-
boost搜索引擎
1.项目背景
Boost是一个功能强大 , 构造精良 , 跨越平台 , 代码开源 , 完全免费的 C ++ 程序库。但是其主页并没有搜索功能,基于其开源的属性,我们可以为其建立一个搜索引擎。
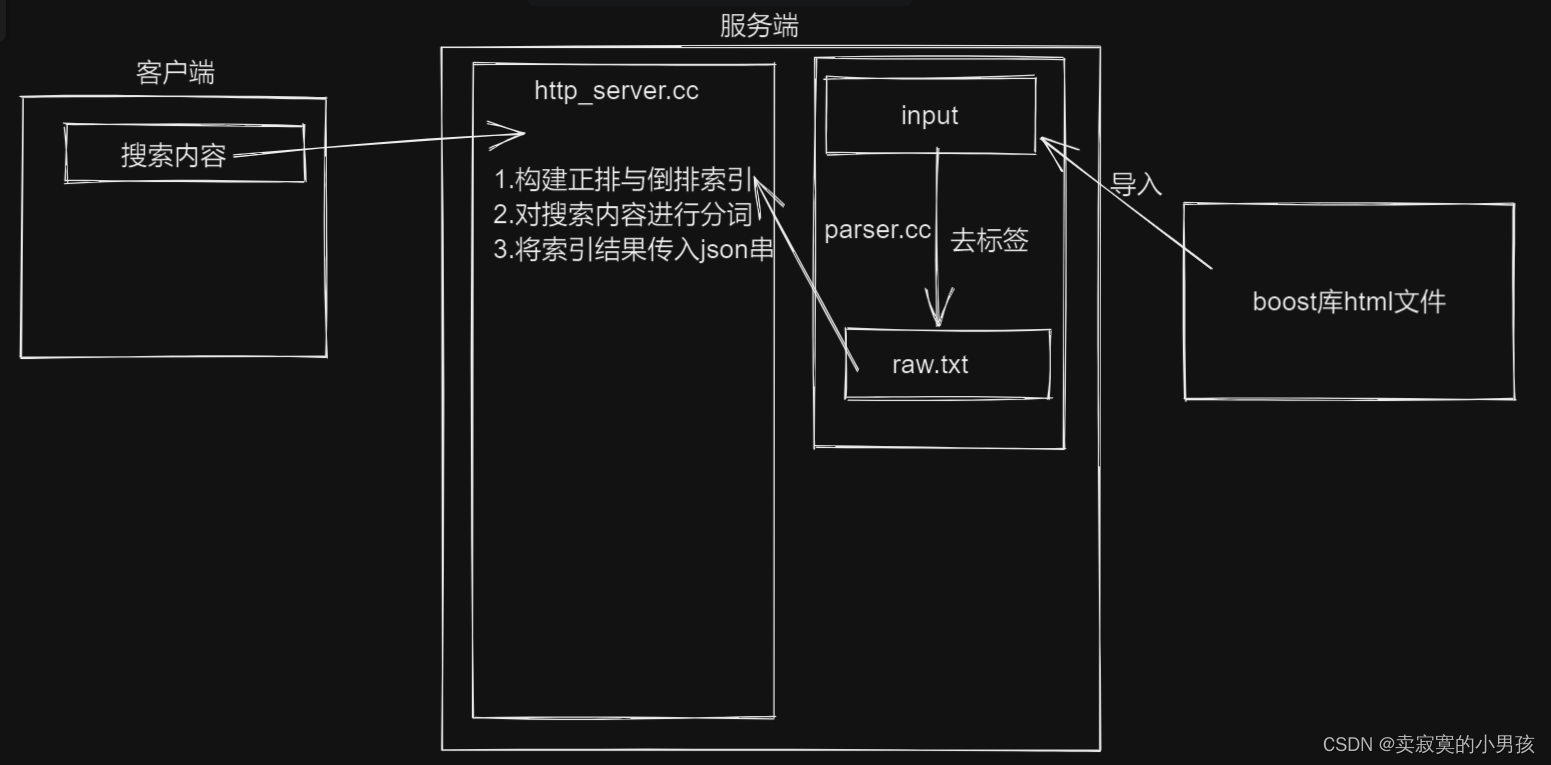
2.原理
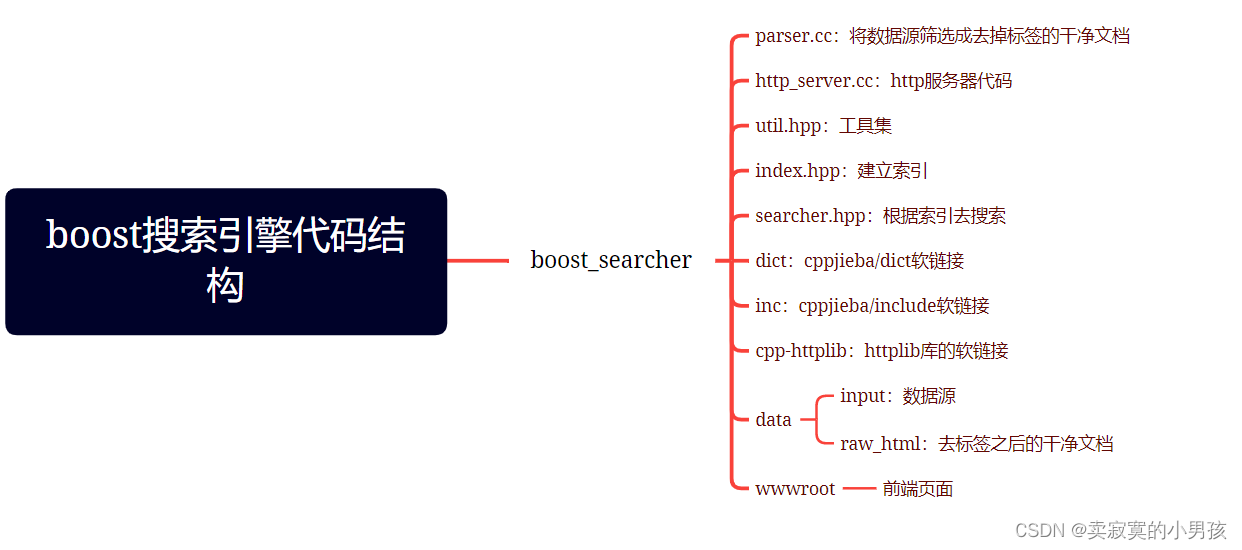
3.代码结构
4.编写思路
- 编写util.hpp文件,这是一个工具类,提供读文件,分词等操作。
- 编写parser.cc文件,将html去标签,保存在raw.txt中。
- 编写index.hpp文件,根据raw.txt中内容建立正排和倒排索引。
- 编写searcher.hpp文件,对搜索内容进行分词,并获得索引结果。
- 编写http_server.cc文件,实现网络通信。
5. util.hpp
5.1 作用
是一个工具类,是在编写项目代码的时候不断进行完善的。
5.2 类与方法说明
- FileUtil
ReadFile:读取文件path的内容,并将内容存放在字符串result中,成功返回true。
class FileUtil { public: static bool ReadFile(const std::string& path,std::string* result) { std::ifstream in(path,std::ios::in); if(!in.is_open()) { std::cerr<<"打开文件失败"<<std::endl; return false; } std::string out; while(getline(in,out)) { *result+=out; } in.close(); return true; } };- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- StringUtil
Split:调用boost库中切分字符串的函数,根据sep将字符串line切割成多个子串,并放入result中。
class StringUtil { public: static void Split(const std::string& line,std::vector<std::string>* results,const std::string& sep) { boost::split(*results,line,boost::is_any_of(sep),boost::token_compress_on); return; } };- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- JieBa
CutString:调用jieba库,进行字符串分割操作
const char *const DICT_PATH = "./dict/jieba.dict.utf8"; const char *const HMM_PATH = "./dict/hmm_model.utf8"; const char *const USER_DICT_PATH = "./dict/user.dict.utf8"; const char *const IDF_PATH = "./dict/idf.utf8"; const char *const STOP_WORD_PATH = "./dict/stop_words.utf8"; class JieBa { public: static cppjieba::Jieba jieba; static void CutString(const std::string& str,std::vector<std::string>* result) { jieba.CutForSearch(str,*result); } }; cppjieba::Jieba JieBa::jieba(DICT_PATH,HMM_PATH,USER_DICT_PATH,IDF_PATH,STOP_WORD_PATH);- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
其中我们使用的是jieba库中CutForSearch的方法。
6.parser.cc
6.1 作用
将读取所有html文件,依次对其进行去标签的操作,并写入raw.txt中。
6.2 类与方法说明
Enum_html:通过筛选的方式筛去非html文件,并将各个html文件依次读取到file_list数组中。//将所有html路径导入到files_list中 bool Enum_html(const std::string &path, std::vector<std::string> *files_list) { //定义一个路径对象,当路径不存在时返回false namespace fs = boost::filesystem; fs::path root_path(path); if (!fs::exists(root_path)) { std::cerr << "path doesn't exists!" << std::endl; return false; } //定义空迭代器end作为结束,定义迭代器it初始化为路径对象,此时它指向的是该路径的第一个元素(文件) fs::recursive_directory_iterator end; for (fs::recursive_directory_iterator it(root_path); it != end; it++)//定义一个目录迭代器,它会遍历目录下的所有目录 { if (!is_regular_file(*it)) //筛掉非普通文件 { continue; } if (it->path().extension() != ".html") //筛掉后缀不为html的文件 { continue; } //std::cout<<"debug "<path().string()< - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
ParserTitle:通过find方法解析单个文本的标题。bool ParserTitle(const std::string& result,std::string* title) { std::size_t begin=result.find(""</span><span class="token punctuation">)</span><span class="token punctuation">;</span> <span class="token keyword">if</span><span class="token punctuation">(</span>begin<span class="token operator">==</span>std<span class="token double-colon punctuation">::</span>string<span class="token double-colon punctuation">::</span>npos<span class="token punctuation">)</span> <span class="token punctuation">{<!