-
hadoop namenode无法启动解决方案
简而言之就是先关闭集群再删除hadoop中所有数据然后再初始化namenode(初始化前先启动zookeeper和journalnode)在启动hadoop
个人笔记:启动zookeeper的shell(通过主机登录其他节点机逐个启动zookeeper)
注:这几个shell是为了方便自己使用hadoop写的。如果是为了解决问题那就是删除数据在初始化namenode,再
start-all.sh就可以了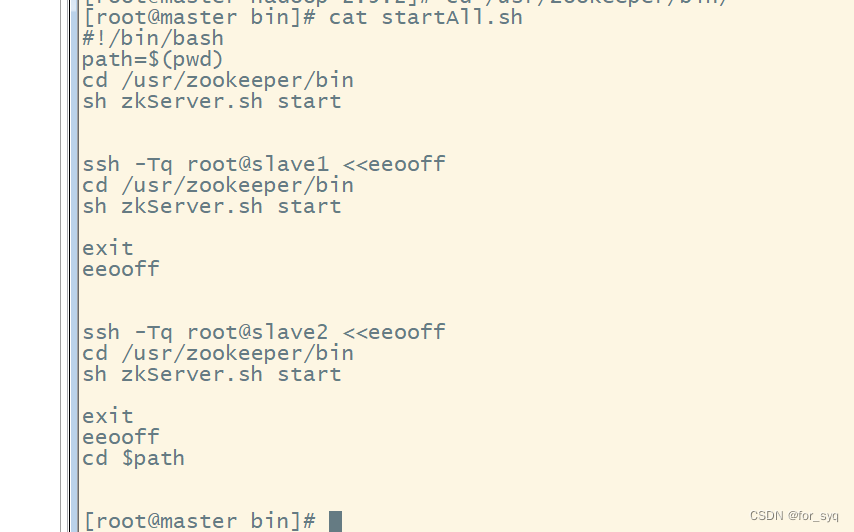
#!/bin/bash path=$(pwd) cd /usr/zookeeper/bin sh zkServer.sh start ssh -Tq root@slave1 <<eeooff cd /usr/zookeeper/bin sh zkServer.sh start exit eeooff ssh -Tq root@slave2 <<eeooff cd /usr/zookeeper/bin sh zkServer.sh start exit eeooff cd $path- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
关闭zookeeper的shell(通过主机登录其他节点机逐个关闭zookeeper)
#!/bin/bash path=$(pwd) cd /usr/zookeeper/bin sh zkServer.sh stop ssh -Tq root@slave1 <<eeooff cd /usr/zookeeper/bin sh zkServer.sh stop exit eeooff ssh -Tq root@slave2 <<eeooff cd /usr/zookeeper/bin sh zkServer.sh stop exit eeooff cd $path- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
重置hadoop
逐台删除tmp下namenode、datanode、和nm*(这个文件具体的忘了只记得以nm开头)中的数据,还有清除日志(logs下的文件)以及journalnode下的文件。
注:删除所有的数据,这样就跟刚刚配置好的一样集群一样需要初始化。
删除之后先启动每台主机的zookeeper,然后再主机(master)上启动journalnode,然后初始化namenode(hadoop namenode -format)#!/bin/bash path=$(pwd) stop-all.sh cd /usr/hadoop/hadoop-2.9.2 rm -rf tmp/namenode/* tmp/datanode/* tmp/nm* rm -rf logs/* rm -rf journal/* ssh -Tq root@slave1 <<eeooff cd /usr/hadoop/hadoop-2.9.2 rm -rf tmp/namenode/* tmp/datanode/* tmp/nm* rm -rf logs/* rm -rf journal/* exit eeooff ssh -Tq root@slave2 <<eeooff cd /usr/hadoop/hadoop-2.9.2 rm -rf tmp/namenode/* tmp/datanode/* tmp/nm* rm -rf logs/* rm -rf journal/* exit eeooff echo "主机和节点机的数据删除成功!" cd /usr/zookeeper/bin ./starpAll.sh echo "启动zookeeper(shell启动3台)" cd /usr/hadoop/hadoop-2.9.2/sbin ./hadoop-daemon.sh start journalnode ./hadoop-daemons.sh start journalnode echo "启动journalnode" hadoop namenode -format echo "初始化成功!可以直接启动!"- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
小技巧
为了方便启动集群所以我在
start-all.sh(该文件在hadoop的sbin目录下)中添加了上面写的启动zookeeper集群的shell和启动hbase、spark的启动shell。(直接vi start-all.sh 添加即可)
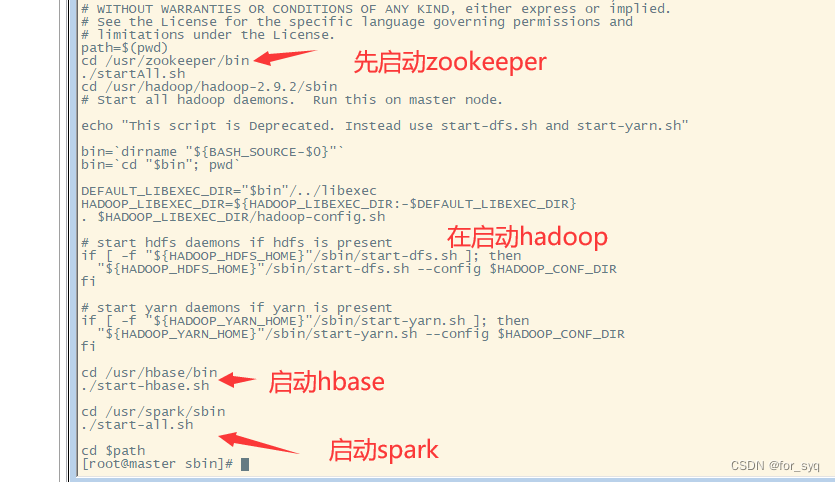
!/usr/bin/env bash # Licensed to the Apache Software Foundation (ASF) under one or more # contributor license agreements. See the NOTICE file distributed with # this work for additional information regarding copyright ownership. # The ASF licenses this file to You under the Apache License, Version 2.0 # (the "License"); you may not use this file except in compliance with # the License. You may obtain a copy of the License at # # http://www.apache.org/licenses/LICENSE-2.0 # # Unless required by applicable law or agreed to in writing, software # distributed under the License is distributed on an "AS IS" BASIS, # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. # See the License for the specific language governing permissions and # limitations under the