-
【论】Balancing bike sharing systems with constraint programming
Balancing bike sharing systems with constraint programming
关键词:Applications · Constraint programming · Hybrid meta-heuristics · Large
neighborhood search · Optimization · V ehicle routing
作者:Luca Di Gaspero, Andrea Rendl & Tommaso Urli
文献:Springer Link, 原文链接
Published: 26 February 2015摘要
自行车共享系统需要进行适当的重新平衡,以满足用户的需求并成功运行。然而,平衡自行车共享系统Balancing Bike Sharing Systems (BBSS)的问题是一项艰巨的任务:它需要设计最佳路线和操作说明,以便在车站之间重新安置自行车,以最大限度地满足预期的未来自行车需求。本文采用约束规划Constraint Programming(CP)的方法解决BBSS问题。首先,我们为BBSS问题引入了两种不同的CP模型,包括两种针对最有前途的路由的定制分支策略。其次,我们将这两个模型合并到适合于各自CP模型的大邻域搜索Large Neighborhood Search(LNS)方法中。第三,我们对我们的方法在三个不同的基准实例集上进行了实验评估,这些实例来自现实世界的自行车共享系统。我们展示了我们的CP模型可以很容易地适应不同的基准问题设置,展示了使用约束编程解决BBSS问题的好处。此外,在我们的实验评估中,我们发现在大型实例中,纯CP(分支和边界)方法优于最先进的MILP,并且LNS方法与其他现有方法具有竞争力。
1. Introduction
自行车共享系统是一种非常流行的解决方案,可以以简单、廉价的方式向市民提供自行车。这个想法是在城市的各个地点安装自行车站,注册用户可以通过将自行车从专门的架子上拆下来,轻松地从那里借出自行车。骑行结束后,用户可以在任意站点归还自行车(前提是有免费的行李架)。这项服务主要是公共或半公共的,通常是为了增加非机动交通工具的吸引力而发起的,通常对用户几乎免费。除其他原因外,这就是为什么共享单车系统在世界各地的许多大城市变得特别流行和必不可少的服务。
自行车站在空车或满载时有特定的模式。例如,在大多数工作岗位位于市中心附近的城市,通勤者可能会在早上造成特定的高峰:中心的自行车站被挤满,而郊区的自行车站则被清空。此外,位于丘陵地区顶部的站点更可能是空的,因为用户不太喜欢骑自行车上山,因此也不太喜欢将自行车返回该站点。这些流量的差异是许多车站随着时间推移自行车负荷极高或极低的几个原因之一,这通常会造成困难:一方面,如果车站是空的,用户无法从中借出自行车,因此车站无法满足需求。另一方面,如果站点已满,用户无法归还自行车,必须找到尚未满的替代站点。这些问题可能导致用户严重不满,最终可能导致用户放弃服务。这就是为什么现在大多数共享单车系统供应商采取措施重新平衡它们。
平衡共享单车系统通常是通过使用卡车车队在不平衡的站点之间移动单车来完成的,通常是在一夜之间。更具体地说,每辆卡车从一个停车场出发,在一次旅行中从一个车站到另一个车站,在每一站执行装载指令(添加或移除自行车)。维修完最后一站后,卡车返回停车场。
寻找最佳的旅游路线和装载指示是一项具有挑战性的任务:该问题包括路线问题和分配单一商品(自行车)以满足需求的问题。此外,由于大多数共享单车系统通常有大量站点(≥ 100),但是卡车车队很小,卡车只能在合理的时间内服务于车站的子集,因此也有必要决定哪些车站应该平衡。
请注意,许多共享单车提供商,包括我们的项目合作伙伴Citybike Wien,还没有应用决策支持系统来优化其网络平衡,而是让车辆驾驶员临时决定下一站访问哪个站点。
在这项工作中,我们通过使用约束编程 Constraint Programming(CP)来解决共享单车系统的平衡问题。☀️ 首先,我们将问题表述为两个不同的CP模型:一个基于经典车辆路由问题V ehicle Routing Problem(VRP)表述的路由模型,以及一个从规划角度考虑问题的步骤模型。我们详细讨论了这两种模型,并在实验评估中比较了它们的性能。☀️ 其次,我们使用两个CP 模型作为 大型邻居搜索( LNS )搜索策略的基础,该策略被定制为利用各自CP模型的特征[8]。
这项工作以三种方式扩展了我们之前关于BBSS的工作[8,9]。首先,这两款车型在原有版本的基础上进行了全面的修改和改进。特别是,这两种模型现在都能够处理重访,即允许车辆多次访问同一站点,一些约束已转化为更高效的基于DF的和调度的传播器,并且路由模型现在配备了一个自定义传播器,该传播器通过一个基于车辆工作时间的预测方案来修剪后续变量的域。此外,这两种模型现在都与两种定制的分支策略相结合,将搜索集中在最有前途的路线上,分别是成本和可行性。在我们的计算评估中,我们观察到,使用改进的模型,纯 CP(分支和边界)方法优于现有的MILP[13],尤其是在硬实例上。此外,这些模型现在能够找到可行的解决方案,即使对于那些我们以前的模型无法实现的情况。
其次,我们对步骤和路由模型进行了更彻底的比较,以更好地理解[8]中观察到的两种模型性能差异的来源。第三,除了我们在之前的贡献[8,9]中考虑的CityBike Wien实例外,我们还处理了具有不同侧面约束的大量其他现实问题实例[7,21]。我们的两个约束模型都可以很容易地适应这些不同的问题设置,证明了在特定于问题的方法上使用CP的可移植性和灵活性,例如当前最先进的求解器中使用的可变邻域搜索V ariable Neighborhood Search(VNS)[13]。此外,我们的实验评估表明,我们的方法与现有方法具有很强的竞争力,即使在很短的时间内也能提供很好的解决方案。
所有采用的问题实例[7,12,21]和我们所有方法的代码都可以从作者的网页上在线公开。
本文的结构如下:第2节描述了BBSS问题,包括我们的符号,而第3节介绍了BBSS的两个CP公式:路由模型(第3.1节)和步长模型(第3.2节)。在第4节中,我们讨论了 LNS 方法,并在第5节中介绍了本研究中使用的实际问题实例。我们在第6节报告了计算评估的结果,第7节总结了论文。
1.1 Related work
略
2 Balancing bike sharing systems
平衡共享自行车系统(BBSS)的问题涉及寻找车队的路线以及每个站点的相应装载指令,以便在车辆完成其路线后共享自行车系统最大限度地平衡。请注意,我们考虑的是BBSS问题的静态情况,其中我们假设在平衡操作期间没有自行车在站点之间独立移动(换句话说,我们假设没有客户在平衡期间使用该服务,这可能是夜间平衡系统的有效近似值)。
根据每个共享单车提供商的要求,BBSS问题可能有不同的侧面约束。在本节中,我们只介绍了CityBike Wien共享自行车提供商的问题设置,我们将其与基准设置的结果进行比较[13]。在第5节中,我们将强调在处理其他基准集时所需的这一公式方面的差异
自行车共享系统由分布在城市各地的自行车站点集合 S = { 1 , ⋯ , S } S=\{1,\cdots,S\} S={1,⋯,S}组成。每个站 s ∈ S s∈ S s∈S的自行车最大容量为 C s C_s Cs,(当前)可容纳 b s b_s bs自行车,其中 0 ≤ b s ≤ C s 0≤ b_s≤ C_s 0≤bs≤Cs。站点 s s s的目标值 t s t_s ts表示站点理想情况下应容纳多少辆自行车以满足客户需求 t s t_s ts的值预先从用户需求模型[16],且 0 ≤ t s ≤ C s 0≤ t_s≤ C_s 0≤ts≤Cs。为了便于说明,图1描绘了我们基准中两个城市的自行车站地图:维也纳和纽约Vienna and New York City。

