-
Learning Tone Curves for Local Image Enhancement
ABSTRACT
图像增强方法可以被描述为全局变换、局部变换、像素处理或这些操作的混合。 全局变换在增强局部图像区域方面是有限的。 现有的局部和像素方法缓解了这一问题,但也带来了额外的挑战,即有限的可解释性。 为了弥补全局和局部方法之间的差距,我们提出了一个局部色调映射网络(LTMNET),它学习一个灰度曲线网格来局部增强图像。 色调曲线通常被照片编辑软件使用,并为摄影师提供直观的表示,便于随后的图像定制。 色调曲线也广泛应用于图像信号处理器中,使得我们的方法易于在摄像机上部署。 由于现有的数据集包含全局和局部色调映射之外的图像增强和照相处理,我们还提出了一种新的代表局部色调映射的数据集LTM数据集。 我们在这个新的数据集以及MIT-Adobe和HDR+数据集上评估了我们的方法。 我们表明,所提出的LTMNET在局部色调映射方面优于现有的方法,同时实现了竞争性的性能建模和额外的照相处理。 此外,我们还表明,我们的方法可以辅助用户交互式照片编辑工具。 我们的代码、模型和数据将在https://github.com/samsunglabs/ltmnet上公开发布。
I. INTRODUCTION
照相机以照片的形式捕捉我们日常生活中有价值的时刻。 大多数相机都使用专用的图像信号处理器将捕获的传感器图像处理成最终的输出图像。 ISP以流水线方式应用几个步骤来处理图像。 其中一个关键操作是色调映射。 色调映射是ISPs图像增强阶段必不可少的一个步骤,它通过增强图像的对比度和色调对最终图像的质量有重要影响。
色调映射将输入像素强度转换为新的输出强度。 通常,相同或不同的色调映射被应用于彩色图像的R、G和B通道。 使用查找表(LUT)在硬件中执行此操作是有效的。 色调映射通常被称为其他名称:例如,色调曲线,传递函数,和一维LUT。 色调映射被广泛地用于动态范围压缩(例如,[3]、[4]、[5]),将高动态范围(HDR)图像减小到较低动态范围(LDR),同时保持美观的外观。 然而,在本文中,我们将重点放在相同动态范围内的转换上,而不是HDR到LDR。 色调映射有两种应用方式,全局和局部。 全局色调映射(GTM)将每个像素值映射到另一个值,而与像素位置无关。 对于一个典型的现实世界的ISP来说,GTM本身很少足以充分增强一个映像。 特别是,GTM缺乏灵活性,并产生了增强过度/不足的局部区域,如图所示 1-(b)。 另一方面,局部色调映射(LTM)根据局部特征,利用不同的色调曲线对图像区域进行空间调整。 LTM提供了更细粒度的控制,有助于突出亮点。 如图所示 1-(d),我们的LTM方法提供针对局部区域的转换--例如,增加密集内容区域(灌木丛)的可见性,以及增加阴影区域的对比度,以提供更有活力的图像效果。
