-
【Linux】--make/makefile--gcc/g++/gdb
make/makefile
概念
make是Linux下的一条指令,而Makefile是一个文件,可以简单理解为make就是执行Makefile里面写的目的。
会不会去写Makefile可以侧面的看出一个人是否具备完成大型工程的能力
假设现有一个工程里面有上千上万个源文件,那么就可以使用Makefile定义一系列的规则来指定,哪些文件需要先编译,哪些文件后编译。当我们写好Makefile后,只需要一个make命令就可以让整个工程完全自动编译,极大地提高了效率
也就是说,make是一个解释Makefile中指令的命令工具,两者搭配使用就可以完成项目自动化构建
Makefile
那么Makefile应该怎么样去写呢,那就得先了解一下Makefile的原理了。
在Makefile里面我们需要去定义一个方法时,就得考虑到两个因素,依赖关系、依赖方法。举例:当我们编写好一个源文件时,我们需要对它进行编译生成可执行文件,那么可以把这个可执行文件看做是目标文件,想要生成它就得依赖我们写好的源文件,那么我们就可以把源文件看做是依赖文件。那有了源文件后,我们需要通过编译工具编译的方法才能生成可执行文件,那这个方法我们就可以看做是依赖方法。
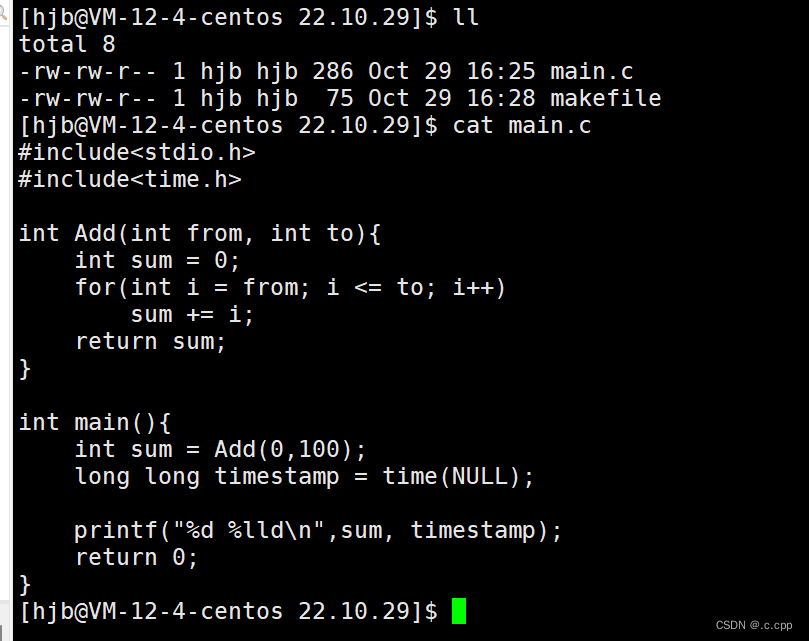
首先我写好了一个.c源文件,并且创建了一个makefile文件,按照之前学的,这是我们可以用gcc直接去编译生成可执行文件,但是如果每一次都去写gcc的指令就会很麻烦,因此我们可以考虑将这条指令放进makefile里面,我们只需要执行一下make指令就可以自动调用了。
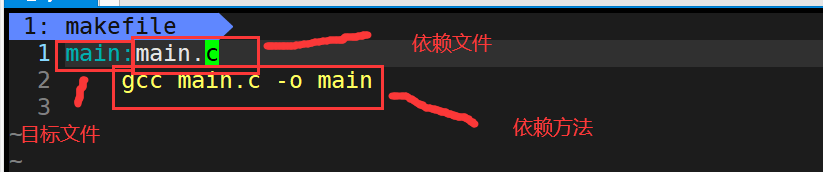
编写的格式就跟上面所讲,需要有依赖关系、依赖方法。目标文件的后面必须要有跟上一个冒号,并且依赖方法另起一行必须以Tab键开头,不能是几个空格