CityBike Wien自行车共享供应商的一项重要要求是确保自行车的单调装载,即仅在必要时添加或从站点移除自行车(无中间存储)。因此,我们介绍了两种不同的站点类型:自行车“汇”和自行车“源”。自行车只能添加到接收站,自行车只能从源站移除。根据其相对需求(如果站点中的自行车数量大于需求,则站点是源,否则站点是汇),站点要么是源。车队 V = { 1 , ⋯ , V } \mathcal{V}=\{1,\cdots,V\} V={1,⋯,V},其每辆车 v ∈ V v∈\mathcal{V} v∈V的容量 c v > 0 c_v>0 cv>0和初始负载 b ^ v ≥ 0 \hat{b}_v≥ 0 b^v≥0 , 在站点之间移动自行车以达到其目标值。每个车辆vechile v v v的起点和终点都在仓库depot d v ∈ D d_v∈ D dv∈D。因此,行程中的一组停靠stop可以表示为 S d = S ∪ D S_d=\mathcal{S} \cup \mathcal{D} Sd=S∪D.我们的时间预算有 t ^ v > 0 \hat{t}_v>0 t^v>0个时间单位去完成再平衡操作(在车辆 v v v必须到达车库之前)。行程时间内的所有可能的stops由矩阵 t r a v e l T i m e u , v travelTime_{u,v} travelTimeu,v来确定,其中 u , v ∈ S d u,v \in S_d u,v∈Sd. 一般来说,还提供了另一个 p r o c e s s i n g T i m e s processingTime_s processingTimes组件,该组件说明了为站点服务的操作所需的时间。通常,该组件是一个函数,它线性地取决于转移自行车的数量(从车辆或转移到车辆)。然而,在我们之前的工作[8,9]中处理的Wien CityBike原始公式中,travelTime 数据中包含了为站点服务所需的处理时间的估计值。
目标是找到每辆车的路线,包括每个到访车站的装载说明。装载说明说明了必须分别从车站移除或添加多少辆自行车。当然,装载指令必须考虑车辆和车站的最大容量和当前负载。此外,每辆车只能在其时间预算 t ^ v \hat{t}_v t^v内运行,并且必须在返回车辆段之前分发所有装载的自行车(即,返回车辆段时卡车必须是空的)。
每辆vehicle必须返回deopt, 每个站点 s ∈ S s\in S s∈S有一个新的负载量(即bikes的数目),记作 b s ′ b'_s bs′. 显然越接近目标值 t s t_s ts,则解决方案越好。因此,我们的目标是找到操纵车站状态的路线,使其尽可能接近目标值。此外,我们很有兴趣为每辆车 v ∈ V v\in \mathcal{V} v∈V找到一条低成本的路线low-cost route r v r_v rv, 所以我们也最小化了总旅行时间travel time(这相当于最小化总旅行成本)。
因此,我们引入了一个包含两个分量的目标函数 f f f:第一,对所有站点 s ∈ S s\in S s∈S的 b s ′ b'_s bs′和目标值 t s t_s ts的偏差; 第二,每辆vehicle的行程时间和每个站点的服务(装载指示):

注意,(1)定义了自然多目标问题的标度化。因此,构造忽略了帕累托最优集中的一些点。我们选择这种方法的主要原因是需要与当前的最佳方法[13]进行比较,即采用等效标量化employ an equivalent scalarization。此外,据我们所知,多目标传播技术仍然是一个相对未开发的研究领域。3 Constraint models for the BBSS
在本节中,我们为 BBSS 问题提供了两个约束模型,我们称之为路由模型routing model和步骤模型 step model。然后,我们描述了两种为两种模型实现的定制分支策略(以相同的方式)。第一种是“成本明智cost-wise”的分支策略,它寻求在每一步优化目标函数;第二种是“可行性明智feasibility-wise”的分枝策略,它试图通过坚持一个简单的不变量,快速构建一个可行的解决方案,而不管获得的成本如何。
3.1 Routing model
路由模型是[11]中描述的经典车辆路由问题(VRP)的CP模型的改编。VRP模型使用后续变量对每辆车的路径进行建模。除此之外,我们还添加了表示每个站点必须执行的操作的服务变量。
路由模型routing model的图形编码的本质以及可能的解决方案的元素如图2所示。与[11]中提出的 VRP 公式一样,原始问题的图结构G(下层)被编码为扩展图 G R G_R GR(上层),该扩展图考虑了每辆车的起点depot的一个副本replica,以便将每辆车路线识别为从该节点开始的图中的子路径。给定车辆的终点仓库段的后续successor被设置为接下来车辆的起点仓库(以车辆数量为模),因此问题简化为在扩展图中找到哈密顿回路Hamiltonian circuit 。此外,服务可选性由额外的“虚拟dummy”车辆 v d u m m y v_{dummy} vdummy 建模,其子路径包括所有未服务的站点。

