-
【Spark NLP】第 13 章:构建知识库
🔎大家好,我是Sonhhxg_柒,希望你看完之后,能对你有所帮助,不足请指正!共同学习交流🔎
📝个人主页-Sonhhxg_柒的博客_CSDN博客 📃
🎁欢迎各位→点赞👍 + 收藏⭐️ + 留言📝
📣系列专栏 - 机器学习【ML】 自然语言处理【NLP】 深度学习【DL】

🖍foreword
✔说明⇢本人讲解主要包括Python、机器学习(ML)、深度学习(DL)、自然语言处理(NLP)等内容。
如果你对这个系列感兴趣的话,可以关注订阅哟👋
文章目录
这个应用程序是关于组织信息并使其易于人类和计算机访问的。这称为知识库。近几十年来,随着焦点从“专家系统”转移到统计机器学习方法,NLP 领域知识库的受欢迎程度已经减弱。
专家系统是一个试图利用知识做出决策的系统。这些知识是关于实体、实体之间的关系和规则的。通常,专家系统具有推理引擎,允许软件利用知识库做出决策。这些有时被描述为 if-then 规则的集合。然而,这些系统比这复杂得多。对于当时的技术而言,知识库和规则集可能非常庞大,因此推理引擎需要能够有效地评估许多逻辑语句。
一般来说,专家系统有许多可以采取的行动。它应该采取哪些行动是有规则的。当需要采取行动时,系统会收集一组语句,并且必须使用这些语句来确定最佳行动。例如,假设我们有一个用于控制房屋温度的专家系统。我们需要能够根据温度和时间做出决定。每当系统决定切换加热器、空调或什么都不做时,它必须获取当前温度(或者可能是温度测量值的集合)和当前时间,并结合规则集来确定要采取的行动. 这个系统有少量的实体——温度和时间。想象一下,如果一个系统有数千个实体、多种关系和不断增长的规则集。
在本章中,我们将建立一个知识库。我们想要一个用于从 wiki 构建知识库的工具和一个用于查询知识库的工具。该系统现在应该可以安装在一台机器上。我们还希望能够使用新类型的实体和关系来更新知识库。这样的系统可以被领域专家用于探索一个主题,或者它可以与专家系统集成。这意味着它应该具有人类可用的界面和响应式 API。
我们的虚构场景是一家正在构建机器学习平台的公司。该公司主要向其他企业销售。销售工程师有时会与系统的当前状态不同步。工程师很好,会在适当的时候更新 wiki,但销售工程师很难跟上最新状态。销售工程师为工程师创建帮助票,以帮助他们更新销售演示。工程师不喜欢这样。所以这个应用程序将用于创建一个知识库,使销售工程师更容易检查可能发生的变化。
问题陈述和约束
-
我们试图解决的问题是什么?
-
有哪些限制条件?
-
知识库构建器应该易于更新。配置新类型的关系应该很容易。
- 存储解决方案应该允许我们轻松添加新的实体和关系。
- 回答查询将需要少于 50GB 的磁盘空间和少于 16GB 的内存。
- 应该有一个获取相关实体的查询。例如,在 wiki 文章的末尾通常有指向相关页面的链接。“获取相关”查询应该获取这些实体。
-
“获取相关”查询应该少于 500 毫秒。
-
-
我们如何解决约束问题?
