-
机器学习基础介绍
这算是一篇对机器学习的扫盲文章吧,在这篇文章中将会主要的介绍一些有关机器学习的基本概念。
同时读者可以点击链接:机器学习-目录_欲游山河十万里的博客-CSDN博客
学习完整的机器学习的相关知识。
机器学习
正如我们根据过去的经验来判断明天的天气,吃货们希望从购买经验中挑选一个好瓜,那能不能让计算机帮助人类来实现这个呢?机器学习正是这样的一门学科,人的“经验”对应计算机中的“数据”,让计算机来学习这些经验数据,生成一个算法模型,在面对新的情况中,计算机便能作出有效的判断,这便是机器学习。
另一本经典教材的作者Mitchell给出了一个形式化的定义,假设:
- P:计算机程序在某任务类T上的性能。
- T:计算机程序希望实现的任务类。
- E:表示经验,即历史的数据集。
若该计算机程序通过利用经验E在任务T上获得了性能P的改善,则称该程序对E进行了学习。
可能有很多同学想到高大上的人工智能、机器学习和深度学习,会在怀疑我是否能学会。在自我怀疑之前,我希望你能考虑一个问题,你了解机动车的构造原理吗?难道你不了解机动车的构造就不能开车了吗?我们的机器学习也是如此,你只要拿到一张“驾驶证”,你就能很好的应用它,并且能通过本文的学习,快速的为公司、为企业直接创造价值。
机器学习已经不知不觉的走入了我们的生活,我们可能无法干涉它的崛起,也可能无法创建如十大算法一样的算法。但现如今生活的方方面面都有着机器学习的身影,为什么我们不试着去认识它呢,让我们能在机器学习彻底降临之前做好驾驭它的准备呢?
一、学习目标
- 了解人工智能、机器学习和深度学习之间的区别
- 掌握机器学习中的监督学习和无监督学习问题
二、人工智能
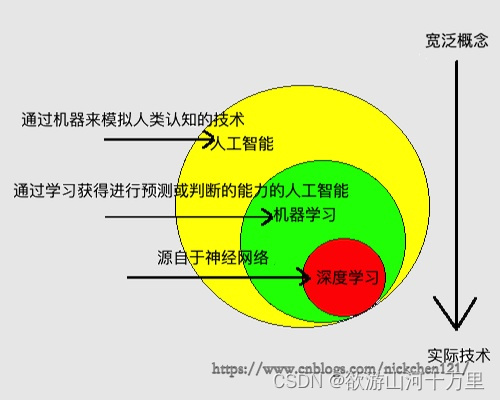
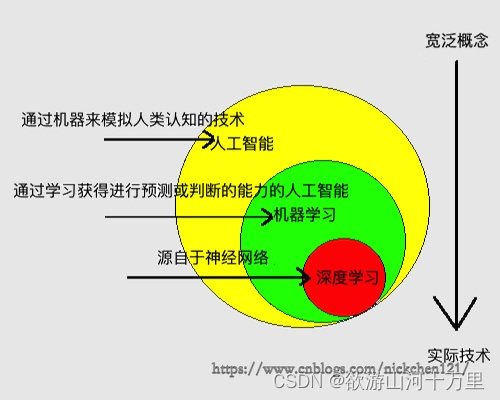
人工智能(artificial intelligence, AI):通过机器来模拟人类认知的技术。
人工智能被新闻媒体吹捧的让人遥不可及,但是细心的你可能会发现人工智能其实已经走入了我们的生活,并且已经步入以下几个领域。
- 人脸识别应用中,他根据输入的照片,判断照片中的人是谁
- 医疗诊断中,他根据输入的医疗影像,判断疾病的成因
- 语音识别中,他根据人说话的音频信号,判断说话的内容
- 电子商务网站中,他根据用户曾经的购买记录,预测用户感兴趣的商品,网站进而达到推荐商品的目的
- 自动驾驶应用中,他根据对当前汽车所处情况的分析,判断汽车接下来的速度和方向
- 金融应用中,他根据股票曾经的价格和其他交易信息,预测股票未来的价格走势
- 围棋对弈中,他根据当前的盘面形式,预测在哪个地方落子胜率最大(2016年3月的alphago大战李世石)
- 基因测序应用中,他根据对人的基因序列的分析,预测这个人未来患病的可能性
- 智能家居、智能玩具、网络安全……
最后,引用《终极算法》中的一段话:"我们可能无法阻挡人工智能发展的趋势,但是我们可以学会和他做朋友。"
三、机器学习
机器学习(machine learning):通过学习获得进行预测或判断的能力的人工智能。
机器学习是人工智能实现的一种方法(算法)。他主要是从已知数据中去学习数据中蕴含的规律或者判断规则,也可以理解成把无序的信息变得有序,然后他通过把这种规律应用到未来的新数据上,并对新数据做出判断或预测。
