-
MMML-CMU 学习笔记_No.1 Multimodal Introduction
What is Multimodal?什么是多模态?
多模态可以在数学上被视为多峰分布,峰指的是概率密度函数中的不同“峰值”(局部最大值)

但在我们实际生活中,更多的是指多种不同的感知方式,比如气味,触觉,听觉,视觉等等。

本门课主要研究交流行为中的多模态问题:语言,声音,视觉

多模态与多媒体的区分:
模态是某事发生或经历的方式。模态是指某种类型的信息或存储信息的表示格式。
多媒体指的是存储或通信的手段或工具。比如声音是一种模态,但是音频是一种媒介。
A Historical View 发展历史
多模态的发展可以划分为四个阶段:“行为”阶段,“计算”阶段,“互动”阶段和深度学习阶段。

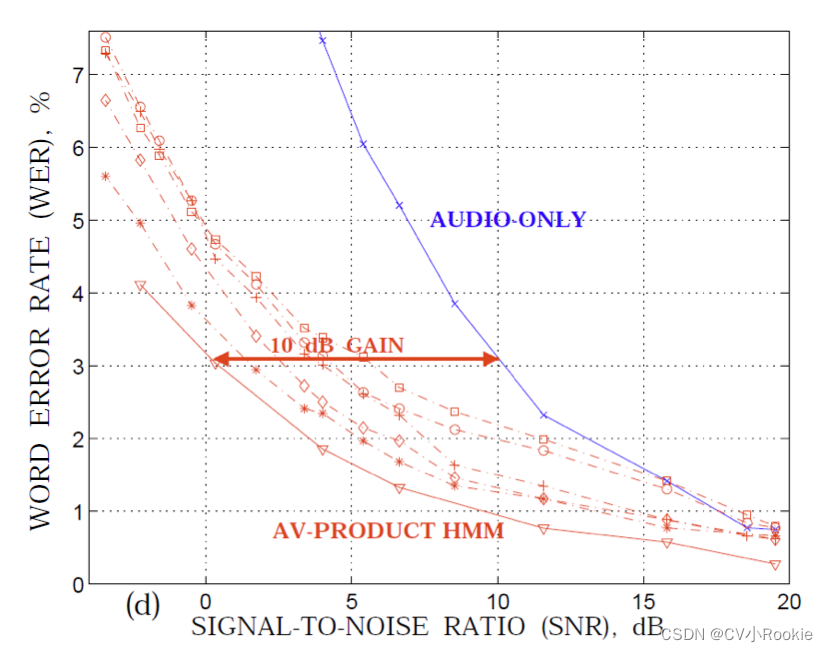
第一阶段“行为”:更多的是从人的行为出发,比如想要做语音识别,有的时候发音过于相似,只根据音频数据很难进行准确划分,可能需要借助视频去观察讲话者的嘴唇(课程视频中有举例)
第二阶段“计算”:在多数情况下可能一种模态信息就足以帮助我们进行分辨,再加上视频数据显得重复与冗余。但是在一些特殊场景下,比如 Audio-Visual Speech Recognition (AVSR),音频与视频数据在冗余之外还可能存在互补性,所以这种关系也让模型更加强大,拥有更好的鲁棒性(毕竟两种模态最后的编码内容是一致的)
第三阶段“互动”:研究人们之间互动,互动是多种多样的,面部表情,语音语调等多模态研究
第四阶段深度学习:多模式研究的关键推动因素:新的大规模多模式数据集;更快的计算机和 GPUs;高级视觉特征;“维度”语言特征。后面两个可以说一下,因为有神经网络的出现,无论是视觉(图像)还是音频单词都可以经过变化映射到一个向量当中,所以不同的模态所具备的形式更加的近似(高维表示相似)这很好的推动了深度学习在多模态领域的发展。(第四阶段也是本门课更加关注的地方)
Core Technical Challenges 核心技术
Representation 表示*

