-
大数据项目之电商数仓、日志采集Flume配置概述、日志采集Flume配置实操
文章目录
4. 用户行为数据采集模块
4.3 日志采集Flume
4.3.2 日志采集Flume配置概述
按照规划,需要采集的用户行为日志文件分布在hadoop102,hadoop103两台日志服务器,故需要在hadoop102,hadoop103两台节点配置日志采集Flume。日志采集Flume需要采集日志文件内容,并对日志格式(JSON)进行校验,然后将校验通过的日志发送到Kafka。
此处可选择TaildirSource和KafkaChannel,并配置日志校验拦截器。
选择TailDirSource和KafkaChannel的原因如下:4.3.2.1 TailDirSource
TailDirSource相比ExecSource、SpoolingDirectorySource的优势
TailDirSource:断点续传、多目录。Flume1.6以前需要自己自定义Source记录每次读取文件位置,实现断点续传。
ExecSource可以实时搜集数据,但是在Flume不运行或者Shell命令出错的情况下,数据将会丢失。
SpoolingDirectorySource监控目录,支持断点续传。4.3.2.2 KafkaChannel
采用Kafka Channel,省去了Sink,提高了效率。
日志采集Flume关键配置如下:

4.3.3 日志采集Flume配置实操
4.3.3.1 创建Flume配置文件
[summer@hadoop102 flume-1.9.0]$ mkdir job [summer@hadoop102 flume-1.9.0]$ cd job/ [summer@hadoop102 job]$ vim file_to_kafka.conf- 1
- 2
- 3
4.3.3.2 配置文件内容如下
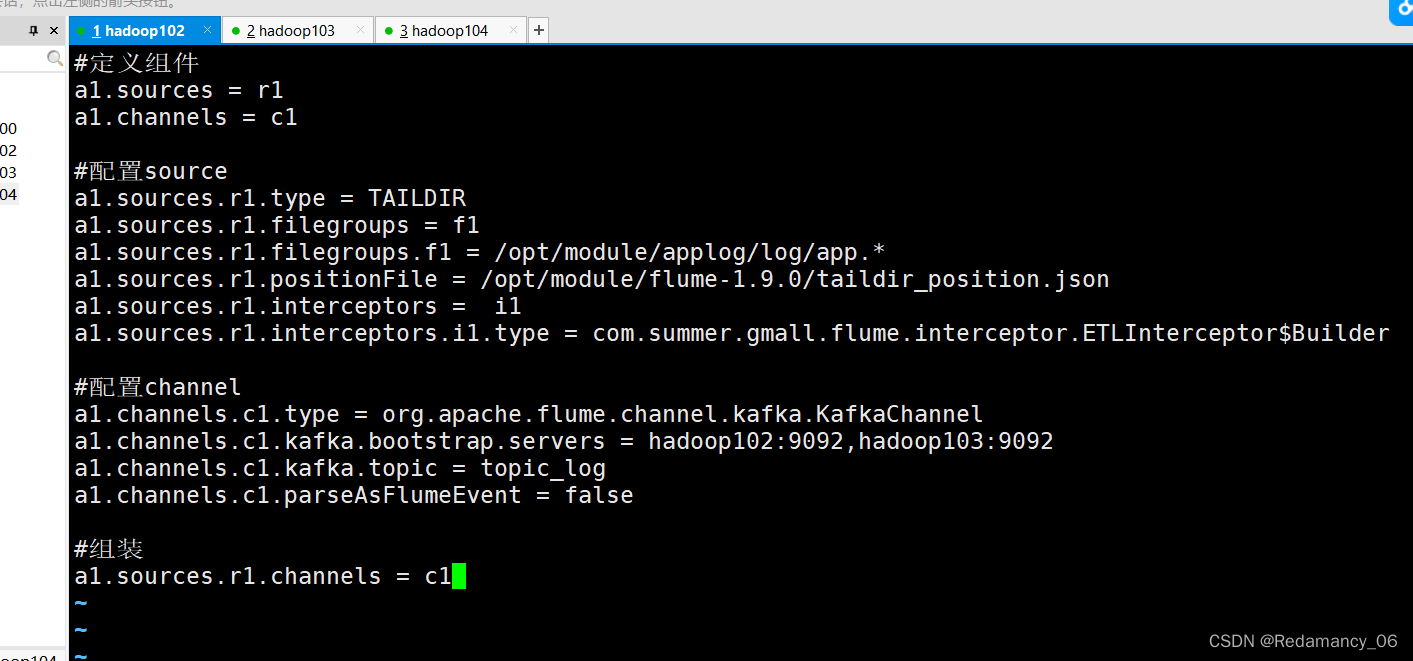
