-
Netty-bytebuf
ByteBuf缓冲区
Netty提供了ByteBuf来替代Java NIO的ByteBuffer缓冲区,以操纵内存缓冲区。
ByteBuf与Java NIO的byteBuffer的对比
ByteBuf的优势
- Pooling (池化,这点减少了内存复制和GC,提升了效率)
- 复合缓冲区类型,支持零复制
- 不需要调用flip()方法去切换读/写模式
- 扩展性好,例如StringBuffer· 可以自定义缓冲区类型
- 读取和写入索引分开
- 方法的链式调用
- 可以进行引用计数,方便重复使用
ByteBuf的逻辑部分
ByteBuf是一个字节容器,内部是一个字节数组。从逻辑上来分,字节容器内部可以分为四个部分,具体如图6-14所示。
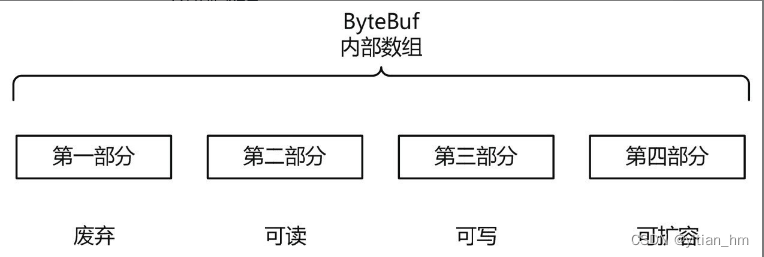
第一个部分是已用字节,表示已经使用完的废弃的无效字节;第二部分是可读字节,这部分数据是ByteBuf保存的有效数据,从ByteBuf中读取的数据都来自这一部分;
第三部分是可写字节,写入到ByteBuf的数据都会写到这一部分中;
第四部分是可扩容字节,表示的是该ByteBuf最多还能扩容的大小。
ByteBuf的重要属性
ByteBuf通过三个整型的属性有效地区分可读数据和可写数据,使得读写之间相互没有冲突。这三个属性定义在AbstractByteBuf抽象类中,分别是
-
readerIndex(读指针)
-
writerIndex(写指针)
-
maxCapacity(最大容量)
ByteBuf的这三个重要属性,如图6-15所示。
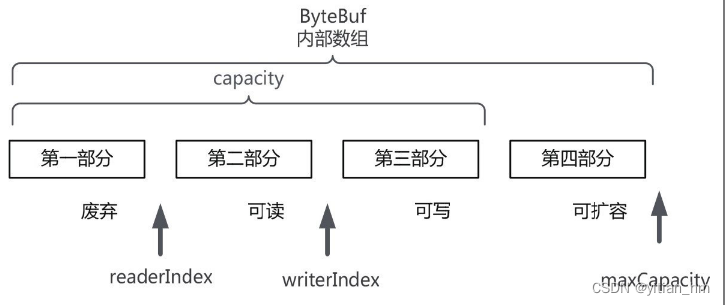
这三个属性的详细介绍如下:
- readerIndex(读指针):指示读取的起始位置。每读取一个字节,readerIndex自动增加1。一旦readerIndex与writerIndex相等,则表示ByteBuf不可读了。
- writerIndex(写指针):指示写入的起始位置。每写一个字节,writerIndex自动增加1。一旦增加到writerIndex与capacity()容量相等,则表示ByteBuf已经不可写了。capacity()是一个成员方法,不是一个成员属性,它表示ByteBuf中可以写入的容量。注意,它不是最大容量maxCapacity。
- maxCapacity(最大容量):表示ByteBuf可以扩容的最大容量。当向ByteBuf写数据的时候,如果容量不足,可以进行扩容。扩容的最大限度由maxCapacity的值来设定,超过maxCapacity就会报错。
ByteBuf的三组方法
ByteBuf的方法大致可以分为三组。
第一组:容量系列
- capacity():表示ByteBuf的容量,它的值是以下三部分之和:废弃的字节数、可读字节数和可写字节数。
- maxCapacity():表示ByteBuf最大能够容纳的最大字节数。当向ByteBuf中写数据的时候,如果发现容量不足,则进行扩容,直到扩容到maxCapacity设定的上限。
第二组:写入系列
- isWritable() :表示ByteBuf是否可写。如果capacity()容量大于writerIndex指针的位置,则表示可写,否则为不可写。注意:如果isWritable()返回false,并不代表不能再往ByteBuf中写数据了。如果Netty发现往ByteBuf中写数据写不进去的话,会自动扩容ByteBuf。
- writableBytes() :取得可写入的字节数,它的值等于容量capacity()减去writerIndex。
- maxWritableBytes() :取得最大的可写字节数,它的值等于最大容量maxCapacity减去writerIndex。
- writeBytes(byte[] src) :把src字节数组中的数据全部写到ByteBuf。这是最为常用的一个方法。
- writeTYPE(TYPE value):写入基础数据类型的数据。TYPE表示基础数据类型,包含了8大基础数据类型。具体如下:writeByte()、 writeBoolean()、writeChar()、writeShort()、writeInt()、writeLong()、writeFloat()、writeDouble()。
- setTYPE(TYPE value):基础数据类型的设置,不改变writerIndex指针值,包含了8大基础数据类型的设置。具体如下:setByte()、 setBoolean()、setChar()、setShort()、setInt()、setLong()、setFloat()、setDouble()。setType系列与writeTYPE系列的不同:setType系列不改变写指针writerIndex的值;writeTYPE系列会改变写指针writerIndex的值。
- markWriterIndex()与resetWriterIndex():这两个方法一起介绍。前一个方法表示把当前的写指针writerIndex属性的值保存在markedWriterIndex属性中;后一个方法表示把之前保存的markedWriterIndex的值恢复到写指针writerIndex属性中。markedWriterIndex属性相当于一个暂存属性,也定义在AbstractByteBuf抽象基类中。
第三组:读取系列
-
isReadable( ) :返回ByteBuf是否可读。如果writerIndex指针的值大于readerIndex指针的值,则表示可读,否则为不可读。
-
readableBytes( ) :返回表示ByteBuf当前可读取的字节数,它的值等于writerIndex减去readerIndex。
-
readBytes(byte[] dst):读取ByteBuf中的数据。将数据从ByteBuf读取到dst字节数组中,这里dst字节数组的大小,通常等于readableBytes()。这个方法也是最为常用的一个方法之一。
-
readType():读取基础数据类型,可以读取8大基础数据类型。具体如下:readByte()、readBoolean()、readChar()、readShort()、readInt()、readLong()、readFloat()、readDouble()。
-