-
知识库构建器可以是获取 wiki 转储并处理 XML 和文本的脚本。这是我们可以在更大的 Spark 管道中使用 Spark NLP 的地方。
- 我们的构建脚本应该监控资源,在我们接近规定的限制时发出警告。
- 我们需要一个数据库来存储我们的知识库。有很多选择。我们将使用 Neo4j,一个图形数据库。Neo4j 也比较有名。还有其他可能的解决方案,但图形数据库固有地以促进知识库的方式构造数据。
- Neo4j 的另一个好处是它带有一个供人类查询的 GUI 和一个用于编程查询的 REST API。
-
计划项目
- 获取 wiki 转储,通常是压缩的 XML 文件
- 提取实体,例如文章标题
- 提取关系,例如文章之间的链接
- 在 Neo4J 中存储实体和关系
- 如果我们生成太多数据,则发出警告
我们需要执行以下操作的服务:
- 允许对给定实体进行“获取相关”查询——结果必须至少是实体文章中链接的文章
- 在 500 毫秒内执行“获取相关”查询
- 有一个人类可用的前端
- 有一个 REST API
- 运行所需内存少于 16GB
这有点类似于第 12 章中的应用程序。但是,与该章不同的是,该模型不是机器学习模型,而是数据模型。我们有一个可以构建模型的脚本,但现在我们还想要一种服务模型的方法。另一个重要的区别是知识库没有简单的分数(例如,F1 分数)。这意味着我们将不得不更多地考虑指标。
设计解决方案
所以我们需要启动Neo4J。一旦你安装了它,你应该能够去 localhost:7474 的 UI。
由于我们使用的是现成的解决方案,因此我们不会过多地研究图形数据库。这是重要的事实。
构建图形数据库以将数据存储为节点和节点之间的边。在这种情况下,节点的含义通常是某种实体,而边缘是某种关系。可以有不同类型的节点和不同类型的关系。在数据库之外,图形数据可以很容易地存储在 CSV 中。节点会有 CSV。此 CSV 将有一个 ID 列、某种名称和属性——取决于类型。边是相似的,除了边的行也将具有边连接的两个节点的 ID。我们不会存储属性。
让我们考虑一个简单的场景,我们想要存储有关书籍的信息。在这个场景中,我们有三种实体:作者、书籍和流派。存在三种关系:作者写一本书,作者是流派作者,一本书属于流派。对于 Neo4j,这些数据可以存储在六个 CSV 中。实体是图的节点,关系是边,如图13-1所示。
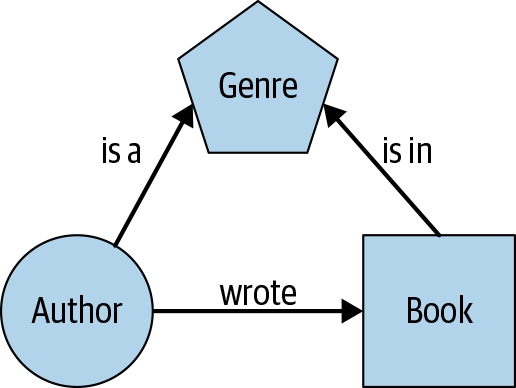
图 13-1。简单图形示例
由于我们无法访问公司的内部 wiki,因此我们将使用实际的 Wikipedia 转储。但是,我们将使用 Simple English wikidump,而不是获得完整的英语语言转储,这将是巨大的。
简单英语是英语的一个子集。它使用了大约 1,500 个单词,不包括专有名词和一些技术术语。这对我们很有用,因为这将帮助我们简化我们需要编写的代码。如果这是一个真正的公司 wiki,可能需要进行几次数据清理迭代。看一下简单英语维基百科的转储。
这是我们的计划:
- 获取数据
- 探索数据
- 解析 wiki 中的实体和关系
- 将实体和关系保存在 CSV 中
- 将 CSV 加载到 Neo4J
实施解决方案
首先,让我们加载数据。大多数 wikidump 以 bzip2 压缩 XML 文件的形式提供。幸运的是,Spark 有能力处理这种数据。让我们加载它。
- import json
- import re
- import pandas as pd
- import sparknlp
- from pyspark.ml import Pipeline
- from pyspark.sql import SparkSession, Row
- from pyspark.sql.functions import lit, col
- import sparknlp
- from sparknlp import DocumentAssembler, Finisher
- from sparknlp.annotator import *
- packages = [
- 'JohnSnowLabs:spark-nlp:2.2.2',
- 'com.databricks:spark-xml_2.11:0.6.0'
- ]
- spark = SparkSession.builder \
- .master("local[*]") \
- .appName("Knowledge Graph") \
- .config("spark.driver.memory", "12g") \
- .config("spark.jars.packages", ','.join(packages)) \
- .getOrCreate()
为了给 Spark 一个解析 XML 的提示,我们需要配置它
rootTag是什么——包含我们所有“行”的元素的名称。我们还需要配置rowTag代表我们行的元素的名称。- df = spark.read\
- .format('xml')\