-- --></span> std<span class="token double-colon punctuation">::</span>cerr<span class="token operator"><<</span><span class="token string">"can't find title's begin"</span><span class="token operator"><<</span>std<span class="token double-colon punctuation">::</span>endl<span class="token punctuation">;</span> <span class="token keyword">return</span> <span class="token boolean">false</span><span class="token punctuation">;</span> <span class="token punctuation">}</span> std<span class="token double-colon punctuation">::</span>size_t end<span class="token operator">=</span>result<span class="token punctuation">.</span><span class="token function">find</span><span class="token punctuation">(</span><span class="token string">" "); if(end==std::string::npos) { std::cerr<<"can't find title's end"<<std::endl; return false; } begin+=std::string(""</span><span class="token punctuation">)</span><span class="token punctuation">.</span><span class="token function">size</span><span class="token punctuation">(</span><span class="token punctuation">)</span><span class="token punctuation">;</span> <span class="token keyword">if</span><span class="token punctuation">(</span>begin<span class="token operator">></span>end<span class="token punctuation">)</span> <span class="token punctuation">{<!-- --></span> std<span class="token double-colon punctuation">::</span>cerr<span class="token operator"><<</span><span class="token string">"title's begin>end"</span><span class="token operator"><<</span>std<span class="token double-colon punctuation">::</span>endl<span class="token punctuation">;</span> <span class="token keyword">return</span> <span class="token boolean">false</span><span class="token punctuation">;</span> <span class="token punctuation">}</span> <span class="token operator">*</span>title<span class="token operator">=</span>result<span class="token punctuation">.</span><span class="token function">substr</span><span class="token punctuation">(</span>begin<span class="token punctuation">,</span>end<span class="token operator">-</span>begin<span class="token punctuation">)</span><span class="token punctuation">;</span> <span class="token comment">//std::cerr<<*title<<std::endl;</span> <span class="token keyword">return</span> <span class="token boolean">true</span><span class="token punctuation">;</span> <span class="token punctuation">}</span> <div class="hljs-button signin active" data-title="登录复制" data-report-click="{"spm":"1001.2101.3001.4334"}"></div></code><div class="hide-preCode-box"><span class="hide-preCode-bt" data-report-view="{"spm":"1001.2101.3001.7365"}"><img class="look-more-preCode contentImg-no-view" src="https://1000bd.com/contentImg/2022/06/27/192342369.png" alt="" title=""></span></div><ul class="pre-numbering" style="opacity: 0.269718;"><li style="color: rgb(153, 153, 153);">1</li><li style="color: rgb(153, 153, 153);">2</li><li style="color: rgb(153, 153, 153);">3</li><li style="color: rgb(153, 153, 153);">4</li><li style="color: rgb(153, 153, 153);">5</li><li style="color: rgb(153, 153, 153);">6</li><li style="color: rgb(153, 153, 153);">7</li><li style="color: rgb(153, 153, 153);">8</li><li