由底图G变为拓展图 G R G_R GR的猜测分析
- 用于再平衡的vehicle的车辆数目为 V V V,Fig.2中假设 V = 2 V=2 V=2
- 底图中节点6为start depot,节点7为end depot,(本质为1个)。站点集合 { 1 , 2 , 3 , 4 , 5 } \{1,2,3,4,5\} {1,2,3,4,5}构成全脸截图。depot与任意一个station可连接;
- 对于每一个vehicle的路线,以创建的start depot副本为起点,以创建的end depot副本为终点。
- 每个站点只能visited一次
- 剩余的unvisited站点可以油“虚拟vehicle”建模
- 在"虚拟vehicle"建立的路线: 2 → 7 → 10 2 \to 7 \to 10 2→7→10中,有 s u c c 2 = 7 , s u c c 7 = 10 , s u c c 10 = 0 succ_2=7, succ_7=10, succ_{10}=0 succ2=7,succ7=10,succ10=0
我们表示一个有序集合U中的节点集合 G R G_R GR,我们用它来索引决策变量:
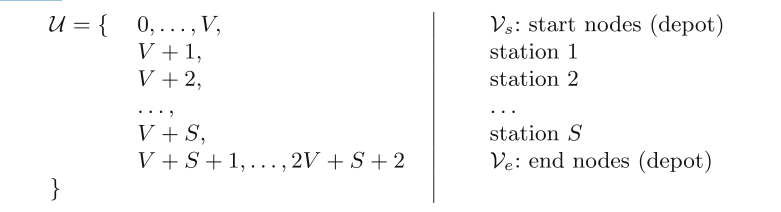
- 通过对 U \mathcal{U} U的定义可以看到,vehicles的车辆数目=实际数目V+虚拟数目1=V+1.
- 分裂为start depot为: 0 , ⋯ , V 0,\cdots, V 0,⋯,V和end depot: V + S + 1 , ⋯ , 2 V + S + 2 V+S+1, \cdots, 2V+S+2 V+S+1,⋯,2V+S+2
- Station的数目为 S S S
值得注意的是,VRP 模型对 BBSS 的这种适应依赖于站点最多访问一次的假设。然而,BBSS问题声明并不阻止一个车站被多次访问(由相同或不同的车辆访问)。为了处理每个站点的多次访问,我们通过考虑对每一次可允许的访问的每个站点的复本来拓展图 G R G_R GR. 也就是说,如果允许同一站点的最多M次访问,则该站点将被映射到节点集 { V + M ( s − 1 ) + 1 , ⋯ , V + M s } \{V+M(s− 1) +1,\cdots,V+Ms\} {V+M(s−1)+1,⋯,V+Ms}.我们用 w ( i ) w(i) w(i)表示一个节点 i ∈ G R i\in G_R i∈GR到原始副本 G G G的逆映射,用 F \mathcal{F} F表示一个站点的第一个副本集,即 F = { V + 1 , V + M + 1 , . . . , V + ( S − 1 ) M + 1 } \mathcal{F} = \{V + 1, V + M + 1, . . . , V + (S − 1)M + 1\} F={V+1,V+M+1,...,V+(S−1)M+1}.
- w ( i ) w(i) w(i)表示从 G ← G R G \leftarrow G_R G←GR逆映射
- F \mathcal{F} F表示 S t a i o n 1 ∈ S Staion 1 \in S Staion1∈S在 G R G_R GR的映射结果
3.1.1 Variables
路由模型routing model的变量总结在表1中。首先,有后继变量successor variables,其中 s u c c i succ_i succi表示节点 i i i的后继变量。我们还引入(冗余redundant)前导变量predecessor variables以改进传播[11]。车辆变量vehicle variables将车辆与图中的每个节点相关联(将为节点提供服务的车辆,如果节点未提供服务,则为虚拟车辆)。服务变量service variables表示在各个节点加载或卸载的自行车数量。与这些变量相关,activity 是指示变量,用于说明给定节点上的服务service是否不同于零。负载变量 l o a d i load_i loadi包含车辆(服务于节点 i i i)在服务节点 i i i后保持的负载(自行车数量)。时间变量 t i m e i time_i timei,表示处理变量processing variables表示在站点 i i i的服务操作的持续时间。最后,当允许多次访问时,需要nbBikes变量。事实上,他们会在车辆服务之前记录某个站点的自行车数量。对于代表第一次访问站点的节点,该值是预先已知的(并设置为 b s b_s bs),但对于后续访问,该值取决于该站点上的先前服务。

至于成本,偏差变量说明在平衡操作后,站点s的负载与目标需求的差异有多大。最后,成本变量包含我们希望最小化的解决方案的总成本(包括差旅成本).
我们仅使用第3.3节中描述的分支策略搜索成功变量和服务变量。
3.1.2 Constraints
为简洁起见,我们在表2中总结了约束,其中我们用相应的问题实例集注释了边约束,即维也纳(V)、混合(M)和纽约(N)。
首先,我们初始化车辆的初始负载 l o a d v = 0 load_v=0 loadv=0,并将depot的服务 s e r v i c e i = 0 service_i=0 servicei=0和初始时间单位 t i m e v = 0 time_v=0 timev=0设置为零。此外,processing 时间变量被设置为零,无论是仅针对仓库(M,N个实例)还是针对所有节点(V个实例)。此外,(站点 s ∈ S s \in S s∈S的未服务前的bikes的数目设置为 b s b_s bs), 每个站点 s s s的 first replicas 设置为 b s b_s bs.
Fig.2 初始化 然后,我们发布符合经典 VRP 模型公式约束的 路由约束routing constraints。特别地,我们 通过circuit全局约束,施加succ和pred变量以形成哈密顿回路。此外,最后两个 路由约束routing constraints分别确保第一个被访问站点不是汇点,以及最后一个访问站点不是源。根据Fig.2中 s u c c 2 = 7 succ_2=7 succ2=7等栗子, 推测根据添加的 前导变量和后继变量,从而形成回路。
- 猜测: 2 → 7 → 10 2 \to 7 \to 10 2→7→10,是哈密顿路,而 s u c c 10 = 0 succ_{10}=0 succ10=0, 从而有 2 → 7 → 10 → 0 2 \to 7 \to 10 \to 0 2→7→10→0, 因为2和0都是start depot的副本,则构成回路。
- 哈密顿路:指定的起点前往指定的终点,途中经过所有其他节点且只经过一次。

Fig.2 路线约束 VRP 模型 : 车辆路径问题(VRP)最早是由 Dantzig 和 Ramser 于1959年首次提出,它是指一定数量的客户,各自有不同数量的货物需求,配送中心向客户提供货物,由一个车队负责分送货物,组织适当的行车路线,目标是使得客户的需求得到满足,并能在一定的约束下,达到诸如路程最短、成本最小、耗费时间最少等目的。
- 带有容量约束的车辆路径问题(CVRP)
- 带有多车场depot的车辆路径问题(MDVRP)
- 带时间窗的车辆路径问题(VRPTW)
- VRP with Backhauls(回程)
参考连接: 《车辆路径问题(VRP,MDVRP,VRPTW)模型介绍》
我们继续处理在每个到访站点装载和卸载自行车的平衡约束balancing constraints。
首先,我们在服务节点 i i i后保持车辆的当前负载。
其次,我们确保车辆永远不会超过其容量。
第三,除虚拟车辆以外的车辆访问的站点 i i i必须进行服务。
接下来的两个限制条件☀️确保自行车站不得超过其容量( C s C_s Cs),或有一个负的负荷;然后我们陈述单调性约束monotonicity constraints(V个实例)。该组的最后两个约束处理模型扩展到多次访问。在这种情况下,为了打破 对称性symmetry, 应按索引的递增顺序访问站点的副本,即,如果使用节点的第 j j j个副本,则所有前面的副本{ 1 , 2 , … , j − 1 1,2,…,j− 1 1,2,…,j−1} 也必须使用。这是通过对活动变量activity variables值的基于 DFA 的正则表达式约束regular expression constraint来说明的。
Fig.2 平衡约束 基于DFA的正则表达式: 参考《如何根据DFA生成正则表达式》 ,《正则表达式(regular expression)和非正则语言(non-regular languages)》
- 约束公式中的,其他的暂时没看懂
下一组的constraints与time有关。🐸首先,我们为后继变量successor variables和前辈变量predecessor variables发布旅行和处理时间约束。🐸其次,我们确保所有车辆在时间预算结束前到达车depot。我们还实现了一个自定义传播器custom propagator ,它将在这个约束之前执行一步操作。该传播器(见图3)的思想是,从 s u c c i succ_i succi 变量中的删除(prune)一个节点 s s s ,如果所有的两步骤路径two-step-paths即从节点 i i i通过 s s s的到达结尾的仓库 d v d_v dv的路径将超过时间预算 t ^ v \hat{t}_v t^v的时候。🐸 最后,我们确保在多次访问的情况下,给定站点的操作不会在时间上重叠。这是通过一元调度约束unary scheduling constraint来说明的。