getTYPE(TYPE value):读取基础数据类型,并且不改变指针值。具体如下:getByte()、 getBoolean()、getChar()、getShort()、getInt()、getLong()、getFloat()、getDouble()。getType系列与readTYPE系列的不同:getType系列不会改变读指针readerIndex的值;readTYPE系列会改变读指针readerIndex的值。
-
markReaderIndex( )与resetReaderIndex( ) :这两个方法一起介绍。前一个方法表示把当前的读指针ReaderIndex保存在markedReaderIndex属性中。后一个方法表示把保存在markedReaderIndex属性的值恢复到读指针ReaderIndex中。markedReaderIndex属性定义在AbstractByteBuf抽象基类中。
ByteBuf基本使用的实践案例
ByteBuf的基本使用分为三部分:
(1)分配一个ByteBuf实例;
(2)向ByteBuf写数据;
(3)从ByteBuf读数据。
这里用了默认的分配器,分配了一个初始容量为9,最大限制为100个字节的缓冲区。关于ByteBuf实例的分配,稍候具体详细介绍。
实战代码很简单,具体如下:
package com.crazymakercircle.netty.bytebuf; //.... public class WriteReadTest { @Test public void testWriteRead() { ByteBuf buffer = ByteBufAllocator.DEFAULT.buffer(9, 100); print("动作:分配ByteBuf(9, 100)", buffer); buffer.writeBytes(new byte[]{1, 2, 3, 4}); print("动作:写入4个字节 (1,2,3,4)", buffer); Logger.info("start==========:get=========="); getByteBuf(buffer); print("动作:取数据ByteBuf", buffer); Logger.info("start==========:read=========="); readByteBuf(buffer); print("动作:读完ByteBuf", buffer); } //取字节 private void readByteBuf(ByteBuf buffer) { while (buffer.isReadable()) { Logger.info("取一个字节:" + buffer.readByte()); } } //读字节,不改变指针 private void getByteBuf(ByteBuf buffer) { for (int i = 0; i<buffer.readableBytes(); i++) { Logger.info("读一个字节:" + buffer.getByte(i)); } } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
运行的结果,节选如下:
//... [main|PrintAttribute:print]:after ===========动作:分配ByteBuf(9, 100)============ [main|PrintAttribute:print]:1.0 isReadable(): false [main|PrintAttribute:print]:1.1 readerIndex(): 0 [main|PrintAttribute:print]:1.2 readableBytes(): 0 [main|PrintAttribute:print]:2.0 isWritable(): true [main|PrintAttribute:print]:2.1 writerIndex(): 0 [main|PrintAttribute:print]:2.2 writableBytes(): 9 [main|PrintAttribute:print]:3.0 capacity(): 9 [main|PrintAttribute:print]:3.1 maxCapacity(): 100 [main|PrintAttribute:print]:3.2 maxWritableBytes(): 100 //... [main|PrintAttribute:print]:after ===========动作:写入4个字节 (1,2,3,4)=========== [main|PrintAttribute:print]:1.0 isReadable(): true [main|PrintAttribute:print]:1.1 readerIndex(): 0 [main|PrintAttribute:print]:1.2 readableBytes(): 4 [main|PrintAttribute:print]:2.0 isWritable(): true [main|PrintAttribute:print]:2.1 writerIndex(): 4 [main|PrintAttribute:print]:2.2 writableBytes(): 5 [main|PrintAttribute:print]:3.0 capacity(): 9 [main|PrintAttribute:print]:3.1 maxCapacity(): 100 [main|PrintAttribute:print]:3.2 maxWritableBytes(): 96 //... [main|PrintAttribute:print]:after ===========动作:取数据ByteBuf============ [main|PrintAttribute:print]:1.0 isReadable(): true [main|PrintAttribute:print]:1.1 readerIndex(): 0 [main|PrintAttribute:print]:1.2 readableBytes(): 4 [main|PrintAttribute:print]:2.0 isWritable(): true [main|PrintAttribute:print]:2.1 writerIndex(): 4 [main|PrintAttribute:print]:2.2 