style="color: rgb(153, 153, 153);">9</li><li style="color: rgb(153, 153, 153);">10</li><li style="color: rgb(153, 153, 153);">11</li><li style="color: rgb(153, 153, 153);">12</li><li style="color: rgb(153, 153, 153);">13</li><li style="color: rgb(153, 153, 153);">14</li><li style="color: rgb(153, 153, 153);">15</li><li style="color: rgb(153, 153, 153);">16</li><li style="color: rgb(153, 153, 153);">17</li><li style="color: rgb(153, 153, 153);">18</li><li style="color: rgb(153, 153, 153);">19</li><li style="color: rgb(153, 153, 153);">20</li><li style="color: rgb(153, 153, 153);">21</li><li style="color: rgb(153, 153, 153);">22</li><li style="color: rgb(153, 153, 153);">23</li><li style="color: rgb(153, 153, 153);">24</li></ul></pre> <p><code>ParserContent</code>:筛选出各个文本的内容,即去标签。</p> <pre data-index="5" class="set-code-hide prettyprint"><code class="prism language-cpp has-numbering" onclick="mdcp.signin(event)" style="position: unset;"><span class="token keyword">bool</span> <span class="token function">ParserContent</span><span class="token punctuation">(</span><span class="token keyword">const</span> std<span class="token double-colon punctuation">::</span>string<span class="token operator">&</span> result<span class="token punctuation">,</span>std<span class="token double-colon punctuation">::</span>string<span class="token operator">*</span> content<span class="token punctuation">)</span> <span class="token punctuation">{<!-- --></span> <span class="token keyword">enum</span> <span class="token class-name">status</span><span class="token comment">//定义一个状态机</span> <span class="token punctuation">{<!-- --></span> LABLE<span class="token punctuation">,</span> CONTENT <span class="token punctuation">}</span><span class="token punctuation">;</span> <span class="token keyword">enum</span> <span class="token class-name">status</span> st<span class="token operator">=</span>LABLE<span class="token punctuation">;</span> <span class="token keyword">for</span><span class="token punctuation">(</span><span class="token keyword">char</span> c<span class="token operator">:</span>result<span class="token punctuation">)</span> <span class="token punctuation">{<!-- --></span> <span class="token keyword">switch</span><span class="token punctuation">(</span>st<span class="token punctuation">)</span> <span class="token punctuation">{<!-- --></span> <span class="token keyword">case</span> LABLE<span class="token operator">:</span> <span class="token keyword">if</span><span class="token punctuation">(</span>c<span class="token operator">==</span><span class="token char">'>'</span><span class="token punctuation">)</span> <span class="token punctuation">{<!-- --></span> st<span class="token operator">=</span>CONTENT<span class="token punctuation">;</span> <span class="token punctuation">}</span> <span class="token keyword">break</span><span class="token punctuation">;</span> <span class="token keyword">case</span> CONTENT<span class="token operator">:</span> <span class="token keyword">if</span> <span class="token punctuation">(</span>c <span class="token operator">==</span> <span class="token char">'<'</span><span class="token punctuation">)</span> <span class="token punctuation">{<!