Fig.2 时间约束 时间约束规则:
- 类似于 VRPTW 问题(带时间窗的车辆路径规划问题) ,可了解,见链接《带时间窗的车辆路径规划问题》
- p r e d v pred_v predv表示站点v的前导变量(车辆路径中v的前一个站点)
- p r o c e s s i n g v processing_v processingv 表示在站点v服务操作的持续时间
- t r a v e l T i m e v , w travelTime_{v,w} travelTimev,w 表示在站点 v v v和站点 w w w之间的行程时间
- t i m e v time_v timev表示到达站点 v v v的时间
- v e h i c l e i vehicle_i vehiclei表示在站点 i i i服务的vehicle
- 到达站点
v
v
v的时间
=到达v的前导站点的时间+服务v的前导站点的时间+从v的前导站点到达站点 v v v的行程时间 - 到达v的后继站点的时间
=到达站点 v v v的时间+服务站点 v v v的时间+从站点 v v v到达 v v v的后继站点的行程时间 - ∀ v ∈ V \forall v \in \mathcal{V} ∀v∈V表示vehicle: **** <给定的预期时间 t ^ v \hat{t}_v t^v
-
∀
i
∈
S
\forall i \in \mathcal{S}
∀i∈S: 表示station:到达站点
i
i
i的时间
+站点 i i i的服务时间+…******(如何理解?)

Fig.3的说明:
- 整个图中,有3个站点: i , s , d i, s, d i,s,d,(猜测 :其中 i ∈ U i \in \mathcal{U} i∈U, s ∈ S s\in S s∈S, d d d表示depot. )
- 猜测: s 1 , s 2 , ⋯ , s k s_1,s_2,\cdots, s_k s1,s2,⋯,sk是站点 s s s的副本, d 1 , d 3 , d 4 d_1,d_3,d_4 d1,d3,d4是站点 d d d的副本的一部分。
- v e h i c l e i ∈ { 1 , 3 , 4 } vehicle_i \in \{1,3,4\} vehiclei∈{1,3,4} :说明在站点 i i i的serving vehicle是编号为1,3,4中的一辆
- i i i站点有向后的3个箭头:说明 s u c c i ∈ { s 1 , s 2 , s k } succ_i \in \{s_1, s_2, s_k\} succi∈{s1,s2,sk} ,虚线表示以 s 2 s_2 s2为例。
- t i m e s u c c i time_{succ_i} timesucci:这里指的是从站点 i i i到达站点 s 2 s_2 s2的时间, 最后一道垂直虚线表示到达站点 d d d的预期时间 t ^ v \hat{t}_v t^v.
删除站点 s 2 s_2 s2的规则:
- 首先在一个两步走的路径中:即 i → s → d i \to s\to d i→s→d
- 其次,对于中间经过站点 s 2 s_2 s2的路径,其 i → s 2 → d i \to s_2 \to d i→s2→d, 其所有的时间都超过了预期时间 t ^ v \hat{t}_v t^v,则删除节点 s 2 s_2 s2这个副本
最后一组约束涉及目标。🐸首先,我们定义平衡操作后每个站的需求偏差。偏差对应于公式(1)中的成本函数的 ∣ b s ′ − t s ∣ |b'_s− t_s| ∣bs′−ts∣中的项。在多次访问的一般情况下,必须将不同访问的服务总量相加。 🐸其次,我们根据问题的原始成本函数指定解决方案的总体成本。有关路由模型routing model的更详细描述,请参阅[9]。
给定输入的大小,路由模型的尺寸如表5所示。

3.2 Step model
步骤模型step model将该问题视为一个规划范围为 K K K个步骤的 规划问题 ,即,我们尝试为每辆车找到一条最大长度为K的路线(带有相应的装载指令),其中第一站和最后一站是仓库depot。我们引入了一组步骤 K = { 0 , … , K } K=\{0,…,K\} K={0,…,K},其中0是初始状态,步骤K是最终状态,因此每个车辆访问 K − 1 K− 1 K−1个站点。
常数K是根据手边的问题实例,根据以下公式(在我们使用步骤模型的过程中迭代演变而来)试探性地计算的:

其中 t ~ \tilde{t} t~是站点之间的平均行驶时间,( t ^ v \hat{t}_v t^v 是指时间预算)
u ˉ \bar{u} uˉ是每个站点需要转移的自行车的平均数量(如果不考虑处理时间processing times,则该数量为0)。
α \alpha α是允许我们拓展路线(在我们的设置中, α = 1.2 \alpha=1.2 α=1.2,因此有额外20%的路线长度需要拓展)的修正参数,以允许不同车辆vehicles的路线长度稍微不平衡。与路线模型routing model相反,该公式允许我们通过一系列固定长度的站点直接表示每辆车的路线,如图4所示。这样,我们可以更自然地制定某些约束条件,如我们将在下面的模型描述中所示。

原图G: 同Fig.2 。节点6和节点7分别对应start depot和end depot.
step model 图:- 这里设置
K
=
3
K=3
K=3,
猜测: 是根据Fig.2中的拓展图具有对应关系。 - 两条线:每个节点由两个数字表示且由
.分割开。第一数字表示时间顺序,第二个数字表示车辆的标号。 - Fig.2中的拓展图中的实际vehicle的线路按照时间拉成直线,则如Fig.4中的拓展图所示。
3.2.1 V ariables
表3总结了所有问题变量。☀️首先,我们引入了 routing variable r o u t e route route,其中 r o u t e k , v route_{k,v} routek,v表示在车辆 v ∈ V v\in \mathcal{V} v∈V的路径中的第 k k k个stop.因此,route variable 跨越了可能的stops S d S_d Sd. ☀️其次,我们引入了service variables,其中 s e r v i c e k , s , v service_{k,s,v} servicek,s,v表示在站点 s ∈ S s\in S s∈S在step k ∈ K k\in \mathcal{K} k∈K由vehicle v ∈ V v\in \mathcal{V} v∈V移除或者添加的自行车数量,因此范围在 [ − C m a x , C m a x ] [−C_{max},C_{max}] [−Cmax,Cmax]之内,其中 C m a x = max s ∈ S { C s } C_{max}=\max_{s∈S}\{C_s\} Cmax=maxs∈S{Cs}表示所有站点的最大容量。vehicle的负载量由load variables表示,其中 l o a d k , v load_{k,v} loadk,v表示vehicle v ∈ V v\in \mathcal{V} v∈V在step k ∈ K k\in \mathcal{K} k∈K进行可能的(平衡)操作之前的负载量。此外,变量 n b B i k e s k , s nbBikes_{k,s} nbBikesk,s表示站点 s ∈ S s\in S s∈S在step k ∈ K k\in \mathcal{K} k∈K存储了多少辆自行车.我们介绍 K − 1 = { 0 , ⋯ , K − 1 } \mathcal{K}_{−1}=\{0,\cdots,K− 1\} K−1={0,⋯,K−1} 对于除最后一步之外的一组steps, K S = { 1 , … , K − 1 } \mathcal{K}_S=\{1,…,K− 1\} KS={1,…,K−1} 是一组steps,涉及车站,但不涉及车站(第一步和最后一步)。 与 路由模型routing model 类似,我们只使用第3.3节中描述的分支策略搜索route variable和service variable。