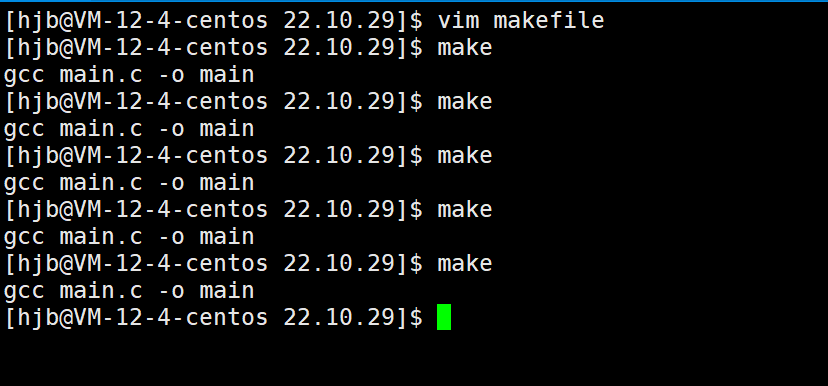
当我们写好之后,make一下看看效果
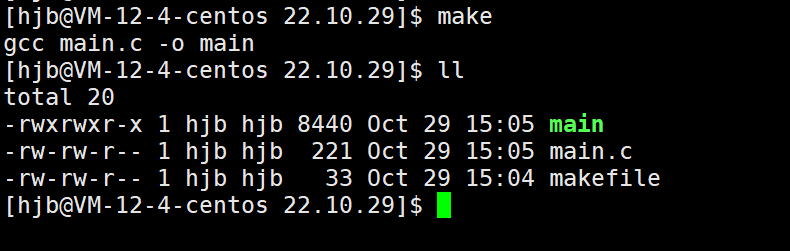
可以看到当我们make一下后,系统会自动执行在makefile里面的指令,生成一个可执行文件。但是现在当我们再make一下,还会再次执行吗?

报错了,这是为什么呢?
make指令这点就带来了好处,当我们的源文件没有被修改时并且可执行文件已经生成时,make就会禁止你的再一次编译,那么问题来了make怎么知道源文件有没有被修改呢,这就得说到文件的属性了。
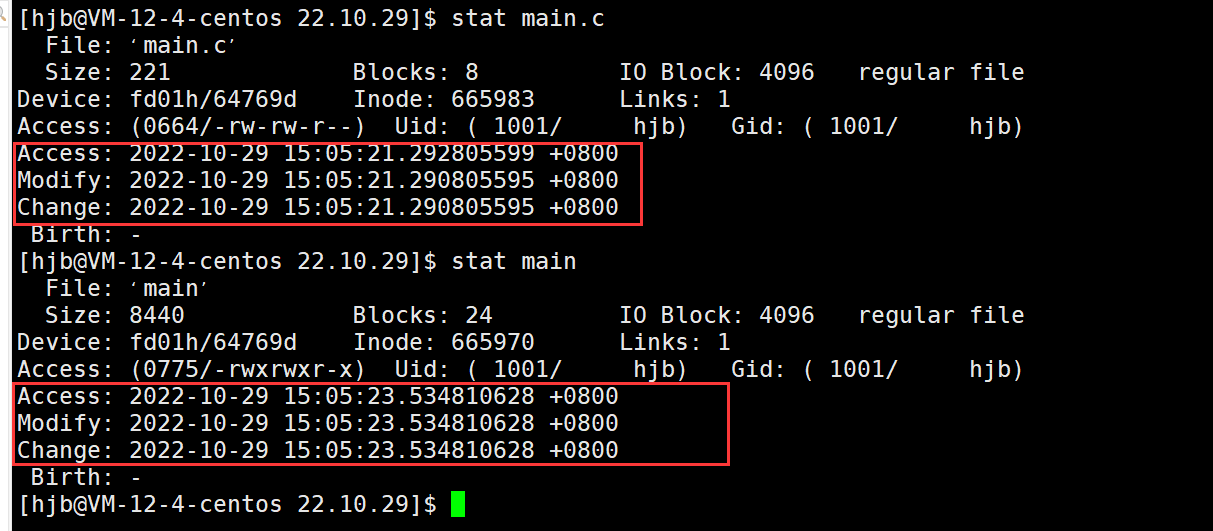
当我们去查看文件的属性时会发现,文件都会有三个时间属性,那么这三个分别代表什么呢
- Access:文件最近一次被访问的时间
- Modify:文件最后一次被修改的时间
- Change:文件的状态被修改的时间
当我们的源文件没有被修改时并且可执行文件已经生成时,此时我们在make一下,make会去比较源文件和已有的可执行文件的被修改时间,如果可执行文件的比源文件的要晚,那么make不再执行编译指令,反之同理
那如果我就想让它执行呢,这时候就引入了一个makefile中的一个关键字:.PHONY(伪目标,该目标总是被执行)
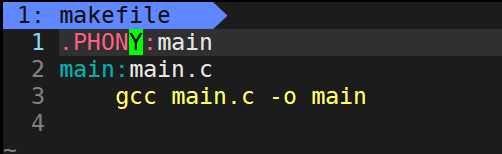
可以看到此时,该条指令就可以无限执行了。
make
make是如何工作的呢
- make首先会在当前目录下找“makefile”或“Makefile”的文件
- 找到之后,它会找文件中的第一个目标文件,并把该依赖方法执行生成最终的目标文件
- 假设现在目标文件为hello,依赖文件为hello.o,但是此时目录下没有hello.o文件,那么make就会继续往下找以hello.o为目标文件的依赖关系,以此类推。
