-
对象存储只能按文件名搜索,你out了吧
摘要:不少大公司的一个桶里都是几亿几十亿的对象,那他们都是怎么检索的呢?
本文分享自华为云社区《对象存储只能按文件名搜索? 用 DWR + ElasticSearch 实现文件名、文件内容、图片文字的模糊搜索!》,作者:云存储开发者支持团队 。
众所周知,由于对象存储的架构限制,要想检索对象存储里的文件,只能使用前缀的方式过滤,然后一页一页的列举,限制多,效率低,要是桶内对象实在太多,可能光列举就要列举一两天。你可能会问,不少大公司的一个桶里都是几亿几十亿的对象,那他们都是怎么检索的呢?很简单但很有效的方案——在上传对象时候把对象信息存到其他数据库里,如 Elasticsearch、MongoDB、MySOL 等,然后在数据库里检索。
这种方案虽然见到有效,但修改成本极高,如果在业务设计初期没有考虑到,或系统运行过程中想要添加些新的字段,那就只能修改业务代码并重新部署,要是再碰上有已分发客户端的情况下还要推动客户端升级才能解决。
有没有升级简单,不用改动业务代码的方案呢?还真有,把存数据库的过程转移到对象存储来做就好了,每次上传对象之后,让对象存储帮你把对象信息存一份到你指定的位置。本文我们尝试通过 DWR 平台来进行解决。DWR 是华为云推出的一个近数据计算平台,简单来说,通过 DWR 平台,我们可以在不改动业务系统的情况下实现对对象的处理。如图片上传时把图片转成 JPG 格式并存储在另一个桶里、在获取图片时给图片加上水印等。DWR 将这一个个的能力都封装成了“算子”,除了官方和第三方伙伴提供的算子外,我们也可以编写自定义算子来实现我们的其他定制类要求。
一、架构总览
1.1 数据库选型
对象存储中一个对象(Object)由对象名(Key)、元数据(Metadata)、对象内容(Data)三部分组成。从原始需求出发,为了实现对象的模糊搜索,我们首先要把对象名存起来。进一步的,元数据中也包含了许多可以进行过略、排序用的信息,如对象大小、最后修改时间、上传时间、对象 Content-Type、自定义元数据等。其中自定义元数据中包含的 Key 的数目、value 类型都是可变的。为了方便存储和检索自定义元数据,不在每次想增加一个字段时都去修改数据库,我们首先就排除了传统的关系型数据库。
非关系型数据库(NoSQL)中,比较符合我们要求的是两款文档型数据库——MongoDB 与 Elasticsearch。从定位上来说,MongoDB 更偏向于数据库,可以用作数据管理和数据搜索; CSS 则偏向于数据搜索服务。具体到我们这个场景,从访问便捷度、最小规格价格几个维度对比,最终选择了选择 CSS 服务。下表为华为云上的 DDS、CSS、GaussDB for NoSQL 的对比,大家也可以根据自己具体场景选择合适的服务。

1.2 存储对象信息的整体流程
总的流程分 3 步:
1. 上传文件到对象存储
2. DWR 自动触发,保存需要的信息到 CSS
3. 通过 API、kibana 等方式检索 CSS 中存储的数据其中第二步还可以进行些进阶的操作,例如上传图片时,检测图片中的文字信息,一并存入数据库;上传视频时,检测把视频大小、码率、清晰度等信息抽取出来存入数据库…
二、购买与配置 CSS
2.1 购买 CSS
1.配置集群 控制台找到 CSS 服务,点击创建集群,集群版本选择了 7.10.2,在此我们先选择最低配的单节点。存储选了超高 IO。

2.配置网络 需要注意,安全组一定要允许 9200 端口,集群在创建后不支持修改安全组,只能删除重新创建。如果只是在 VPC 内网访问可以不开安全模式,要是想开放给公网访问就必须开启完全模式。