3.2.2 Constraints
表4总结了所有约束条件。
🐸首先,我们在步骤 k = 0 k=0 k=0设置初始状态:每个车辆 v v v的路线的第一站是depot,v的初始负载等于 b ^ v \hat{b}_v b^v。初始服务为零,以及初始时间,站点 s s s的初始自行车数量等于 b s b_s bs。🐸其次,我们继续讨论路由约束routing constraints。由于路由变量routing variables包含每条路由中的后续变量successors,因此路由模型需要较少的约束。一开始,我们声明最后一站必须是depot。 然后,如果在步骤 k k k已经到达depot,则车辆必须在步骤 k + 1 k+1 k+1停留在depot。
这是通过一个基于DFA的正则表达式约束来建模的,该约束强制要求对车辆段的“访问”必须位于路线的尾部。此外,尽管这不是严格必要的,但为了与路由模型的可比性,我们使用全局基数约束global cardinality constraint(gcc)将每个站点的可能访问次数限制为M次,即站点必须作为路由变量的值出现最多M次。🐸第三是平衡约束balancing constraints。在步骤 k k k,车辆 v v v在站点 s s s的活动被约束为总是等于相应服务的绝对值。然后,我们链接route和activity变量。 接下来,每辆车 v ∈ V v∈ V v∈V被设置为在每个步骤 k k k中仅在最多一个站点上执行操作,因此activity在至少 S − S- S−个站点中为零,我们用至少一个约束表示。然后,我们在步骤 k + 1 k+1 k+1在vehicle v v v服务一个站点后更新其负载量同时更新站点 s s s的自行车的数量。对于最终状态,我们将每辆车的负载限制为零,车辆段的服务必须为零。最后,还有单调性限制(“接收站sink”和“源站source”):那些需要接收自行车以达到其目标值的站点必须有 positive 的服务,而需要从中移除自行车以达到目标值的站必须有 negative 的服务。
🐸我们继续处理时间约束time constraints问题。首先,我们声明时间总是递增的。然后,我们声明两辆不同的车辆不能同时在同一车站运行。最后,我们在步骤 k + 1 k+1 k+1限制车辆 v v v到达其服务的站点的时间,其中表达式“ t r v a l T i m e r o u t e k , v , r o u t k + 1 , v trvalTime_{route_{k,v},{rout_{k+1,v}}} trvalTimeroutek,v,routk+1,v ”由元素约束element constraint表示。
🐸最后,我们定义了与路由模型类似的目标变量。
表5总结了作为输入大小函数的步长模型的尺寸。

3.3 Branching strategies
我们在两个模型上都实现了两种不同的分支策略。在这里,我们描述了它们的逻辑和使用它们的条件。
“成本明智cost-wise”策略 (图5)在可用车辆vehicles之间循环,在每个转弯处首先 服务service,然后分配所选车辆vehicle路线中最后一个车站的 后续successor (除了固定服务的初始车辆段,图5a)。选择每个站点的服务service(图5b和d)和后续successor(图5e和e),以便贪婪地优化目标函数。为此,该策略总是选择平衡最大化的服务,然后选择下一步能够产生最高平衡的后续服务,与车辆的当前负载保持一致。由于使用了这种分支策略,在图5所示的运行中,服务者solver在10个步骤中实现了14的最终不平衡(为了简洁起见,其中一些步骤已被省略)。 该分支机构通常可以获得非常好的解决方案,但如果车辆在服务结束时需要清空,则会产生大量故障。发生这种情况是因为,当行为贪婪时,通常需要进行大量的回溯,以便在最后得到一个空车的解决方案。
Fig.5 猜测解析:
- D10表示库存, s 0 , ⋯ , s 9 s_0, \cdots,s_9 s0,⋯,s9表示站点
- 在D10引出两条箭头:红棕色,墨蓝色。 箭头的指向是根据“cost-wise”原则,分别选择的 ∣ + 10 ∣ \vert +10 \vert ∣+10∣的 s 2 s_2 s2,和 ∣ + 9 ∣ \vert +9 \vert ∣+9∣的 s 2 s_2 s2
- 每个矩形块中的红线:表示成本?或者表示在该站点装卸的自行车数量?
- 每个矩形块中的蓝线:表示站点的容量?或者表示站点的目标值?
- 对于两条线,对比每次的再平衡的成本或者装卸自行车的数量(即红线表示的绝对值), 值大的,进行再平衡操作。
- 矩形中的橙色表示站点的障碍大小,绿色表示解决成功。

a. 设置depot的(service变量和)successors[后继变量者们]
根据"wise-cost",车辆1选择了站点 s 2 s_2 s2, 车辆2选择了站点 s 3 s_3 s3
b. 设置
标号为1的vehicle的最后一个车站的service,并完成再平衡操作进行这一步的原因在于:车辆1的服务量为10,车辆2的服务量为9,选择最优的
此时,车辆1的内有10辆bikes
c . (车辆1服务完成后,先寻找其后继站点)设置车辆1的最后一个站点的后继站点
- 可选择: 根据“wise-cost” 原则,车辆1选择了服务量最高的站点 s 7 s_7 s7,其服务量为 ∣ − 8 ∣ = 8 \vert -8 \vert =8 ∣−8∣=8.
- 可满足:车辆1内有10辆bikes, 可以满足 − 8 -8 −8的需求
d. (两辆车都有后继站点的时候,选择服务量大的后继站点)设置车辆2的最后一个站点的服务量,并完成再平衡操作
车辆1: 内有10bikes, 服务量为-8
车辆2 : 内有0bikes, 服务量为+9
故,选择车辆2为服务站点,并完成再平衡操作
e. (车辆2完成服务后,先寻找后继站点) 设置车辆2在最后一个站点的后继站点
根据“cost-wist” ,选择后继站点为 s 8 s_8 s8, 其服务量 ∣ − 7 ∣ = 7 \vert -7 \vert=7 ∣−7∣=7
f. 根据以上规则,完成两个车辆的路线选择

总结“cost-wise”的规律- 从depot 0出,到depot 0进。(0: bikes的数目为0)
- 猜测: vehicle先在站点拾取自行车,后卸载自行车。
- vehicle的再平衡操作要满足 其容量的限制。
- 优先选择服务量(cost)大的站点作为车辆服务的后继站点
- 对于两辆车同时服务的时候,优先确定服务量大的vehicle进行服务(4,5两条充分保证服务最大原则)
- 猜测: 两辆车不会访问同一个站点
“可行性feasibility-wise ”策略(图6)并不旨在优化目标函数。相反,它试图通过利用简单的不变量快速获得可行的解决方案。在每个分支步骤braching step(对应于将路线延长两条腿)之后,每辆车vehicle的负载必须为零,以便车辆始终可以选择返回车辆段,从而产生可行的解决方案。这允许始终满足要求车辆在返回车depot之前清空的约束条件。为此,该策略考虑所有不平衡节点对是(否)互补的,并选择相互平衡最大的节点对。因此,在每个分支步骤中,两个后续步骤和两个服务都是固定的(图6a、b和c)。当然,这是对初始问题公式的限制,即这种分支策略不探索整个搜索空间。然而,当公式要求车辆vehicles在服务结束时为空时,这是一个合适的分支,可以找到合理的初始解决方案,或者启动启发式搜索策略heuristic search strategy(如LNS,在下一节中描述)程序。由于使用了这种分支策略,在图6所示的运行中,求解器仅用4步就实现了36的最终不平衡。