许多现有的方法要么只执行GTM(例如,[1],[6]),要么执行像素级增强(例如,[2],[7]),其输出增强图像而不是传递函数。 很少有工作集中在显式学习局部色调曲线上,它可以作为一维LUT有效地集成到现有的ISP中,使其比像素处理更方便,比GTM更强大。
Contribution
我们提出了一种基于深度学习的局部图像增强方法,该方法估计局部色调曲线。 与现有的方法不同,我们的方法是训练输出局部色调曲线网格,而不是像素级处理。 色调曲线对后处理、编辑和硬件实现更加直观。 由于色调曲线可以应用于任何尺寸的图像,我们的方法不局限于特定的分辨率。 我们还提出了一种新的表示局部色调映射的图像数据集,由色调映射和非色调映射图像对组成。 此外,我们提供了一个交互式LTM操作工具,可以用来手动微调由我们的方法自动预测的色调曲线。
II. RELATED WORK
在图像增强方面有大量的工作; 这里只呈现有代表性的作品。 根据它们对图像的处理方式,我们将这些方法分为三类:(1)将全局传递函数或LUTS应用于整个图像的方法; (2)对图像局部区域进行局部增强的方法; (3)应用从输入到增强图像的像素级映射的方法。 有些方法可以将全局处理、局部处理和像素处理中的两种或多种结合起来。
A. GLOBAL ENHANCEMENT
传统的图像增强方法应用预定义的全局传递函数,如伽马校正,或从强度分布估计的传递函数,如直方图均衡化[8]及其扩展:对比度限制直方图均衡化(CLHE)[9]和直方图修改框架(HMF)[10]。
最近的方法使用神经网络来预测全局转换。 例如,[11]中的方法提出了一个神经网络来实现CLHE和HMF。 Splinet[12]使用学习的全局色调曲线执行个性化增强。 文[6]中的方法学习一个3D查找表来实现快速和鲁棒的增强。 White Box[13]基于生成对抗网络引导的深度强化学习(RL)从预先定义的集合中选择全局增强操作的最佳序列。 扭曲-恢复[14]也使用RL来显式地模拟人类润色过程的步骤性质。 类似地,[15]使用RL和未配对的图像。
正如在引言中所提到的,全局变换可能会低估或过度增强局部图像内容,从而导致对局部增强方法的需求。
B. LOCAL ENHANCEMENT
许多方法将直方图均衡技术扩展为局部自适应[16]-[19]。 一个突出的例子是自适应直方图均衡化(AHE)[20],[21],其涉及均衡从局部图像区域计算的一组直方图,典型地是斑块网格。 另一个扩展是对比度限制AHE(CLAHE)[9],其中对比度放大通过裁剪计算的直方图来限制。 CLAHE是许多相机ISP采用的行业标准,通常用作局部色调映射操作符; 但是,它需要仔细的参数调优。