3.配置备份 建议开启下数据备份,OBS 本身价格也不贵,还可以通过转冷存储进一步降低成本,数据多一份保护,万一哪天误删了不用从头挨个列举。

4.完成配置 至此就完成了初始的配置,点击立即申请即开始创建集群。
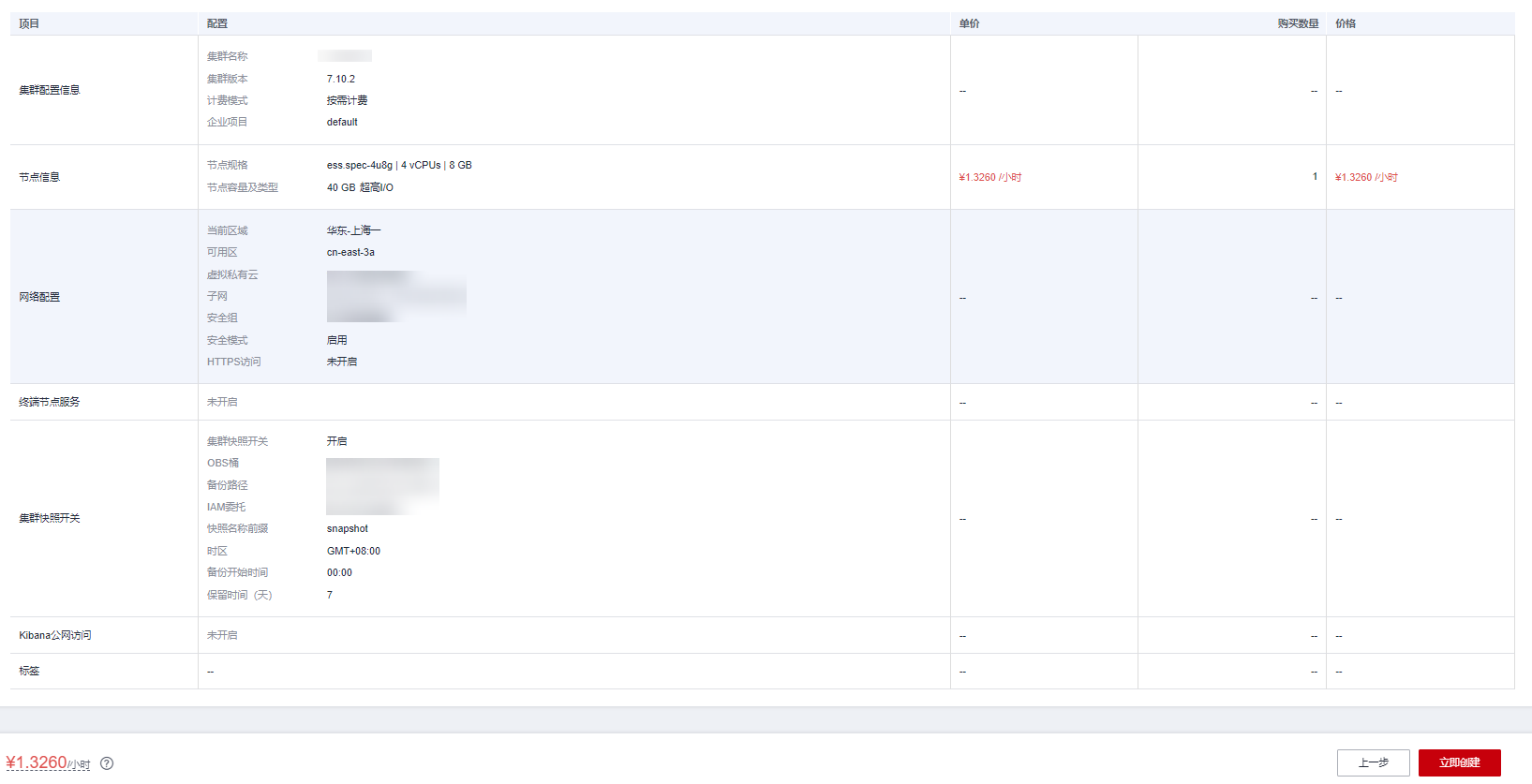
2.2 初始化 Mapping
ES 中的 Mapping 大致可以类比为数据库中的表结构,通过定义 mapping,可以指定字段的存储类型。我们目前需要的字段如下。可以使用 CSS 自带的 kibana 控制台创建 Mapping。
在 CSS 控制台找到 kibana,点击跳转后登录,侧边栏找到 Dev Tools

