-
2022-10-31-基于用户的协同过滤推荐算法实现+MAE+RMSE的求解+项目代码+运行结果图
推荐算法学习笔记
协同过滤推荐算法测评指标RMSE均方根误差
推荐系统笔记:
一、为什么需要推荐系统
为了解决互联网时代下的信息超载问题。
二、搜索引擎和推荐系统的区别
· 分类目录,是将著名网站分门别类,从而方便用户根据类别查找公司。
· 搜索引擎,用户通过输入关键字,查找自己需要的信息。
· 推荐系统,和搜索引擎一样,是一种帮助用户快速发展有用信息的工具。通过分析用户的历史行为,给用户的兴趣建模,从而主动给用户推荐能够满足他们兴趣和需求的信息。并且,推荐系统能够很好的发掘物品的长尾,挑战传统的2/8原则(80%的销售额来自20%的热门品牌)。
三、技术角度来看,搜索引擎和推荐系统的区别
1)搜索引擎,注重搜索结果之间的关系和排序;
2)推荐系统,需要研究用户的兴趣模型,利用社交网络的信息进行个性化的计算;
3)搜索引擎,由用户主导,需要输入关键词,自行选择结果。如果结果不满意,需要修改关键词,再次搜索;
4)推荐系统,由系统主导,根据用户的浏览顺序,引导用户发现自己感兴趣的信息;
四、推荐系统的定义
推荐系统通过发掘用户的行为,找到用户的个性化需求,从而将长尾物品准确推荐给需要它的用户,帮助用户找到他们感兴趣但很难发现的物品。
高质量的推荐系统会使用户对系统产生依赖,因此,推荐系统不仅能为用户提供个性化服务,还能与用户建立长期稳定的关系,提高用户忠诚度,防止用户流失。
五、推荐系统评测
一般推荐系统的参与方有3个:- 用户
- 物品提供商
- 推荐系统提供网站
因此,评测一个推荐系统时,需要考虑3方的利益,一个好的推荐系统是能够令三方共赢的系统。

六、三个实验方法的优缺点
1)离线实验
离线实验的方法的步骤如下:
a)通过日志系统获得用户行为数据,并按照一定格式生成一个标准的数据集;
b)将数据集按照一定的规则分成训练集和测试集;
c)在训练集上训练用户兴趣模型,在测试集上进行预测;
d)通过事先定义的离线指标,评测算法在测试集上的预测结果。
从以上步骤看出,离线实验的都是在数据集上完成的。意味着,它不需要一个实际的系统作为支撑,只需要有一个从日志中提取的数据集即可。
离线实验的优点是:
不需要有对实际系统的控制权;
不需要用户参与实践;
速度快,可以测试大量算法;
缺点是:
数据集的稀疏性限制了适用范围,例如一个数据集中没有包含某用户的历史行为,则无法评价对该用户的推荐结果;
评价结果的客观性,无法得到用户主观性的评价;
难以找到离线评价指标和在线真实反馈(如 点击率、转化率、点击深度、购买客单价、购买商 品类别等)之间的关联关系;
2)用户调查
用户调查需要一些真实的用户,让他们在需要测试的推荐系统上完成一些任务。在他们完成任务时,需要观察和记录用户的行为,并让他们回答一些问题。
最后,我们通过分析他们的行为和答案,了解测试系统的性能。
用户调查的优点是:
可以获得用户主观感受的指标,出错后容易弥补;
缺点是:
招募测试用户代价较大;
无法组织大规模的测试用户,统计意义不足;
3)在线实验
在完成离线实验和用户调查之后,可以将系统上线做AB测试,将它和旧算法进行比较。
在线实验最常用的评测算法是【A/B测试】,它通过一定的规则将用户随机分成几组,对不同组的用户采用不同的算法,然后通过统计不同组的评测指标,比较不同算法的好坏。
它的核心思想是:
a) 多个方案并行测试;
b) 每个方案只有一个变量不同;
c) 以某种规则优胜劣汰。其中第2点暗示了A/B 测试的应用范围:A/B测试必须是单变量。
对于推荐系统的评价中,唯一变量就是–推荐算法。
AB测试的优点是:
可以公平获得不同算法实际在线时的性能指标,包括商业上关注的指标;
缺点是:
周期较长,必须进行长期的实验才能得到可靠的结果;
大型网站做AB测试,可能会因为不同团队同时进行各种测试对结果造成干扰,所以切分流量是AB测试中的关键。
不同的层以及控制这些层的团队,需要从一个统一的地方获得自己AB测试的流量,而不同层之间的流量应该是正交的。
总结:一般来说,一个新的推荐算法最终上线,需要完成上述的3个实验。- 首先,通过离线实验证明它在很多离线指标上优于现有的算法;
- 其次,通过用户调查确定用户满意度不低于现有的算法;
- 最后,通过在线AB测试确定它在我们关心的指标上优于现有的算法;
关于均方根误差(RMSE):
RMSE是一个重要的预测评分的准确度指标,所谓预测评分的准确度衡量的是算法评测的评分与用户的实际评分之间的贴合度
RMSE越小表示误差越小,推荐系统的性能就越好

其中的平方根是RMSE加大了对预测不准的用户物品评分的惩罚(平方项的惩罚),因而对系统的评测更加苛刻。但是要注意研究表明,如果评分系统是基于整数建立的(即用户给的评分都是整数),那么对预测结果取整数会降低MAE的误差。
项目代码
一、实现原理和步骤
1、使用movielens数据集(943个用户,1682部电影,80000条评分数据);
2、构建用户-电影评分矩阵;
二维矩阵,横坐标为943的用户的id,纵坐标为1682部电影的id,其中在用户打过分 的电影的下方标出对应的分数。
3、数据统计分析,可以直观地打印出比如电影的评分分布情况,可以明显的看出打高分的 数量和打低分的数量。
4、输入用户id(1-943);
5、基于用户的协同过滤推荐算法;
1、根据用户历史行为信息构建用户-项目评分矩阵,用户历史行为信息包括项目评分、浏览历史、收藏历史、喜好标签等,本项目以单一的项目评分为例
2、根据用户-项目评分矩阵计算用户之间的相似度。计算相似度常用的方法有余弦算法、修正余弦算法、皮尔森算法等等,该项目为余弦算法。
3、根据用户之间的相似度得到目标用户的最近邻居KNN。KNN的筛选常用的有两种方式,一种是设置相似度阀值(给定一个相似度的下限,大于下限的相似度为最近邻居),一种是根据与目标用户相似度的高低来选择前N个最近邻居(本项目以前N个为例)。相似度排序可用经典冒泡排序法。
