阅识风云是华为云信息大咖,擅长将复杂信息多元化呈现,其出品的一张图(云图说)、深入浅出的博文(云小课)或短视频(云视厅)总有一款能让您快速上手华为云。更多精彩内容请单击此处。

摘要:MapReduce是Hadoop的核心,是Google提出的一个软件架构,用于大规模数据集(大于1TB)的并行运算。概念“Map(映射)”和“Reduce(化简)”,及他们的主要思想,都是从函数式编程语言借来的,还有从矢量编程语言借来的特性。
本文分享自华为云社区《【云小课】EI第42课 MRS基础原理之Mapreduce介绍》,作者:Hello EI
MapReduce是Hadoop的核心,是Google提出的一个软件架构,用于大规模数据集(大于1TB)的并行运算。概念“Map(映射)”和“Reduce(化简)”,及他们的主要思想,都是从函数式编程语言借来的,还有从矢量编程语言借来的特性。

MapReduce是面向大数据并行处理的计算模型、框架和平台。当前的软件实现是指定一个Map(映射)函数,用来把一组键值对映射成一组新的键值对,指定并发的Reduce(化简)函数,用来保证所有映射的键值对中的每一个共享相同的键组。
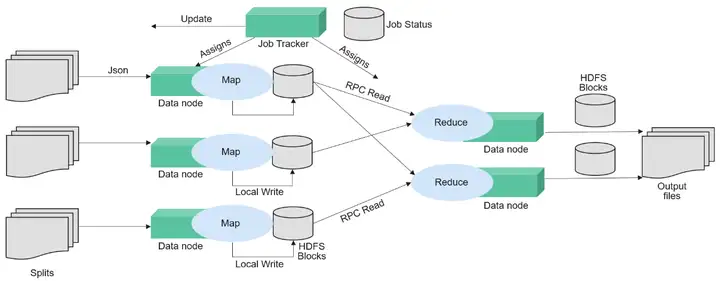
MapReduce是用于并行处理大数据集的软件框架。MapReduce的根源是函数性编程中的map和reduce函数。Map函数接受一组数据并将其转换为一个键/值对列表,输入域中的每个元素对应一个键/值对。Reduce函数接受Map函数生成的列表,然后根据它们的键缩小键/值对列表。MapReduce起到了将大事务分散到不同设备处理的能力,这样原本必须用单台较强服务器才能运行的任务,在分布式环境下也能完成。
MapReduce结构
MapReduce通过实现YARN的Client和ApplicationMaster接口集成到YARN中,利用YARN申请计算所需资源。
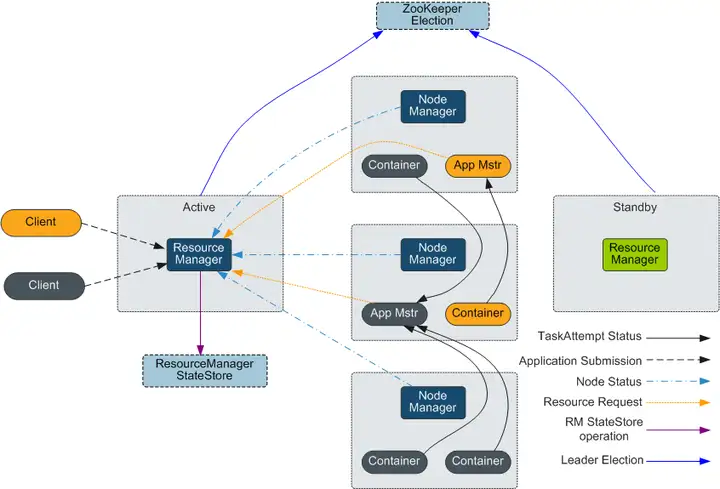
HDFS是Hadoop分布式文件系统,具有高容错和高吞吐量的特性,可以部署在价格低廉的硬件上,存储应用程序的数据,适合有超大数据集的应用程序。
而MapReduce是一种编程模型,用于大数据集(大于1TB)的并行运算。在MapReduce程序中计算的数据可以来自多个数据源,如Local FileSystem、HDFS、数据库等。最常用的是HDFS,可以利用HDFS的高吞吐性能读取大规模的数据进行计算。同时在计算完成后,也可以将数据存储到HDFS。
MapReduce是运行在YARN之上的一个批处理的计算框架。MRv1是Hadoop 1.0中的MapReduce实现,它由编程模型(新旧编程接口)、运行时环境(由JobTracker和TaskTracker组成)和数据处理引擎(MapTask和ReduceTask)三部分组成。该框架在扩展性、容错性(JobTracker单点)和多框架支持(仅支持MapReduce一种计算框架)等方面存在不足。MRv2是Hadoop 2.0中的MapReduce实现,它在源码级重用了MRv1的编程模型和数据处理引擎实现,但运行时环境由YARN的ResourceManager和ApplicationMaster组成。其中ResourceManager是一个全新的资源管理系统,而ApplicationMaster则负责MapReduce作业的数据切分、任务划分、资源申请和任务调度与容错等工作。
如何在MRS集群中提交一个MapReduce分析作业
应用开发完成后,用户可通过MRS云服务管理控制台直接提交Mapreduce作业,也可以通过集群客户端提交。
首先参考MRS快速入门中的“创建集群”章节购买一个MRS集群,例如购买MRS 3.1.0版本集群,该集群已开启Kerberos认证。
通过界面提交MapReduce作业
1、登录MRS管理控制台。
2、选择“集群列表 > 现有集群”,单击集群名称,进入集群信息页面。
3、在“概览”页签的基本信息区域,单击“IAM用户同步”右侧的“同步”进行IAM用户同步。
4、单击“作业管理”,进入“作业管理”页签。
5、单击“添加”,进入“添加作业”页面。在“添加作业”页面配置以下信息。
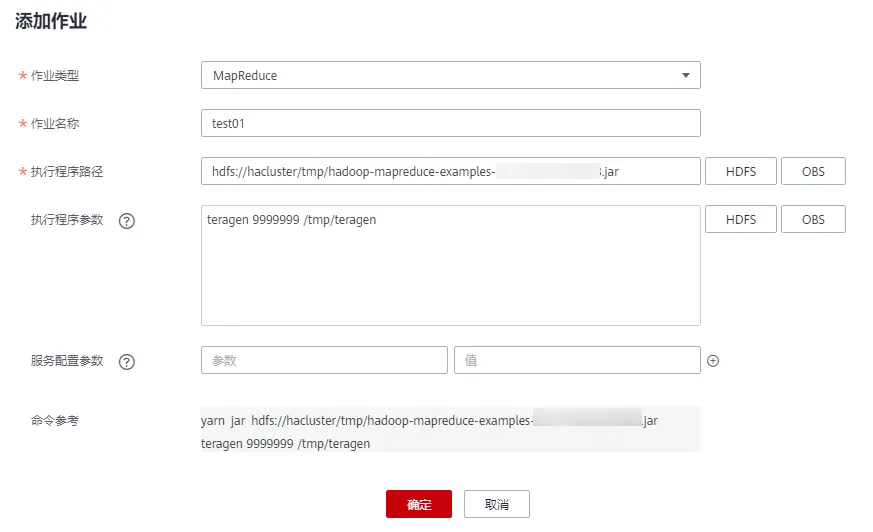
作业类型:MapReduce
作业名称:test01
执行程序路径:单击“HDFS”,并选择待执行的jar文件。例如:hdfs://hacluster/tmp/hadoop-mapreduce-examples-xxx.jar(此处以hadoop example程序为例,已提前将jar包上传至HDFS)
执行程序参数:teragen 9999999 /tmp/teragen (表示随机生成9999999行的数据,并将执行结果放置在“/tmp/teragen”路径下)
6、确认作业配置信息,单击“确定”,完成作业的新增,等待执行结果变为“成功”。