-- --></span> st <span class="token operator">=</span> LABLE<span class="token punctuation">;</span> <span class="token punctuation">}</span> <span class="token keyword">else</span> <span class="token punctuation">{<!-- --></span> <span class="token keyword">if</span> <span class="token punctuation">(</span>c <span class="token operator">==</span> <span class="token char">'\n'</span><span class="token punctuation">)</span><span class="token comment">//不希望读入"\n"想将它作为文本的分隔符</span> <span class="token punctuation">{<!-- --></span> c <span class="token operator">=</span> <span class="token char">' '</span><span class="token punctuation">;</span> <span class="token punctuation">}</span> <span class="token operator">*</span>content <span class="token operator">+=</span> c<span class="token punctuation">;</span> <span class="token punctuation">}</span> <span class="token keyword">break</span><span class="token punctuation">;</span> <span class="token keyword">default</span><span class="token operator">:</span> <span class="token keyword">break</span><span class="token punctuation">;</span> <span class="token punctuation">}</span><span class="token punctuation">;</span> <span class="token punctuation">}</span> <span class="token comment">//std::cout<<*content<<std::endl;</span> <span class="token keyword">return</span> <span class="token boolean">true</span><span class="token punctuation">;</span> <span class="token punctuation">}</span> <div class="hljs-button signin active" data-title="登录复制" data-report-click="{"spm":"1001.2101.3001.4334"}"></div></code><div class="hide-preCode-box"><span class="hide-preCode-bt" data-report-view="{"spm":"1001.2101.3001.7365"}"><img class="look-more-preCode contentImg-no-view" src="https://1000bd.com/contentImg/2022/06/27/192342369.png" alt="" title=""></span></div><ul class="pre-numbering" style="opacity: 0.269718;"><li style="color: rgb(153, 153, 153);">1</li><li style="color: rgb(153, 153, 153);">2</li><li style="color: rgb(153, 153, 153);">3</li><li style="color: rgb(153, 153, 153);">4</li><li style="color: rgb(153, 153, 153);">5</li><li style="color: rgb(153, 153, 153);">6</li><li style="color: rgb(153, 153, 153);">7</li><li style="color: rgb(153, 153, 153);">8</li><li style="color: rgb(153, 153, 153);">9</li><li style="color: rgb(153, 153, 153);">10</li><li style="color: rgb(153, 153, 153);">11</li><li style="color: rgb(153, 153, 153);">12</li><li style="color: rgb(153, 153, 153);">13</li><li style="color: rgb(153, 153, 153);">14</li><li style="color: rgb(153, 153, 153);">15</li><li style="color: rgb(153, 153, 153);">16</li><li style="color: rgb(153, 153, 153);">17</li><li style="color: rgb(153, 153, 153);">18</li><li style="color: rgb(153, 153, 153);">19</li><li style="color: rgb(153, 153, 153);">20</li><li style="color: rgb(153, 153, 153);">21</li><li style="color: rgb(153, 153, 153);">22</li><li style="color: rgb(153, 153, 153);">23</li><li style="color: rgb(153, 153, 153);">24</li><li style="color: rgb(153, 153, 153);">25</li><li style="color: rgb(153, 153, 153);">26</li><li style="color: rgb(153, 153, 153);">27</li><li style="color: rgb(153, 153, 153);">28</li><li style="color: rgb(153, 153, 153);">29</li><li style="color: rgb(153, 153, 153);">30</li><li style="color: rgb(153, 153, 153);">31</li><li style="color: rgb(153, 153, 153);">32</li><li style="color: rgb(153, 153, 153);">33</li><li style="color: rgb(153, 153, 153);">34</li><li style="color: rgb(153, 153, 153);">35</li><li style="color: rgb(153, 153, 153);">36</li><li style="color: rgb(153, 153, 153);">37</li><li style="color: rgb(153, 153, 153);">38</li><li style="color: rgb(153, 153, 153);">39</li></ul></pre> <p><code>ParserUrl</code>:获取各个文本的url。</p> <pre data-index="6" class="set-code-show prettyprint"><code class="prism language-cpp has-numbering" onclick="mdcp.signin(event)" style="position: unset;"><span class="token keyword">bool</span> <span class="token function">ParserUrl</span><span class="token punctuation">(</span><span class="token keyword">const</span> std<span class="token double-colon punctuation">::</span>string<span class="token operator">&</span> file<span class="token punctuation">,</span>std<span class="token double-colon punctuation">::</span>string<span class="token operator">*</span> url<span class="token punctuation">)</span> <span class="token punctuation">{<!-- --></span> std<span class="token double-colon punctuation">::</span>string url_head <span class="token operator">=</span> <span class="token string">"https://www.boost.org/doc/libs/1_80_0/doc/html"</span><span class="token punctuation">;</span> std<span class="token double-colon punctuation">::</span>string url_tail<span class="token operator">=</span>file<span class="token punctuation">.</span><span class="token function">substr</span><span class="token punctuation">(</span>src<span class="token punctuation">.</span><span class="token function">size</span><span class="token punctuation">(</span><span class="token punctuation">)</span><span class="token punctuation">)</span><span class="token punctuation">;</span> <span class="token operator">*</span>url<span class="token operator">=</span>url_head<span class="token operator">+</span>url_tail<span class="token punctuation">;</span> <span class="token keyword">return</span> <span class="token boolean">true</span><span class="token punctuation">;</span> <span class="token punctuation">}</span> <div class="hljs-button signin active" data-title="登录复制" data-report-click="{"spm":"1001.2101.3001.4334"}"></div></code><ul class="pre-numbering" style="opacity: 0.269718;"><li style="color: rgb(153, 153, 153);">1</li><li style="color: rgb(153, 153, 153);">2</li><li style="color: rgb(153, 153, 153);">3</li><li style="color: rgb(153, 153, 153);">4</li><li style="color: rgb(153, 153, 153);">5</li><li style="color: rgb(153, 153, 153);">6</li><li style="color: rgb(153, 153, 153);">7</li></ul></pre> <p><code>Parse_html</code>:将每一个文本中标题,内容以及url信息存放在result数组中的每一个doc中。