writableBytes(): 5 [main|PrintAttribute:print]:3.0 capacity(): 9 [main|PrintAttribute:print]:3.1 maxCapacity(): 100 [main|PrintAttribute:print]:3.2 maxWritableBytes(): 96 //... [main|PrintAttribute:print]:after ===========动作:读完ByteBuf============ [main|PrintAttribute:print]:1.0 isReadable(): false [main|PrintAttribute:print]:1.1 readerIndex(): 4 [main|PrintAttribute:print]:1.2 readableBytes(): 0 [main|PrintAttribute:print]:2.0 isWritable(): true [main|PrintAttribute:print]:2.1 writerIndex(): 4 [main|PrintAttribute:print]:2.2 writableBytes(): 5 [main|PrintAttribute:print]:3.0 capacity(): 9 [main|PrintAttribute:print]:3.1 maxCapacity(): 100 [main|PrintAttribute:print]:3.2 maxWritableBytes(): 96- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
可以看到,使用get取数据是不会影响ByteBuf的指针属性值的。由于篇幅原因,这里不仅省略了很多的输出结果,还省略了print方法的源代码,它的作用是打印ByteBuf的属性值。建议打开源代码工程,查看和运行本案例的代码。
ByteBuf的引用计数
Netty的ByteBuf的内存回收工作是通过引用计数的方式管理的。JVM中使用“计数器”(一种GC算法)来标记对象是否“不可达”进而收回(注:GC是Garbage Collection的缩写,即Java中的垃圾回收机制), Netty也使用了这种手段来对ByteBuf的引用进行计数。Netty采用“计数器”来追踪ByteBuf的生命周期,一是对Pooled ByteBuf的支持,二是能够尽快地“发现”那些可以回收的ByteBuf(非Pooled),以便提升ByteBuf的分配和销毁的效率。
插个题外话:什么是Pooled(池化)的ByteBuf缓冲区呢?在通信程序的执行过程中,Buffer缓冲区实例会被频繁创建、使用、释放。大家都知道,频繁创建对象、内存分配、释放内存,系统的开销大、性能低,如何提升性能、提高Buffer实例的使用率呢?从Netty4版本开始,新增了对象池化的机制。即创建一个Buffer对象池,将没有被引用的Buffer对象,放入对象缓存池中;当需要时,则重新从对象缓存池中取出,而不需要重新创建。
回到正题。引用计数的大致规则如下:在默认情况下,当创建完一个ByteBuf时,它的引用为1;每次调用retain()方法,它的引用就加1;每次调用release()方法,就是将引用计数减1;如果引用为0,再次访问这个ByteBuf对象,将会抛出异常;如果引用为0,表示这个ByteBuf没有哪个进程引用它,它占用的内存需要回收。在下面的例子中,多次用到了retain()和release()方法,运行后可以看效果:
package com.crazymakercircle.netty.bytebuf; //.... public class ReferenceTest { @Test public voidtestRef() { ByteBufbuffer =ByteBufAllocator.DEFAULT.buffer(); Logger.info("after create:"+buffer.refCnt()); buffer.retain(); Logger.info("after retain:"+buffer.refCnt()); buffer.release(); Logger.info("after release:"+buffer.refCnt()); buffer.release(); Logger.info("after release:"+buffer.refCnt()); //错误:refCnt: 0,不能再retain buffer.retain(); Logger.info("after retain:"+buffer.refCnt()); } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
运行后我们会发现:最后一次retain方法抛出了IllegalReferenceCountException异常。原因是:在此之前,缓冲区buffer的引用计数已经为0,不能再retain了。也就是说:在Netty中,引用计数为0的缓冲区不能再继续使用。为了确保引用计数不会混乱,在Netty的业务处理器开发过程中,应该坚持一个原则:retain和release方法应该结对使用。简单地说,在一个方法中,调用了retain,就应该调用一次release。
public void handlMethodA(ByteBufbyteBuf) { byteBuf.retain(); try { handlMethodB(byteBuf); } finally { byteBuf.release(); } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
如果retain和release这两个方法,一次都不调用呢?则在缓冲区使用完成后,调用一次release,就是释放一次。例如在Netty流水线上,中间所有的Handler业务处理器处理完ByteBuf之后直接传递给下一个,由最后一个Handler负责调用release来释放缓冲区的内存空间。当引用计数已经为0, Netty会进行ByteBuf的回收。分为两种情况:(1)Pooled池化的ByteBuf内存,回收方法是:放入可以重新分配的ByteBuf池子,等待下一次分配。(2)Unpooled未池化的ByteBuf缓冲区,回收分为两种情况:如果是堆(Heap)结构缓冲,会被JVM的垃圾回收机制回收;如果是Direct类型,调用本地方法释放外部内存(unsafe.freeMemory)。