a. 两个互补节点匹配
vehicle 1首先选择了两个互补节点(s2[+10]和s1[-2]) , 这里的互补节点指的应该是正负性
vehicle 1在 s2 取走10辆车,然后全部送入 s 1 s1 s1, 则 s 1 s1 s1由 − 2 → + 8 -2 \to +8 −2→+8 ,vehicle 1空车了b. 更多的互补节点匹配
vehicle 2选择了两个互补节点(s5[+9]和s3[-1])
vehicle 2在 s 5 s5 s5取走了9辆车,然后全部送入 s 3 s3 s3,则变为了 − 1 → + 8 -1 \to +8 −1→+8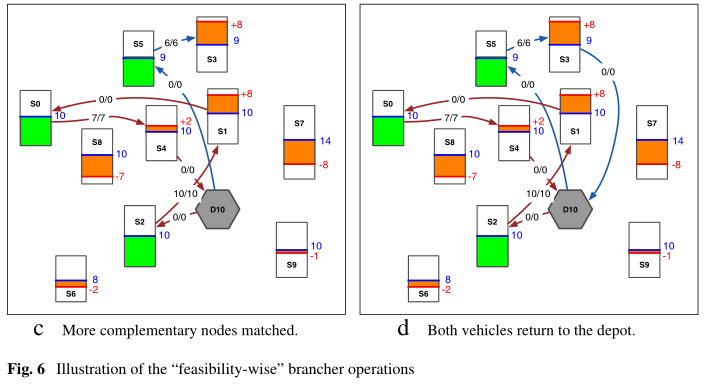
c. 更多的互补节点匹配
vehicle 1选择了一对新的互补节点(s0[+7]和 s4[-5])
vehihcle 1空车去了s0取走7辆车,又将车全部放到s4,则变为了 − 5 → + 2 -5 \to +2 −5→+2d. 两辆车返回depot
vehicle 1从 s 4 s4 s4空车返回depot
vehicle 2从 s 3 s3 s3空车返回depot总结‘’feasibility-wise”规则
- vehicle每次选择连续的互补站点,先取车使前一个站点再平衡,在后一个站点卸载全部车,使是vehicle可以随时返回depot
- 猜测: 两辆车不可访问同一个站点
4 Large neighborhood search
大邻域搜索Large Neighborhood Search(LNS)[11,18]是一种 局部搜索元启发式算法 ,基于这样的观察,即探索大邻域large nerghborhoode,即改变解决方案的重要部分,通常会导致比用小扰动获得的质量更高higher quality的局部优化。 虽然这在质量方面是一个毋庸置疑的优势,但这并不是没有代价的,因为探索大型社区结构可能需要计算。出于这个原因,LNS 通常采用允许去除不可行解决方案的过滤技术。 特别是,大型邻域探索已成功地与基于约束的传播相结合,用于解决复杂的路由问题,如具有时间窗口的 VRP [2,15]。
指定大邻域的惯用方法是定义两个步骤:
i)破坏步骤,取一个解并松弛其变量的数 d d d(破坏率);
ii)修复步骤,取松弛解并通过分配自由变量重构可行解,通常通过贪婪启发式或穷举搜索。
当然, d d d的不同值源自不同的邻域,并意味着不同的搜索努力。在最极端的情况下,当 d d d等于决策变量的总数时,原始解被一个新解完全替换,所有局部信息都会丢失,而如果d很小,则保留大部分解,只探索一个小的邻域。请注意,在第一种情况下,该方法类似于执行穷举搜索。通过在求解过程中调整 d 4 ,例如,基于搜索性能,可以对更复杂的行为进行编码,例如停滞避免。总体而言, L N S (参见算法 1 )的一般结构与经典邻域搜索 n e i g h b o r h o o d s e a r c h ( N S )的结构相似。在伪代码中,元组 d4,例如,基于搜索性能,可以对更复杂的行为进行编码,例如停滞避免。总体而言,LNS(参见算法1)的一般结构与经典邻域搜索neighborhood search(NS)的结构相似。在伪代码中,元组 d4,例如,基于搜索性能,可以对更复杂的行为进行编码,例如停滞避免。总体而言,LNS(参见算法1)的一般结构与经典邻域搜索neighborhoodsearch(NS)的结构相似。在伪代码中,元组N=

参考资料:《求解PDPTW问题的快速LNS算法》
《自适应大领域搜索算法(ALNS) 详解及python示例》
《大规模邻域搜索(LNS)求解带时间窗的车辆路径问题(VRPTW)(附MATLAB代码)》
《基于LNS算法的带时间窗和“灰色地带”客户的两级车辆路径优化》
从伪代码中,很容易意识到,与大多数元启发式算法一样,LNS 实际上是一个算法模板,其实例化,例如如何实现销毁和修复步骤,可能取决于特定问题的方面。在下文中,我们描述了我们对算法的“自由”部分的选择,并具体引用了算法1中的模板。
在我们的工作中,所描述的两个 CP 模型既可以独立使用,也可以用作LNS引擎的树搜索子例程。因此,当LNS引擎使用路由(resp.step)模型作为基础树搜索时,我们称为路由(resp.step)LNS。两种模型的LNS设置相似,但有些组件(特别是销毁步骤)是特定于模型的,因为它们取决于决策变量的语义或分支策略,这通常是不同的。我们将这些特定于模型的组件的描述推迟到本节的最后一部分
🔥INITIALIZESOLUTION初始解 通过使用所描述的分支策略之一进行树搜索来获得初始解。然而,搜索在找到第一个可行方案后停止,因为即使使用“成本明智”分支策略找到一个可行方案也需要大量时间,对于某些公式变体,我们在这一步骤中使用“可行性明智”分支战略。
🔥 REPAIR修复 与初始化类似,修复步骤包括有时间限制的分支和绑定树搜索,受限于下一个解决方案必须比当前解决方案质量更好的约束。搜索从宽松的解决方案开始,时间预算与其中的自由变量( t B A B ⋅ n f r e e t_{BAB}·n_{f re e} tBAB⋅nfree)的数量成比例。 树搜索总是采用“成本明智”的分支策略,因为要解决的问题通常比完整的问题小得多,因此使用面向质量的搜索是合理的。
🔥 SOLUTIONACCEPTED可接受的解 我们的算法实现支持各种不同的验收标准,如下所述。
Accept improvement (strict)接受改进(严格) : 如果修复后的解决方案 x t x_t xt严格改进了以前的最佳 x b e s t x_{best} xbest,那么它将被接受。如果修复步骤无法在分配的时间限制内找到解决方案,则增加空闲迭代计数器ii。当ii超过空闲迭代的最大次数iimax时,更新 d d d。
Accept improvement (loose)接受改进(松散) : 如果修复的解决方案 x t x_t xt等于或改进了先前的最佳 x b e s t x_{best} xbest,即允许横向移动,则接受该解决方案。如果修复步骤无法在分配的时间限制内找到改进的解决方案,则增加空闲迭代计数器ii(等效的解决方案不构成改进)。当ii超过空闲迭代的最大次数iimax时,更新 d d d。
Simulated annealing (SA) 模拟退火 首先,我们有一个随机分布 p ∼ U ( 0 , 1 ) p \sim U(0,1) p∼U(0,1),则我们计算新解的允许成本增加为 Δ = − ( t l n p ) \Delta=−(t ln p) Δ=−(tlnp)(反向 SA 规则),其中 t t t是SA中的典型温度参数。在该温度下已接受 ρ ρ ρ解,将温度 t t t更新为 t = t ⋅ λ t=t·λ t=t⋅λ,其中 0 < λ < 1 0<λ<1 0<λ<1。一旦已经计算好了 Δ \Delta Δ,我们使用它来约束松弛解的成本,并且我们接受分支约束步骤产生的任何解。如果修复步骤无法在分配的时间限制内找到改进的解决方案,则增加空闲迭代计数器ii。当ii超过空闲迭代的最大次数 i i m a x ii_{max} iimax时,更新 d d d。🔥 Update of d 更新: 销毁率 d d d在搜索过程中不断变化,以实施强化/多样化战略,避免搜索停滞。在我们的实现中,在每个步骤中,其值都会更新如下

