-
[笔记] FragmentVC(2021)
[笔记] FragmentVC(2021)
Author : Xin Pan
Date: 2022.09.14
台湾国立大学2021年发表在ICASSP的工作,关于VC的工作。论文标题全文是
FragmentVC: Any-to-any voice conversion by end-to-end extracting and fusing fine-grained voice fragments with attention。
摘要
任意人到任意人的VC目标是将源发音人的音色转换到目标发音人上,即便目标发音人和源发音人都是在训练时未曾出现的发音人。这是相比一对一,多对多更具有挑战的任务,而这也在现实场景中更加吸引我们,因为这个情况更加常见。在这个论文中作者团队提出了FragmentVC。使用Wav2Vec 2.0从源发音人语句中隐式提取音素结构。目标发音人的语谱特征使用log 梅尔谱。通过一个二阶段训练过程,可以将两个不同的特征空间中的隐式结构对齐。FragmentVC能够从目标发音人中提取细粒度的语音片段,然后将它们融合进期望的语音。而这都是验证过Transformer中注意力机制,通过attention map进行的验证,而且是端到端完成的。FragmentVC只使用重构损失,没有使用其他的内容和说话人信息,而且不需要平行语料。使用说话人验证的客观评价方式和主观评价方式如MOS都表明这个方法超过了SOTA方法,例如AdaIN-VC和AUTO-VC
解释:
Any-to-any 任意到任意的发音人VC。这里的任意是可以不在训练集内。
Many-to-many 多到多的发音人VC。但是发音人都在训练集内,也就是训练集内互转。
One-to-one 一对一的发音人VC。发音人在训练集内,可以理解为Many-to-many的一个特例。
从难度上来说从难到易:Any-to-any >Many-to-many >One-to-one
论文十问
Q1论文试图解决什么问题?
性能超过当时SOTA(AdaIN-VC和AUTO-VC)的Any-to-any voice conversion系统。
Q2这是否是一个新的问题?
不是一个新的问题。
Q3这篇文章要验证一个什么科学假设?
个人感觉这篇论文并不是验证什么假设,而是提出这个思路并验证这个方法有效。如果这个思路是科学假设的话。那么要验证的科学假设就是使用wave2vec并使用src encoder +target encoder+decoder的思路,训练时使用文中的二阶段训练策略在any-2-any 场景下是有效的。
Q4有哪些相关研究?如何归类?谁是这一课题在领域内值得关注的研究员?
个人感觉相关的研究有AdaIN-VC,AUTOVC和StarGAN2-vc。可以通过使用场景,any-to-any 还是many-to-many进行分类。像MSRA的谭旭可以关注。
Q5论文中提到的解决方案之关键是什么?
FragmentVC没有使用attention 去学习源和目标语句之间的单调对齐。
FragmentVC 学习去利用从源语句提取隐式音素信息之后将他们融合进目标语句的细粒度声音片段中。
AuToVC(2019)和AdaIN-VC(2019)是最早做any-to-any VC的算是。他俩最早是通过一个上下文编码器和说话人编码器去做文本信息和说话人信息的解耦。
AdaIN-VC利用样例标准化(instance normalization)去做源发言人到目标说话人的转换。