ByteBuf的Allocator分配器
Netty通过ByteBufAllocator分配器来创建缓冲区和分配内存空间。Netty提供了ByteBufAllocator的两种实现:PoolByteBufAllocator和UnpooledByteBufAllocator。PoolByteBufAllocator(池化ByteBuf分配器)将ByteBuf实例放入池中,提高了性能,将内存碎片减少到最小;这个池化分配器采用了jemalloc高效内存分配的策略,该策略被好几种现代操作系统所采用。UnpooledByteBufAllocator是普通的未池化ByteBuf分配器,它没有把ByteBuf放入池中,每次被调用时,返回一个新的ByteBuf实例;通过Java的垃圾回收机制回收。
为了验证两者的性能,大家可以做一下对比试验:
(1)使用UnpooledByteBufAllocator的方式分配ByteBuf缓冲区,开启10000个长连接,每秒所有的连接发一条消息,再看看服务器的内存使用量的情况。实验的参考结果:在短时间内,可以看到占到10GB多的内存空间,但随着系统的运行,内存空间不断增长,直到整个系统内存被占满而导致内存溢出,最终系统宕机。
(2)把UnpooledByteBufAllocator换成PooledByteBufAllocator,再进行试验,看看服务器的内存使用量的情况。实验的参考结果:内存使用量基本能维持在一个连接占用1MB左右的内存空间,内存使用量保持在10GB左右,经过长时间的运行测试,我们会发现内存使用量都能维持在这个数量附近,系统不会因为内存被耗尽而崩溃。
在Netty中,默认的分配器为ByteBufAllocator.DEFAULT,可以通过Java系统参数(System Property)的选项io.netty.allocator.type进行配置,配置时使用字符串值:“unpooled”, “pooled”。
不同的Netty版本,对于分配器的默认使用策略是不一样的。在Netty 4.0版本中,默认的分配器为UnpooledByteBufAllocator。而在Netty 4.1版本中,默认的分配器为PooledByteBufAllocator。现在PooledByteBufAllocator已经广泛使用了一段时间,并且有了增强的缓冲区泄漏追踪机制。因此,可以在Netty程序中设置启动器Bootstrap的时候,将PooledByteBufAllocator设置为默认的分配器。
ServerBootstrap b = new ServerBootstrap() //.... //4 设置通道的参数 b.option(ChannelOption.SO_KEEPALIVE, true); b.option(ChannelOption.ALLOCATOR, PooledByteBufAllocator.DEFAULT); b.childOption(ChannelOption.ALLOCATOR, PooledByteBufAllocator.DEFAULT); //....- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
内存管理的策略可以灵活调整,这是使用Netty所带来的又一个好处。只需一行简单的配置,就能获得到池化缓冲区带来的好处。在底层,Netty为我们干了所有“脏活、累活”!这主要是因为Netty用到了Java的Jemalloc内存管理库。
使用分配器分配ByteBuf的方法有多种。下面列出主要的几种:
package com.crazymakercircle.netty.bytebuf; //... public class AllocatorTest { @Test public void showAlloc() { ByteBuf buffer = null; //方法一:分配器默认分配初始容量为9,最大容量100的缓冲区 buffer = ByteBufAllocator.DEFAULT.buffer(9, 100); //方法二:分配器默认分配初始容量为256,最大容量Integer.MAX_VALUE的缓冲区 buffer = ByteBufAllocator.DEFAULT.buffer(); //方法三:非池化分配器,分配基于Java的堆(Heap)结构内存缓冲区 buffer = UnpooledByteBufAllocator.DEFAULT.heapBuffer(); //方法四:池化分配器,分配基于操作系统管理的直接内存缓冲区 buffer = PooledByteBufAllocator.DEFAULT.directBuffer(); //…..其他方法 } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
如果没有特别的要求,使用第一种或者第二种分配方法分配缓冲区即可。
ByteBuf缓冲区的类型
介绍完了分配器的类型,再来说一下缓冲区的类型,如表6-2所示。根据内存的管理方不同,分为堆缓存区和直接缓存区,也就是Heap ByteBuf和Direct ByteBuf。另外,为了方便缓冲区进行组合,提供了一种组合缓存区。
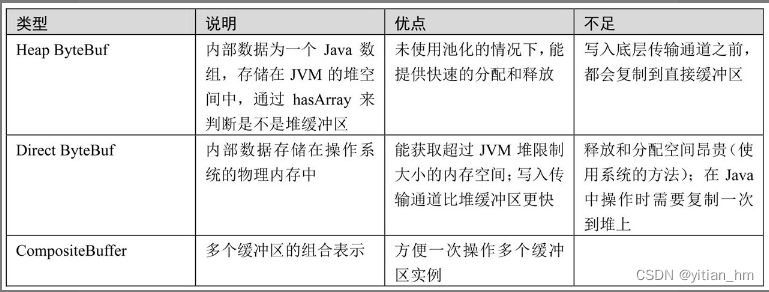
上面三种缓冲区的类型,无论哪一种,都可以通过池化(Pooled)、非池化(Unpooled)两种分配器来创建和分配内存空间。
下面对Direct Memory(直接内存)进行一下特别的介绍:
- Direct Memory不属于Java堆内存,所分配的内存其实是调用操作系统malloc()函数来获得的;由Netty的本地内存堆Native堆进行管理。
- Direct Memory容量可通过-XX:MaxDirectMemorySize来指定,如果不指定,则默认与Java堆的最大值(-Xmx指定)一样。注意:并不是强制要求,有的JVM默认Direct Memory与-Xmx无直接关系。
- Direct Memory的使用避免了Java堆和Native堆之间来回复制数据。在某些应用场景中提高了性能。
- 在需要频繁创建缓冲区的场合,由于创建和销毁Direct Buffer(直接缓冲区)的代价比较高昂,因此不宜使用Direct Buffer。也就是说,Direct Buffer尽量在池化分配器中分配和回收。如果能将Direct Buffer进行复用,在读写频繁的情况下,就可以大幅度改善性能。