把下面的代码插入进去,点击运行,记得把 your-bucket-name 替换成你实际要用的桶名,需要自己在 OBS 手动创建桶
- PUT your-bucket-name
- {
- "mappings": {
- "dynamic": true,
- "properties": {
- "etag": {
- "type": "text"
- },
- "expiration": {
- "type": "text"
- },
- "content-type": {
- "type": "text"
- },
- "date": {
- "type": "text"
- },
- "content-length": {
- "type": "integer"
- },
- "bucket_name": {
- "type": "text"
- },
- "object_name": {
- "type": "text"
- },
- "create_time": {
- "type": "integer"
- }
- }
- }
- }
三、配置 DWR
数据工坊(Data Workroom,DWR)是一款近数据处理服务,下层调用了函数服务 FunctionGraph 的能力,自定义算子本质上就是 FunctionGraph 的一个函数,为了开发自定义算子,我们首先要在 FunctionGraph 上创建一个自定义函数并测试通过。
3.1 创建 FunctionGraph 函数
创建函数包含上传依赖包、创建函数、创建委托、测试函数几个步骤,都不复杂。
3.1.1 上传依赖包
本地 Python 操作 Elasticsearch 需要通过 pip 安装 Elasticsearch Python 依赖,相应的,我们在函数工作流中调用也需要添加对应的依赖包,我们需要安装7.10.1 版本的 elasticsearch 。
首先需要使用你对应 python 版本创建个新的虚拟环境,如果没有新建,而你本地已经有了部分依赖,会导致依赖包装不出来。
建议使用 Linux 环境打包依赖包,在 windows 环境下打包出的部分包可能不兼容 functionGraph 环境
- # 安装虚拟环境包,有的话可以跳过
- pip install virtualenv
- # 创建 python 3.9 的虚拟环境
- virtualenv fgpackage --python=3.9
- # Linux 激活虚拟环境
- source ./fgpackage/bin/activate
- # Windows 激活虚拟环境
- # .\fgpackage\Scripts\activate
- # 安装指定包到临时目录
- pip install elasticsearch==7.10.1 --root \tmp\fgpackage
经过上面的操作,把就elasticsearch 和它们需要的依赖安装到了 \tmp\fgpackage 下了。一层一层进入 \tmp\es_package,一直到 site-packages 一层,全选后添加到一个压缩包内。

在函数列表页点击函数-依赖包管理-添加依赖包

运行语言选 Python3.9,上传刚刚打包的压缩文件点击确定即可。

更多可参考 官方添加依赖说明
3.1.2 创建函数
控制台找到 FuntionGraph 服务,点击创建函数。

选择空白函数,运行时选择为 Python 3.9 (话说把 Runtime 翻译成运行时好奇怪,这种专有词是不是最好别强行翻译?);委托需要具有 VPC Administrator 与 Tenant Administrator 两个权限,用以访问其他云服务和 VPC 内网资源,如果有现成的可以直接选择,没有的话点击创建委托进入创建页,参考下一节进行创建,然后刷新下选择即可。

点击完成创建。
3.1.3 创建委托
委托需要有 VPC Administrator 与 Tenant Administrator 两个权限,如果已有可以直接跳过。上一节中的创建函数位置点击 创建委托 跳转到委托创建页,点击创建委托。

委托类型选择云服务
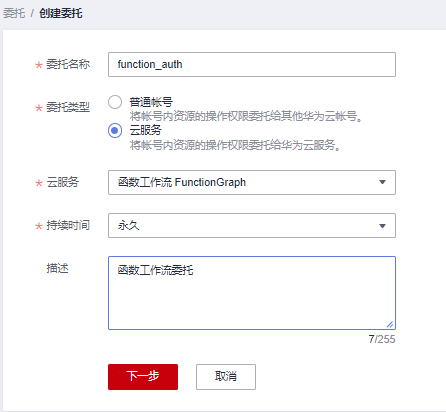
权限选择 VPC Administrator 与 Tenant Administrator 两个权限

