-
【算法】剑指offer-删除链表中重复的节点&&最小栈
删除链表中重复的节点
在一个排序的链表中,存在重复的结点,请删除该链表中重复的结点,重复的结点不保留,返回链表头指针. 例
如,链表1->2->3->3->4->4->5 处理后为 1->2->5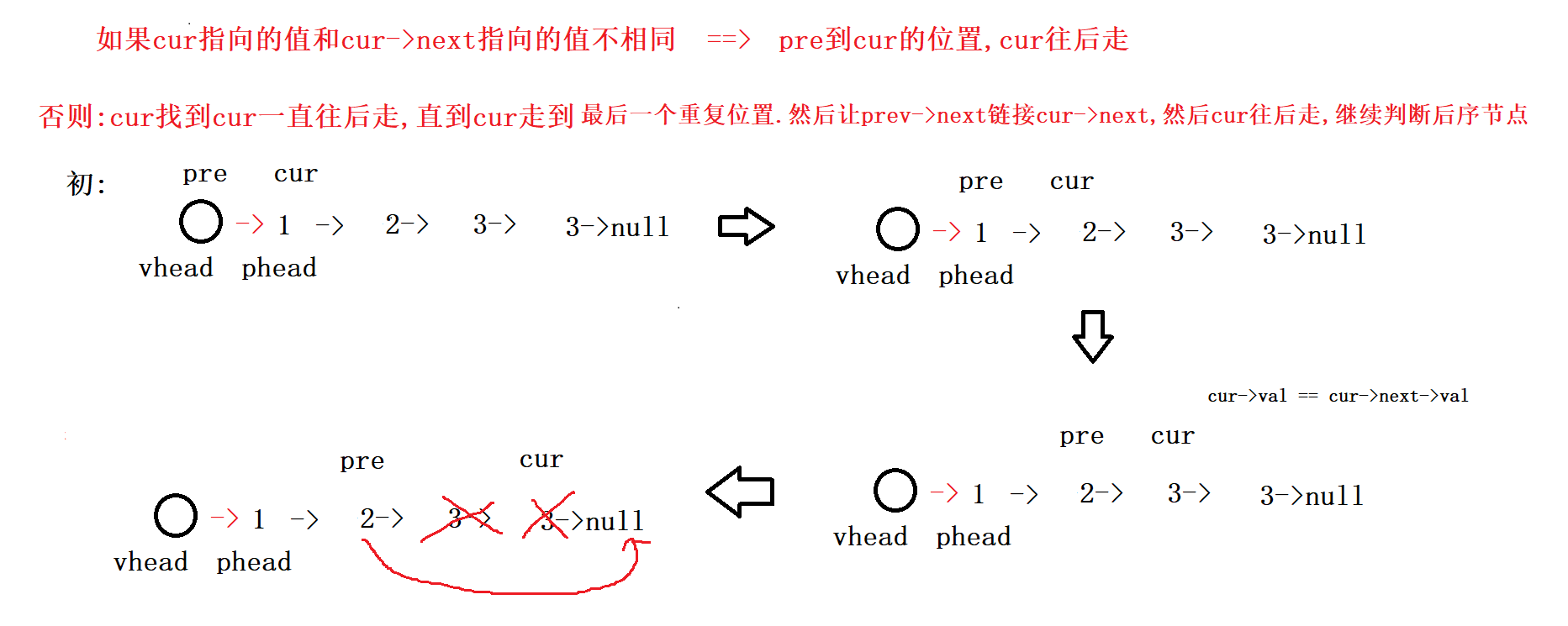
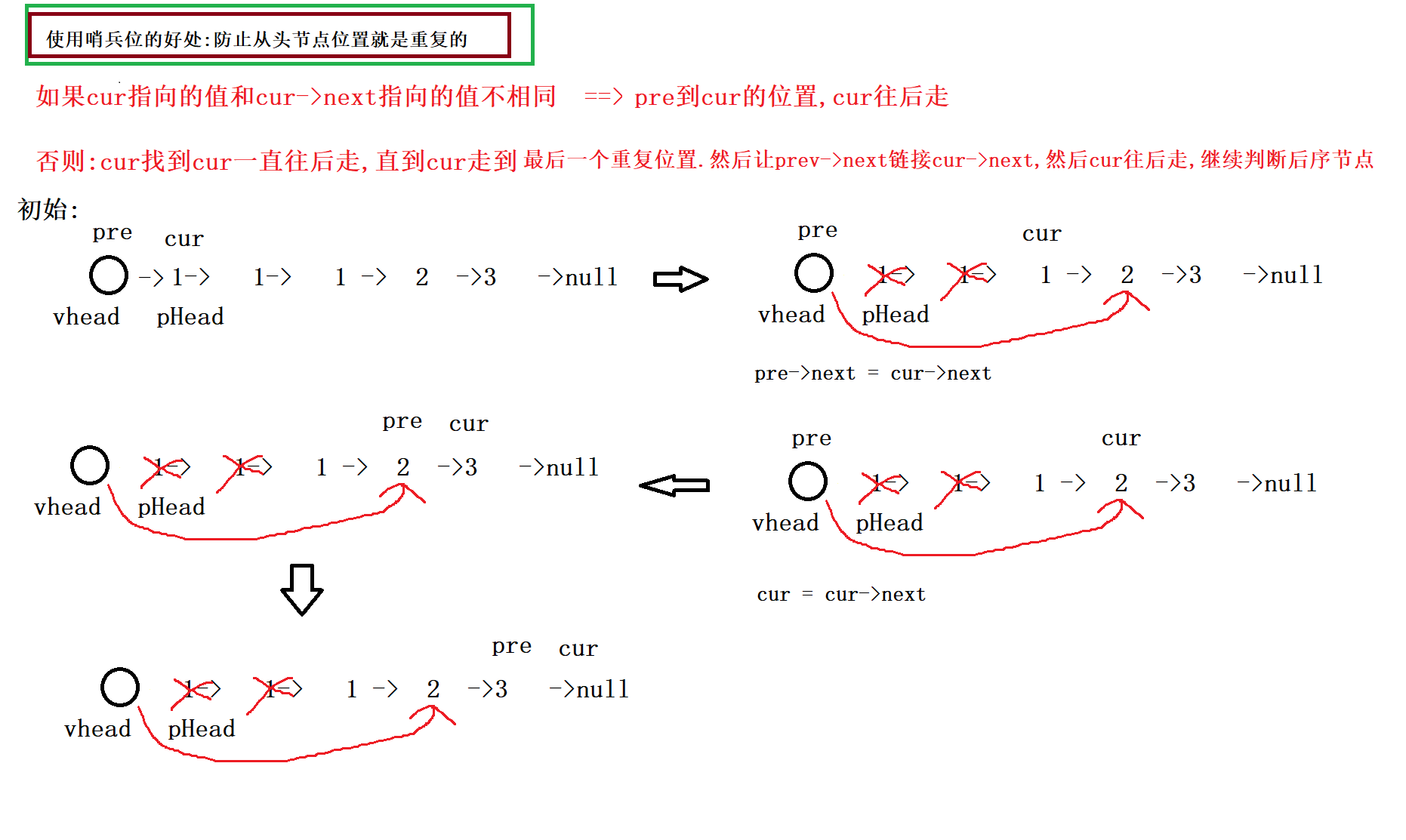
/* struct ListNode { int val; struct ListNode *next; ListNode(int x) : val(x), next(NULL) { } }; */ class Solution { public: ListNode* deleteDuplication(ListNode* pHead) { if(pHead == nullptr) { return nullptr; } ListNode* vhead = new ListNode(0);//新建哨兵位头节点 vhead->next = pHead;//哨兵位链接原链表 ListNode* prev = vhead; ListNode* cur = pHead; //prev 在cur的前面 while(cur) { //如果当前cur指向的值==cur->next指向的值 if(cur->next !=nullptr &&cur->val ==cur->next->val) { //cur走到重复值的最后一个位置 while(cur->next&&cur->val ==cur->next->val) { cur = cur->next; } //跳出循环时,cur指向的就是重复值的最后一个位置 prev->next = cur->next;//prev链接cur的下一个节点 cur = cur->next;//cur往后走 } else { //prev和cur一起往后走 //prev到cur的位置,此时cur位置的值一定是不重复的 //prev始终指向的是不重复的位置 prev = cur; cur = cur->next; } } return vhead->next; } };- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
最小栈
定义栈的数据结构,请在该类型中实现一个能够得到栈中所含最小元素的min函数(时间复杂度应为O(1)).
注意:保证测试中不会当栈为空的时候,对栈调用pop()或者min()或者top()方法.
题目已经说明:pop、top 和 min 函数操作时,栈中一定有元素
方法1:
我们使用一个辅助栈,内部保存元素的个数和数据栈完全一样,不过,辅助栈内部永远保存本次入栈的数为
所有数据的最小值(注意**:辅助栈内部元素可能会出现“必要性”重复**)入栈:
- 最小栈为空 || 最小栈的栈顶元素大于当前入栈元素 -> 压入当前元素到最小栈
- 否则重复压入最小栈的栈顶元素
出栈:
- 直接Pop掉最小栈的栈顶元素