- 对Direct Buffer的读写比Heap Buffer快,但是它的创建和销毁比普通Heap Buffer慢。
- 在Java的垃圾回收机制回收Java堆时,Netty框架也会释放不再使用的Direct Buffer缓冲区,因为它的内存为堆外内存,所以清理的工作不会为Java虚拟机(JVM)带来压力。注意一下垃圾回收的应用场景:(1)垃圾回收仅在Java堆被填满,以至于无法为新的堆分配请求提供服务时发生;(2)在Java应用程序中调用System.gc()函数来释放内存。
三类ByteBuf使用的实践案例
首先对比介绍一下,Heap ByteBuf和Direct ByteBuf两类缓冲区的使用。它们有以下几点不同:
- 创建的方法不同:Heap ByteBuf通过调用分配器的buffer()方法来创建;而Direct ByteBuf的创建,是通过调用分配器的directBuffer()方法。
- Heap ByteBuf缓冲区可以直接通过array()方法读取内部数组;而Direct ByteBuf缓冲区不能读取内部数组。
- 可以调用hasArray()方法来判断是否为Heap ByteBuf类型的缓冲区;如果hasArray()返回值为true,则表示是Heap堆缓冲,否则就不是。
- Direct ByteBuf要读取缓冲数据进行业务处理,相对比较麻烦,需要通过getBytes/readBytes等方法先将数据复制到Java的堆内存,然后进行其他的计算。
Heap ByteBuf和Direct ByteBuf这两类缓冲区的使用对比,实践案例的代码如下:
package com.crazymakercircle.netty.bytebuf; //... public class BufferTypeTest { final static Charset UTF_8 = Charset.forName("UTF-8"); //堆缓冲区 @Test public void testHeapBuffer() { //取得堆内存 ByteBuf heapBuf = ByteBufAllocator.DEFAULT.buffer(); heapBuf.writeBytes("疯狂创客圈:高性能学习社群".getBytes(UTF_8)); if (heapBuf.hasArray()) { //取得内部数组 byte[] array = heapBuf.array(); int offset = heapBuf.arrayOffset() + heapBuf.readerIndex(); int length = heapBuf.readableBytes(); Logger.info(new String(array, offset, length, UTF_8)); } heapBuf.release(); } //直接缓冲区 @Test public void testDirectBuffer() { ByteBuf directBuf= ByteBufAllocator.DEFAULT.directBuffer(); directBuf.writeBytes("疯狂创客圈:高性能学习社群".getBytes(UTF_8)); if (! directBuf.hasArray()) { int length = directBuf.readableBytes(); byte[] array = new byte[length]; //把数据读取到堆内存 directBuf.getBytes(directBuf.readerIndex(), array); Logger.info(new String(array, UTF_8)); } directBuf.release(); } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
注意,如果hasArray()返回false,不一定代表缓冲区一定就是Direct ByteBuf直接缓冲区,也有可能是CompositeByteBuf缓冲区。
下面演示一下通过CompositeByteBuf来复用Header,代码如下:
package com.crazymakercircle.netty.bytebuf; //... public class CompositeBufferTest { static Charset utf8 = Charset.forName("UTF-8"); @Test public void byteBufComposite() { CompositeByteBufcbuf = ByteBufAllocator.DEFAULT.compositeBuffer(); //消息头 ByteBufheaderBuf = Unpooled.copiedBuffer("疯狂创客圈:", utf8); //消息体1 ByteBufbodyBuf = Unpooled.copiedBuffer("高性能Netty", utf8); cbuf.addComponents(headerBuf, bodyBuf); sendMsg(cbuf); //在refCnt为0前,retain headerBuf.retain(); cbuf.release(); cbuf = ByteBufAllocator.DEFAULT.compositeBuffer(); //消息体2 bodyBuf = Unpooled.copiedBuffer("高性能学习社群", utf8); cbuf.addComponents(headerBuf, bodyBuf); sendMsg(cbuf); cbuf.release(); } private void sendMsg(CompositeByteBufcbuf) { //处理整个消息 for (ByteBufb :cbuf) { int length = b.readableBytes(); byte[] array = new byte[length]; //将CompositeByteBuf中的数据复制到数组中 b.getBytes(b.readerIndex(), array); //处理一下数组中的数据 System.out.print(new String(array, utf8)); } System.out.println(); } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