授权范围选择所有资源,或跟你需要自己配置

点击完成即可。
3.1.4 填写代码
创建过函数后,会进入函数编辑页面,将下面的代码写到编辑器里,点击下部署,或键盘按 Ctrl + S 进行部署
- # -*- coding:utf-8 -*-
- import time
- from urllib.parse import unquote_plus
- from elasticsearch import Elasticsearch
- from obs import ObsClient
- def handler(event, context):
- # 获取桶名与对象名
- region_id, bucket_name, object_name = get_obs_obj_info(event.get("Records", None)[0])
- context.getLogger().info(f"bucket name: {bucket_name}, object key: {object_name}")
- ak = context.getAccessKey()
- sk = context.getSecretKey()
- server = 'obs.' + region_id + '.myhuaweicloud.com'
- context.getLogger().info("before token")
- context.getLogger().info(context.getToken())
- context.getLogger().info("finish token")
- obs_client = ObsClient(access_key_id=ak, secret_access_key=sk, server=server)
- # 获取对象元数据
- object_metadata = obs_client.getObjectMetadata(bucket_name, object_name)
- # 将头域转为字典
- info_dict = {i[0]: i[1] for i in object_metadata["header"]}
- info_dict["bucket_name"] = bucket_name
- info_dict["object_name"] = object_name
- # 为了不同系统下时区转换导致时间不统一,这里不使用 OBS 里的 last-modified 的 GMT 时间,改用时间戳
- info_dict["create_time"] = int(time.time())
- # 把对象大小转为数字格式
- info_dict["content-length"] = int(info_dict["content-length"])
- # 去除部分无用的 header
- for i in ["id-2", "request-id", "connection", "last-modified", "uploadid"]:
- if i in info_dict:
- info_dict.pop(i)
- # 把其他算子里包含的信息也一起保存下来
- if "other_info" in event["dynamic_source"]:
- info_dict.update(event["dynamic_source"]["other_info"])
- context.getLogger().info(f"metadata to save: {info_dict}")
- es_user = event["dynamic_source"]["es_user"]
- es_password = event["dynamic_source"]["es_password"]
- es_server_ip = event["dynamic_source"]["es_server"]
- es_port = event["dynamic_source"]["es_port"]
- context.getLogger().info(es_port)
- if es_user != "" and es_password != "":
- es_server = f"https://{es_user}:{es_password}@{es_server_ip}:{es_port}"
- context.getLogger().info(es_server.replace(es_password, "xxxxxxx"))
- else:
- es_server = f"http://{es_server_ip}:{es_port}"
- context.getLogger().info(es_server)
- es = Elasticsearch([es_server], ca_certs=False, verify_certs=False)
- response = es.index(index=bucket_name, body=info_dict)
- context.getLogger().info(response)
- return {
- "statusCode": 200,
- "isBase64Encoded": False,
- "body": response,
- "headers": {
- "Content-Type": "application/json"
- }
- }
- def get_obs_obj_info(record):
- if 's3' in record:
- s3 = record['s3']
- return record["eventRegion"], s3['bucket']['name'], unquote_plus(s3['object']['key'])
- else:
- obs_info = record['obs']
- return record["eventRegion"], obs_info['bucket']['name'], \
- unquote_plus(obs_info['object']['key'])
3.1.5 配置函数
1.配置依赖 在代码配置页最下找到添加依赖包按钮,分别添加公共依赖中的OBS 3.21.8 与 私有依赖中的fgpackage



2.配置 VPC 还是代码配置页,点击基本信息的编辑按钮,这里要记得与 2.1 节中的 CSS 选择同一个 VPC。


3.1.6 测试函数
在 OBS 里创建一个桶,最好和 CSS、FunctionGraph 都在同一个 Region,我用的上海一节点,region id 为 cn-east-3 桶内随便上传一个对象做备用。然后点击函数代码页中配置测试事件,把下面这段 Json 添加进去,并修改下面的配置为你的配置。其中 es_server 的值为 CSS 集群 IP。
- {
- "Records": [
- {
- "eventRegion": "cn-east-3",
- "obs": {
- "bucket": {
- "name": "your-bucket-name"
- },
- "object": {
- "key": "your-object-name"
- }
- }
- }
- ],
- "dynamic_source": {
- "es_server": "your-CSS-endpoint",
- "es_user": "admin",
- "es_password": "your-CSS-password",
- "es_port": 9200
- }
- }
保存后点击测试,如果一切配置正确,右边会出现这样的结果,如果提示执行失败,就看下下面报错,再找找前面几步哪个写错了。