- 也就是说make会一层一层的去找文件的依赖关系,直到最终编译出第一个目标文件
- 如果最后被依赖的文件找不到,那么make会直接退出并报错
gcc/g++/gdb
gcc/g++
众所周知,当我们使用C/C++语言写好代码后,我们的先让源文件经过预处理,编译,汇编,链接几个步骤后才会生成一个二进制机器语言,这样计算机才能看得懂并且执行。那么在Windows下我们可以利用集成开发软件去帮我们完成这几个步骤,同理在Linux下我们就需要借用gcc/g++工具来帮我们完成。
预处理
预处理的主要功能包括宏定义,文件包含,条件编译,去注释等操作。
我们在编写代码时包含的头文件就会在这个步骤进行展开,宏定义会进行替换,我们写的注释也会在这个步骤去除
在Linux中该步骤生成的文件一般以.i为后缀,我们可以通过命令去完成这个步骤,需要用到-E选项
gcc -E main.c -o main.i- 1
编译
这个步骤,首先gcc/g++会检查代码是否有错误,以及确定代码的实际要做的工作,如果一切正常无误后,gcc/g++就会把代码翻译成汇编语言
在Linux中该步骤生成的文件一般以.s为后缀,我们可以通过命令去完成这个步骤,需要用到-S选项
gcc -S main.c -o main.s- 1
汇编
汇编阶段就是把生成的.s文件转为目标文件也就是生成机器可以识别的二进制语言
在Linux中该步骤生成的文件一般以.o为后缀,我们可以通过命令去完成这个步骤,需要用到-c选项
gcc -c main.c -o main.o- 1
链接
这个阶段,目标文件会和系统库进行连接生成一个可执行程序
Linux中库的命名:去掉前缀lib,去掉后缀.so,剩下的就是库的名称
静态链接
这个链接方式下,代码会将静态链接库拷贝一份到最终的可执行程序中,这样虽然提高了效率但是会是可执行程序的空间变得很大,不利于大型项目
在linux下想要生成静态链接就要在后面加上 -static选项,并且要确保已经安装了C/C++的静态库