- .option("rootTag", "mediawiki")\
- .option("rowTag", "page")\
- .load("simplewiki-20191020-pages-articles-multistream.xml.bz2")\
- .persist()
现在,让我们看看架构是什么样的。
df.printSchema()- root
- |-- id: long (nullable = true)
- |-- ns: long (nullable = true)
- |-- redirect: struct (nullable = true)
- | |-- _VALUE: string (nullable = true)
- | |-- _title: string (nullable = true)
- |-- restrictions: string (nullable = true)
- |-- revision: struct (nullable = true)
- | |-- comment: struct (nullable = true)
- | | |-- _VALUE: string (nullable = true)
- | | |-- _deleted: string (nullable = true)
- | |-- contributor: struct (nullable = true)
- | | |-- _VALUE: string (nullable = true)
- | | |-- _deleted: string (nullable = true)
- | | |-- id: long (nullable = true)
- | | |-- ip: string (nullable = true)
- | | |-- username: string (nullable = true)
- | |-- format: string (nullable = true)
- | |-- id: long (nullable = true)
- | |-- minor: string (nullable = true)
- | |-- model: string (nullable = true)
- | |-- parentid: long (nullable = true)
- | |-- sha1: string (nullable = true)
- | |-- text: struct (nullable = true)
- | | |-- _VALUE: string (nullable = true)
- | | |-- _space: string (nullable = true)
- | |-- timestamp: string (nullable = true)
- |-- title: string (nullable = true)
这有点复杂,所以我们应该尝试简化。让我们看看我们有多少文件。
df.count()284812让我们看一下“Paper”页面,以便我们了解如何简化数据。
- row = df.filter('title = "Paper"').first()
- print('ID', row['id'])
- print('Title', row['title'])
- print()
- print('redirect', row['redirect'])
- print()
- print('text')
- print(row['revision']['text']['_VALUE'])
- ID 3319
- Title Paper
- redirect None
- text
- [[File:...
- [[File:...
- [[File:...
- [[File:...
- [[File:...
- [[File:...
- Modern '''paper''' is a thin [[material]] of (mostly)
- [[wood fibre]]s pressed together. People write on paper, and
- [[book]]s are made of paper. Paper can absorb [[liquid]]s such as
- [[water]], so people can clean things with paper.
- The '''pulp and paper industry''' comprises companies that use wood as
- raw material and produce [[Pulp (paper)|pulp]], paper, board and other
- cellulose-based products.
- == Paper making ==
- Modern paper is normally ...