在上面的程序中,向CompositeByteBuf对象中增加ByteBuf对象实例,这里调用了addComponents方法。Heap ByteBuf和Direct ByteBuf两种类型都可以增加。如果内部只存在一个实例,则CompositeByteBuf中的hasArray()方法,将返回这个唯一实例的hasArray()方法的值;如果有多个实例,CompositeByteBuf中的hasArray()方法返回false。
调用nioBuffer()方法可以将CompositeByteBuf实例合并成一个新的Java NIO ByteBuffer缓冲区(注意:不是ByteBuf)。演示代码如下:
package com.crazymakercircle.netty.bytebuf; //... public class CompositeBufferTest { @Test public void intCompositeBufComposite() { CompositeByte Bufcbuf = Unpooled.compositeBuffer(3); cbuf.addComponent(Unpooled.wrappedBuffer(new byte[]{1, 2, 3})); cbuf.addComponent(Unpooled.wrappedBuffer(new byte[]{4})); cbuf.addComponent(Unpooled.wrappedBuffer(new byte[]{5, 6})); //合并成一个的缓冲区 ByteBuffer nioBuffer = cbuf.nioBuffer(0, 6); byte[] bytes = nioBuffer.array(); System.out.print("bytes = "); for (byte b : bytes) { System.out.print(b); } cbuf.release(); } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
在以上代码中,使用到了Netty中一个非常方便的类——Unpooled帮助类,用它来创建和使用非池化的缓冲区。另外,还可以在Netty程序之外独立使用Unpooled帮助类。
ByteBuf的自动释放
查看Netty源代码,我们可以看到,Netty的Reactor反应器线程会在底层的Java NIO通道读数据时,也就是AbstractNioByteChannel.NioByteUnsafe.read()处,调用ByteBufAllocator方法,创建ByteBuf实例,从操作系统缓冲区把数据读取到Bytebuf实例中,然后调用pipeline.fireChannelRead(byteBuf)方法将读取到的数据包送入到入站处理流水线中。再看看入站处理时,入站的ByteBuf是如何自动释放的。
方式一:TailHandler自动释放
Netty默认会在ChannelPipline通道流水线的最后添加一个TailHandler末尾处理器,它实现了默认的处理方法,在这些方法中会帮助完成ByteBuf内存释放的工作。在默认情况下,如果每个InboundHandler入站处理器,把最初的ByteBuf数据包一路往下传,那么TailHandler末尾处理器会自动释放掉入站的ByteBuf实例。
如何让ByteBuf数据包通过流水线一路向后传递呢?如果自定义的InboundHandler入站处理器继承自ChannelInboundHandlerAdapter适配器,那么可以在InboundHandler的入站处理方法中调用基类的入站处理方法,演示代码如下:
public class DomoHandler extends ChannelInboundHandlerAdapter { /** * 出站处理方法 * @param ctx上下文 * @param msg 入站数据包 * @throws Exception可能抛出的异常 */ @Override public void channelRead(ChannelHandlerContext ctx, Object msg) throws Exception { ByteBuf byteBuf = (ByteBuf) msg; //...省略ByteBuf的业务处理 //自动释放ByteBuf的方法:调用父类的入站方法,将msg向后传递 // super.channelRead(ctx, msg); } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
总体来说,如果自定义的InboundHandler入站处理器继承自ChannelInboundHandlerAdapter适配器,那么可以调用以下两种方法来释放ByteBuf内存:(1)手动释放ByteBuf。具体的方式为调用byteBuf.release()。(2)调用父类的入站方法将msg向后传递,依赖后面的处理器释放ByteBuf。具体的方式为调用基类的入站处理方法super.channelRead(ctx, msg)。
public class DomoHandler extends ChannelInboundHandlerAdapter { /** * 出站处理方法 * @param ctx上下文 * @param msg 入站数据包 * @throws Exception 可能抛出的异常 */ @Override public void channelRead(ChannelHandlerContextctx, Object msg) throws Exception { ByteBufbyteBuf = (ByteBuf) msg; //...省略ByteBuf的业务处理 //释放ByteBuf的两种方法 // 方法一:手动释放ByteBuf byteBuf.release(); //方法二:调用父类的入站方法,将msg向后传递 // super.channelRead(ctx, msg); } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
方式二:SimpleChannelInboundHandler自动释放