例如某个机器学习算法从全球70亿人类的数据集中学得了某种判断规则,这个判断规则可以通过输入Nick老师的身高180cm、体重70Kg,判断他是个帅哥。
3.1 机器学习基本术语
- # 机器学习基本术语图例
- import matplotlib.pyplot as plt
- from matplotlib.font_manager import FontProperties
- # 显示plt.show()的图片,如若不使用jupyter,请注释
- # 中文字体设置,找到与之对应的中文字体路径
- font = FontProperties(fname='C:\\windows\\fonts\\simsun.ttc')
- # 样本
- plt.text(1, 70, s='{身高(180),体重(70),年龄(19),五官(精致)',
- fontproperties=font, fontsize=13, color='g')
- plt.annotate(text='样本', xytext=(90, 70), xy=(78, 71), ha='center', arrowprops=dict(
- arrowstyle="<-", color='b'), fontproperties=font, fontsize=15, color='r')
- plt.annotate(text='特征', xytext=(30, 90), xy=(10, 73), ha='center', arrowprops=dict(
- arrowstyle="<-", color='b'), fontproperties=font, fontsize=15, color='r')
- plt.annotate(text='', xytext=(30, 90), xy=(30, 73), ha='center', arrowprops=dict(
- arrowstyle="<-", color='b'), fontproperties=font, fontsize=15, color='r')
- plt.annotate(text='', xytext=(30, 90), xy=(50, 73), ha='center', arrowprops=dict(
- arrowstyle="<-", color='b'), fontproperties=font, fontsize=15, color='r')
- plt.annotate(text='', xytext=(30, 90), xy=(70, 73), ha='center', arrowprops=dict(
- arrowstyle="<-", color='b'), fontproperties=font, fontsize=15, color='r')
- plt.hlines(67, 0, 100, linestyle='--', color='gray')
- # 特征
- plt.text(1, 40, s='{身高(180),体重(70),年龄(19),五官(精致),帅}',