- ==Related pages==
- * [[Paper size]]
- * [[Cardboard]]
- == References ==
- {{Reflist}}
- [[Category:Basic English 850 words]]
- [[Category:Paper| ]]
- [[Category:Writing tools]]
看起来文本存储在
revision.text._VALUE.似乎有一些特殊条目,即categories和redirects。在大多数 wiki 中,页面被组织成不同的类别。页面通常属于多个类别。这些类别有自己的页面链接回文章。重定向是从文章的备用名称指向实际条目的指针。让我们看一些类别。
- df.filter('title RLIKE "Category.*"').select('title')\
- .show(10, False, True)
- -RECORD 0--------------------------
- title | Category:Computer science
- -RECORD 1--------------------------
- title | Category:Sports
- -RECORD 2--------------------------
- title | Category:Athletics
- -RECORD 3--------------------------
- title | Category:Body parts
- -RECORD 4--------------------------
- title | Category:Tools
- -RECORD 5--------------------------
- title | Category:Movies
- -RECORD 6--------------------------
- title | Category:Grammar
- -RECORD 7--------------------------
- title | Category:Mathematics
- -RECORD 8--------------------------
- title | Category:Alphabet
- -RECORD 9--------------------------
- title | Category:Countries
- only showing top 10 rows
现在让我们看看重定向。看起来重定向指向的重定向目标存储在
redirect._title.- df.filter('redirect IS NOT NULL')\
- .select('redirect._title', 'title')\
- .show(1, False, True)
- -RECORD 0-------------
- _title | Catharism
- title | Albigensian
- only showing top 1 row
这本质上给了我们一个同义词关系。因此,我们的实体将是文章的标题。我们的关系将是重定向,链接将位于页面的相关部分。首先让我们获取我们的实体。
- entities = df.select('title').collect()
- entities = [r['title'] for r in entities]
- entities = set(entities)
- print(len(entities))
284812我们可能想引入同类别关系,所以我们也提取类别。
- categories = [e for e in entity if e.startswith('Category:')]
- entity = [e for e in entity if not e.startswith('Category:')]
现在,让我们获取重定向。
- redirects = df.filter('redirect IS NOT NULL')\
- .select('redirect._title', 'title').collect()
- redirects = [(r['_title'], r['title']) for r in redirects]
- print(len(redirects))
63941
现在我们可以从
revision.text._VALUE.- data = df.filter('redirect IS NULL').selectExpr(
- 'revision.text._VALUE AS text',
- 'title'
- ).filter('text IS NOT NULL')
要获取相关链接,我们需要知道我们在哪个部分。所以让我们将文本分成几个部分。然后我们可以使用
RegexMatcher注释器来识别链接。查看数据,部分看起来就像== Paper making ==我们在前面的示例中看到的那样。让我们为此定义一个正则表达式,增加额外空格的可能性。section_ptn = re.compile(r'^ *==[^=]+ *== *$')现在,我们将定义一个函数,该函数将对数据进行分区并为这些部分生成新行。我们需要跟踪文章标题、部分和部分的文本。
- def sectionize(rows):
- for row in rows:
- title = row['title']
- text = row['text']
- lines = text.split('\n')
- buffer = []
- section = 'START'
- for line in lines:
- if section_ptn.match(line):
- yield (title, section, '\n'.join(buffer))
- section = line.strip('=').strip().upper()
- buffer = []
- continue
- buffer.append(line)
现在我们将调用
mapPartitions创建一个新的RDD并将其转换为DataFrame.- sections = data.rdd.mapPartitions(sectionize)
- sections = spark.createDataFrame(sections, \
- ['title', 'section', 'text'])
让我们看看最常见的部分。
- sections.select('section').groupBy('section')\
- .count().orderBy(col('count').desc()).take(10)
- [Row(section='START', count=115586),
- Row(section='REFERENCES', count=32993),
- Row(section='RELATED PAGES', count=8603),
- Row(section='HISTORY', count=6227),
- Row(section='CLUB CAREER STATISTICS', count=3897),
- Row(section='INTERNATIONAL CAREER STATISTICS', count=2493),
- Row(section='GEOGRAPHY', count=2188),
- Row(section='EARLY LIFE', count=1935),
- Row(section='CAREER', count=1726),
- Row(section='NOTES', count=1724)]
说白了,
START是最常见的,因为它捕获了文章开头和第一部分之间的文本,所以几乎所有的文章都会有这个。这是来自维基百科,所以REFERENCES是下一个最常见的。它看起来RELATED PAGES只出现在 8,603 篇文章中。现在,我们将使用 Spark-NLP 从文本中提取所有链接。- %%writefile wiki_regexes.csv