sudo yum install glibc-static//安装C静态库 sudo yum install libstdc++-static//安装c++静态库- 1
- 2


动态链接
这个链接方式下,在可执行程序执行的时候,会将动态链接库映射到一块虚拟空间中,然后根据需要再去找对应的函数代码,这样可以极大地缩小可执行程序的空间。
Linux下默认的链接方式是动态链接,依赖的动态库一般为.so为后缀


对比上面的静态链接明显大小小很多
选项操作
- -E 只激活预处理,这个不生成文件,你需要把它重定向到一个输出文件里面
- -S 编译到汇编语言不进行汇编和链接
- -c 编译到目标代码
- -o 重命名可执行文件
- -static 此选项对生成的文件采用静态链接
- -g 生成调试信息。GNU 调试器可利用该信息
gdb
在平时Windows下我们使用想vs2019这样的话编译器时都会有一个调试的功能,让我们发现代码的错误之处。
同理在Linux下也有,这个调试工具就叫gdb,首先我们要安装一下gdb
sudo yum install gdb- 1
安装好之后当我们直接运行gdb调试我们的可执行代码时会发现出问题了
因为程序会分为两个版本,一个是Debug版,一个是Release版
在debug模式下我们才可以对代码进行调试,但是Linux默认的模式是release,所以在生成可执行文件时需要加上-g选项,让它生成的可执行程序是debug模式才可以进行调试
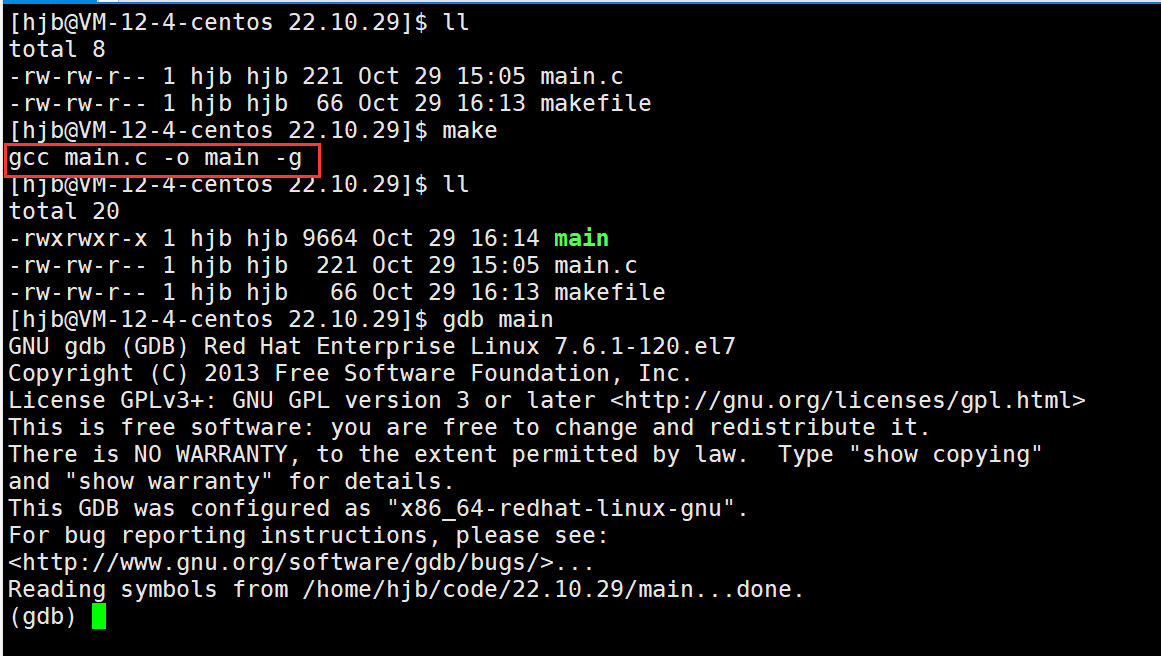
自此我们才算是正式进入到了gdb中
那么对于gdb而言也有属于自己的指令
- list/l 行号:显示binFile源代码,接着上次的位置往下列,每次列10行。
- list/l 函数名:列出某个函数的源代码。
- r或run:运行程序。
- n 或 next:单条执行。