4、预测项目评分并进行推荐。
6、计算推荐算法测评指标rmse值。
7、冷启动推荐(扩展,暂未实现);
在该推荐系统中用所拥有的用户-电影-评分数据集进行训练测试所产生的一个推荐算法进行一个冷启动推荐,冷启动推荐的场景分别为刚注册的新用户在没有用户使用系统历史数据的情况下进行一个合适的推荐,和刚刚上线一个新电影的时候在没有用户观看记录数据的情况下将该电影推荐给可能对该电影感兴趣的用户。
二、代码实现
项目目录:
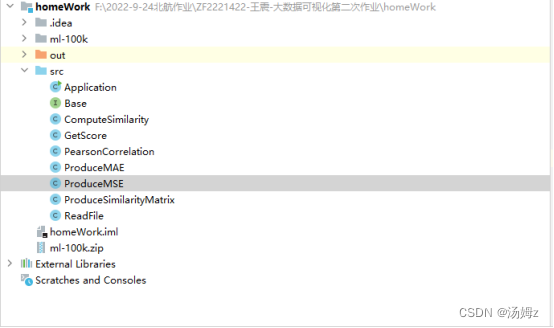
Application:算法主运行算法
Base:基础常量接口
ComputeSimilarity:比较两个用户相似度的类
GetScore:获取预测评分
PearsonCorrelation:余弦算法/皮尔森算法
ProduceSimilarityMatrix:得到用户相似度矩阵
ReadFile:读取movielens
u1.base:训练集
ui.test:测试集Application:
import java.util.Arrays; import java.util.HashMap; import java.util.Map; import java.util.Scanner; import java.util.Set; /** * 协同过滤推荐算法运行主方法 * @author line * */ public class Application implements Base { public static void main(String[] args) { // 输入userId,并获取 System.out.println("请输入一个用户Id(1、2、3……943)"); Scanner scanner = new Scanner(System.in); //获取得到输入的userId int userId = scanner.nextInt(); // 从文件中读取数据 int[][] user_movie_base = new int[PREFROWCOUNT][COLUMNCOUNT]; //读取文件中的数据 user_movie_base = new ReadFile().readFile(BASE); //产生相似度矩阵 double[] similarityMatrix = new ProduceSimilarityMatrix().produceSimilarityMatrix(user_movie_base, userId); // 知道每个用户之间的相似度值之后,开始获取每隔相似值对应的userId,然后和相似值关联,再根据相似值排序,即得到相似爱好的userId,然后再输出相似推荐的商品 int[] id = new int[KNEIGHBOUR];//存放K个最近邻userId //产生一个临时相似度矩阵变量,是为了相似度排序时和userid对应 double[] tempSimilarity = new double[similarityMatrix.length]; for (int j = 0; j < tempSimilarity.length; j++) { tempSimilarity[j] = similarityMatrix[j]; } Arrays.sort(tempSimilarity);//排序,升序 int flag = 0;//临时变量 double[] similarity = new double[KNEIGHBOUR];//保存前K个相似度,从大到小 for (int m = tempSimilarity.length - 1; m >= tempSimilarity.length - KNEIGHBOUR; m--) { for(int j = 0; j < similarityMatrix.length; j++) { if (similarityMatrix[j] == tempSimilarity[m] && similarityMatrix[j] != 0.0){ similarity[flag] = tempSimilarity[m]; id[flag]=j;//保存前K个相似度的userid flag++; } } } System.out.println("相似度最近的" + KNEIGHBOUR + "个用户是:"); System.out.print("近邻用户"); System.out.printf("%25s","相似度");//格式化输出"%25s"是占多少位 System.out.printf("%30s\n","推荐产品"); Map<Integer, Double> map = new HashMap<Integer, Double>();//存放每件商品的id和期望值,是键值对关系,即一对一 for (int i = 0; i < KNEIGHBOUR; i++) {//按照k值得大小来循环 // 前k个近邻用户的推荐产品 int user_id = id[i];//数组id中的userid根据相似度大小顺序已经排好,从大到小 int[] items = user_movie_base[user_id];// 获取源数据K个邻近用户userid的所有评分 String str = ""; for (int j = 0; j < COLUMNCOUNT; j++) {//循环每件商品,如果相邻用户对某件商品的评分不为0,而目标用户的评分为0,该商品就为推荐商品 if ((items[j] != 0) && (user_movie_base[userId - 1][j] == 0)){ str += " " + (j + 1);//将推荐商品的id保存在一个字符串中,可以直接输出 //此时,可以通过循环计算某一件推荐商品的评分用户的相似度期望 //开始计算期望,将相同商品的相似度相加,并保存在map集合中 if(map.containsKey(j + 1)){//如果一件商品的值,已经保存在map集合的键中(键是唯一的,即不会和其他的数值一样),那么键对应的值,就会改变,加上该商品不用用户的相似度 double d = map.get(j+1); d+=similarity[i]; map.put(j+1,d);//修改map中的值 }else{ map.put(j+1, similarity[i]);//如果没有保存一件商品的id,那么开始保存 } } } System.out.print(id[i] + 1); System.out.printf("%16s\t" ,String.format("%.2f",similarity[i]*100)+"%");//输出的同时格式化数据 System.out.println(str);//输出每个用户的推荐商品 } //选择最好的推荐商品,期望加权 //循环map集合的键 Map<Integer,Double> map2 = new HashMap<Integer, Double>(); //保存商品id和加权期望,因为还要对加权期望排序,要和商品id对应 double s1 = 0; double s2 = 0; Set<Integer> set = map.keySet();//获取map集合中的所有键,输出是一个set集合 for(int key : set){//循环map中的所有键 for (int i = 0; i < KNEIGHBOUR; i++) { int score = user_movie_base[id[i]][key-1];//map中的键是商品id,i是userid,获取评分 s1+=score*map.get(key); s2+=score; } map2.put(key, s1/s2);//保存加权期望值,和商品id对应 } Object[] arr = map2.values().toArray();//获取map2中所有的值,也就是每件商品的加权期望 Arrays.sort(arr);//升序排列,调用系统数据包中的函数,自动排列数组 set = map2.keySet();//获取商品id int max=0;//最佳推荐项目id for(int key : set){//循环商品id,根据最大的加权期望,找到商品id if(map2.get(key)==arr[arr.length-1]){ max = key; break; } } System.out.println("最值得推荐的商品是:"+max); // 误差率 int[][] test = new ReadFile().readFile(TEST); // 462个用户的实际评分 double[][] similarityMatrix2 = new ProduceSimilarityMatrix().produceSimilarityMatrix(user_movie_base);//获取任意两行之间的相似度矩阵 double[][] matrix = new GetScore().getScore(user_movie_base,similarityMatrix2); double[] mae = new ProduceMAE().produceMAE(matrix, test); double Mae = 0.0, MAE = 0.0;//平均绝对误差,通过两大组数据的相似度矩阵对比而来 for (int k = 0; k < mae.length; k++) { Mae += mae[k]; } MAE = Mae / TESTROWCOUNT; System.out.println("MAE=:" + MAE); double RMSE=new ProduceMSE().produceMSE(matrix,test); System.out.println("MSE=:" + RMSE); } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
Base
/** * 基础静态文件数据 * @author line * */ public interface Base { public static final int KNEIGHBOUR = 10; //number of neighbors最近邻个数 public static final int COLUMNCOUNT = 1682; //number of items 项目总数 public static final int PREFROWCOUNT = 943; //number of users in base训练集上的用户数目 public static final int TESTROWCOUNT = 462; //number of users in test测试集上的用户数目 public static final String BASE = "./ml-100k/u1.base";//训练集 public static final int BASE_LINE = 80000;//base数据集的行数 public static final String TEST = "./ml-100k/u1.test";//测试集 public static final int TEST_LINE = 20000;//test数据集的行数 public static final String BASE_GENRE = "./ml-100k/u.user";//用户属性集 public static final String BASE_ITEMS_GENRE = "./ml-100k/u.item";//用户属性集 public static final int ITEMS_GENRE_LINE = 19;//test数据集的行数 }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