有些方法执行颜色变换来进行局部图像增强。 基于调色板的方法[22],[23]基于调色板中的稀疏颜色集来插值颜色。 但是,更新调色板需要用户交互或示例图像。 代表颜色变换(RCT)[24]学习和变换图像中的一组代表颜色,全局和局部。 hdrnet[25]从下采样图像学习由3×4仿射变换矩阵组成的双边网格[26]。 每个矩阵将输入颜色映射到输出颜色。 这些仿射系数然后通过双边引导上采样应用于全分辨率输入图像[27]。 HDRNET在建模复杂的转换方面很有表现力。 然而,这些矩阵很难可视化和解释。 相比之下,我们的方法学习一个网格的一维曲线,这是直观的摄影师,易于解释和编辑。 StarEnhancer[28]还学习一组基于亮度值和像素位置变换图像的曲线。 曲线可以手动微调,但很难精确地调整到特定的空间坐标。 相比之下,我们的方法显式地将每条曲线映射到一个局部区域。
C. PIXEL-WISE ENHANCEMENT
传统的基于像素的方法通过基细节层分解来增强图像的高频细节。 这些方法包括双边滤波[29]、拉普拉斯算子[30]、引导滤波[31]和JND变换[32]。 许多最近的方法使用卷积神经网络(CNNs),特别是编码器-解码器结构[33]。 [34]中的方法使用每像素二次颜色变换将输入图像映射到增强图像。通过[35]将低质量智能手机图像映射到相应的DSLR高质量图像。 一些方法使用GAN,如WeSPE[36]和Depe[37]的照片增强器(DPE)[37]。 EnhanceGan[38]使用图像美学质量的二值化标记应用弱监督来估计CIELAB颜色空间上的分段传递函数。 Pienet[39]通过向其基本网络中注入偏好向量来合并用户偏好。 CSRNET[1]使用由从条件网络中提取的全局特征向量调制的多层感知器(MLP)独立地处理像素。 神经曲线层(CURL)[2]预测应用于不同颜色空间的全局传递函数序列,同时使用主干CNN进行局部增强。 [7]和[40]都学习全局色调曲线和基于像素的残差图用于局部增强。 ICENET[41]通过基于由用户交互提供的全局亮度参数和涂写地图预测像素外伽马校正值来个性化局部对比度增强。 我们的方法结合了自动图像增强和手动后期编辑选项,以最大限度地减少用户的努力,同时允许交互性。
基于像素的方法不太容易解释,因为它很难识别对输入图像执行的操作,而我们的方法显式地指定了转换。
D. OTHER METHODS