- fontproperties=font, fontsize=10, color='g')
- plt.annotate(text='样例(实例)', xytext=(90, 40), xy=(70, 41), ha='center', arrowprops=dict(
- arrowstyle="<-", color='b'), fontproperties=font, fontsize=15, color='r')
- plt.annotate(text='特征', xytext=(30, 60), xy=(8, 43), ha='center', arrowprops=dict(
- arrowstyle="<-", color='b'), fontproperties=font, fontsize=15, color='r')
- plt.annotate(text='', xytext=(30, 60), xy=(23, 43), ha='center', arrowprops=dict(
- arrowstyle="<-", color='b'), fontproperties=font, fontsize=15, color='r')
- plt.annotate(text='', xytext=(30, 60), xy=(38, 43), ha='center', arrowprops=dict(
- arrowstyle="<-", color='b'), fontproperties=font, fontsize=15, color='r')
- plt.annotate(text='', xytext=(30, 60), xy=(53, 43), ha='center', arrowprops=dict(
- arrowstyle="<-", color='b'), fontproperties=font, fontsize=15, color='r')
- plt.annotate(text='标记', xytext=(67, 60), xy=(67, 43), ha='center', arrowprops=dict(
- arrowstyle="<-", color='b'), fontproperties=font, fontsize=15, color='r')
- plt.hlines(37, 0, 100, linestyle='--', color='gray')
- # 特征空间
- plt.text(1, 30,
- s='$\{(x_1^{(1)},x_1^{(2)},\cdots,x_1^{(n)}),(x_2^{(1)},x_2^{(2)},\cdots,x_2^{(n)}),\cdots,(x_m^{(1)},x_m^{(2)},\cdots,x_m^{(n)})\}$',
- fontproperties=font, fontsize=10, color='g')
- plt.annotate(text='特征空间($m$个样本)', xytext=(90, 15), xy=(92, 30), ha='center', arrowprops=dict(