ComputeSimilarity
import java.util.ArrayList; import java.util.List; /** * 从两行数据中,获取需要对比的要求数据 * @author line * */ public class ComputeSimilarity { public double computeSimilarity(int[] item1,int[] item2) { List<Integer> list1 = new ArrayList<Integer>();//因为不知道两行userid的评分是否有效即都不为0,所以定义集合来储存不知道的有效评分 List<Integer> list2 = new ArrayList<Integer>(); for (int i = 0; i < item1.length; i++) { if(item1[i] != 0 || item2[i] !=0) {//如果相同列上有0就舍去 list1.add(new Integer(item1[i]));//因为合格数据个数不确定,所以用集合表示 list2.add(new Integer(item2[i])); } } return new PearsonCorrelation().pearsonCorrelation(list1,list2);//返回相似度值 } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
GetScore
import java.util.ArrayList; import java.util.Arrays; import java.util.HashMap; import java.util.List; import java.util.Map; import java.util.Set; public class GetScore implements Base { //方法参数,一个是源数据,一个是通过源数据得到的相似度矩阵 //得到预测评分矩阵,先循环行userid,得到每一个userid的K个近邻用户和相似度,再得到目标用户的预测项目 public double[][] getScore(int[][] user_movie_base,double[][] combineMatrix ){ double[][] matrix = new double[PREFROWCOUNT][COLUMNCOUNT];//保存每个用户对评分为0的项目的预测值 //循环userid for (int i = 0; i < PREFROWCOUNT; i++) {//KNEIGHBOUR //得到每一个userid的K个邻近相似度极其userid int[] id = new int[KNEIGHBOUR];//存放K个最近邻userId double[] tempSimilarity = new double[combineMatrix[i].length];//产生一个临时相似度矩阵变量,是为了相似度排序时和userid对应 for (int j = 0; j < tempSimilarity.length; j++) { tempSimilarity[j] = combineMatrix[i][j]; } //Arrays.sort(tempSimilarity);//排序,升序 //int flag = 0;//临时变量 double[] similarity = new double[KNEIGHBOUR];//保存前K个相似度,从大到小 // for (int m = tempSimilarity.length - 1; m >= tempSimilarity.length - KNEIGHBOUR; m--) { // for(int j = 0; j < combineMatrix[i].length; j++) { // if (combineMatrix[i][j] == tempSimilarity[m] && combineMatrix[i][j] != 0.0){ // similarity[flag] = tempSimilarity[m]; // id[flag]=j;//保存前K个相似度的userid // flag++; // } // } // } int[] ids = new int[PREFROWCOUNT];//存放K个邻近项目id for (int h = 0; h < PREFROWCOUNT; h++) { ids[h] = h; } for (int h = 0; h < tempSimilarity.length; h++) { for (int j = 0; j < tempSimilarity.length - 1 - h; j++) { if (tempSimilarity[j] < tempSimilarity[j + 1]) { //如果后一个数小于前一个数交换 double tmp = tempSimilarity[j]; tempSimilarity[j] = tempSimilarity[j + 1]; tempSimilarity[j + 1] = tmp; int temp = ids[j]; ids[j] = ids[j + 1]; ids[j + 1] = temp; } } } for (int h = 0; h < KNEIGHBOUR; h++) { similarity[h] = tempSimilarity[h]; } for (int h = 0; h < KNEIGHBOUR; h++) { id[h] = ids[h]; } //以上代码已经得到一个目标用户的K个相似度userid和相似度结束,并且已经排好顺序,分别是:数组id,和数组similarity //开始计算一个目标用户的推荐产品的预测评分,方法,K个邻近用户的相同商品的加权平均数 Map<Integer, Double> map = new HashMap<Integer, Double>();//存放每件商品的id和商品评分*相似度 Map<Integer, Double> map2 = new HashMap<Integer, Double>();//存放每件商品的id和相似度之和 for (int k = 0; k < KNEIGHBOUR; k++) {//按照k值得大小来循环 // 前k个近邻用户的推荐产品 int user_id = id[k];//数组id中的userid根据相似度大小顺序已经排好,从大到小 int[] items = user_movie_base[user_id];// 获取源数据K个邻近用户userid的所有评分 for (int j = 0; j < COLUMNCOUNT; j++) {//循环每件商品,如果相邻用户对某件商品的评分不为0,而目标用户的评分为0,该商品就为推荐商品 if ((items[j] != 0) && (user_movie_base[i][j] == 0)) { if (map.containsKey(j)) {//如果一件商品的值,已经保存在map集合的键中(键是唯一的,即不会和其他的数值一样),那么键对应的值,就会改变,加上该商品不用用户的相似度 double d = map.get(j); d += similarity[k] * items[j]; map.put(j, d);//修改map中的值 double dd = map2.get(j); dd += similarity[k]; map2.put(j, dd); } else { map.put(j, similarity[k] * items[j]);//如果没有保存一件商品的id,那么开始保存 map2.put(j, similarity[k]); } } } } Set<Integer> set = map.keySet();//循环所有推荐商品 for (Integer key : set) { matrix[i][key] = map.get(key) / map2.get(key); } } return matrix; } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
PearsonCorrelation
import java.util.List; /** * 余弦算法计算相似度 * * @author line */ public class PearsonCorrelation implements Base { // 通过余弦求相邻值,对比两行数据,方法有很多,列举的是余弦方法,也可用皮尔森方法 public double pearsonCorrelation(List<Integer> a, List<Integer> b) {// 返回某两行的相似度值 double sum1 = 0; double sum2 = 0; Object[] a2 = a.toArray(); Object[] b2 = b.toArray(); int aimcha; int usercha; double wei = 0; for (int j = 0; j < a.size(); j++) { aimcha = (Integer) a2[j]; usercha = (Integer) b2[j]; sum1 += aimcha * aimcha; sum2 += usercha * usercha; } for (int i = 0; i < a.size(); i++) { double light = 0; double right = 0; aimcha = (Integer) a2[i]; usercha = (Integer) b2[i]; light = aimcha / Math.sqrt(sum1); right = usercha / Math.sqrt(sum2); wei += light * right; } return wei;//相似度值 } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
ProduceMAE
/** * 计算MSE平均绝对误差 * @author line * */ public class ProduceMAE implements Base{ //求误差 public double[] produceMAE(double[][] m,int[][]test){ double mae= 0.0; double []mm=new double[TESTROWCOUNT ]; for(int i=0;i<TESTROWCOUNT ;i++ ) { double sum_fencha= 0.0; int num=0; for(int j=0;j<PREFROWCOUNT;j++){ if(test[i][j]!=0&& m[i][j]!=0){ sum_fencha+=Math.abs(m[i][j]-(double)test[i][j]);//相差取绝对值 num++; } }if (num==0) mae=0;else mae= sum_fencha/num; mm[i]=mae; } return mm; } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
