-
Hive与Hbase的区别与联系
一、概念
1,Hive
hive是基于Hadoop的一个数据仓库工具,用来进行数据提取、转化、加载,这是一种可以存储、查询和分析存储在Hadoop中的大规模数据的机制。hive数据仓库工具能将结构化的数据文件映射为一张数据库表,并提供SQL查询功能,能将SQL语句转变成MapReduce任务来执行。Hive的优点是学习成本低,可以通过类似SQL语句实现快速MapReduce统计,使MapReduce变得更加简单,而不必开发专门的MapReduce应用程序。hive十分适合对数据仓库进行统计分析。
2,Hbase
HBase是一个分布式的、面向列的开源数据库,该技术来源于 Fay Chang 所撰写的Google论文“Bigtable:一个结构化数据的分布式存储系统”。就像Bigtable利用了Google文件系统(File System)所提供的分布式数据存储一样,HBase在Hadoop之上提供了类似于Bigtable的能力。HBase是Apache的Hadoop项目的子项目。HBase不同于一般的关系数据库,它是一个适合于非结构化数据存储的数据库。另一个不同的是HBase基于列的而不是基于行的模式。
二、共同点
Hbase与Hive都是架构在hadoop之上的。都是用HDFS作为底层存储。
三、区别
- Hive是建立在Hadoop之上为了减少MapReduce jobs编写工作的批处理系统,HBase是为了支持弥补Hadoop对实时操作的缺陷的项目 。
- Hive是高延迟、结构化和面向分析的,Hbase是低延迟、非结构化和面向编程的。Hive数据仓库在hadoop上是高延迟的。HBase位于结构化存储层,Hadoop HDFS为HBase提供了高可靠性的底层存储支持,Hadoop MapReduce为HBase提供了高性能的计算能力,Zookeeper为HBase提供了稳定服务和failover机制。
- 在操作RMDB数据库,如果是全表扫描,就用Hive+Hadoop,如果是索引访问,就用HBase+Hadoop 。
- Hive query就是MapReduce jobs可以从5分钟到数小时不止,HBase是非常高效的,肯定比Hive高效的多。
- Hive本身不存储和计算数据,它完全依赖于HDFS和MapReduce,Hive中的表纯逻辑。
- Hive借用hadoop的MapReduce来完成一些Hive中的命令的执行
- Hbase是物理表,不是逻辑表,提供一个超大的内存hash表,搜索引擎通过它来存储索引,方便查询操作。
- Hbase是列存储。
- HDFS作为底层存储,HDFS是存放文件的系统,而Hbase负责组织文件。
- Hive需要用到hdfs存储文件,需要用到MapReduce计算框架。
四、联系
在大数据架构中,Hive和HBase是协作关系,Hive方便地提供了Hive QL的接口来简化MapReduce的使用, 而HBase提供了低延迟的数据库访问。如果两者结合,可以利用MapReduce的优势针对HBase存储的大量内容进行离线的计算和分析。
Hive与HBase整合的实现是利用两者本身对外的API接口互相通信来完成的,这种相互通信是通过$HIVE_HOME/lib/hive-hbase-handler-*.jar工具类实现的。通过HBaseStorageHandler,Hive可以获取到Hive表所对应的HBase表名,列簇和列,InputFormat、OutputFormat类,创建和删除HBase表等。
1,访问
Hive访问HBase中HTable的数据,实质上是通过MR读取HBase的数据,而MR是使用HiveHBaseTableInputFormat完成对表的切分,获取RecordReader对象来读取数据的。
对HBase表的切分原则是一个Region切分成一个Split,即表中有多少个Regions,MR中就有多少个Map;
读取HBase表数据都是通过构建Scanner,对表进行全表扫描,如果有过滤条件,则转化为Filter。当过滤条件为rowkey时,则转化为对rowkey的过滤;Scanner通过RPC调用RegionServer的next()来获取数据。
简单来说,Hive和Hbase的集成就是,打通了Hive和Hbase,使得Hive中的表创建之后,可以同时是一个Hbase的表,并且在Hive端和Hbase端都可以做任何的操作。
2,访问流程
- 通过ETL工具将数据源抽取到HDFS存储;
- 通过Hive清洗、处理和计算原始数据;
- HIve清洗处理后的结果,如果是面向海量数据随机查询场景的可存入Hbase
- 数据应用从HBase查询数据;
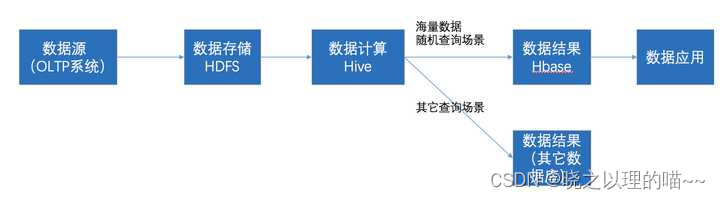
3,使用场景
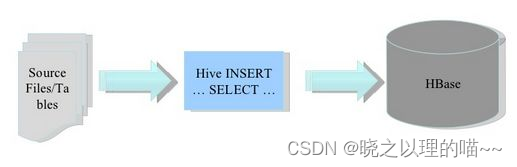
(1)将ETL操作的数据通过Hive加载到HBase中,数据源可以是文件也可以是Hive中的表。
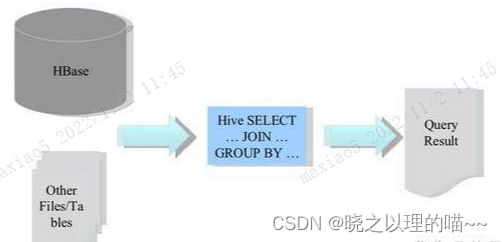
(2)Hbae作为Hive的数据源,通过整合,让HBase支持JOIN、GROUP等SQL查询语法。
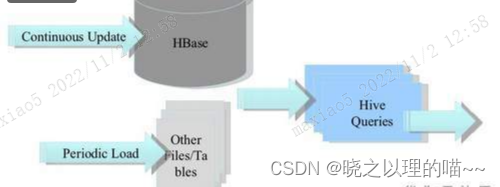
(3)构建低延时的数据仓库
文章参考链接:https://zhuanlan.zhihu.com/p/74041611
-
相关阅读:
98. 验证二叉搜索树(中等 二叉搜索树 dfs)
浅谈电动汽车充电桩设计与应用研究
please choose a certificate and try again.(-5)报错怎么解决
C++--二叉搜索树初阶
电脑可以模拟人脑吗
SpringMVC组件和注解解析
使用KEIL自带的仿真器仿真遇到问题解决
说说BTree和B+Tree
【HBuilder X】解决HBuilder X内置浏览器显示过大影响使用
计算机网络——物理层の选择题整理
- 原文地址:https://blog.csdn.net/weixin_42011858/article/details/127649012