-
agent+ddd实践案例
1. 大纲
2. 业务背景(situation)
消息网关内部采用
MySQL进行消息持久化,需要大量的I/O开销,因此在高并发请求下会成为系统瓶颈,亟需一种高吞吐量的替代方案。这里主要思考了2种解决方案:
-
寻找一种
MySQL的替代方案。由于MySQL是基于B-Tree的,考虑性能提升的话,需要采用基于LSM-Tree的方案设计的数据库- 但是这种方案涉及业务侧比较大的改造(对于当前MVC3层结构的代码来说,因为并未对repo层进行抽象,因此替换底层存储几乎是革命性的变革)
B-TreevsLSM-Tree,分别适合读多和写多的场景
-
放弃以
DB进行数据持久化的方案,转而采用ES等其他引擎。这里又可以进一步细化为2种方式,分别为- 代码中直接嵌入
ES-Template,将数据存储到ES中 - 将数据写入
log中,通过中间件将log中的信息同步至ES
其中,第一种方案需要引入新的依赖,同时在有新租户接入时面临比较大的代码编写任务;而第二种方案仅需配置
logback.xml,在有新tenant接入时,采用扩展的方式就可以很好的完成对接。 - 代码中直接嵌入
3. 设计思路(task)
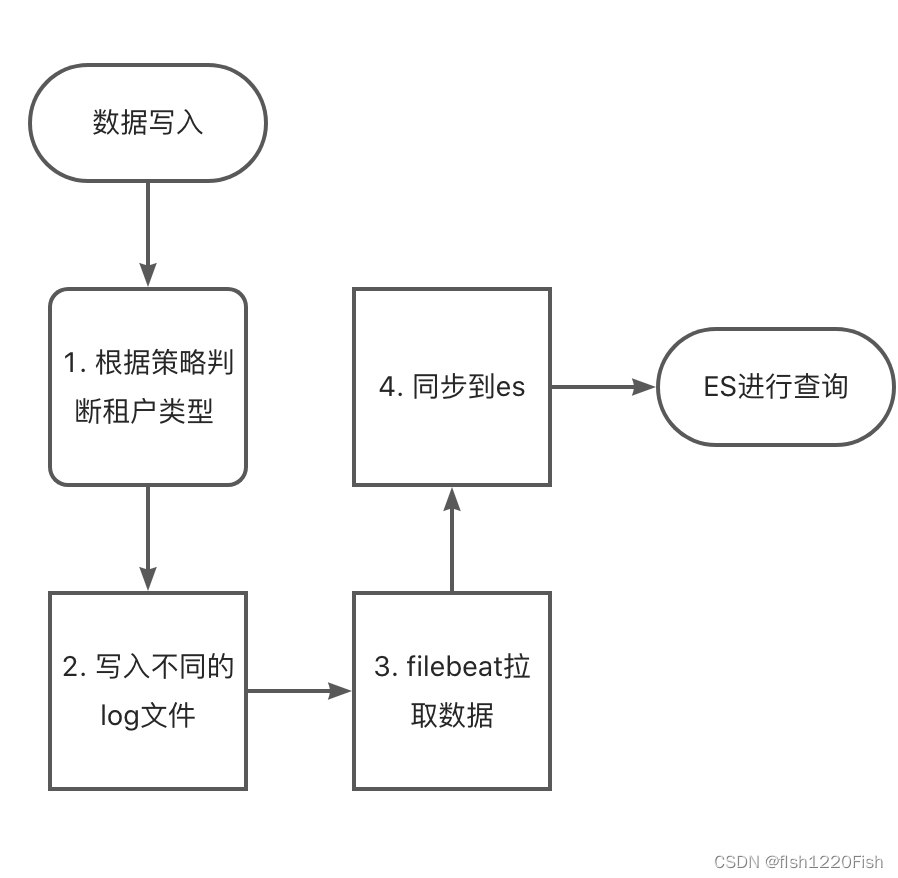
这里需要着重考虑的一点是,写入不同的log文件时,是否可以采用对先用代码无侵入的解决方案?答案是:
javaagent4. 重点难点(action)
4.1 logback
- 系统引入logback.jar依赖
- 编写logback.xml文件
- 日志存储位置LOG_DIR
- 日志输出格式pattern
- 多个日志appender
- 异步日志打印ASYNC
- 日志类配置logger name
<configuration> <property name="LOG_DIR" value="resource/log-save"/> <property name="pattern" value="%d{yyyy-MM-dd HH:mm:ss.SSS} [%thread] %-5level %msg%n"/> <appender name="STDOUT" class="ch.qos.logback.core.ConsoleAppender"> <target>System.outtarget> <encoder class="ch.qos.logback.classic.encoder.PatternLayoutEncoder"> <pattern>${pattern}pattern> encoder> appender> <appender name="tenant_A" class="ch.qos.logback.core.rolling.RollingFileAppender"> <file>${LOG_DIR}/tenantA.logfile> <rollingPolicy class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy"> <fileNamePattern>${LOG_DIR}/tenantA_%d{yyyy-MM-dd}.log.%i.gzfileNamePattern> <timeBasedFileNamingAndTriggeringPolicy class="ch.qos.logback.core.rolling.SizeAndTimeBasedFNATP"> <maxFileSize>50MBmaxFileSize> timeBasedFileNamingAndTriggeringPolicy> <maxHistory>10maxHistory> rollingPolicy> <encoder class="ch.qos.logback.classic.encoder.PatternLayoutEncoder"> <pattern>${pattern}pattern> encoder> <filter class="ch.qos.logback.classic.filter.LevelFilter"> <level>WARNlevel> <onMatch>ACCEPTonMatch> <onMismatch>DENYonMismatch> filter> appender> <appender name="tenant_B" class="ch.qos.logback.core.rolling.RollingFileAppender"> <file>${LOG_DIR}/tenantB.logfile> <rollingPolicy class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy"> <fileNamePattern>${LOG_DIR}/tenantB_%d{yyyy-MM-dd}.log.