如果Handler业务处理器需要截断流水线的处理流程,不将ByteBuf数据包送入后边的InboundHandler入站处理器,这时,流水线末端的TailHandler末尾处理器自动释放缓冲区的工作自然就失效了。在这种场景下,Handler业务处理器有两种选择:
-
手动释放ByteBuf实例。
-
继承SimpleChannelInboundHandler,利用它的自动释放功能。
这里,我们聚焦的是第二种选择:看看SimpleChannelInboundHandler是如何自动释放的。
以入站读数据为例,Handler业务处理器必须继承自SimpleChannelInboundHandler基类。并且,业务处理器的代码必须移动到重写的channelRead0(ctx, msg)方法中。SimpleChannelInboundHandle类的channelRead等入站处理方法,会在调用完实际的channelRead0方法后,帮忙释放ByteBuf实例。如果大家好奇,想看看SimpleChannelInboundHandler是如何释放ByteBuf的,那么就一起来看看Netty源代码。截取部分的代码如下所示:
public abstract class SimpleChannelInboundHandler<I> extends ChannelInboundHandlerAdapter { //基类的入站方法 @Override public void channelRead(ChannelHandlerContext ctx, Object msg) throws Exception { boolean release = true; try { if (acceptInboundMessage(msg)) { @SuppressWarnings("unchecked") I imsg = (I) msg; //调用实际的业务代码,必须由子类继承,并且提供实现 channelRead0(ctx, imsg); } else { release = false; ctx.fireChannelRead(msg); } } finally { if (autoRelease&& release) { //释放ByteBuf ReferenceCountUtil.release(msg); } } } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
在Netty的SimpleChannelInboundHandler类的源代码中,执行完由子类继承的channelRead0()业务处理后,在finally语句代码段中,ByteBuf被释放了一次,如果ByteBuf计数器为零,将被彻底释放掉。再看看出站处理时,Netty是何时释放出站的ByteBuf的呢?出站缓冲区的自动释放方式:HeadHandler自动释放。在出站处理流程中,申请分配到的ByteBuf主要是通过HeadHandler完成自动释放的。出站处理用到的Bytebuf缓冲区,一般是要发送的消息,通常由Handler业务处理器所申请而分配的。例如,在write出站写入通道时,通过调用ctx.writeAndFlush(Bytebufmsg), Bytebuf缓冲区进入出站处理的流水线。在每一个出站Handler业务处理器中的处理完成后,最后数据包(或消息)会来到出站的最后一棒HeadHandler,在数据输出完成后,Bytebuf会被释放一次,如果计数器为零,将被彻底释放掉。
在Netty开发中,必须密切关注Bytebuf缓冲区的释放,如果释放不及时,会造成Netty的内存泄露(Memory Leak),最终导致内存耗尽。
ByteBuf浅层复制的高级使用方式
首先说明一下,浅层复制是一种非常重要的操作。可以很大程度地避免内存复制。这一点对于大规模消息通信来说是非常重要的。ByteBuf的浅层复制分为两种,有切片(slice)浅层复制和整体(duplicate)浅层复制。
slice切片浅层复制
ByteBuf的slice方法可以获取到一个ByteBuf的一个切片。一个ByteBuf可以进行多次的切片浅层复制;多次切片后的ByteBuf对象可以共享一个存储区域。
slice方法有两个重载版本:
(1)public ByteBuf slice()(2)public ByteBuf slice(int index, int length)
第一个是不带参数的slice方法,在内部是调用了第二个带参数的slice方法,调用大致方式为:buf.slice(buf.readerIndex(), buf.readableBytes())。也就是说,第一个无参数slice方法的返回值是ByteBuf实例中可读部分的切片。第二个带参数的slice(int index, int length) 方法,可以通过灵活地设置不同起始位置和长度,来获取到ByteBuf不同区域的切片。
一个简单的slice的使用示例代码如下:
package com.crazymakercircle.netty.bytebuf; //.... public class SliceTest { @Test public voidtestSlice() { ByteBuf buffer = ByteBufAllocator.DEFAULT.buffer(9, 100); print("动作:分配ByteBuf(9, 100)", buffer); buffer.writeBytes(new byte[]{1, 2, 3, 4}); print("动作:写入4个字节 (1,2,3,4)", buffer); ByteBuf slice = buffer.slice(); print("动作:切片slice", slice); } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
在上面代码中,输出了源ByteBuf和调用slice方法后的切片ByteBuf的三组属性值,运行结果如下:
//…篇幅原因,省略了ByteBuf刚分配后的属性值输出 [main|SliceTest:print]:after ===========动作:写入4个字节 (1,2,3,4)============ [main|SliceTest:print]:1.0 isReadable(): true [main|SliceTest:print]:1.1 readerIndex(): 0 [main|SliceTest:print]:1.2 readableBytes(): 4 [main|SliceTest:print]:2.0 isWritable(): true [main|SliceTest:print]:2.1 writerIndex(): 4 [main|SliceTest:print]:2.2 writableBytes(): 5 [main|SliceTest:print]:3.0 capacity(): 9 [main|SliceTest:print]:3.1 maxCapacity(): 100 [main|SliceTest:print]:3.2 maxWritableBytes(): 96 [main|SliceTest:print]:after ===========动作:切片slice============ [main|SliceTest:print]:1.0 isReadable(): true [main|SliceTest:print]:1.1 readerIndex(): 0 [main|SliceTest:print]:1.2 readableBytes(): 4 [main|SliceTest:print]:2.0 isWritable(): false [main|SliceTest:print]:2.1 writerIndex(): 4 [main|SliceTest:print]:2.2 writableBytes(): 0 [main|SliceTest:print]:3.0 capacity(): 4 [main|SliceTest:print]:3.1 maxCapacity(): 4 [main|SliceTest:print]:3.2 maxWritableBytes(): 0- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
调用slice()方法后,返回的切片是一个新的ByteBuf对象,该对象的几个重要属性值,大致如下:
-
readerIndex(读指针)的值为0。
-
writerIndex(写指针)的值为源Bytebuf的readableBytes()可读字节数。·
-
maxCapacity(最大容量)的值为源Bytebuf的readableBytes( )可读字节数。
切片后的新Bytebuf有两个特点:
- 切片不可以写入,原因是:maxCapacity与writerIndex值相同。
- 切片和源ByteBuf的可读字节数相同,原因是:切片后的可读字节数为自己的属性writerIndex - readerIndex,也就是源ByteBuf的readableBytes() -0。切片后的新ByteBuf和源ByteBuf的关联性:
- 切片不会复制源ByteBuf的底层数据,底层数组和源ByteBuf的底层数组是同一个。
- 切片不会改变源ByteBuf的引用计数。
从根本上说,slice()无参数方法所生成的切片就是源ByteBuf可读部分的浅层复制。
duplicate整体浅层复制
和slice切片不同,duplicate() 返回的是源ByteBuf的整个对象的一个浅层复制,包括如下内容:
- duplicate的读写指针、最大容量值,与源ByteBuf的读写指针相同。
- duplicate() 不会改变源ByteBuf的引用计数。
- duplicate() 不会复制源ByteBuf的底层数据。
duplicate() 和slice() 方法都是浅层复制。不同的是,slice()方法是切取一段的浅层复制,而duplicate( )是整体的浅层复制。
浅层复制的问题
leBytes( )可读字节数。
切片后的新Bytebuf有两个特点:
- 切片不可以写入,原因是:maxCapacity与writerIndex值相同。
- 切片和源ByteBuf的可读字节数相同,原因是:切片后的可读字节数为自己的属性writerIndex - readerIndex,也就是源ByteBuf的readableBytes() -0。切片后的新ByteBuf和源ByteBuf的关联性:
- 切片不会复制源ByteBuf的底层数据,底层数组和源ByteBuf的底层数组是同一个。
- 切片不会改变源ByteBuf的引用计数。
从根本上说,slice()无参数方法所生成的切片就是源ByteBuf可读部分的浅层复制。
duplicate整体浅层复制
和slice切片不同,duplicate() 返回的是源ByteBuf的整个对象的一个浅层复制,包括如下内容:
- duplicate的读写指针、最大容量值,与源ByteBuf的读写指针相同。
- duplicate() 不会改变源ByteBuf的引用计数。
- duplicate() 不会复制源ByteBuf的底层数据。
duplicate() 和slice() 方法都是浅层复制。不同的是,slice()方法是切取一段的浅层复制,而duplicate( )是整体的浅层复制。
浅层复制的问题
浅层复制方法不会实际去复制数据,也不会改变ByteBuf的引用计数,这就会导致一个问题:在源ByteBuf调用release() 之后,一旦引用计数为零,就变得不能访问了;在这种场景下,源ByteBuf的所有浅层复制实例也不能进行读写了;如果强行对浅层复制实例进行读写,则会报错。因此,在调用浅层复制实例时,可以通过调用一次retain() 方法来增加引用,表示它们对应的底层内存多了一次引用,引用计数为2。在浅层复制实例用完后,需要调用两次release()方法,将引用计数减一,这样就不影响源ByteBuf的内存释放。
-
相关阅读:
达梦数据库的锁排查方法
数字IC设计面试题目集21~46
Java OutputStream.close()功能简介说明
【字符串】求解方程 数学
彻底解决 IDC Incast
万物皆可“云” 从杭州云栖大会看数智生活的未来
【新版】系统架构设计师 - 案例分析 - 总览
java加sqlite3右键菜单版圣经,还没检查错误
【短道速滑十】非局部均值滤波的指令集优化和加速(针对5*5的搜索特例,可达到单核1080P灰度图 28ms/帧的速度)。
【SpringBoot】idea创建SpringBoot项目及注解配置相关应用
- 原文地址:https://blog.csdn.net/yitian881112/article/details/127656847