- s或step:进入函数调用
- break(b) 行号:在某一行设置断点
- break 函数名:在某个函数开头设置断点
- info break :查看断点信息。
- finish:执行到当前函数返回,然后挺下来等待命令
- print§:打印表达式的值,通过表达式可以修改变量的值或者调用函数
- p 变量:打印变量值。
- set var:修改变量的值
- continue(或c):从当前位置开始连续而非单步执行程序
- delete breakpoints:删除所有断点
- delete breakpoints n:删除序号为n的断点
- disable breakpoints:禁用断点
- enable breakpoints:启用断点
- info(或i) breakpoints:参看当前设置了哪些断点
- display 变量名:跟踪查看一个变量,每次停下来都显示它的值
- undisplay:取消对先前设置的那些变量的跟踪
- until X行号:跳至X行
- breaktrace(或bt):查看各级函数调用及参数
- info(i) locals:查看当前栈帧局部变量的值
- quit:退出gdb
接下来我们一个一个看
首先显示我们的代码,需要用到l指令
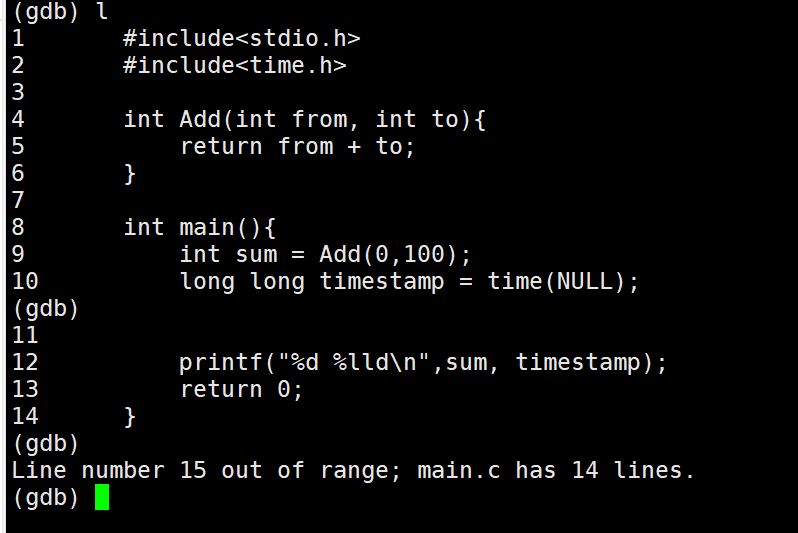
该指令后面也可以加上行号或者函数名,显示指定内容
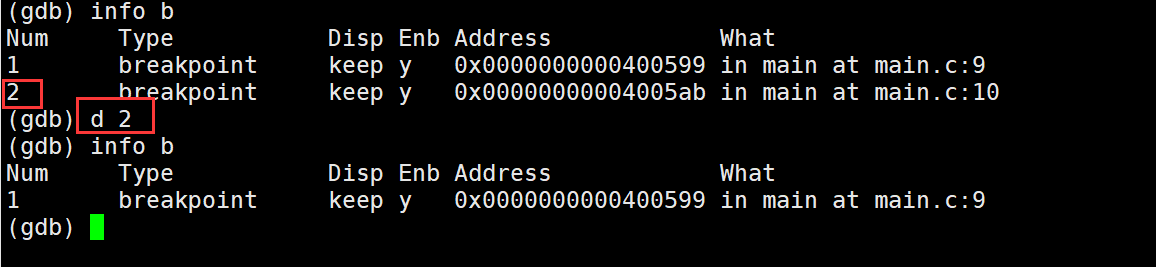
接下来我们需要为程序设置一个断点,如果不设置直接执行程序就会跑完,这是要用到b + 行号指令,设置好之后我们可以通过info b查看我们已经设置好的断点

还可以通过d + 序号删除对应的断点,注意这里的序号不是行号,而是我们设置好断点后每个断点通过info b查看之后每个断点对应的序号
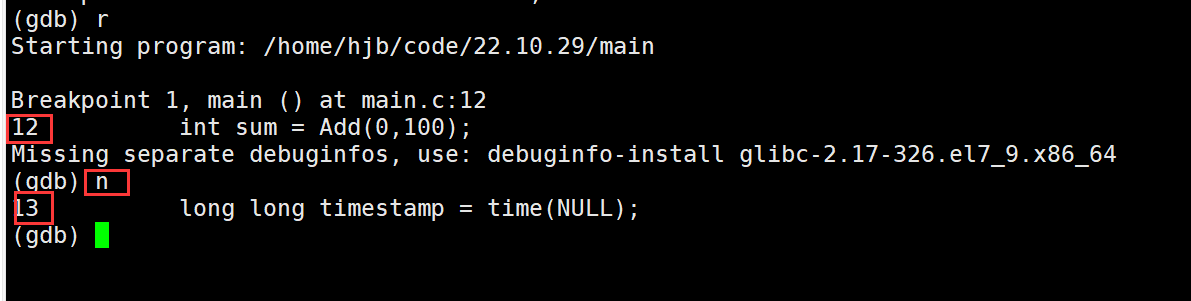