%i.gzfileNamePattern> <timeBasedFileNamingAndTriggeringPolicy class="ch.qos.logback.core.rolling.SizeAndTimeBasedFNATP"> <maxFileSize>50MBmaxFileSize> timeBasedFileNamingAndTriggeringPolicy> <maxHistory>10maxHistory> rollingPolicy> <encoder class="ch.qos.logback.classic.encoder.PatternLayoutEncoder"> <pattern>${pattern}pattern> encoder> <filter class="ch.qos.logback.classic.filter.LevelFilter"> <level>WARNlevel> <onMatch>ACCEPTonMatch> <onMismatch>DENYonMismatch> filter> appender> <appender name="tenant_Default" class="ch.qos.logback.core.rolling.RollingFileAppender"> <file>${LOG_DIR}/tenantDefault.logfile> <rollingPolicy class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy"> <fileNamePattern>${LOG_DIR}/tenantDefault_%d{yyyy-MM-dd}.log.%i.gzfileNamePattern> <timeBasedFileNamingAndTriggeringPolicy class="ch.qos.logback.core.rolling.SizeAndTimeBasedFNATP"> <maxFileSize>50MBmaxFileSize> timeBasedFileNamingAndTriggeringPolicy> <maxHistory>10maxHistory> rollingPolicy> <encoder class="ch.qos.logback.classic.encoder.PatternLayoutEncoder"> <pattern>${pattern}pattern> encoder> <filter class="ch.qos.logback.classic.filter.LevelFilter"> <level>WARNlevel> <onMatch>ACCEPTonMatch> <onMismatch>DENYonMismatch> filter> appender> <appender name="ASYNC" class="ch.qos.logback.classic.AsyncAppender" > <discardingThreshold>0discardingThreshold> <queueSize>512queueSize> <neverBlock>trueneverBlock> <appender-ref ref="tenant_A" /> <appender-ref ref="tenant_B" /> <appender-ref ref="tenant_Default" /> appender> <root level="info"> <level>infolevel> <appender-ref ref="ASYNC"/> <appender-ref ref="tenant_A"/> <appender-ref ref="tenant_B"/> <appender-ref ref="tenant_Default"/> root> <logger name="com.example.logback.domain.factory.DefaultLogger" level="warn" additivity="false"> <level value="warn"/> <appender-ref ref="tenant_Default"/> logger> <logger name="com.example.logback.domain.factory.TenantALogger" level="warn" additivity="false"> <level value="warn"/> <appender-ref ref="tenant_A"/> logger> <logger name="com.example.logback.domain.factory.TenantBLogger" level="warn" additivity="false"> <level value="warn"/> <appender-ref ref="tenant_B"/> logger> configuration>- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
- 148
4.2 DDD
4.2.1 编写消息写入log的代码
- DDD层级划分

- 代码层级划分
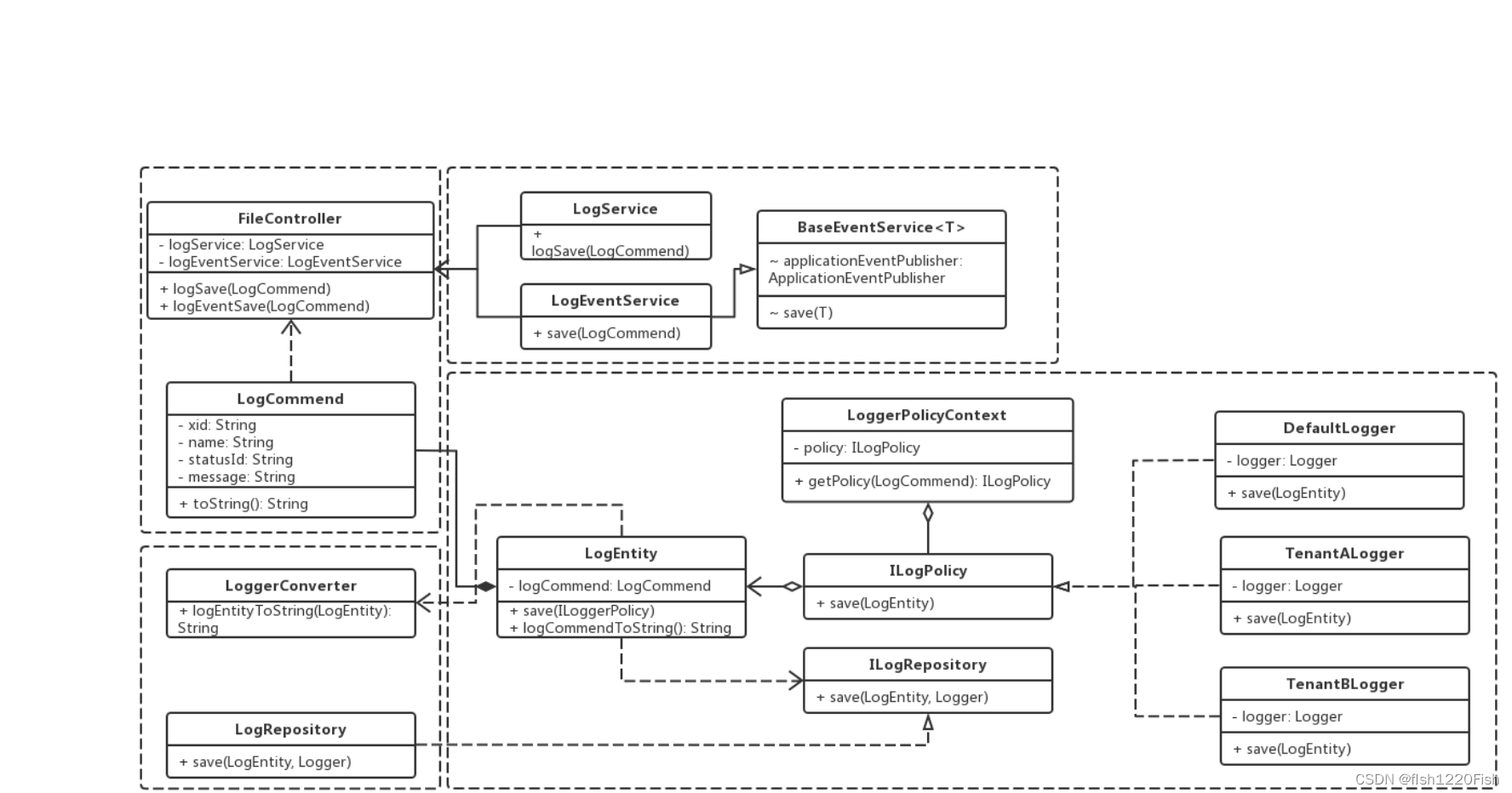
- UML图
- UML类图知识点回顾
- 强弱关系:依赖 < 关联 < 聚合 < 组合
- 依赖
- 表示方式:虚线箭头
- 解释说明:对象A作为对象B方法的一个参数,则对象B依赖于对象A
- 关联
- 表示方式:实线箭头
- 解释说明:对象A作为对象B的一个属性,则对象B依赖于对象A
- 聚合
