-
超大规模云数据中心对存储的诉求有哪些?
超大规模的数据中心,核心在于实现大规模的分布式存储计算,具有高性能、高吞吐、高冗余、高可靠性的特性,一般情况下,规模超过5000台服务器,就可以算是超大规模集群了,通常应用在云计算场景。

因为要实现超大规模部署的特性,就对存储有别于普通数据中心或者消费市场的诉求。具体有哪些呢?主要有以下几点,我们针对部分信息展开讨论下:
-
超大规模且具备弹性
-
大容量、低成本
-
功耗、散热效率
-
热插拔可维护能力
-
峰值性能、单TB的性能优势以及稳定的QoS性能
-
安全性
-
向后兼容
-
完整的远程debug分析能力
第一点:M.2接口正在逐渐远离数据中心
在存储领域,M.2固态硬盘支持NVME/PCIe和SATA两类协议。PCIe SSD其实都是NVMe over PCIe;SATA SSD,则是AHCI over SATA.

在M.2接口细分两个规格,Socket2和Socket3。Socket 2支持SATA和PCIe X2接口SSD。Socket 3可以支持PCIe x4接口。虽然长得很像,但是大有乾坤,如下图左,是M.2 SATA接口SSD的模样,下图右则是M.2 PCIe 接口SSD的模样。

目前M.2根据尺寸的不同也可以分为大概4类,不过容量最大只支持8T容量。而且还不支持热插拔。

更多M.2接口尺寸如下图,供参考。

M.2接口的金手指接口,比较容易出现划伤,出现接触相关的链路异常。

M.2接口最大的功耗也有限制,不能超过8.25W。M.2目前在数据中心主要用于boot ssd,系统启动盘。CPU不断的迭代和性能提升,很多CPU目前已经去掉了链接SATA盘的接口,也导致M.2 SATA SSD作为启动盘就需要中间增加PCIe转SATA控制器,这就意味着成本的增加。此外,Boot盘的容量也在缓慢上升。
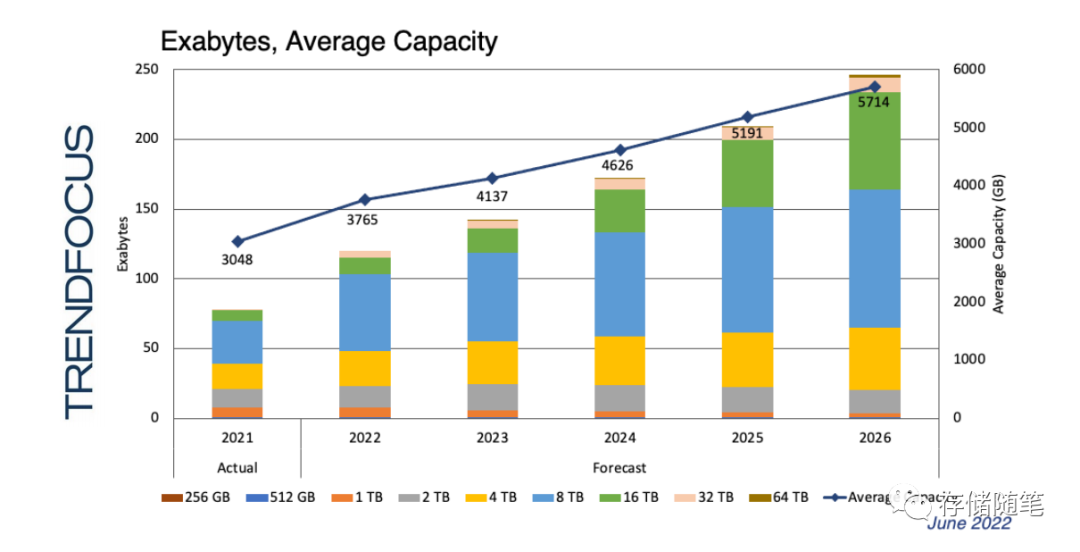
为解决M.2接口存在的热插拔、散热、过热以及容量扩展问题,业内目前找到的解决方案是采用E1.S接口。E1.S是一个小尺寸,比M.2长一点,但更宽,可以容纳更多的NAND Die,实现容量的叠加,具有更强的扩展性。最新版本的E1.S提供了一个新的可选对称外壳,宽度为9.5毫米 (类似于E1.L),可根据需要提供高达20w和x8 PCIe的可扩展性。主流ssd仍有望仅是PCIe x4,但尺寸上的PCIe x8支持允许使用其他需要更高带宽的设备。