License. path=$(pwd) cd /usr/zookeeper/bin ./startAll.sh cd /usr/hadoop/hadoop-2.9.2/sbin # Start all hadoop daemons. Run this on master node. echo "This script is Deprecated. Instead use start-dfs.sh and start-yarn.sh" bin=`dirname "${BASH_SOURCE-$0}"` bin=`cd "$bin"; pwd` DEFAULT_LIBEXEC_DIR="$bin"/../libexec HADOOP_LIBEXEC_DIR=${HADOOP_LIBEXEC_DIR:-$DEFAULT_LIBEXEC_DIR} . $HADOOP_LIBEXEC_DIR/hadoop-config.sh # start hdfs daemons if hdfs is present if [ -f "${HADOOP_HDFS_HOME}"/sbin/start-dfs.sh ]; then "${HADOOP_HDFS_HOME}"/sbin/start-dfs.sh --config $HADOOP_CONF_DIR fi # start yarn daemons if yarn is present if [ -f "${HADOOP_YARN_HOME}"/sbin/start-yarn.sh ]; then "${HADOOP_YARN_HOME}"/sbin/start-yarn.sh --config $HADOOP_CONF_DIR fi cd /usr/hbase/bin ./start-hbase.sh cd /usr/spark/sbin ./start-all.sh cd $path- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
关闭
stop-all.sh

#!/usr/bin/env bash # Licensed to the Apache Software Foundation (ASF) under one or more # contributor license agreements. See the NOTICE file distributed with # this work for additional information regarding copyright ownership. # The ASF licenses this file to You under the Apache License, Version 2.0 # (the "License"); you may not use this file except in compliance with # the License. You may obtain a copy of the License at # # http://www.apache.org/licenses/LICENSE-2.0 # # Unless required by applicable law or agreed to in writing, software # distributed under the License is distributed on an "AS IS" BASIS, # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. # See the License for the specific language governing permissions and # limitations under the License. path=$(pwd) #cd /usr/hbase/bin #./stop-hbase.sh #cd /usr/spark/sbin #./stop-all.sh # Stop all hadoop daemons. Run this on master node. echo "This script is Deprecated. Instead use stop-dfs.sh and stop-yarn.sh" bin=`dirname "${BASH_SOURCE-$0}"` bin=`cd "$bin"; pwd` DEFAULT_LIBEXEC_DIR="$bin"/../libexec HADOOP_LIBEXEC_DIR=${HADOOP_LIBEXEC_DIR:-$DEFAULT_LIBEXEC_DIR} . $HADOOP_LIBEXEC_DIR/hadoop-config.sh # stop hdfs daemons if hdfs is present if [ -f "${HADOOP_HDFS_HOME}"/sbin/stop-dfs.sh ]; then "${HADOOP_HDFS_HOME}"/sbin/stop-dfs.sh --config $HADOOP_CONF_DIR fi # stop yarn daemons if yarn is present if [ -f "${HADOOP_HDFS_HOME}"/sbin/stop-yarn.sh ]; then "${HADOOP_HDFS_HOME}"/sbin/stop-yarn.sh --config $HADOOP_CONF_DIR fi #path=$(pwd) #cd /usr/zookeeper/bin #./stopAll.sh #cd $path- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
-
相关阅读:
设计模式学习(一)单例模式的几种实现方式
计算机网络:根据IP和子网掩码计算网络号
LVGL源码分析(1):lv_ll链表的实现
OpenHarmony其他工具类—lua
cmake入门
基于量子粒子群算法(QPSO)优化LSTM的风电、负荷等时间序列预测算法(Matlab代码实现)
洛谷题单 【入门1】顺序结构
处理cookie和session
编译openMVG出现的错误的解决
Unity3D 基础——使用 Mathf.SmoothDamp 函数制作相机的缓冲跟踪效果
- 原文地址:https://blog.csdn.net/for_syq/article/details/127639640