AuToVC是利用一个预训练的说话人编码器去做说话人的信息提取,然后用一个bottleneck去做源目标发音人信息泄露的遏制。
相比而言,FragmentVC使用目标发音人语句提取并融合适当信息进入细粒度声音片段,这里说的很模糊。
FragmentVC的整体结构如图所示。
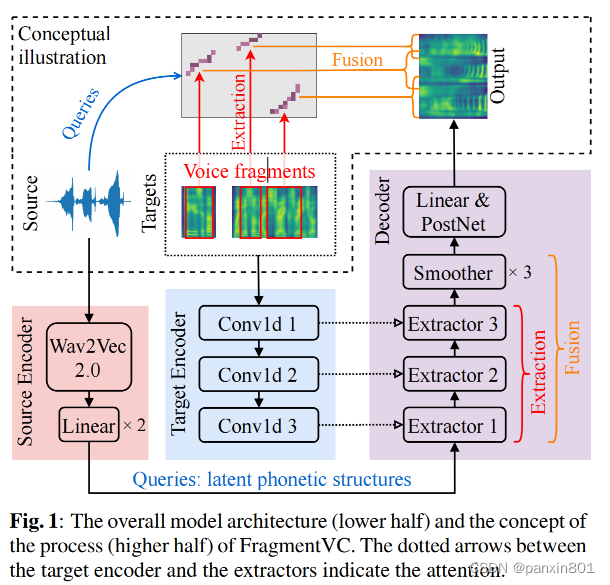
其中解码器里边是多个Extractor和Smoother的叠加。为的是以非自回归的方式做目标发音人的log mel-spectrogram。
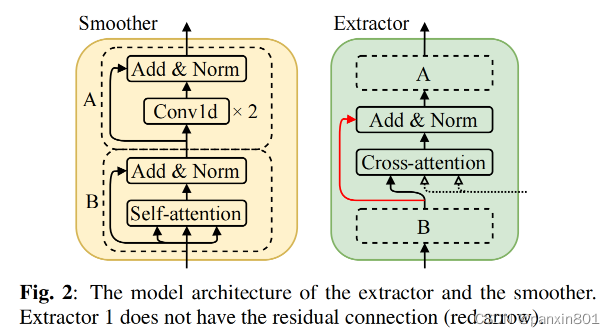
如果说到用我自己的话总结这论文的方案关键,就是提取src内容信息并通过attention融合进target的细粒度语音片段中。这里个人是这么理解的。如果有意见希望大家一起讨论。
Q6论文中的实验是如何设计的?
使用当时的SOTA,AdaIN-VC和AUTOVC做对照组。Vocoder使用的是WaveRNN。
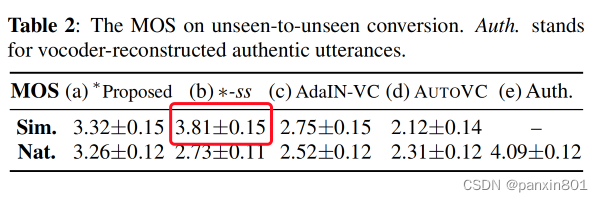
测试场景分为两个。一个是集内互转(seen-to-seen),另一个是集外转集外(unseen-to-unseen)。在两个测试场景中各随机选择了1000组测试对,每个对包括一个source speaker 语句和10个target speaker 语句。为了和实际情况靠近,数据选择的时候排除了source 和target 语句文本内容一致的情况。
Q7用于定量评估的数据集是什么?代码有没有开源?
使用的数据集是109 speaker,44小时的VCTK。代码开源。https://github.com/yistLin/FragmentVC
Q8论文中的实验及结果有没有很好地支持需要验证的科学假设?
比较全面系统的验证了科学假设。从主观和客观评价两个维度评价。客观维度从相似度和自然度进行了评价。算是全面。可能唯一不足在于只使用了VCTK做实验,如果可以再加一个实验,会更完美,另外加上RTF更完美。可能对于学术来说这不重要。
Q9这篇论文到底有什么贡献?
提出any-to-any的voice conversion。通过提取并融合音频片段使用attention来构建目标语句。
Q10下一步呢?有什么工作可以继续深入?
论文最后提到使用其他的预训练模型替换Wav2Vec 另外如何将Wav2Vec 和FragmentVC做joint training 是一个有意思的事情。
但另一个有意思的地方在于,消融实验中不使用二阶训练会让相似度提升,这挺有意思的,原因论文中没有提及。
-
相关阅读:
【luogu P1912】诗人小G(二分栈)(决策单调性优化DP)
Linux重定向
DiFi A Go-as-You-Pay Wi-Fi Access System 精读笔记(三)
大学生游戏静态HTML网页设计 (HTML+CSS+JS仿英雄联盟网站15页)
【笔者感悟】笔者的学习感悟【二】
【RabbitMQ】——路由模式(Direct)
zlMediaKit 3 socket模块--怎么封装socket,怎么connect listen/bind write read
C++数据结构X篇_20_选择排序
Unity 如何实现框选游戏战斗单位
React报错之Expected `onClick` listener to be a function
- 原文地址:https://blog.csdn.net/panxin801/article/details/127634591