根据TrendFocus机构的预测,在2026年,按照容量计算,E1.S接口的占比将会达到35.4%,M.2接口的占比会跌落到2.1%。按照Unit计算,E1.S接口的占比将会达到51.4%,M.2接口的占比从45.9%跌落到12%。

另外,针对NVME SSD作为boot盘,OCP也制定了相关的标准和策略,比如OCP的定义,“OCP Hyperscale NVMe Boot SSD Specification Goals”:
• Aligns NVMe Boot SSD needs and requirements between Hyperscale and SSD makers
• Share flash learnings based on Hyperscale deployments
• Provide everything needed to build a boot SSD for hyperscale deployments

第二点:性能峰值与QoS稳定性同样重要
在通常固态硬盘性能对比和评价体系中,一般会关注顺序读写的峰值性能带宽和随机读写的IOPS,在实际应用过程中,QoS也是至关重要的因素。比如下图实例,不同的业务场景通过VM实例进行访问,但是由于SSD内部启动GC/WL导致延迟升高,无法满足业务响应的SLA。此时QoS就会成为致命伤。

此外,Boot盘的IO特性显示,IO没有idle时间,一直在很小的压力下读写,同时trim命令非常频繁。虽然boot盘对性能要求不是很苛刻,但是这种IO异常也会导致上层应用出现异常。

为了提升QoS的稳定性,在应用端通常会考虑增加OP,降低写放大,采用multi-stream,ZNS等。
更多介绍,具体参考:SSD写放大的优化策略要统一标准了吗?
更重要的是,在固态硬盘设计过程中,需要考虑每个IO调度的影响。比如目前业内控制器厂商也在涉及基于类似AI机器学习的功能,更加智能化的管理SSD内部的算法。这里面就需要大量的经验和设计智慧了,不是每个厂商都能达到预期的效果。
第三点:远程debug定位分析能力提升核心竞争力
以NVME SSD为例,通常大家想到的是观察SMAR-log定位异常,但是这个信息在多数情况下无法支撑完整的定位链路。

定位能力的缺失和低效是数据中心问题解决最大的障碍。

为了解决这个问题,Meta的做法是推进OCP组织加入延迟记录页面。同时NVME协议也增加了Telemetry盘片的故障定位能力。

在故障IO定位过程中,利用IO全栈周期信息,快速定位IO异常发生的地址与故障根源。

Meta提供的故障跟踪方案是监控Kernel Stats,APP metrics,Workload特性,延迟日志、SMART日志信息等,通过异常信息的自动探测,进行监控、预警、修复等操作。整个过程实现全景监控分析。

结语
云数据中心对存储的诉求千奇百怪,各种场景,是一项复杂的工程,也是一件非常有趣的探索,欢迎大家一起交流讨论~
-
-
相关阅读:
什么是神经网络(Neural Network,NN)
Greenplum-表的存储模式
苹果AR设备未来展望:硬件舒适性、软件功能与网络速度等多维度期待
MyBatisPlus(1)
c++视觉图像线性混合
(Git)git clone报错——SSL certificate problem: self signed certificate
maven了解
MQ - 11 Kafka的架构设计与实现
【老生谈算法】matlab实现LU分解算法源码——LU算法
计算需要的MIPI lane数目
- 原文地址:https://blog.csdn.net/zhuzongpeng/article/details/127625529