-
Redis是如何做缓存的
前言
基于Redis的高性能特性,我们将Redis用在缓存场景非常广泛。使用起来方便,响应也是远超关系型数据库。
但我们用Redis做缓存时,也要注意各种问题的应对和措施,比如缓存失效、数据一致性问题等。因此,用redis做缓存需要熟悉这一套逻辑的工作原理、异常处理等。
缓存的工作机制
缓存的特征
说到redis适合做缓存,我们第一时间能想到的原因就是Redis基于内存,响应快。这个是对的,我们结合计算机三个存储介质的速度来看:
- CPU:响应速度20-40ns,存储空间1-32MB;
- 内存:响应速度100ns,存储空间一般在16G-128GB之间;
- 磁盘:响应速度3-5ms,存储空间可达到4TB。
这个对比显而易见,响应速度上cpu > 内存 > 磁盘,存储空间上cpu < 内存 < 磁盘。综合起来看,内存是最适合作为缓存的,因为速度快,而空间也相对来说较大。
在计算机中,缓存有这2种:
- cpu中的缓存:这是用来缓存内存数据的;
- 内存中的缓存:用来缓存磁盘中的数据。
最快的CPU,内存速度也不错,而磁盘是最慢的。如果我们要保证响应速度,就得避免即时从磁盘拉取数据了。
总结一下,缓存的特征就是响应快,避免每次从磁盘获取数据;缓存系统的空间容量比磁盘小,因此不能把所有数据都放缓存中。这也就是Redis作为缓存通常要配合存在磁盘的mysql工作的缘故。
Redis缓存的2种情况
我们用Redis做缓存时,业务数据通常在数据中(比如mysql)。当客户端要访问数据时,先从redis拉取缓存,这时就有2种情况了:
- 数据在缓存上: 也就是缓存命中,此时直接将缓存结果返回。
- 数据不在缓存上:也就是缓存未命中,这个时候就得从mysql来读取数据了,而响应速度自然会慢下来。同时,这个数据也得再写到redis上,避免后续读数据又得走数据库。
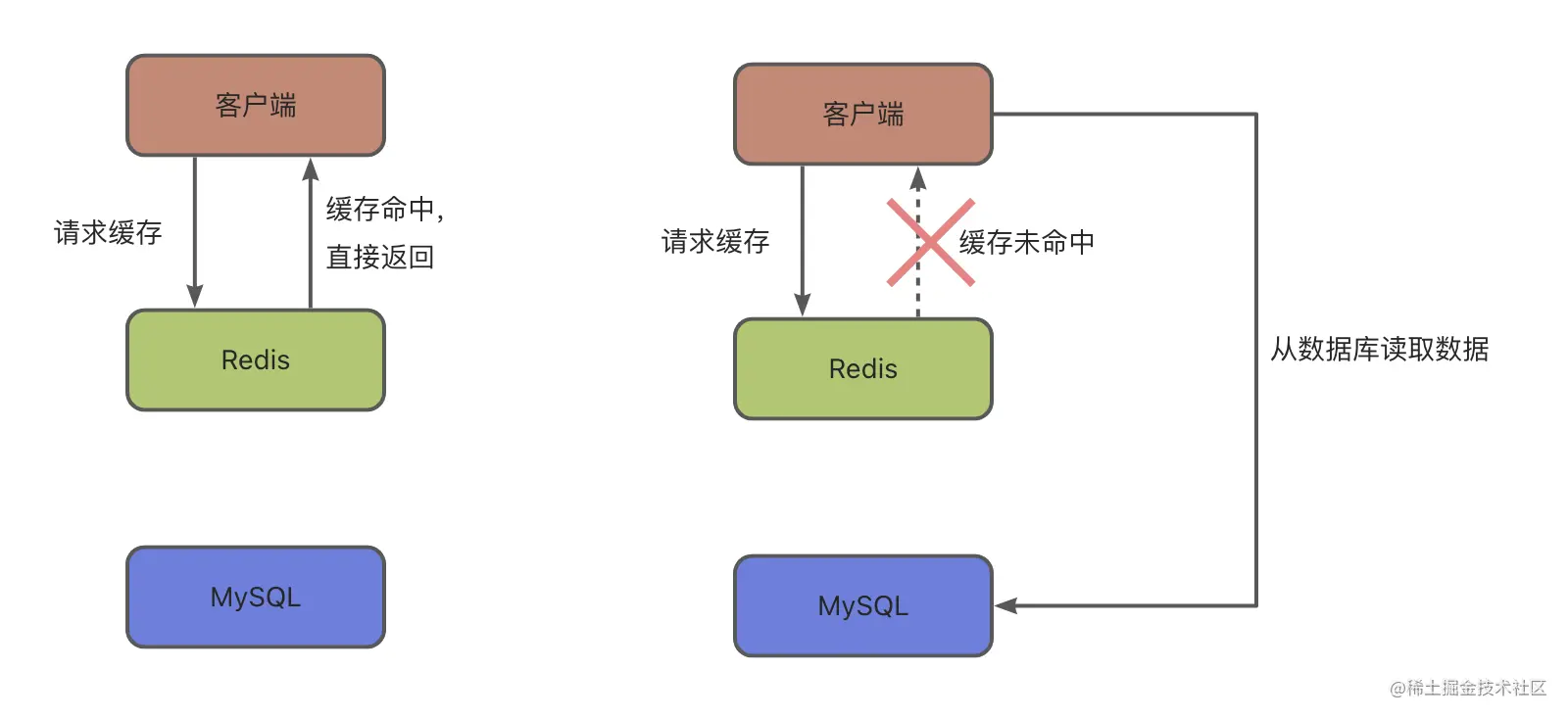
redis做缓存的使用方法
使用比较简单,通常就是3步骤:
- 当需读取数据时,首先请求Redis数据,比如用get、hget方法获取Redis缓存。