3.2 配置 DWR 工作流
DWR 现在还在公测中,需要点击申请公测,信息随便填就可以,目测是自动审核的,点完申请就通知申请成功了。
进入页面,点击工作流选项-创建工作流

左侧把自定义算子拖到中间,和 Start、End 连上线,函数选择刚刚创建的函数,再填写下参数。这里的参数就是上一节 Json 文件里 dynamic_source 字段的参数即可。

点击保存,写上名字,会自动跳转出来,创建个触发器再

这里我没有写前缀和后缀,对桶内所有对象生效,如果填了前缀后缀,则会只匹配指定事件。
四、检索
到现在所有配置都完成了,使用 OBS Browser+ 向桶里上传几个测试文件,然后用自己熟悉 Elasticsearch 调用方法尝试下检索,我这里使用 CSS 自带的 kibana 控制台。

4.1 检索名字里包含测试 两个字的对象
测试代码:
- POST _search
- {
- "query": {
- "match": {
- "object_name": "测试"
- }
- }
- }

4.2 检索为 .mp4 结尾的对象
- POST _search
- {
- "query": {
- "regexp": {
- "object_name": ".*mp4"
- }
- }
- }

4.3 检索大小介于 100k 到 1M 的对象
- POST _search
- {
- "query": {
- "range": {
- "content-length": {
- "gt":"102400",
- "lt":"1048576"}
- }
- }
- }

4.4 检索创建时间在 2022 年 8 月 5 日与 2022 年 8 月 6 日之间的对象(时间戳)
- POST _search
- {
- "query": {
- "range": {
- "create_time": {
- "gt":"1659628800",
- "lt":"1659715200"}
- }
- }
- }