图中表示,意义相似但表示方式不同的数据在高维空间表示也会表现出一定的关联性(这点我记得在机器翻译当中,同一个物品虽然语言不通,但是映射得到的高维向量却相近,好像有相关的研究去证实这一点)
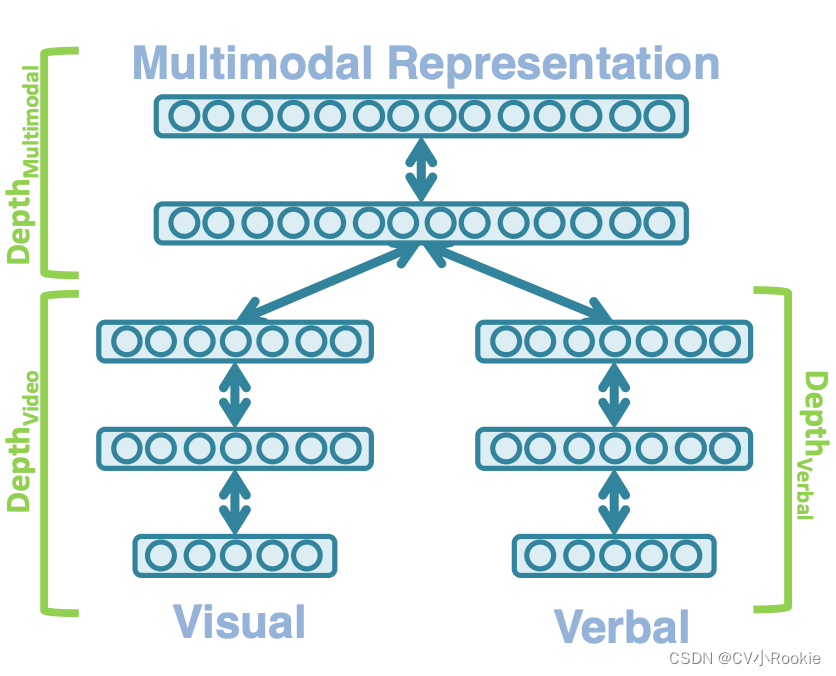
多模态表示就是将不同的数据进行特征提取,映射到不同向量中,然后利用不同模态下的数据之间的互补性和冗余性来表示和总结多模态数据。
统一的表示形式带来的一个好处是哪怕是不同表达方式的事物,但是有相同的表示形式,比如“红色”可以和“热情”相近。在一些相关工作上例如多模态向量空间算术 Multimodal Vector Space Arithmetic 中,研究人员对蓝色汽车进行编码,对“red”和“blue”也分别进行表示,当对于蓝色汽车的编码减去“blue”的编码再加上“red”的编码就会产生有趣的事情:原本蓝色的汽车变成了红色的汽车。

表示分可以为两种:联合表示 Joint representations 和协调表示 Coordinated representations。

联合表示是将不同模态的数据映射到同一个向量中去表示;协调表示则是让不同模态的数据就存在自己的向量,这些向量是多模态表示的子空间,我们应该找到一种方式去让不同模式的向量进行对应,这也就是在一个研究重点 Alignment 。
Alignment 对齐**
定义:识别来自两种或多种不同模式的(子)元素之间的直接关系。
对齐也包含两种情况:显式对齐 Explicit Alignment 和隐式对齐 Implicit Alignment。


左图就是一种 Explicit Alignment 真实的动作和火柴人的动作一一对应,右图是 Implicit Alignment 图片里的含义与单词存在对应关系。
Translation && Fusion
Translation:将数据从一种模式变为另一种模式的过程,其中翻译关系通常是开放式的或主观的。

Fusion:连接来自两个或多个模态的信息以执行预测任务。


这两部分我更倾向于看作多模态领域不同的任务的划分:Translation 做的是从一种模态到另一种模态的映射比如给定一张图片,输出是对于这幅图像的描述。Fusion 作的就比较高级,当然也可以看做是找一种映射关系,只不过要找到的东西是一种更高级的特征,比如情感识别或者预测。
Co-Learning 联合学习
定义:在模态之间转移知识,包括它们的表示和预测模型。
我个人的理解是利用多峰问题去解决单峰问题,通常我们所遇到的问题还是比较单一的,但如果我们利用多模态的内容去提高单峰问题解决能力。
但是co-learning面临的挑战是使用的第二个模态(辅助)对于第一个模态(实际的单峰问题)链接配对问题。