- 表示方式:空心菱形加实线
- 解释说明:弱的拥有关系,has a的一种情形,两者不需要有相同的生命周期
- 组合
- 表示方式:实心菱形加实线
- 解释说明:强的拥有关系,contains a的一种情形,两者是严格的整体与部分的关系
- 代码说明
- 入口是fileController中的logSave和logEventSave,其中logSave方法用于模拟正常的日志存储、logEventSave方法用来模拟消息送达后的事件触发日志存储。
- fileController中的传参分为三种类型,分别是commend、query、event。分别对应于写请求、读请求和事件请求。
- 事件请求是指,将原本串行化执行的指令修改为监听事件触发。在Spring中可以直接使用Spring Event机制。该机制通过编写ApplicationEvent、ApplicationListener并交由ApplicationEventPublisher进行事件发布,完成全部流程。使用监听器模式处理事件请求可以很好的实现逻辑解耦,以遵循单一职责原则。
- 具体Logger对象实例的构造,采用了策略模式实现,通过传递参数中的属性,在LoggerPolicyContext中进行判断后构造。
- UML类图知识点回顾
4.3 javaagent
这部分很多,参考我的另一篇文章:
https://www.yuque.com/docs/share/205ed300-cb08-4929-8cb4-7d61631fd152?# 《2022-02-18【agent代理】》4.4 filebeat接入
一波三折的一次实践。
首先,晒出最终的filebeat配置:###################### Filebeat Configuration Example ######################### # This file is an example configuration file highlighting only the most common # options. The filebeat.full.yml file from the same directory contains all the # supported options with more comments. You can use it as a reference. # # You can find the full configuration reference here: # https://www.elastic.co/guide/en/beats/filebeat/index.html #=========================== Filebeat prospectors ============================= filebeat.inputs: # Each - is a prospector. Most options can be set at the prospector level, so # you can use different prospectors for various configurations. # Below are the prospector specific configurations. - type: log enabled: true # Paths that should be crawled and fetched. Glob based paths. paths: - /home/admin/koms/log2/error.log json.keys_under_root: true json.overwrite_keys: true tags: ["error"] - type: log enabled: true # Paths that should be crawled and fetched. Glob based paths. paths: - /home/logback/resource/log-save/tenantA.log json.keys_under_root: true json.overwrite_keys: true tags: ["tenantA"] - type: log enabled: true # Paths that should be crawled and fetched. Glob based paths. paths: - /home/logback/resource/log-save/tenantB.log json.keys_under_root: true json.overwrite_keys: true tags: ["tenantB"] - type: log enabled: true # Paths that should be crawled and fetched. Glob based paths. paths: - /home/logback/resource/log-save/tenantDefault.log json.keys_under_root: true json.overwrite_keys: true tags: ["tenantDefault"] # - /home/admin/koms/log2/info.log #- c:\programdata\elasticsearch\logs\* # Exclude lines. A list of regular expressions to match. It drops the lines that are # matching any regular expression from the list. #exclude_lines: ["^DBG"] # Include lines. A list of regular expressions to match. It exports the lines that are # matching any regular expression from the list. #include_lines: ["^ERR", "^WARN", "^INFO"] # Exclude files. A list of regular expressions to match. Filebeat drops the files that # are matching any regular expression from the list. By default, no files are dropped. #exclude_files: [".gz$"] # Optional additional fields. These field can be freely picked # to add additional information to the crawled log files for filtering #fields: # level: debug # review: 1 ### Multiline options # Mutiline can be used for log messages spanning multiple lines. This is common # for Java Stack Traces or C-Line Continuation # The regexp Pattern that has to be matched. The example pattern matches all lines starting with [ # multiline.pattern: '^\[[0-9]{4}-[0-9]{2}-[0-9]{2}' # Defines if the pattern set under pattern should be negated or not. Default is false. # multiline.negate: true # Match can be set to "after" or "before". It is used to define if lines should be append to a pattern # that was (not) matched before or after or as long as a pattern is not matched based on negate. # Note: After is the equivalent to previous and before is the equivalent to to next in Logstash # multiline.match: after # multiline.max_lines: 2000 #================================ General ===================================== # The name of the shipper that publishes the network data. It can be used to group # all the transactions sent by a single shipper in the web interface. #name: # The tags of the shipper are included in their own field with each # transaction published. #tags: ["service-X", "web-tier"] # Optional fields that you can specify to add additional information to the # output. #fields: # env: staging #================================ Outputs ===================================== # Configure what outputs to use when sending the data collected by the beat. # Multiple outputs may be used. #-------------------------- Elasticsearch output ------------------------------ output.elasticsearch: # Array of hosts to connect to. hosts: ["xxxx:9200"] indices: - index: "filebeat-error-%{+yyyy.MM.dd}" when.contains: tags: "error" - index: "tenanta-%{+yyyy.MM.dd}" when.contains: tags: "tenantA" - index: "tenantb-%{+yyyy.MM.dd}" when.contains: tags: "tenantB" - index: "tenantdefault-%{+yyyy.MM.dd}" when.contains: tags: "tenantDefault" # Optional protocol and basic auth credentials. #protocol: "https" #username: "elastic" #password: "123456" #----------------------------- Logstash output -------------------------------- #output.logstash: # The Logstash hosts #hosts: ["localhost:5044"] # Optional SSL. By default is off. # List of root certificates for HTTPS server verifications #ssl.certificate_authorities: ["/etc/pki/root/ca.pem"] # Certificate for SSL client authentication #ssl.certificate: "/etc/pki/client/cert.pem" # Client Certificate Key #ssl.key: "/etc/pki/client/cert.key" #================================ Logging ===================================== # Sets log level. The default log level is info. # Available log levels are: critical, error, warning, info, debug #logging.level: debug # At debug level, you can selectively enable logging only for some components. # To enable all selectors use ["*"]. Examples of other selectors are "beat", # "publish", "service". #logging.selectors: ["*"]- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
- 148
- 149
- 150
- 151
- 152
- 153
- 154
- 155
- 156
- 157
- 158
- 159
- 160
- 161
- 162
- 163
一开始启动时一直报错下面这个错误,检索到的资料都说是配置文件写法问题。
Exiting: No modules or prospectors enabled and configuration reloading disabled. What files do you want me to watch?
最终发现,并不是写法问题,而是由于filebeat版本过低导致的。上面的写法需要filebeat-6.x,而测试环境使用的还是5.x版本。
果断升级了新版本后,启动成功。
在filebeat向es创建索引的过程中,还出现了一些问题,那就是es中的索引不能有大写字母,所以修改了一下配置文件的index字段信息。
按照上述方法得到的es查询日志如下,不是很直观,因此需要format后进行便捷的查询

4.5 ES同步
- filebeat将数据同步至es中
- es层面的查询,采用kibana提供的sense组件实现

5. 代码
-
-
相关阅读:
flume系列(一)部署示例及组件介绍
windows10系统下载go语言包,并且配置go环境配置
《IP编址与路由:网络层的关键技术》
一文搞懂Linux内核之内核线程
scrapy框架——架构介绍、安装、项目创建、目录介绍、使用、持久化方案、集成selenium、去重规则源码分析、布隆过滤器使用、redis实现分布式爬虫
数值分析基础应用线性代数
Jmeter(115)——在jmeter中写入xls文件的基本方法
C#获取http请求的JSON数据并解析
Redis解决秒杀微服务抢购代金券超卖和同一个用户多次抢购
Springboot 项目读取yaml的配置文件信息给静态方法使用,以及通过配置 ResourceBundle 类读取config.properties
- 原文地址:https://blog.csdn.net/fIsh1220Fish/article/details/127597476