另一组方法解决曝光不足增强,如Deepupe[42],DRHT[43]和[44]。 类似地,其他方法侧重于微光图像增强,如[45]-[47]。 零参考深度曲线估计(Zero-DCE)[48]是一种基于像素的基于曲线的方法,它针对没有参考图像的微光图像。 有些方法依赖于图像形成的物理模型(例如,色觉的Retinex理论[49])。 这些方法包括基于场景反射率和照度分离的曝光校正方法[50]、照度估计[42]、[51]和相机响应函数建模[52]。
作为CNNS的替代方案,STAR[53]是一个快速和轻量级的骨干网,用于多种图像增强任务,如白平衡、微光图像增强和照相处理。
全局变换可能不足以估计低质量和高质量图像之间的高度非线性映射。 基于像素处理的方法通常很难解释、微调或集成到ISPS或照片编辑软件中。 我们的方法是基于学习局部图像区域的局部色调曲线; 这使得它比全局增强方法更加灵活。 此外,色调曲线是很好理解,解释,并广泛应用于许多相机ISP和照片编辑软件。 据我们所知,我们的方法是第一个引入学习局部色调映射自动在一个数据驱动的方式,而不是人工调优。
III. LTMNet


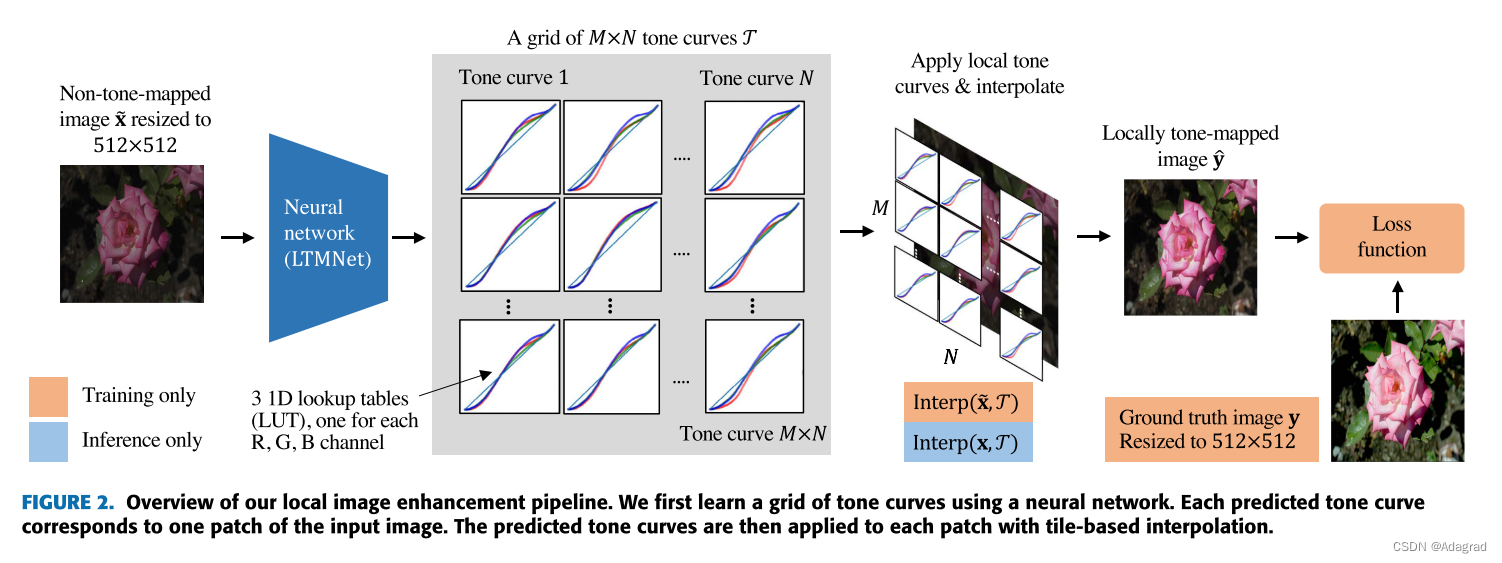
LTMNET层有两个目的:特征提取和色调曲线预测。 对于特征提取,只要构成色调曲线的输出神经元的感受野覆盖它们所应用的图像斑块,就可以使用广泛的结构。 色调曲线预测头可以堆叠在特征提取层的顶部,以确保色调曲线条目处于期望的形状和范围(即,M×N×C×L)。 为了提高效率,我们设计LTMNet,使得输入图像的大小总是调整到一个固定的输入大小(例如,512×512)。
A. LOCAL TONE CURVES

B. LOCAL TONE CURVE INTERPOLATION
在MxN网格中,预测的色调曲线
最适合于贴片(m,n)的中心像素。 直观地说,根据该像素到相邻片中心的距离,相邻片的色调曲线对片内所有其他像素都有不同程度的影响。 这样,每个像素的色调曲线平滑地过渡到另一个像素,导致连续的输出图像没有边界伪影。
我们的色调曲线插值模块,INTERP,通过贴片中心最接近它的相邻色调曲线的组合来变换所有非中心像素,如图所示 3. 结合相邻四条色调曲线的影响,对图像中心区域的像素进行双插值。
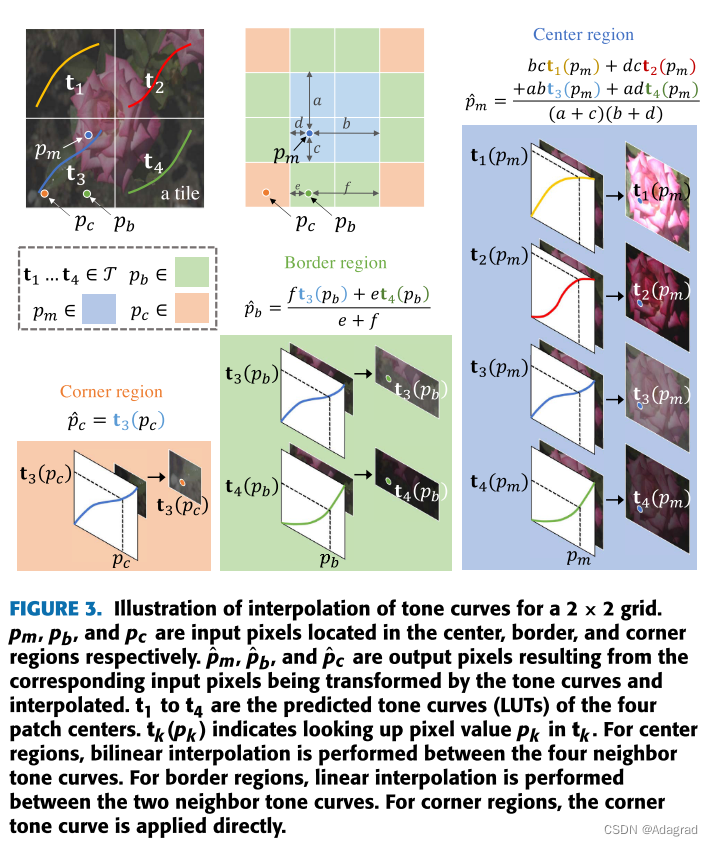

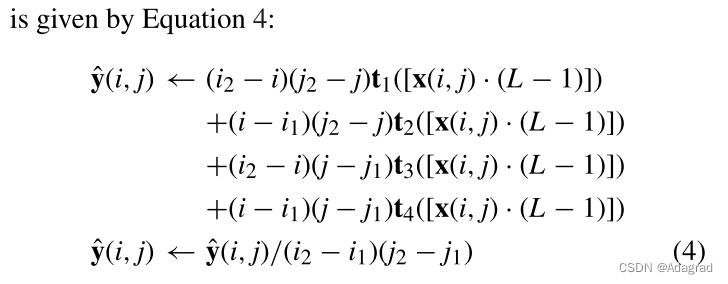

C. TONE CURVE CONSTRAINTS

D. LOSS FUNCTIONS

E. NETWORK ARCHITECTURE

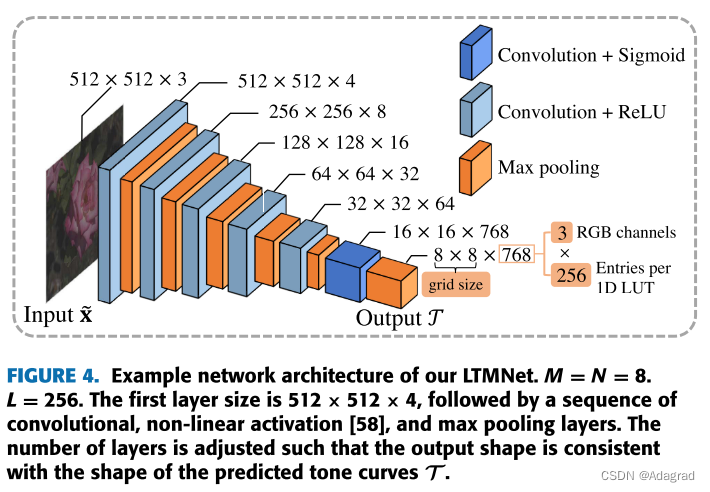
IV. DATASETS