class Solution { public: void push(int value) { stPush.push(value); //如果最小栈为空 || 最小栈的栈顶元素大于当前入栈元素 if(stMin.empty() || stMin.top()>=value) { stMin.push(value); } else { //重复压入最小栈的栈顶元素 stMin.push(stMin.top()); } } void pop() { stMin.pop(); stPush.pop(); } int top() { return stPush.top(); } int min() { return stMin.top(); } private: stack<int> stPush; stack<int> stMin;//最小栈,辅助栈 };- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
方法2:方法1的优化版本
入栈:最小栈为空 || 最小栈的栈顶元素大于当前入栈元素 :才放到最小栈中
出栈:当前出栈数据和最小栈的栈顶元素相同才Pop掉,否则不处理最最小栈的栈顶元素
class Solution { public: void push(int value) { stPush.push(value); //如果最小栈为空 || 最小栈的栈顶元素大于当前入栈元素 if(stMin.empty() || stMin.top()>=value) { stMin.push(value); } } void pop() { if(stMin.top() == stPush.top()) { stMin.pop(); } stPush.pop(); } int top() { return stPush.top(); } int min() { return stMin.top(); } private: stack<int> stPush; stack<int> stMin;//最小栈,辅助栈 };- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
-
相关阅读:
数组补全(冬季每日一题 24)
【PyQt5 实战项目1】武汉大学建筑知识系统--思路分享2(软件版本1.0.0介绍之打开图片)
以escalate靶机为例学习linux的提权方式-linux提权学习笔记(1)
错过等一年!2022年全国注册城乡规划师考试报名入口开启!
Mybatis巧用@Many注解一个SQL联合查询语句搞定一对多查询
Python中stack和unstack函数(附加reset_index,set_index函数)
SpringAMQP中AmqpTemplate发送接收消息
竞赛选题 深度学习图像修复算法 - opencv python 机器视觉
三维重建之NeRF(pytorch)
Django--ORM 常用字段及属性介绍
- 原文地址:https://blog.csdn.net/chuxinchangcun/article/details/127119790