- 判断第一步的缓存是否存在,存在就直接返回数据了; 若缓存不存在,这时要从数据库来查询数据。
- 数据查询到之后,还得更新到Redis中,比如set、hset方法的调用。
数据除了读取,还会有更新的操作,这时我们还得考虑这个更新的操作。
缓存的类型
我们根据Redis是否接收写请求,可分为只读缓存和读写缓存。
只读缓存就是数据的更新时,直接在数据库更新数据,若Redis已有缓存,需要删除缓存。
只读缓存的数据更新用图来解释很清晰:

读写缓存就是数据的更新,会先在缓存中进行更新,然后再写回数据库。而写回数据库这个动作,可分为同步直写和异步写回。
同步写回就是缓存更新的同时,也给数据库发送写请求。这种方式性能较低,因为每次更新数据都要走数据库,但是它有个优点就是数据可靠性高。缓存故障了也不会丢失数据。
异步写回就是 所有写请求都先在缓存中处理。等到这些增改的数据要被从缓存中淘汰出来时,缓存将它们写回后端数据库。用个图例来说明:
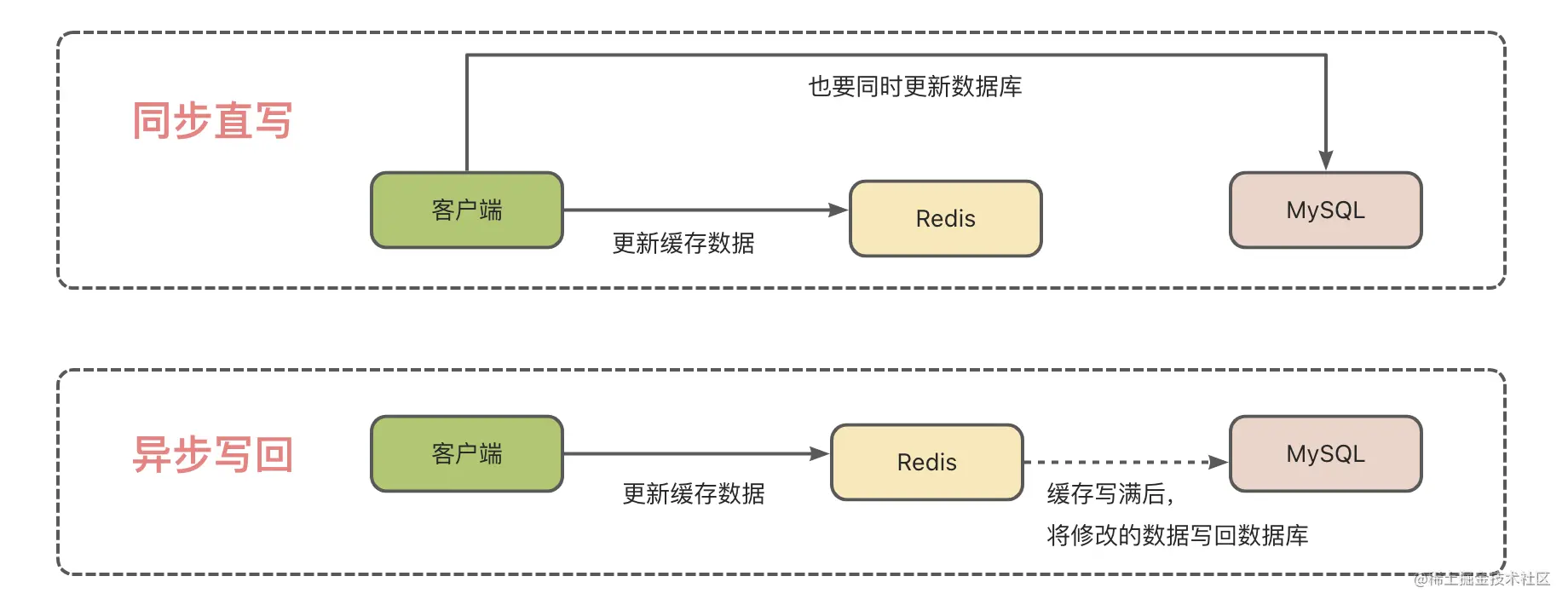
我们在选择缓存类型的时候,如果对读请求响应速度要求很高的话,可选只读缓存;如果对写请求要加速,就选择读写缓存。
小结
本文介绍了Redis做缓存会遇到的两种情况,以及2种模式–只读缓存和读写缓存。我们在用Redis做缓存时,结合项目具体背景,按需选择缓存模式。
-
相关阅读:
单片机,0.06
出海电商APP外包开发及上线流程
Python 位运算的操作
YOLOV1详解——Pytorch版
Angular 项目升级需要注意什么?
Lua如何调用C程序库
LINUX-VIM编辑器常用命令大全(超全)
libevent学习——例子.md
在 Android Studio Java 项目里混合 Kotlin 编程
常见聚类算法及使用--Affinity Propagation(AP)
- 原文地址:https://blog.csdn.net/Huangjiazhen711/article/details/127610090