V. EXPERIMENTS
VI. EVALUATION ON MIT-ADOBE FiveK DATASET
VII. LIMITATIONS AND FUTURE WORK
当输入图像中的前景目标经过与背景场景完全不同的函数变换时,我们的方法可以体验到光晕伪影。 这是由于靠近物体边界的像素受到来自两个不同传递函数的影响。 如图所示 11.根据预测的灰度背景的色调曲线和预测的黄色花朵的色调曲线,对靠近花朵的背景像素进行插值。 受花朵色调曲线的影响,会产生暗晕。 这也是Clahe[9]的一个局限性,它使用了相同的插值方案。 这个问题可以通过语义分割来解决,它将场景中的突出对象分离出来,使得每个片段都有自己的转换功能,不受相邻片段的影响。 我们可以为每个片段学习不同的网格大小,这样均匀的片段被分配一个更小的网格以减少空间变化量,纹理的片段被分配一个更大的网格大小以利用更有表现力的局部增强。

另一个潜在的未来方向是将我们的网络工作条件在可调参数上,以允许自动增强和手动调优。 虽然我们的方法可以通过对预测的色调曲线进行后期编辑来调整输出图像,但我们的网络本身是全自动的。 如果用户想根据个人偏好对神经网络进行自定义自适应,这就带来了挑战--例如,调整一些参数,以便网络为不同的场景类别一致地产生不同的风格。 我们希望在今后的工作中研究应对这些挑战的战略。
VIII. CONCLUSION
我们提出了LTMNET,一种学习局部色调曲线网格的局部图像增强方法。 与全局变换相比,LTMNET更有效地增强了局部图像区域,并提供了比像素化方法更高的可解释性。 LTMNET在局部色调映射方面优于现有方法,并在建模附加的冲印操作方面取得了有竞争力的结果。 另外,我们提出了一种新的表示局部色调映射的数据集(LTM数据集),它不同于现有的数据集,只表示全局和局部色调映射。 我们的方法很有优势,因为它可以很容易地集成到相机ISP和用户交互式图像编辑工具中。
-
相关阅读:
Apache网页优化
基于PETALINUX的以太网调试
远程仓库创建好后,出现版本冲突,提交不成功,pull也会失败的解决方法
1.8 - 多级存储
现代前端常用工具
机器学习(9)---线性回归中的公式推导(手推)、闭式解和数值解
超硬核,拒绝内卷全靠阿里大能整理的这份 Java 核心手册,堪称强无敌,谁来不说一声牛 AC
华为HCIP Datacom H12-821 卷18
每个后端都应该了解的OpenResty入门以及网关安全实战
Vite 入门篇:学会它,一起提升开发幸福感。
- 原文地址:https://blog.csdn.net/u013049912/article/details/127611420