其中ii是当前以破坏率 d d d执行的空闲迭代次数, i i m a x ii_{max} iimax是此类迭代的最大次数。当修复步骤在给定邻域中找不到改进的解决方案时,该更新方案将增加邻域的半径以允许解决方案多样化。当找到新的最佳解时,原始初始邻域半径被重置,从而加强了对新发现的解区域的探索。当 d d d被更新时,计数器ii被复位。如果使用了 d = d m a x d=d_{max} d=dmax和最大空闲迭代次数,则通过以 d = 2 d m a x d=2d_{max} d=2dmax破坏率扰动解来重新开始搜索。STOPPINGCRITERION停止标准 :我们允许算法有一个给定的超时,当时间到了,算法会被中断,并返回找到的最佳解决方案。
DESTROY破坏 : 如前所述,销毁步骤是我们实现的唯一特定于模型的组件。事实上,这是LNS最相关的方面,因为它需要仔细选择必须放松的变量,以避免无意义的组合。
Routing model: 通过从每条路线 R i R_i Ri中随机均匀选择 d ⋅ ∣ R i ∣ d·|R_i| d⋅∣Ri∣个站点,并将这些站点的succ、service和vehicle变量重置为其原始域,生成松弛解。此外,还释放了放松站之前的站的成功变量,以允许不同的路线。注意,由于我们也考虑这些变量,放松变量的最终分数实际上大于 d d d。
Step model:: 松弛解是通过选择 d ⋅ ∑ i ∣ R i ∣ d·\sum_i|R_i| d⋅∑i∣Ri∣内部节点(即,不包括depots)从所有路线中随机均匀分布,并重置route和service变量。请注意,这与路由模型中的销毁步骤不同,因为无法保证路由之间的松弛平衡。5 Test instances
5.1 CityBike Wien benchmark set
5.2 Mixed instances benchmark set
5.3 Citibike NYC benchmark set
6 Experimental evaluation
在本节中,我们报告并讨论了算法的实验分析。所有的实验都是在一台Ubuntu Linux 13.10机器上执行的,该机器有16个Intel Xeon CPU E5-2660(2.20GHz)内核和32 GB RAM。这种处理器采用(英特尔)超线程技术将每个内核拆分为两个虚拟内核。在我们的实验中,32个虚拟核中的每一个都专用于一个不同的实验,因此该实验在单核环境中运行。原则上,我们的LNS引擎能够在每次调用树搜索子例程时利用并行性,但是在本次测试中没有利用这种能力。
为了公平比较,CP和LNS算法均在GECODE(v 4.2.1)中实现[10]。LNS实现包括基于GECODE框架的专门搜索“元引擎”。不同引道的允许运行时间通常为30分钟,但Wien CityBike的情况除外,因为与其他引道相比,时间限制提高到60分钟。
在所有实验中,车辆容量均设置为20辆自行车,除CityBike Wien实例的时间预算随所考虑的实例组而变化外,对于所有实验,所有车辆的时间预算 t ^ v \hat{t}_v t^v均设置为360分钟。最后,根据[13],将 w 1 w_1 w1和 w 2 w_2 w2的目标权重设置为 w 1 = 1 w_1=1 w1=1 , w 2 = 1 0 − 5 w_2=10^{−5} w2=10−5.
6.1 Tuning of LNS parameters
通过运行置信水平为0.95的F-Race[3],我们对每个基准集的LNS方法的参数进行了调整。由于计算工作量大,这些比赛的实验运行了15分钟。表6总结了各种基准设置的最佳参数设置。
6.2 Models analysis
第一组实验旨在分析不同变体中的两种模型,并进行比较。特别是,我们想研究[13]的原始BBSS模型或我们之前关于模型的工作[8,9]中引入的一些建模假设对CP解算法的影响.
具体而言,我们考虑以下备选方案:i)放宽车辆必须空车到达其最终停车场的假设,ii)放宽车站服务的单调性约束,iii)两次访问车站的可能性。
表7显示了在这些实验中分析的 CP 模型的不同变体。已经在路由和步骤模型上对这些因素进行了全因子实验(即所有可能的设置组合)。这些求解器已经在Citibike NYC基准集的一个子集实例上运行。我们从{40、80、…、240}中的每个尺寸值的基准集中选择一个实例,并用2、4和6辆车进行求解。

除了解算器发现的解决方案的成本值,我们还记录了其他指标,如发现的(严格改进的)解决方案的数量、探索的搜索节点的数量、失败的数量(即回溯)和传播的数量。结果在第7、8、9、10和11页。
在图中,我们以盒子和胡须图的形式报告结果,这是显示结果分布的一种紧凑方式。该框包含分布的第1个和第3个四分位数之间的值,也称为四分位数范围或IQR。中间带表示为中间水平线。延伸到盒子外的胡须标记分布的最小值和最大值,除非这些值超过IQR的1.5倍。超过1.5 IQR的极值标记为点。方框图和胡须图显示了所考虑的度量值相对于实例大小的分布。此外,汇总结果的各个方面将突出这些特定因素对所考虑指标的影响。在所有图中,结果都是基于CP模型来区分的:粉红色(最左边)方框图表示路由模型,而绿色(最右边)方框图则表示步骤模型。
查看这些图,首先要注意的是,施加单调性约束会不断减少路线模型可以找到的解决方案的数量,同时提升阶梯模型的分布(图7),而放松对最终车辆负载的约束对该指标的影响较小。 然而,从图8(其报告了相对于初始站点不平衡的改善百分比)可以看出,车辆最终负载约束的存在对路线模型有更深的影响,有助于搜索向更大的改进迈进。相反,步骤模型对于这些约束几乎完全不可知。