设置好断点后此时我们就可以运行起来了,输入r运行程序(对应VS2019F5),如果执行到某行,该行有函数我们想进入函数调试就需要输入s(对应vs2019的F11),不想进入函数就输入n(对应vs2019F10)
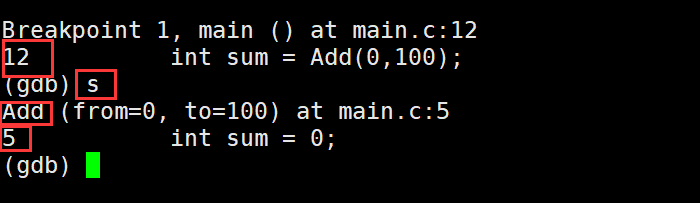
那么现在如果我进入到函数里面了,但是函数里有千次的循环怎么直接执行完函数退出呢,需要输入finish
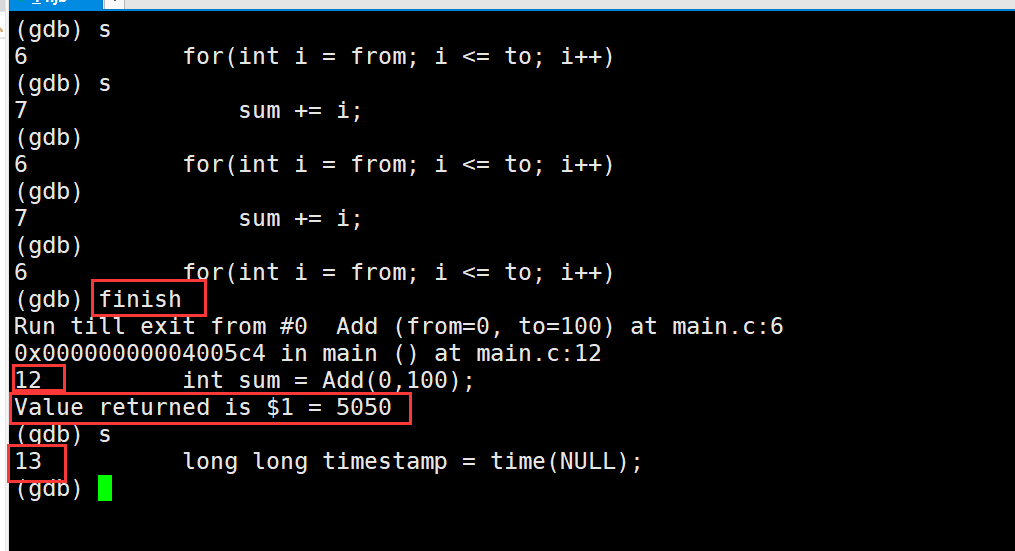
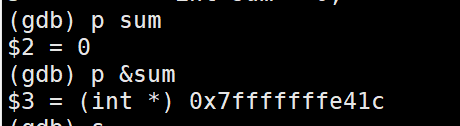
那么当我们进入到一个函数时,我们查看函数的变量值和变量的地址,这时候需要输入p + 变量名或p + &变量名
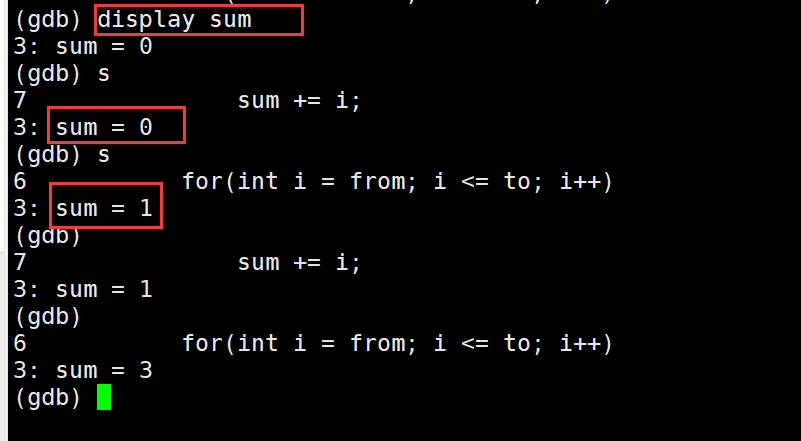
如果想每次执行完一条语句就显示出想查看的变量值,就需要用display + 变量名,不想看了想删除掉就使用undisplay + 变量名
剩下的一些可以自己去探索了,在上面所讲的都是一些比较常用的。
总结
学习到这里已经是可以再Linux下进行代码编写了
接下来就得学习一些系统底层的知识了
每天进步一点淡👍
-
相关阅读:
K8S集群实现外部访问(INGRESS)
业务调整,业绩短期承压,市场热潮退去后的乐舱物流将驶向何方?
大数据学习(5)-hive文件格式
接口测试实战 | Android 高版本无法抓取 HTTPS,怎么办?
序列模型 - 搭建循环神经网络及其应用
Linux系统下KVM虚拟机的基本管理和操作
机械转计算机,成功上岸鹅厂。白菜价年薪40w
C# wpf 使用ListBox实现尺子控件
logback+MQ+Logstash 日志收集
腾讯面试真题 | 没在我八股文列表里。。。
- 原文地址:https://blog.csdn.net/weixin_52563203/article/details/127589027