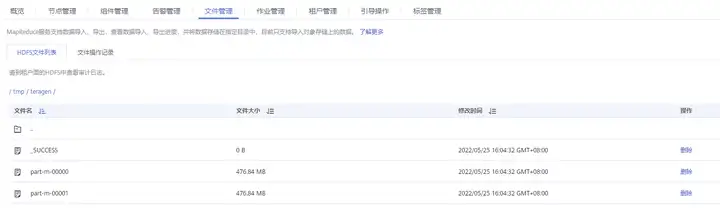
7、选择“文件管理 > HDFS文件列表”,在“/tmp/teragen”路径下查看到新生成的文件。
通过客户端CLI提交作业
我们也可以通过集群的客户端,以命令行的形式来提交作业。
1、安装集群客户端,可参考MRS用户指南中的“安装客户端”章节,例如客户端安装目录为:“/opt/client”。
2、登录客户端服务器,进入客户端目录。
cd /opt/client
source bigdata_env
kinit 集群业务用户
3、执行以下命令提交任务。
yarn jar HDFS/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-*.jar teragen 9999999 /tmp/teragen
4、执行结果显示“Job xxx completed successfully”表示执行成功。

... 2022-05-26 19:16:02,274 INFO mapreduce.Job: Job job_1653461199536_0001 running in uber mode : false 2022-05-26 19:16:02,275 INFO mapreduce.Job: map 0% reduce 0% 2022-05-26 19:16:14,453 INFO mapreduce.Job: map 50% reduce 0% 2022-05-26 19:16:16,471 INFO mapreduce.Job: map 100% reduce 0% 2022-05-26 19:16:16,482 INFO mapreduce.Job: Job job_1653461199536_0001 completed successfully 2022-05-26 19:16:16,601 INFO mapreduce.Job: Counters: 33 File System Counters FILE: Number of bytes read=0 FILE: Number of bytes written=587030 FILE: Number of read operations=0 ...
5、执行以下命令,查看“/tmp/teragen”路径下文件生成成功。
hdfs dfs -ls /tmp/teragen Found 3 items -rw-r--r-- 3 developuser hadoop 0 2022-05-26 19:16 /tmp/teragen/_SUCCESS -rw-r--r-- 3 developuser hadoop 500000 2022-05-26 19:16 /tmp/teragen/part-m-00000 -rw-r--r-- 3 developuser hadoop 499900 2022-05-26 19:16 /tmp/teragen/part-m-00001
6、使用业务用户登录FusionInsight Manager界面,进入Yarn服务概览页面,单击“ResourceManager(主机名,主)”,在Yarn的原生界面,也可以查看该作业的详细信息。
好了,本期云小课就介绍到这里,快去体验MapReduce(MRS)更多功能吧!猛戳这里