- arrowstyle="<-", color='b'), fontproperties=font, fontsize=15, color='r')
- plt.annotate(text='特征向量($n$维特征)', xytext=(15, 15), xy=(15, 28), ha='center', arrowprops=dict(
- arrowstyle="<-", color='b'), fontproperties=font, fontsize=15, color='r')
- plt.xlim(0, 100)
- plt.ylim(10, 100)
- plt.title('机器学习基本术语图例', fontproperties=font, fontsize=20)
- plt.show()
通过上图,我们可以习得以下机器学习的基本术语:
- 特征(feature):描述一件事物的特性,如一个人的身高、体重、年龄和五官。
- 样本(sample):由一个人的特征组成的数据,如{180,70,19,精致}
- 标记(label):描述一件事物的特性,如一个人帅或丑、一个人的财富数量。注:特征和标记没有明确的划分,由于问题的不同可能导致A问题的特征是B问题的标记,B问题的标记是A问题的特征。
- 样例(example):由一个人的特征和标记组成的数据,如{180,70,19,精致,帅}
- 特征空间(feature space):由{x(1),x(2),⋯,x(n)}这n个特征张成的n维空间,如以身高张成的一维空间(线);以身高和体重张成的二维空间(面);以身高、体重和年龄张成的三维空间(体)。
- 特征向量(feature vector):特征空间内的某一个具体的向量,即特种空间中的某一个具体的点,{x(1)i,x(2)i,⋯,x(n)i},i∈R{xi(1),xi(2),⋯,xi(n)},i∈R
- 其中x(n)m表示第m个人的第n个特征。如身高、体重、年龄张成的三维空间中的某一个具体的点(180,70,19)
四、深度学习
深度学习(deep learning):通过组合低层属性特征形成更加抽象的高层属性特征。如学英语的时候,“Nick handsome”这12个英文单词是低层属性特征,而“Nick handsome”的语义则是抽象的高层属性特征。
深度学习的概念源于人工神经网络的研究,它属于机器学习中的某一个方法,其中深度学习中的“深度”是指神经网络的层数。

五、机器学习分类
机器学习依据数据集数据格式的不同,可以划分成监督学习和无监督学习;依据算法模式的不同可以划分为监督学习、无监督学习、半监督学习和强化学习。

5.1监督学习
监督学习(supervised learning):通过输入一组已知标记的样本,输出一个模型(model),然后通过这个模型预测未来新数据的预测值或预测类别。
监督学习的流程:
- 输入:一组已知类别的样本
- 输出:一个模型
- 预测未来新数据的预测值或预测类别
由于数据标记的类型不同,监督学习问题又分为回归问题和分类问题:
- 如果模型的输出为连续值,如股票价格2.2,2.4,2.6,3…类型的数据称为连续值,则该监督学习问题称作回归问题
- 如果模型的输出为离散值,如阿猫,阿狗,…阿猫,阿狗,…或{0,1}(输出不是0就是1),则该监督学习问题称作分类问题。