ProduceMSE
import static java.lang.Math.sqrt; /** * 计算MSE平均绝对误差 * @author line * */ public class ProduceMSE implements Base{ //求误差 //该函数用于计算均方根误差,m为预测数据,test为真实数据 // RMSE : 浮点型 // 均方根误差. public double produceMSE(double[][] m,int[][]test){ //定义一个变量用于存储所有样本的平方误差之和 double the_sum_of_error = 0; double []mm=new double[TESTROWCOUNT ]; for(int i=0;i<TESTROWCOUNT ;i++ ) { for(int j=0;j<test[i].length;j++){ the_sum_of_error += ((double) test[i][j]-m[i][j])*((double) test[i][j]-m[i][j]); } } double RMSE = sqrt(the_sum_of_error/TESTROWCOUNT); return RMSE; } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
ProduceSimilarityMatrix
/** * 产生相似矩阵,通过一个userId找其最近邻userId喜欢的产品,则相似度矩阵为一行n列矩阵, * 若是全部比较一个矩阵所有userId的相关度产生一个n行n列矩阵 * @author line * */ public class ProduceSimilarityMatrix implements Base{ //在计算MAE会用到 public double[][] produceSimilarityMatrix(int[][] preference) { double[][] similarityMatrix = new double[PREFROWCOUNT][PREFROWCOUNT];//行和列都是所有的用户,因为是每一行和每一行相比,所以得到的相似矩阵为正方形 for (int i = 0; i < PREFROWCOUNT; i++) { for (int j = 0; j < PREFROWCOUNT; j++) { if (i == j) { continue; } //数据是两行之间对比,其实只需要填满相似度矩阵的左下方或者右上方即可(减少重复运算) similarityMatrix[i][j] = new ComputeSimilarity().computeSimilarity(preference[i], preference[j]);//参数是从第一行开始,和其他每一行比较相似度 } } return similarityMatrix;//返回相似度矩阵 } //计算某个userId的相似度矩阵,用户之间的相似度是每个用户的每件商品评分的相似度,也就是说相似度矩阵是行是用户列也是用户,是正方形矩阵,对角线上的值都为1 //参数i是输入的userid public double[] produceSimilarityMatrix(int[][] preference,int i) { double[] similarityMatrix = new double[PREFROWCOUNT];//定义一个相似度矩阵,行和列都是所有的用户,因为是每一行和每一行相比,所以得到的相似矩阵为正方形 for (int j = 0; j < PREFROWCOUNT; j++) {//循环和其他userId对比其所有商品 if(j==(i-1)){//不比较同行,i-1是因为数组索引比userid小1 continue;//跳出循环,继续下一次循环 } similarityMatrix[j] = new ComputeSimilarity().computeSimilarity(preference[i-1], preference[j]);//参数是从第一行开始,和其他每一行比较相似度 } return similarityMatrix;//返回相似度矩阵,只有在userid-1行有数据,其他行列数据都为0,因为只是userid-1行和其他行对比 } //根据性别属性,产生用户性别属性相似度 public double[] produceSimilarityMatrixGener(int[] preference,int userId) { double[] similarityMatrix = new double[PREFROWCOUNT];//定义一个相似度矩阵,行和列都是所有的用户,因为是每一行和每一行相比,所以得到的相似矩阵为正方形 for (int j = 0; j < PREFROWCOUNT; j++) {//循环和其他userId对比其所有商品 if(j==(userId-1)){//不比较同行,i-1是因为数组索引比userid小1 continue;//跳出循环,继续下一次循环 } if(preference[j]==preference[userId-1]) similarityMatrix[j] = 1; else similarityMatrix[j] = 0; } return