-
【李宏毅机器学习】Domain Adaptation 域适应
note:
- 在工程很常见的现象,训练好的模型用在model未见过域的样本时,表现效果较差,解决domain shift可以使用迁移学习transfer learning,而domain adaptation是transfer learning的一种方法。
- DA一般分为one-step和multi-step两种,前者是说源域和目标域是相关的,但是域分布存在一点差异,需要通过调整域间的分布(1步)实现domain adaptation:
- Discrepancy-based;这类方法主要利用微调网络参数降低域偏移(domain shift)。
- Adversarial-based;这类方法引入了判别器,并引入对抗损失来使得源域和目标域使得域判别器难以分辨(也就是混淆域判别器),那么源域和目标域就靠的足够近了。
- Reconstruction-based;这类方法为了保证域适应过程中图片信息的完整性,通常将数据重建(保证重建误差最小)作为域适应过程中另一辅助任务。
一、迁移学习 和 域适应
1.1 微调和迁移学习的区别
fine-tune(微调):是对已经训练好的模型,把整个这个模型放到另一个数据集上继续进行训练(其中参数继续发生变化)
迁移学习:提取模型中所需要的部分层,对这些层进行冻结(固定层的参数)在冻结层后增加新的训练层,最后完成训练。
fine-tune是继续更新模型的参数,迁移学习是固定一部分参数,训练更新一部分参数。迁移学习能解决很多时候训练集和测试集存在数据分布差异的问题,迁移学习的一种方法——domain adaptation域自适应,一般是表示域不同(数据集集合),但任务相同。源域数据集一般有标签,目标域没有or很少标签,所以才需要domain adaptation。
二、 三种domain adaptation方法
domain adaptation需要解决减少source和target数据集不同分布之间的差异。有三种主流方法:
- 样本自适应:对源域样本进行加权重采样,从而逼近目标域的分布。
- 特征层面自适应:将源域和目标域投影到公共特征子空间。
- 模型层面自适应:对源域误差函数进行修改,考虑目标域的误差。
三、domain shift的三种类型
- source domain data和target domain data的分布不同
- source domain和target domain data的不同类别数据出现频次相差很大,比如在target domain中的手写识别数据集中大部分是数字1的数据
- source domain和target domain data的输入和输出关系改变:比如两个data中的图片数字0,在前者正确标注为0,但后者标注为1
四、target domain的测试资料几种情况
- target data很多且有label:直接拿target domain资料训练。
- target data很少label, 且数据量少
微调。为了避免过拟合,可以把学习速率调小等操作。 - target data数据量多,但没有label
- 没有label且数据量很少
- 对target domain一无所知
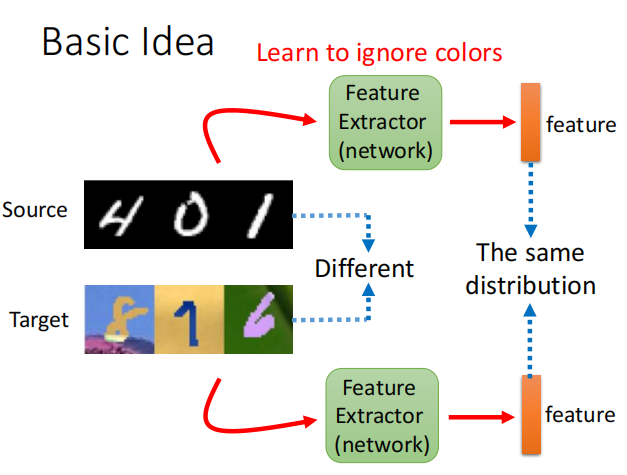
五、Domain Adversarial Training