五、再进一步
有的同学可能注意到了,流程介绍时我提到可以进行进阶的操作,存入 CSS 的算子上头可以拼接很多其他算子,算子的代码包里也留了一个小扩展,可以从上一个算子中读取 other_info 并一起保存,这个能干点啥嘞。咱们举几个场景:
- 把对象名缩写存起来,如一个文件叫我的文件.txt,只用输入 wdwj 就能找到该文件的全称
- 图片文件上传后,调用 AI 给图片打个标签,把标签存到数据库,可以通过风景、美食、猫咪 等关键词检索到图片,现在华为鸿蒙、苹果 iOS 都有这样的功能
- 图片包含文字的话,把文字识别出来存入数据库,可以通过文字搜索图片,在某些业务系统里还可以用专用的算子,如发票识别、身份证识别等。
…
这里先把最简单的对象名缩写给个示例,抛砖引玉,大家可以自行尝试更多功能。
用了xpinyin 这个库,上传依赖包步骤参考前面的介绍。代码很简单:
- # coding:utf-8
- from urllib.parse import unquote_plus
- from xpinyin import Pinyin
- def handler(event, context):
- # 获取桶名与对象名
- _, _, object_name = get_obs_obj_info(event.get("Records", None)[0])
- context.getLogger().info(f"Object name is {object_name}")
- pinyin = Pinyin()
- pinyin = pinyin.get_pinyin(object_name, '-')
- short_pinyin = "".join([i[0] for i in pinyin.split("-") if i[0].isalpha()])
- if "other_info" in event["dynamic_source"]:
- event["dynamic_source"]["other_info"]["short_pinyin"] = short_pinyin
- else:
- event["dynamic_source"]["other_info"] = {"short_pinyin": short_pinyin}
- context.getLogger().info(f"Object short name is {short_pinyin}")
- context.getLogger().info(event)
- return event
- def get_obs_obj_info(record):
- if 's3' in record:
- s3 = record['s3']
- return record["eventRegion"], s3['bucket']['name'], unquote_plus(s3['object']['key'])
- else:
- obs_info = record['obs']
- return record["eventRegion"], obs_info['bucket']['name'], \
- unquote_plus(obs_info['object']['key'])
这就配置完了,只用去 DWR 工作流页面创建个工作流,把这个函数加载前面:
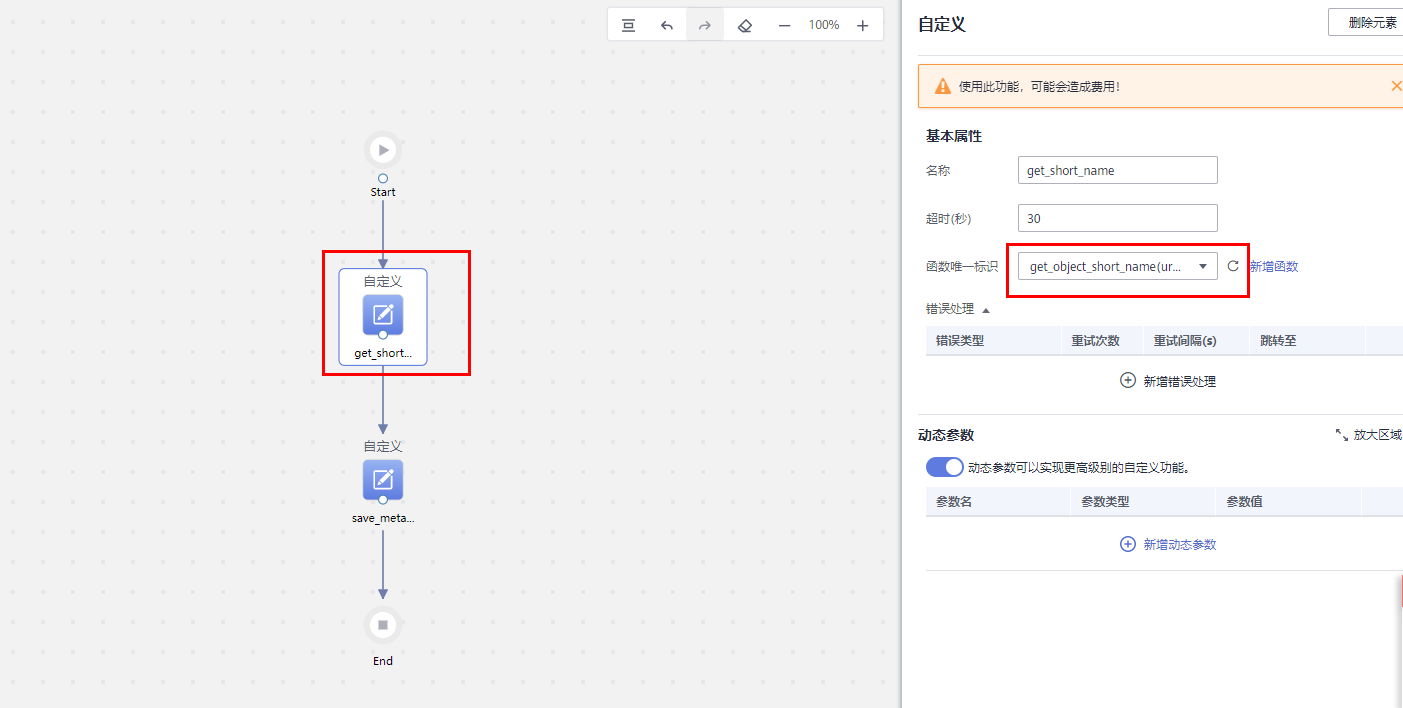
给工作流配置个触发器,然后把之前创建的工作流先删除掉,以免重复触发。再上传几个文件。
搜索下包含 cs 的对象
- POST _search
- {
- "query": {
- "regexp": {
- "short_pinyin": ".*cs.*"
- }
- }
- }

-
相关阅读:
Middleware ❀ Kafka功能与使用详解
jenkins调用metersphere自动化接口
MYSQL常见优化一
<九> objectARX开发:读写Excel、json与txt格式文件
Element+Vue+OpenLayers的项目实战
【slam十四讲第二版】【课本例题代码向】【第二讲初识SLAM】【SLAM基础知识】【linux下C++编译】【cmake基础使用】
秋日渲染季 | 效果图充值新升级!金秋好礼等你领
常见排序方法原理及C语言实现
elementui限制input输入框中小数点保留一位小数
PHP+防止SQL注入的网上二手交易平台 毕业设计-附源码241552
- 原文地址:https://blog.csdn.net/devcloud/article/details/127512423