5.1.1 回归问题
- # 回归问题图例
- import numpy as np
- import matplotlib.pyplot as plt
- from matplotlib.font_manager import FontProperties
- font = FontProperties(fname='C:\\windows\\fonts\\simsun.ttc')
- x = np.linspace(0, 200, 10)
- y = 10*x
- plt.plot(x, y)
- plt.xlabel('房子面积', fontproperties=font, fontsize=15)
- plt.ylabel('房价', fontproperties=font, fontsize=15)
- plt.title('回归问题图例', fontproperties=font, fontsize=20)
- plt.show()
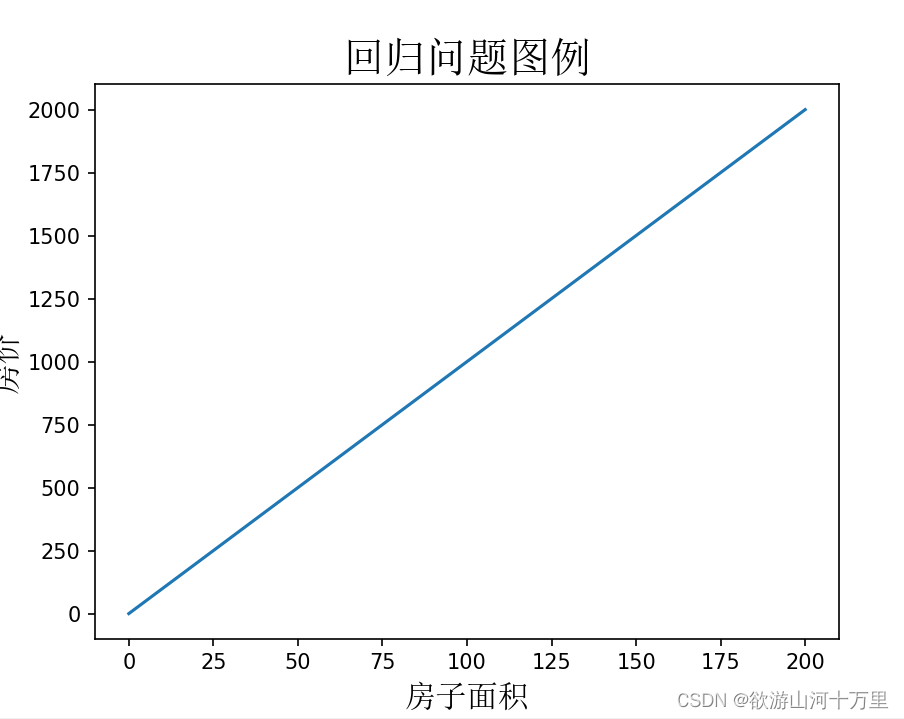
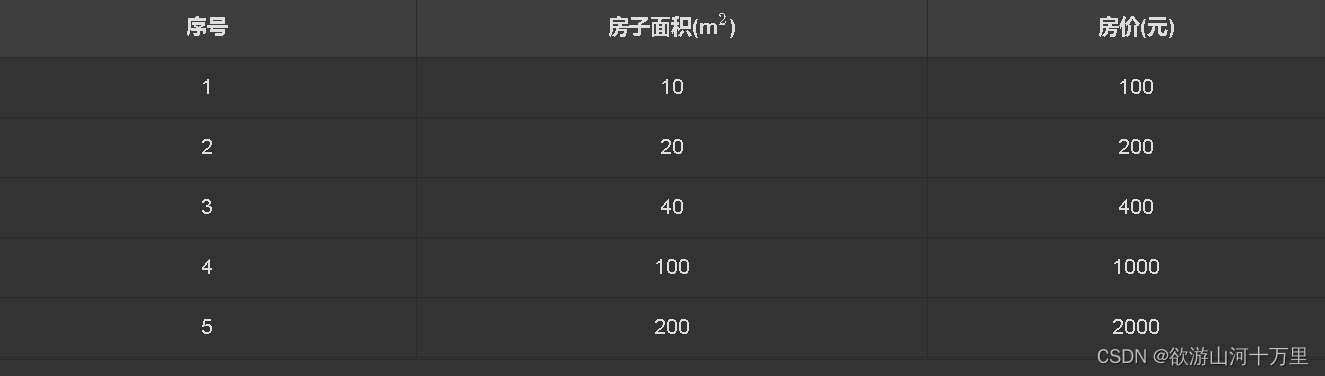
通过上表给出的数据集(一组已知标记的样本)举例,通过数据集中的数据,我们可以假设房子面积和房价之间存在某种关系(模型)为
房价=10∗房子面积房价=10∗房子面积
假设你在得到房子面积和房价之间的关系后,得到了上海二环某一所房子H1H1的面积为1000m21000m2的消息(未来新数据),这个时候你就可以通过H1H1的房子面积和房价之间的关系得到这所房子的价格为
H1的房价=10∗H1的房子面积=10∗1000=10000(元)预测值H1的房价=10∗H1的房子面积=10∗1000=10000(元)预测值
在这个回归问题中:
- 房子面积称为特征(feature)
- 房价称为标记(label)
5.1.2分类问题
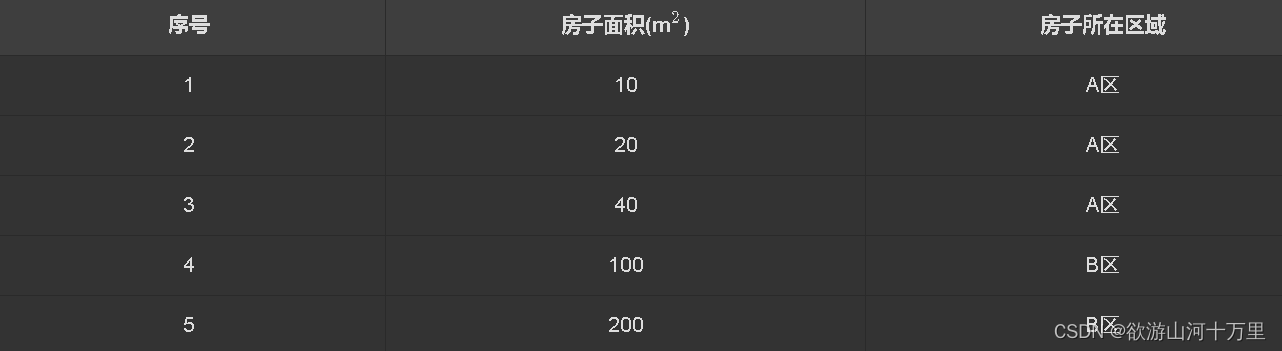
- # 分类问题图例
- import numpy as np
- import matplotlib.pyplot as plt
- from matplotlib.font_manager import FontProperties
- font = FontProperties(fname='C:\\windows\\fonts\\simsun.ttc')
- a_area = [10, 20, 40]
- a_y = [0, 0, 0]
- b_area = [100, 200]
- b_y = [0, 0]
- plt.scatter(a_area, a_y, label='A', color='r')
- plt.scatter(b_area, b_y, label='B', color='g')
- plt.vlines(50, ymin=-0.015, ymax=0.015, color='gray', linestyles='--')
- plt.xlabel('房子面积', fontproperties=font, fontsize=15)
- plt.title('分类问题图例', fontproperties=font, fontsize=20)