如第四大点中的base idea,我们想让模型学习source domain和target domain两个域中共有的特征(如上图中,source域数据集是黑白图片,而target domain数据有颜色,特征提取器提取的特征应该尽量不包含颜色信息,即服从相同的分布)。所以model分为特征提取器+标签预测器。
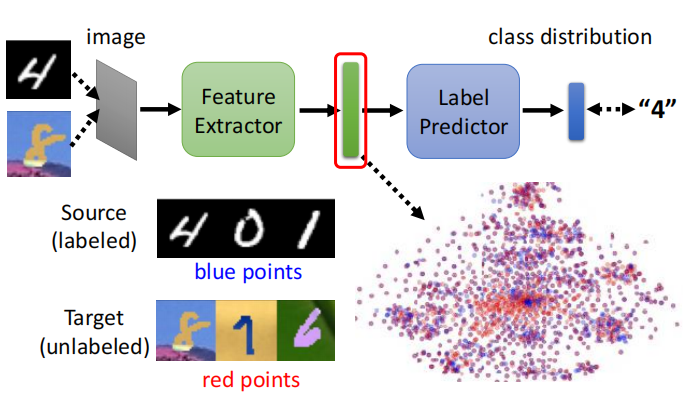
如果是用source domain data则可以用prediction和label进行二分类交叉熵损失函数训练;但是input是target domain data时则没有label。我们希望特征处理器feature extractor处理source domain和target domain data后的向量,两者的向量分布都是差不多的(如上图的右下角,颜色接近)。利用对抗GAN思想学习共有的特征:
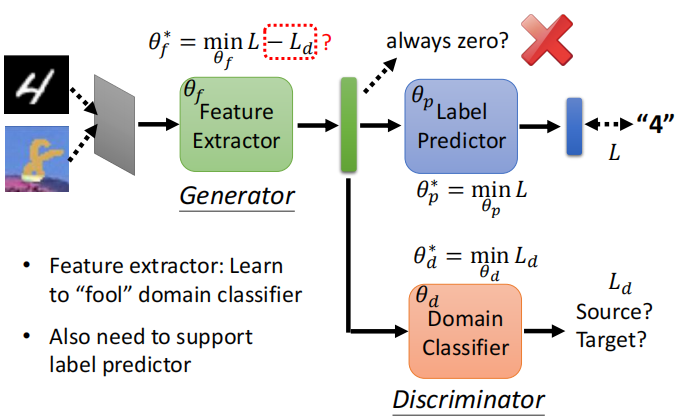
(1)领域分辨器:input为特征提取器的output vector(ouput为该该向量是来自source domain还是target domain)。把特征提取器看做是generator,不断调整参数来欺骗domain classifier。(2)优缺点:
优点:大多数方法适用
缺点:难于求解,容易过适配(3)符号化(具体公式见下图):
- 假设 Label Predictor 的参数,我们就叫它 θ p \theta_p θp
- Domain Classifier 的参数 叫做 θ d \theta_d θd
- 然后 Feature Extractor 的参数 叫做 θ f \theta_f θf
六、limitation
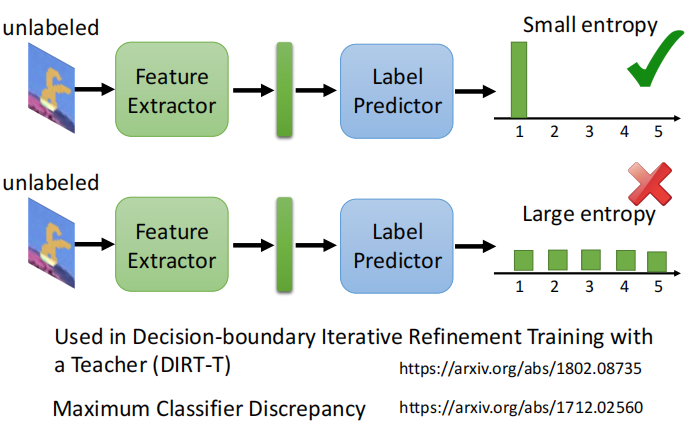
假设我们当前样本的类别有两类,那么对于有标签的训练集我们可以明显地划分为两类,那么对于没有标签的测试我们希望它的分布能够和训练集的分布越接近越好,如下图的右图:
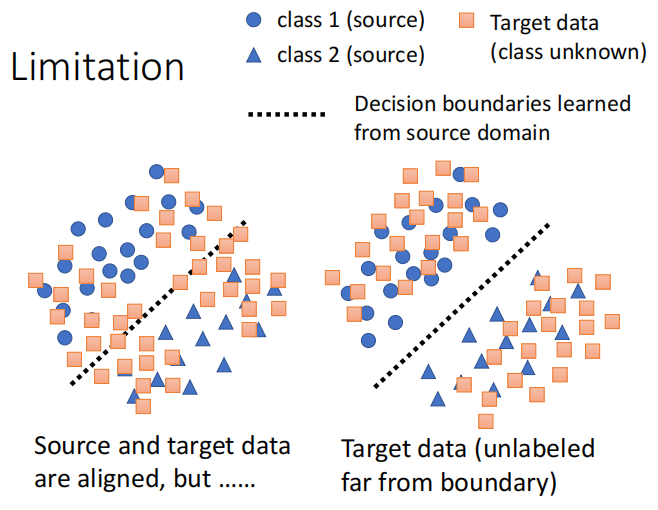
考虑到决策边界:DIRT-T方法。
Reference
[1] 李宏毅21版视频地址:https://www.bilibili.com/video/BV1JA411c7VT
[2] 李宏毅ML官方地址:http://speech.ee.ntu.edu.tw/~tlkagk/courses.html
[3] https://blog.csdn.net/qq_40714949/article/details/122268709?spm=1001.2014.3001.5506
[4] 【GAN】GAN论文总结和解析
[5] 【迁移学习】Domain Adaptation系列论文解析
[6] Understanding Domain Adaptation:Learn how to design a deep learning framework enabling them for domain adaptation -
相关阅读:
milvus数据库-连接
为什么访问同一个网址却返回不同的内容
Python实现Prophet时间序列数据建模与异常值检测(Prophet算法)项目实战
水滴邮件营销:让企业营销更简单
Windows快捷键
vue3前端以json样式输入组件实现
XSS漏洞DOM型总结、XSS利用、XSS绕过
云上未来:探索云计算的技术变革与应用趋势
华清远见-JavaWeb学习总结
Kotlin 使用泛型
- 原文地址:https://blog.csdn.net/qq_35812205/article/details/127354795