另一个有趣的分析涉及建模变量对传播次数和回溯次数的影响。从图9和图10可以清楚地看出,车辆最终载荷约束对两个指标的影响有限,而最有影响的因素是单调性约束的存在。


最后,我们分析了允许同一节点多次访问的影响。考虑到单调性约束的主要影响,我们仅对这方面的结果进行汇总。在图11中,我们报告了相对于初始站点不平衡的改善百分比。可以看出,允许多次访问对解决方案质量有害。该分析的结果为我们决定在以下实验中使用的模型变量提供了帮助。考虑到车辆最终负载约束对解决方案质量几乎没有影响,并且允许一次以上访问没有任何好处,在下面的实验中,我们将把这些设置固定为每个节点一次访问,并且不允许在终点站进行最终负载。关于单调性,我们将在不同设置的Mixed和Citibike NYC基准集上进行实验。
6.3 Runtime behavior
作为附加分析,我们展示了通过CP和LNS求解的两个模型的原始变体的运行时行为的示例。图12显示了两种模型上由两种搜索策略(CP和LNS)表示的四种算法变体的单次运行。该图显示了解决方案成本在维也纳数据集中一个平均大小的实例(60个站点、3辆车、8个小时重新平衡)中一小时内的演变。虽然单次运行不能代表所有可能的情况,但所显示的结果与表8中的结果一致。在有限的时间内,步长模型通常比路由模型更好,LNS比CP更好。应该注意的是,在小的情况下,系统的分支和边界搜索甚至可以获得比LNS更好的结果,但是这种问题大小在现实世界的共享单车系统中并不常见。
6.4 Impact of the custom look-ahead propagator
在早期研究阶段引入了定制的前瞻传播器,试图降低故障率,即在1小时超时内没有可行解决方案的运行分数,这一问题尤其影响到较大的实例。这一目标后来通过前瞻传播器和“可行性”分支器的联合应用得以实现。为了单独评估先行传播器的影响,我们进行了额外的实验,测试了未配备先行约束时路由模型(CP搜索)的性能。
将结果与表8的路由CP列中的结果进行了比较。比较表明,在较小的实例中(大小为10,平均成本增加<1%),先行传播器的影响最小,但随着实例大小的增加(大小分别为20到30,平均成本增加∼ 20%和∼ 28 %). 在大小为60及以上的实例中,启用先行传播器非常关键,因此在1小时的超时时间内,如果没有它,就不可能找到任何可行的解决方案。
6.5 Comparison with other methods
在第二个实验中,我们将我们的CP和LNS求解方法与[13]的最新结果进行了比较,[13]使用混合整数线性规划求解器(MILP)和可变邻域搜索(VNS)策略求解了CityBike Wien实例集。请注意,我们没有与其他方法进行比较,因为它们要么将平衡视为硬约束[1,6],要么不考虑静态问题版本[5]。在[13]的设置中,单调性约束是强制性的,因此我们也在两个模型中启用它们。此外,为了使用与[13]中相同的实验设置,我们让算法运行一小时。
比较结果如表8所示。每行报告的结果为150个实例的平均值,按大小、车辆数量和车辆总可用时间分组。标有f的列报告了每类实例的平均最佳成本。列 ub 和 lb 表示用MILP获得的上限和下限。列标记为 Δ L N S \Delta_{LNS} ΔLNS(CP部分)和 Δ V N S \Delta_{V NS} ΔVNS(在 LNS 部分)分别标记了使用纯 CP 和 LNS 求解模型时的成本差异,以及使用LNS和VNS方法求解模型时成本差异[13]。如果LNS(分别为VNS)方法提高了功能质量,则 Δ L N S / V N S \Delta_{LNS/VNS} ΔLNS/VNS为正,如果降低了功能质量则为负. 最后,用破折号标记的单元格表示算法无法在一小时内找到可行解决方案的实例类。
我们首先对属于同一类方法的方法进行比较:即精确/启发式。至于确切的方法(即两种CP变体和MILP),可以观察到CP模型对于中大型实例(S≥ 30). 此外,他们能够在MILP无法找到任何结果的情况下找到至少一个解决方案。在这些设置中,路由模型的性能优于阶梯模型。
转到启发式方法的比较,明确(和总体)胜利者是VNS程序[13]。然而,可以注意到,LNS正在进一步改进CP找到的解决方案,从而证明其在这个问题上的使用是合理的。
6.6 Results on Mixed instances
本节报告了我们的方法在混合实例上获得的结果。
表9显示了基准集每个实例的结果,其中车辆数量已固定为足以满足实例大小。从表中可以清楚地看出,两种模型具有相似的性能,但是步长模型有时会获得更好的结果。这可以用单调约束是活动的这一事实来解释,从而破坏了路由模型的性能,同时增强了步长模型的性能。这与第6.2节的发现一致。
6.7 Results on Citibike NYC instances
本节报告了我们在一组Citibike NYC实例中采用的方法获得的结果。表10显示了按实例大小分组的结果,而车辆数量已固定为足以满足实例大小。从表中可以注意到,无论是在纯CP公式中还是在使用LNS策略时,路由模型都始终优于步长模型,尽管差异从未特别大。路由模型在这些实例上的优越性可以通过以下事实来解释:在这些实验中,我们放弃了单调性约束,因此结果再次与第6.2节的比较分析结果一致。
7 Conclusions
在本文中,我们研究了约束规划在解决共享单车系统平衡问题中的应用。我们制定了两个约束模型,将其纳入大型邻域搜索(LNS)方法,并在三组大型真实世界基准上评估了精确和启发式方法。特别是,我们的贡献如下:
我们的第一个贡献是BBSS的两个不同约束模型:路由模型和步骤模型。路线模型结合了问题的车辆路线视角,而步骤模型结合了人工智能规划视角。对于这两种模型,我们提出了新的和改进的公式和分支策略。我们在实证评估中研究了它们的差异,观察了每种配方的优缺点。在我们的实验评估中,我们看到两种约束模型在中型和大型问题实例上都优于最先进的精确方法。
其次,我们为BBSS提出了一个大型邻居搜索(LNS)策略(每个模型一个)。在我们的实证评估中,我们观察到,与纯CP方法相比,LNS方法在更大的情况下尤其强大,它可以更好地利用其支配的时间预算,而不依赖于约束模型。此外,LNS方法被证明与最先进的方法具有竞争力,即使在短时间内也能找到好的解决方案。
我们的第三个贡献在于我们能够用我们的方法解决的大量现实问题实例和问题设置。由于每个基准集的问题侧约束不同,因此需要根据每个问题公式调整约束模型。我们展示了如何通过省略或向各个模型添加约束来轻松实现这一点。这种灵活性和可移植性是约束公式的最大好处之一,并证明了应用约束编程来平衡共享单车系统的优势。事实上,这表明我们的CP方法可以成功地应用于许多不同的共享单车提供商。
对于未来的工作,我们希望考虑BBSS的动态变体,其中共享单车系统在白天平衡,当用户使用该系统时,因此自行车站的负载和需求会随着时间变化。
附录
A.LNS的伪代码编程
\begin{algorithm} %生成浮动式图 \caption{大邻域搜索算法(LNS)} %标题 % 由algorighmic完成代码的编译部分 \begin{algorithmic}[1] %[1]表示每行显示行号 ,且由123..排序 \Procedure{LargeNerghborhoodSerach}{N=- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
B. 索引该篇+自行车的文章
-
相关阅读:
OpenCV4.9.0开源计算机视觉库在 Linux 中安装
深入理解Docker:简化部署与管理的利器
ESB+MDM同步分发流程开发总结
小项目-词法分析器
GPG加密解密
Real-Time Rendering——15.2 Outline Rendering轮廓渲染
How to install mongodb 7.0 to Ubuntu 22.04
力扣刷题day52|84. 柱状图中最大的矩形
腾讯大佬的“百万级”MySQL笔记,基础+优化+架构一篇搞定,秋招必看系列!
第4章_freeRTOS入门与工程实践之开发板使用
- 原文地址:https://blog.csdn.net/panbaoran913/article/details/127509047