- plt.legend()
- plt.show()

在这个分类问题中:
- 房子面积称为特征
- 房子所在区域称为标记
5.2无监督学习
无监督学习(unsupervised learning):通过输入一组未知标记的样本,可以通过聚类(clustering)的方法,将数据分成多个簇(cluster)。
无监督学习的流程:
- 输入:一组未知类别的样本
- 输出:分成多个簇的一组样本
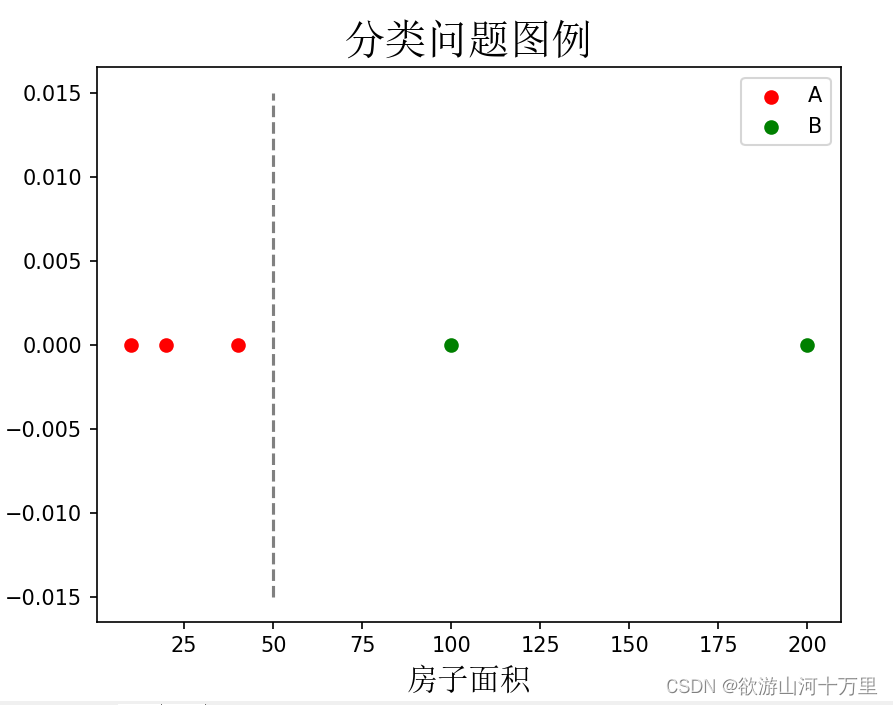
5.2.1 聚类
聚类(clustering):将数据集分成由类似的数据组成的多个类的过程被称为聚类。由聚类所生成的簇是一组数据的集合,同一个簇中的数据彼此相似,不同簇中的对象相异。
需要注意的是,组成多个簇的概念是由某种非人为定义的潜在概念自动生成的,而我们在监督学习中的分类都有明确的定义,即按照房子面积和房价的关系、房子面积和房子所在区域的关系。
通过上表给出的数据集举例,通过聚类可能把数据集中的5个数据分成两个簇,即房子面积大于50的分为一个簇,房子面积小于50的为另一个簇,而这种通过面积分类并不是我们事先设定的,而是由聚类算法自己实现的。也就是说通过聚类把上表的数据集分为两簇,但是我们需要在把数据集分成两个簇后再去决定用什么概念定义这两个簇的划分。
5.3 半监督学习
半监督学习(semi-supervised learning):监督学习与无监督学习相结合的一种学习方法。
监督学习和无监督学习的区别主要在于数据集中的数据是否具有标记,当某个问题中的数据集中的数据具有标记时,我们称之为监督学习;反之,我们称之为无监督学习。
目前,由于无监督学习算法的不稳定性,它一般作为中间算法,工业上使用较多的是监督学习算法。但是目前工业上累积较多的是不带标记的数据,因此无监督学习在未来将是一个技术突破的重点目标。为了处理这批不带标记的数据,也有科学家提出了半监督学习,它可以简单的理解为监督学习和无监督学习的综合运用,它即使用带有标记的数据也使用不带有标记的数据。
参考文献
写在最后
为了完成这一篇博文,我参考了如上很多个大佬的博文,我真心地觉得诸位大佬地水平高超,博文条例清晰,诸位可以直接通过链接阅读我所推荐地几位大佬地博文。
-
相关阅读:
氨基NH2/羧基COOH修饰/偶联/接枝NaY(Gd/Lu/Nd)F4:Yb,Tm核壳上转换纳米粒子
基于Java的二手车交易管理系统设计与实现(源码+lw+部署文档+讲解等)
下载JDK8 JVM源码
【接口加密】接口加密的未来发展与应用场景
dubbo复习: (5)和springboot集成时的标签路由
VS2019编译配置Cilantro库
紫光同创FPGA实现HSSTLP高速接口通信,8b/10b编解码数据回环,提供PDS工程源码和技术支持
代码随想录Day43 | 1049.最后一块石头的重量II | 494. 目标和 | 474. 一和零
19.Win10安装Linux(Ubuntu 20.04)双系统
如何使用libswscale库将YUV420P格式的图像序列转换为RGB24格式输出?
- 原文地址:https://blog.csdn.net/qq_41221411/article/details/127621544