- \[\[[^\]]+\]\]~link
- \{\{[^\}]+\}\}~anchor
Overwriting wiki_regexes.csv- assembler = DocumentAssembler()\
- .setInputCol('text')\
- .setOutputCol('document')
- matcher = RegexMatcher()\
- .setInputCols(['document'])\
- .setOutputCol('matches')\
- .setStrategy("MATCH_ALL")\
- .setExternalRules('wiki_regexes.csv', '~')
- finisher = Finisher()\
- .setInputCols(['matches'])\
- .setOutputCols(['links'])
- pipeline = Pipeline()\
- .setStages([assembler, matcher, finisher])\
- .fit(sections)
extracted = pipeline.transform(sections)现在,我们可以根据任何地方出现的链接来定义关系。目前,我们将仅使用相关链接。
- links = extracted.select('title', 'section','links').collect()
- links = [(r['title'], r['section'], link) for r in links for link in r['links']]
- links = list(set(links))
- print(len(links))
4012895- related = [(l[0], l[2]) for l in links if l[1] == 'RELATED PAGES']
- related = [(e1, e2.strip('[').strip(']').split('|')[-1]) for e1, e2 in related]
- related = list(set([(e1, e2) for e1, e2 in related]))
- print(len(related))
20726现在,我们已经提取了我们的实体、重定向和相关链接。让我们为它们创建 CSV。
- entities_df = pd.Series(entities, name='entity').to_frame()
- entities_df.index.name = 'id'
- entities_df.to_csv('wiki-entities.csv', index=True, header=True)
e2id = entity_df.reset_index().set_index('entity')['id'].to_dict()- redirect_df = []
- for e1, e2 in redirects:
- if e1 in e2id and e2 in e2id:
- redirect_df.append((e2id[e1], e2id[e2]))
- redirect_df = pd.DataFrame(redirect_df, columns=['id1', 'id2'])
- redirect_df.to_csv('wiki-redirects.csv', index=False, header=True)
- related_df = []
- for e1, e2 in related:
- if e1 in e2id and e2 in e2id:
- related_df.append((e2id[e1], e2id[e2]))
- related_df = pd.DataFrame(related_df, columns=['id1', 'id2'])
- related_df.to_csv('wiki-related.csv', index=False, header=True)
现在我们有了 CSV,我们可以
/var/lib/neo4j/import/使用以下命令将它们复制到并导入它们:-
加载实体
- LOAD CSV WITH HEADERS FROM "file:/wiki-entities.csv" AS csvLine
- CREATE (e:Entity {id: toInteger(csvLine.id), entity: csvLine.entity})
-
加载“重定向”关系
- USING PERIODIC COMMIT 500
- LOAD CSV WITH HEADERS FROM "file:///wiki-redirected.csv" AS csvLine
- MATCH (entity1:Entity {id: toInteger(csvLine.id1)}),(entity2:Entity {id: toInteger(csvLine.id2)})
- CREATE (entity1)-[:REDIRECTED {conxn: "redirected"}]->(entity2)
-
加载“相关”关系
- USING PERIODIC COMMIT 500
- LOAD CSV WITH HEADERS FROM "file:///wiki-related.csv" AS csvLine
- MATCH (entity1:Entity {id: toInteger(csvLine.id1)}),(entity2:Entity {id: toInteger(csvLine.id2)})
- CREATE (entity1)-[:RELATED {conxn: "related"}]->(entity2)Let's go see what we can query. We will get all entities related to "Language" and related to entities that are related to Language (i.e., second-order relations).
让我们看看我们可以查询什么。我们将得到所有与“Language”相关的实体,以及与“Language”相关的实体(即二阶关系)。
- import requests
- query = '''
- MATCH (e:Entity {entity: 'Language'})
- RETURN e
- UNION ALL
- MATCH (:Entity {entity: 'Language'})--(e:Entity)
- RETURN e
- UNION ALL
- MATCH (:Entity {entity: 'Language'})--(e1:Entity)--(e:Entity)
- RETURN e
- '''
- payload = {'query': query, 'params': {}}
- endpoint = 'http://localhost:7474/db/data/cypher'
- response = requests.post(endpoint, json=payload)
- response.status_code
200- related = json.loads(response.content)
- related = [entity[0]['data']['entity']
- for entity in related['data']]
- related = sorted(related)
- related
- 1989 in movies
- Alphabet
- Alphabet (computer science)
- Alphabet (computer science)
- American English
- ...