similarityMatrix;//返回相似度矩阵,只有在userid-1行有数据,其他行列数据都为0,因为只是userid-1行和其他行对比 } //基于项目 public double[] produceSimilarityMatrixItems(int[][] preference,int i) { double[] similarityMatrix = new double[COLUMNCOUNT]; for (int j = 0; j < COLUMNCOUNT; j++) { if(j==(i-1)){//不比较同行 continue;//跳出循环,继续下一次循环 } similarityMatrix[j] = new ComputeSimilarity().computeSimilarity(preference[i-1], preference[j]);//参数是从第一行开始,和其他每一行比较相似度 } return similarityMatrix;//返回相似度矩阵,只有在userid-1行有数据,其他行列数据都为0,因为只是userid-1行和其他行对比 } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
ReadFile
import java.io.BufferedReader; import java.io.File; import java.io.FileReader; /** * 读取数据集中的数据 * @author line * */ public class ReadFile implements Base { //从文件中读取数据,以“ ”划分 public int[][] readFile( String fileName) { int[][] user_movie = new int[PREFROWCOUNT][COLUMNCOUNT];//存放数据 try { File file = new File(fileName); FileReader fr = new FileReader(file); BufferedReader br = new BufferedReader(fr); String line = ""; while (br.ready()) { line = br.readLine();//按行获取数据 String[] data = line.split("\t");//以“TAB”符来分割每行的四个数据数据获取userid,score,product int[] ddd = new int[4]; for (int j = 0; j < data.length; j++) { ddd[j] = Integer.parseInt(data[j]); } user_movie[ddd[0] - 1][ddd[1] - 1] = ddd[2];//因为数组的索引是从0开始,而商品和用户id是从1开始,故减去1 } } catch (Exception ex) { ex.printStackTrace();//如果方法出现错误,会被抓住,在控制台输出错误原因 } return user_movie; } //从文件中读取数据,以“|”划分 public int[] readFileGener(String fileName) { int[] user_genre_base = new int[PREFROWCOUNT];//存放数据 try { File file = new File(fileName); FileReader fr = new FileReader(file); BufferedReader br = new BufferedReader(fr); String line = ""; int i=0; while (br.ready()) { line = br.readLine();//按行获取数据 String[] data = line.split("\\|"); if(data[2].equals("M")){//男性设为1 user_genre_base[i]= 1; }else user_genre_base[i]= 0;//女性 i++; } } catch (Exception ex) { ex.printStackTrace();//如果方法出现错误,会被抓住,在控制台输出错误原因 } return user_genre_base; } //获取items-user矩阵 public int[][] readFileItems( String fileName) { int[][] items_movie = new int[COLUMNCOUNT][PREFROWCOUNT];//存放数据 try { File file = new File(fileName); FileReader fr = new FileReader(file); BufferedReader br = new BufferedReader(fr); String line = ""; while (br.ready()) {//矩阵中循环列 line = br.readLine(); String[] data = line.split("\t"); int itemsId = Integer.parseInt(data[1]); int userId = Integer.parseInt(data[0]); items_movie[itemsId-1][userId-1] = Integer.parseInt(data[2]); } } catch (Exception ex) { ex.printStackTrace();//如果方法出现错误,会被抓住,在控制台输出错误原因 } return items_movie; } //获取items-gener矩阵 public int[][] readFileItemsGener( String fileName) { int[][] items_movie = new int[COLUMNCOUNT][ITEMS_GENRE_LINE];//存放数据 try { File file = new File(fileName); FileReader fr = new FileReader(file); BufferedReader br = new BufferedReader(fr); String line = ""; while (br.ready()) {//矩阵中循环列 line = br.readLine(); String[] data = line.split("\\|"); int itemsId = Integer.parseInt(data[0]); int j = 0; for (int i = data.length-ITEMS_GENRE_LINE; i < data.length; i++) { items_movie[itemsId-1][j] =Integer.parseInt(data[i]); j++; } } } catch (Exception ex) { ex.printStackTrace();//如果方法出现错误,会被抓住,在控制台输出错误原因 } return items_movie; } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
运行结果图
RMSE计算过程示意图
运行结果示意图

数据集

MovieLens数据集MovieLens数据集包含多个用户对多部电影的评级数据,也包括电影元数据信息和用户属性信息。
下载地址
http://files.grouplens.org/datasets/movielens/
介绍下面以ml-100k数据集为例进行介绍:
最主要用的是u.data(评分) | u.item(电影信息) | u.user(用户信息)
下载之后各文件具体含义如下:
各文件含义如下:allbut.pl --生成训练和测试集的脚本,其中除了n个用户评分之外,所有训练和测试集都在训练数据中。 mku.sh --从u.data数据集生成的所有用户的shell脚本。 u.data – 由943个用户对1682个电影的10000条评分组成。每个用户至少评分20部电影。用户和电影从1号开始连续编号。数据是随机排序的。 标签分隔列表:user id | item id | rating | timestamp u.genre --类型列表。 u.info --u.data数据集中的用户数,电影数和评分数。 u.item --电影信息。 标签分隔列表:movie id | movie title | release date | video release date | IMDb URL | unknown | Action | Adventure | Animation | Children’s | Comedy | Crime | Documentary | Drama | Fantasy | Film-Noir | Horror | Musical | Mystery | Romance | Sci-Fi | Thriller | War | Western 最后19个字段是流派,1表示电影是该类型,0表示不是;电影可以同时使用几种流派。 电影id和u.data数据集中的id是一致的。 u.occupation --职业列表。 u.user --用户的人口统计信息。 标签分隔列表:user id | age | gender | occupation | zip code 用户id和u.data数据集中的id是一致的。 u1.base --数据集u1.base / u1.test到u5.base / u5.test都是将u.data数据集按照80% / 20%的比例分割的训练集和测试集。 u1.test u1,…,u5有互不相交的测试集;如果是5次交叉验证,那么你可以在每个训练和测试集中重复实验,平均结果。 u2.base 这些数据集可以通过mku.sh从u.data生成 u2.test u3.base u3.test u4.base u4.test u5.base u5.test ua.base --数据集ua.base, ua.test, ub.base, ub.test将u.data数据集分为训练集和测试集,每个用户在测试集中具有10个评分。 ua.test ua.test和ub.test是不相交的。这些数据集可以通过mku.sh从u.data生成- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
-
相关阅读:
git只提交部分修改的文件(提交指定文件)
js的宏任务与微任务
redis的原理和源码-慢查询日志&监视器
X书6.97版本shield-unidbg调用方式
最长情的告白就是陪伴【Python七夕祝福】——那些浪漫的开始
Springboot服装服装销售管理系统毕业设计-附源码221801
电脑清理c盘怎么清理全教程,教你彻底清理所有垃圾
Springboot+高校教材预订信息管理系统 毕业设计-附源码150905
Unity之NetCode多人网络游戏联机对战教程(6)--NetworkTransform组件
0基础学习PyFlink——使用Table API实现SQL功能
- 原文地址:https://blog.csdn.net/nalidour/article/details/127624390