#定义组件 a1.sources = r1 a1.channels = c1 #配置source a1.sources.r1.type = TAILDIR a1.sources.r1.filegroups = f1 a1.sources.r1.filegroups.f1 = /opt/module/applog/log/app.* a1.sources.r1.positionFile = /opt/module/flume-1.9.0/taildir_position.json a1.sources.r1.interceptors = i1 a1.sources.r1.interceptors.i1.type = com.summer.gmall.flume.interceptor.ETLInterceptor$Builder #配置channel a1.channels.c1.type = org.apache.flume.channel.kafka.KafkaChannel a1.channels.c1.kafka.bootstrap.servers = hadoop102:9092,hadoop103:9092 a1.channels.c1.kafka.topic = topic_log a1.channels.c1.parseAsFlumeEvent = false #组装 a1.sources.r1.channels = c1- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20

这个是将拦截器加上了,类名和Builder要用$连接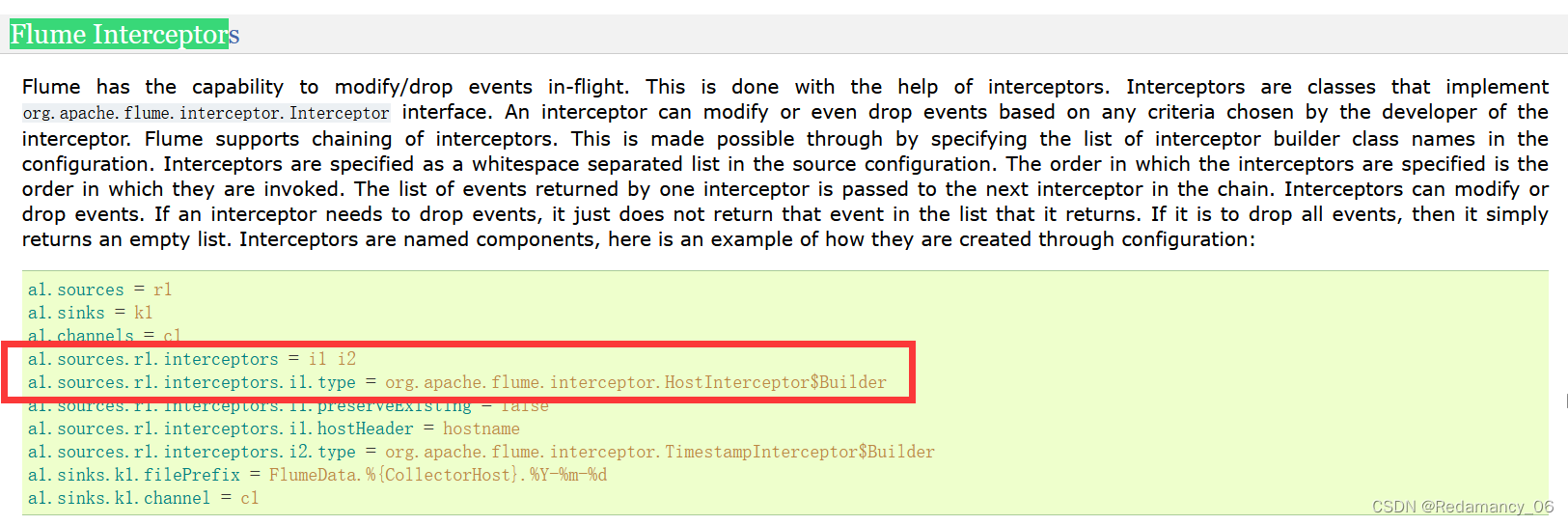
4.3.3.3 编写Flume拦截器
如果没有ETL清洗,则数据有好多残缺,但是只能是轻度清洗,过于重的话则数据会堵塞到管道里,导致数据传输变慢
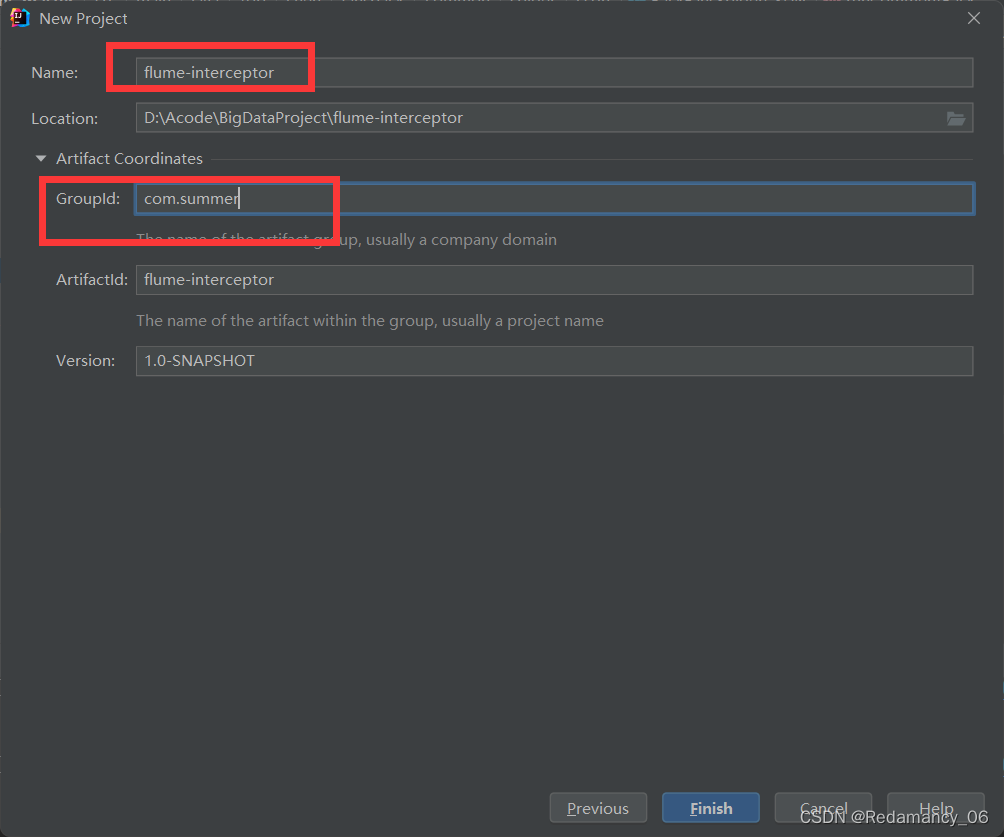
4.3.3.3.1 创建Maven工程flume-interceptor
4.3.3.3.2 创建包:com.summer.gmall.flume.interceptor