下面看一个co-learning的事例
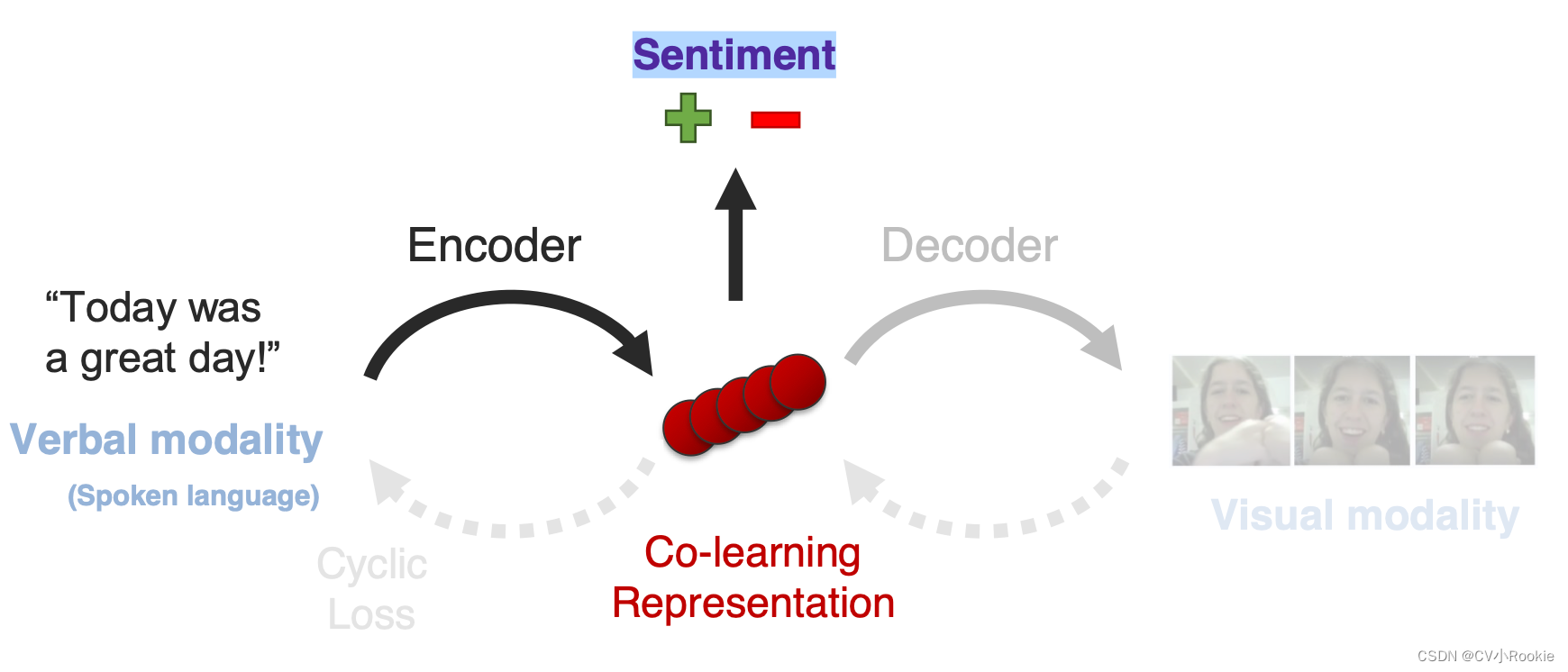
任务本身是做口语对于视觉的翻译,但是在单向的情况下(verbal2visual)潜在空间可能学到的东西更加偏向输出,并不能确定潜在空间学习到的就是“情绪”本身。通过引入循环损失,学习反向映射(visual2verbal),就让潜在空间更加贴近输入。幸运的是这样真的有效,好像潜在空间真的学习到了“情绪”本身。抛开多模态,当在一个小的数据集上进行情感分析的实验时,单一模态模型的训练与测试就像多模态模型一样。
总结
多模态问题存在的5个挑战:表示representation;对齐alignment;翻译translation;融合fusion;联合学习co-learning。

面临的一些具体挑战与方法和相关应用。


-
相关阅读:
内部即时通讯软件,为企业协同办公保驾护航
照片图片 动漫化 卡通化
Eigen
输入的这些数是否对称
QT day5
考研英语易混词整理【闪过】
架构设计时需要遵守的七大原则
graphviz 绘制红黑树
git还原到之前某个版本
机器学习 周志华 第一章课后习题
- 原文地址:https://blog.csdn.net/like_jmo/article/details/127629438