- Template:Jctint/core
- Testing English as a foreign language
- Vowel
- Wikipedia:How to write Simple English pages
- Writing
我们已经处理了一个 wikidump 并在 Neo4j 中创建了一个基本图。该项目的下一步将是提取更多的节点类型和关系。找到一种将重量附加到边缘的方法也会很好。这将使我们能够从查询中返回更好的结果。
测试和测量解决方案
业务指标
这将取决于此应用程序的特定用例。如果这个知识库是用来组织公司内部信息的,那么我们可以看看使用率。这不是一个很好的指标,因为它并没有告诉我们该系统实际上正在帮助业务——只是它正在被使用。让我们考虑一个假设的场景。
使用我们的示例,销售工程师可以查询他们想要演示的功能并获取相关功能。希望这会减少帮助票。这是我们可以监控的业务级指标。
如果我们实现了这个系统并且没有看到业务指标有足够的变化,我们仍然需要指标来帮助我们了解问题是出在应用程序的基本思想上还是出在知识库的质量上。
以模型为中心的指标
衡量一个集合的质量并不像衡量一个分类器那么简单。让我们考虑一下我们对知识库中应该包含什么的直觉,并将这些直觉转化为指标。
- 稀疏性与密度:如果太多实体与任何其他实体没有关系,它们会降低知识库的有用性;同样,无处不在的关系会耗费资源并且几乎没有收益。以下是一些可用于衡量连接性的简单指标。
- 每个实体的平均关系数
- 没有关系的实体的比例
- 关系出现与全连接图的比率
- 人们查询的实体和关系是我们必须关注的。同样,几乎从未使用过的关系可能是多余的。部署系统并记录查询后,我们可以监视以下内容以了解使用情况。
- 未找到实体的查询数
- 一个时间段(天、周、月)内未被查询的关系数
输出 CSV 的中间步骤的好处是我们不需要从数据库中进行大量提取——我们可以使用 CSV 数据计算这些图形指标。
现在我们对如何衡量知识库的质量有了一些了解,让我们来谈谈衡量基础设施。
审查
第 12 章中的许多审查步骤也适用于该应用程序。您仍然需要进行架构审查和代码审查。在这种情况下,模型审查看起来会有所不同。您将查看数据模型,而不是查看机器学习模型。在构建知识图谱时,您需要平衡性能需求,同时以对领域有意义的方式构建数据。这不是一个新问题。事实上,传统的关系数据库有很多方法可以平衡这些需求。
您可以注意一些常见的结构性问题。第一,有一个节点类型只有一两个属性;您可能需要考虑使其成为它连接到的节点的属性。例如,我们可以定义一个名称类型的节点并让它连接到实体,但这会使图形不必要地复杂化。
这种应用程序的部署会更容易,除非它是面向客户的。您的备份计划应该更关注与用户的沟通,而不是替换“更简单”的版本。
结论
在本章中,我们探索了创建一个不基于机器学习的应用程序。我们可以用 NLP 做的最有价值的事情之一就是让人们更容易访问里面的信息。当然,这可以通过构建模型来完成,但也可以通过组织信息来完成。在第 14 章中,我们将研究构建一个使用搜索来帮助人们组织和访问文本信息的应用程序。
-
-
相关阅读:
【软考】系统集成项目管理工程师(九)项目成本管理
Python优化算法03——粒子群算法
SQL教学:掌握MySQL数据操作核心技能--DML语句基本操作之“增删改查“
2022.7.23 高数据结构——二叉树(递归思想)
重复造轮子 SimpleMapper
我的2023年终回顾:以终为始,持续更新
【全方位带你配置yolo开发环境】快速上手yolov5
c期末复习
LeetCode LCR024.反转链表 经典题目 C写法
学习笔记 MySQL面试题积累(重要) 【实时更新】
- 原文地址:https://blog.csdn.net/sikh_0529/article/details/127569535