4.3.3.3.3 在pom.xml文件中添加如下配置
<dependencies> <dependency> <groupId>org.apache.flumegroupId> <artifactId>flume-ng-coreartifactId> <version>1.9.0version> <scope>providedscope> dependency> <dependency> <groupId>com.alibabagroupId> <artifactId>fastjsonartifactId> <version>1.2.62version> dependency> dependencies> <build> <plugins> <plugin> <artifactId>maven-compiler-pluginartifactId> <version>2.3.2version> <configuration> <source>1.8source> <target>1.8target> configuration> plugin> <plugin> <artifactId>maven-assembly-pluginartifactId> <configuration> <descriptorRefs> <descriptorRef>jar-with-dependenciesdescriptorRef> descriptorRefs> configuration> <executions> <execution> <id>make-assemblyid> <phase>packagephase> <goals> <goal>singlegoal> goals> execution> executions> plugin> plugins> build>- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
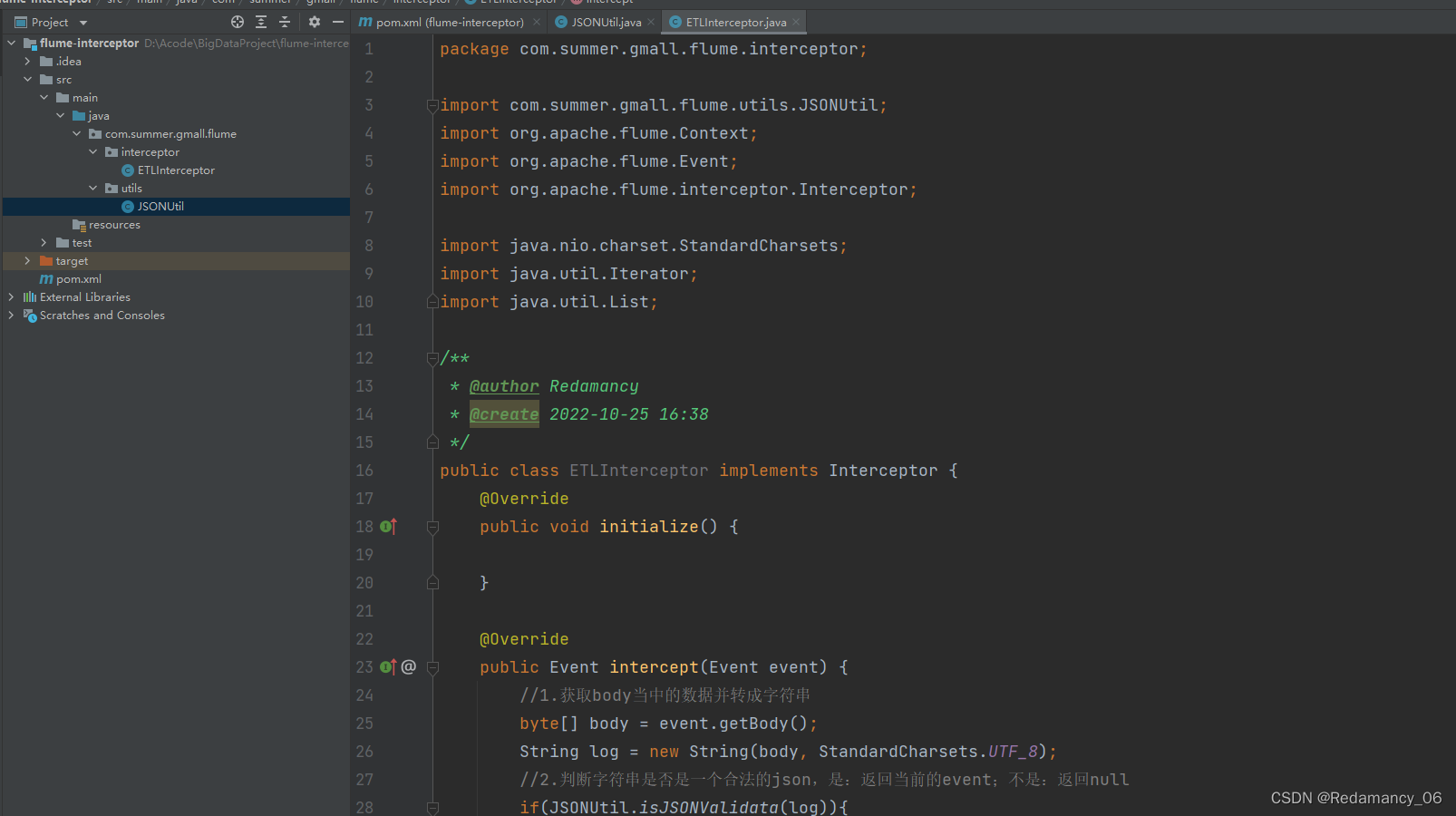
4.3.3.3.4 在com.summer.gmall.flume.utils包下创建JSONUtil类
package com.summer.gmall.flume.utils; import com.alibaba.fastjson.JSONObject; /** * @author Redamancy * @create 2022-10-25 16:38 */ public class JSONUtil { public static boolean isJSONValidata(String log) { //1.JSONObject.parseObject(log);判断json,如果是json,则返回JSON的值,如果不是JSON则会报错。 // 因此使用try,catch来捕捉,如果报错,则该log不是我们想要的JSON格式,就返回false,正确的话就返回true try { JSONObject.parseObject(log); return true; } catch (Exception e) { return false; } } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
4.3.3.3.5 在com.summer.gmall.flume.interceptor包下创建ETLInterceptor类
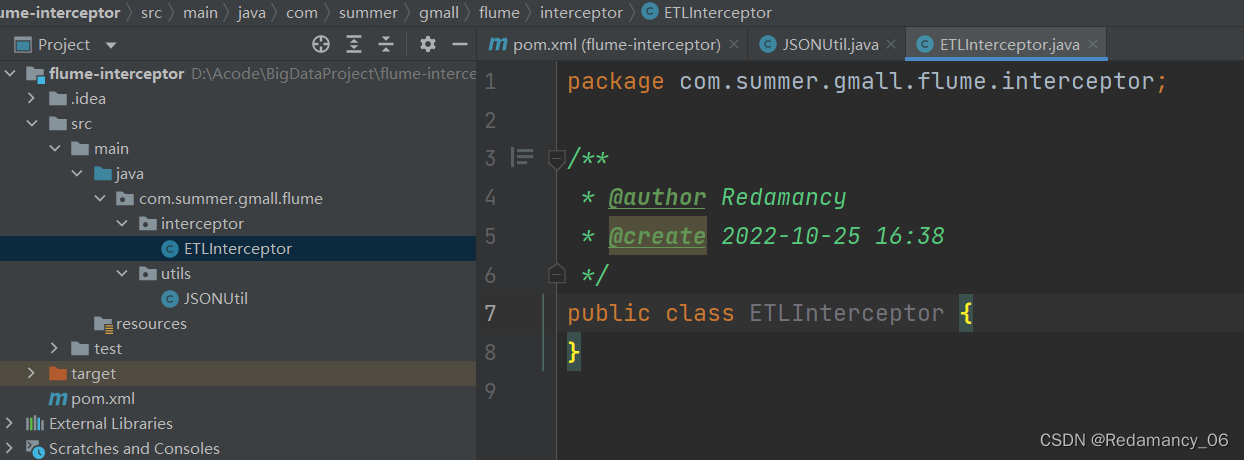
package com.summer.gmall.flume.interceptor; import com.summer.gmall.flume.utils.JSONUtil; import org.apache.flume.Context; import org.apache.flume.Event; import org.apache.flume.interceptor.Interceptor; import