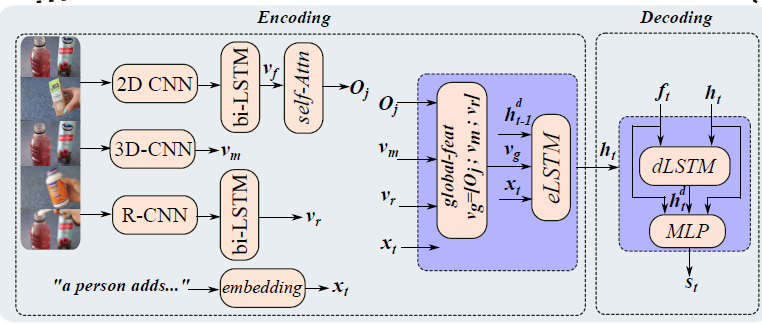
appearance feature :初始 v f v_f vf经过self-attention强化得到新的appearance feature O$$,motion feature v m v_m vm,object feature v r v_r vr
- feature encoder:将上述三种特征concatenate之后作为encoder的feature
v
g
v_g
vg输入LSTM encoder
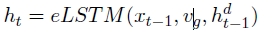
- 对appearance feature和region feature分别做
h
t
h_t
ht指导的cross attention,然后所有特征concatenate在一起作为decoder的feature输入LSTM
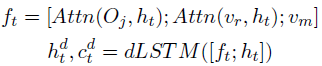
- 最后concatenate encoder和decoder的hidden state以及decode feature
f
t
f_t
ft得到输出单词
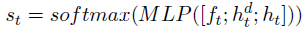
7.3 Experiments
比较的都是一些少见的方法,,,不放也罢。这篇文章是因为最近在看key frame相关的内容,但是相关paper很少,关键词搜索只有这几篇,所以也看了看。decoder的部分感觉处理有些冗余和杂乱,并没有讲清楚这么处理的原因和想法,而且陈述顺序上让人很难理解处理流程。不过其实这里LSTM encoder和LSTM decoder还是有一点吸引我的。
8. Research on Video Captioning Method Based on Semantic Key Frame
- 发表:ACCTCS 2022
- idea:基于平均采样的现有方法选择的frames存在大量冗余且缺乏多样性;作者考虑用语义信息指导frame选择。具体而言,先使用CNN提取帧特征,然后使用image caption方法得到每一帧的语义标注,基于语义标注的相似度选择key frame,然后使用预交互(基于动dot product)的LSTM得到caption。
8.1 key frame extraction(2D)
- 目标:less number and high diversity
- 方法:使用pretrained InceptionResnetV2得到每一帧的2d特征,将这些特征输入image caption model得到每一帧的caption,将caption输入bert得到semantic feature
s
i
s_i
si,计算相邻真的相似度,低于阈值(所有相邻帧相似度平均值)则为key frame
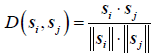 ,
, 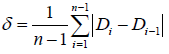
8.2 3D feature && region feature
-
3D:C3D+使用金字塔卷积来捕捉多尺度上下文交互信息来提高视频的细粒度动态特性

 ,k=2,3,5
,k=2,3,5 -
与SAAT中处理相同,faster-RCNN V r V_r Vr+位置信息 B B B
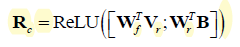
8.3 decoder
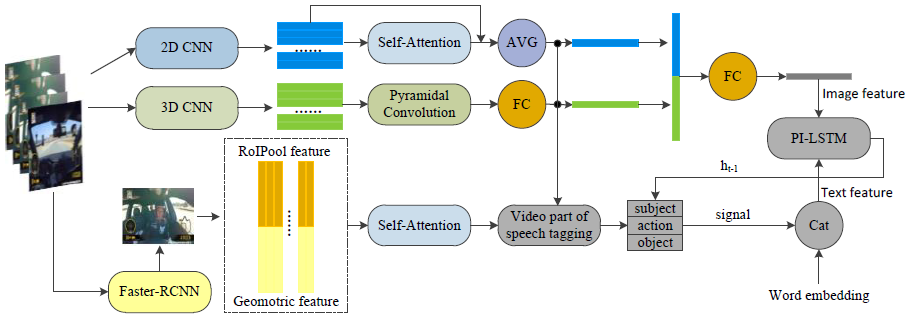
- 使用了SAAT中的主谓宾预测( y i y_i yi)
- 通过点积处理多模态之间的交互(
I
I
I表示全局特征,
T
T
T为主谓宾预测词)
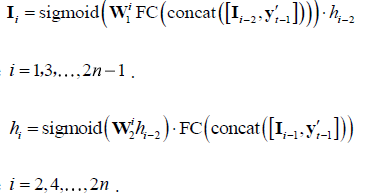
- 小结:总体感觉虽然文章的亮点是semantic key frame,但是做法过于复杂,甚至是使用到了image caption model 和 bert,最后也只是基于相似度;decoder部分感觉没什么亮点,基本上比较新颖的部分都是SAAT(region embedding、主谓宾等),可能唯一的点就是点积吧,但是点积在多模态融合领域已经不算新了。。。
8.4 experiments

-
相关阅读:
Hystrix线程池创建,调用
【Opencv450】HOG+SVM 与Hog+cascade进行行人检测
【React】第十部分 redux
YOLOV1详解——Pytorch版
vue中diff算法原理
Oracle/PLSQL: Sinh Function
js正则练习示例
ESP8266-Arduino编程实例-PIR(被动红外)传感器驱动
P1101 单词方阵——dfs
肖sir__面试接口测试
- 原文地址:https://blog.csdn.net/hei_hei_hei_/article/details/127508253