java.nio.charset.StandardCharsets; import java.util.Iterator; import java.util.List; /** * @author Redamancy * @create 2022-10-25 16:38 */ public class ETLInterceptor implements Interceptor { @Override public void initialize() { } @Override public Event intercept(Event event) { //1.获取body当中的数据并转成字符串 byte[] body = event.getBody(); String log = new String(body, StandardCharsets.UTF_8); //2.判断字符串是否是一个合法的json,是:返回当前的event;不是:返回null if(JSONUtil.isJSONValidata(log)){ return event; }else{ return null; } } @Override public List<Event> intercept(List<Event> list) { //不能使用for循环来删,因为在list里面删除一个数据,则后面的数据会补上来,index会减少,使用使用这个来remove数据是不可行的,到后面会报错。 //可以使用迭代器来删数据 /* for (int i = 0; i < list.size(); i++) { Event event = list.get(i); if(intercept(event) == null){ list.remove(i); } }*/ Iterator<Event> iterator = list.iterator(); while(iterator.hasNext()){ Event next = iterator.next(); if(intercept(next) == null) { iterator.remove(); } } return list; } public static class Builder implements Interceptor.Builder{ @Override public Interceptor build() { return new ETLInterceptor(); } @Override public void configure(Context context) { } } @Override public void close() { } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
4.3.3.3.6 打包
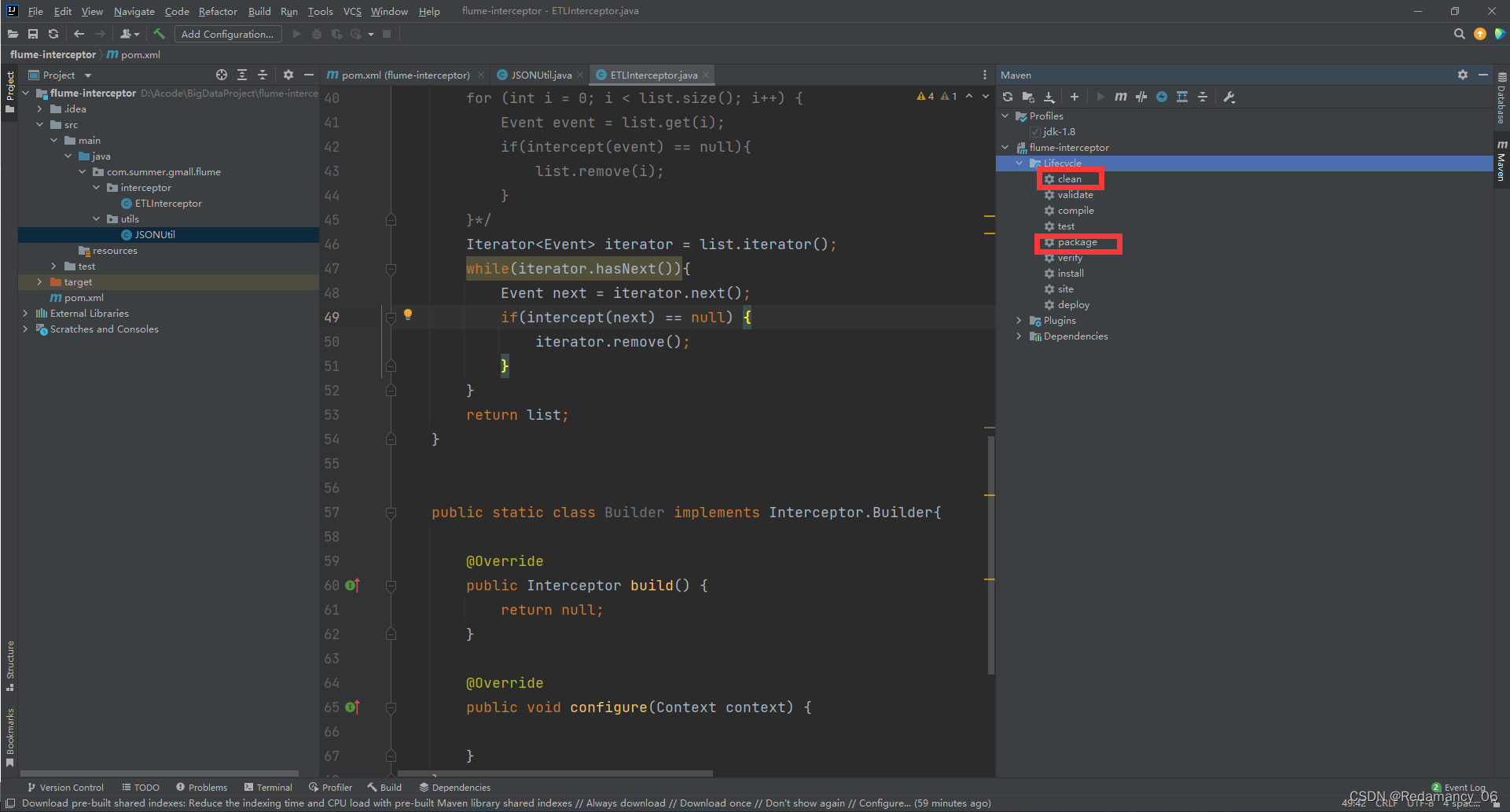 先点击clean,然后点击package。
先点击clean,然后点击package。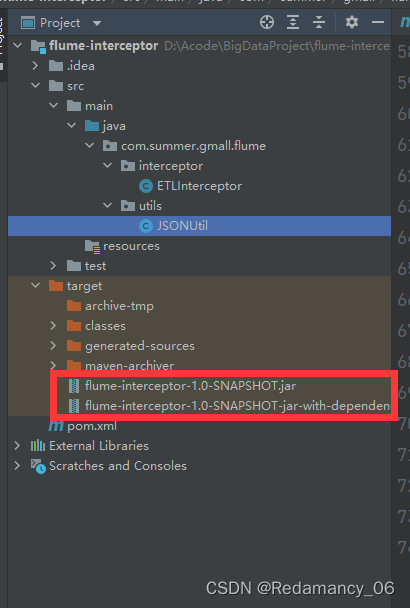

将带依赖的放到/opt/module/flume/lib文件夹下面4.3.3.3.7 需要先将打好的包放入到hadoop102的/opt/module/flume/lib文件夹下面

-
相关阅读:
神经网络建模的基本思想,神经网络建模实验总结
fpga驱动4K edp屏幕
jeesite vue教程
直播的多样性
VictoriaLogs 要凭什么革了各家日志存储的命
hadoop学习使用
kubernetes的服务暴露Service的三种常用类型
代码随想录算法训练营第三十七天| 860.柠檬水找零,406.根据身高重建队列 ,738.单调递增的数字
AtCoder Beginner Contest 276「A」「B」「C」「D 思维」「E 联通块」「F 树状数组维护期望」
SFI立昌Ultra Low Capacitance方案与应用
- 原文地址:https://blog.csdn.net/Redamancy06/article/details/127509712