</p> <pre data-index="7" class="set-code-hide prettyprint"><code class="prism language-cpp has-numbering" onclick="mdcp.signin(event)" style="position: unset;"><span class="token keyword">bool</span> <span class="token function">Parse_html</span><span class="token punctuation">(</span><span class="token keyword">const</span> std<span class="token double-colon punctuation">::</span>vector<span class="token operator"><</span>std<span class="token double-colon punctuation">::</span>string<span class="token operator">></span> <span class="token operator">&</span>files_list<span class="token punctuation">,</span> std<span class="token double-colon punctuation">::</span>vector<span class="token operator"><</span>Doc<span class="token operator">></span> <span class="token operator">*</span>results<span class="token punctuation">)</span> <span class="token punctuation">{<!-- --></span> <span class="token keyword">for</span> <span class="token punctuation">(</span><span class="token keyword">auto</span> <span class="token operator">&</span>file<span class="token operator">:</span>files_list<span class="token punctuation">)</span> <span class="token punctuation">{<!-- --></span> std<span class="token double-colon punctuation">::</span>string result<span class="token punctuation">;</span> <span class="token keyword">if</span> <span class="token punctuation">(</span><span class="token operator">!</span>ns_util<span class="token double-colon punctuation">::</span><span class="token class-name">FileUtil</span><span class="token double-colon punctuation">::</span><span class="token function">ReadFile</span><span class="token punctuation">(</span>file<span class="token punctuation">,</span> <span class="token operator">&</span>result<span class="token punctuation">)</span><span class="token punctuation">)</span> <span class="token punctuation">{<!-- --></span> <span class="token keyword">continue</span><span class="token punctuation">;</span> <span class="token punctuation">}</span> Doc doc<span class="token punctuation">;</span> <span class="token keyword">if</span><span class="token punctuation">(</span><span class="token operator">!</span><span class="token function">ParserTitle</span><span class="token punctuation">(</span>result<span class="token punctuation">,</span><span class="token operator">&</span>doc<span class="token punctuation">.</span>title<span class="token punctuation">)</span><span class="token punctuation">)</span><span class="token comment">//提取一个file的标题</span> <span class="token punctuation">{<!-- --></span> <span class="token keyword">continue</span><span class="token punctuation">;</span> <span class="token punctuation">}</span> <span class="token keyword">if</span><span class="token punctuation">(</span><span class="token operator">!</span><span class="token function">ParserContent</span><span class="token punctuation">(</span>result<span class="token punctuation">,</span><span class="token operator">&</span>doc<span class="token punctuation">.</span>content<span class="token punctuation">)</span><span class="token punctuation">)</span><span class="token comment">//提取一个file的内容</span> <span class="token punctuation">{<!-- --></span> <span class="token keyword">continue</span><span class="token punctuation">;</span> <span class="token punctuation">}</span> <span class="token keyword">if</span><span class="token punctuation">(</span><span class="token operator">!</span><span class="token function">ParserUrl</span><span class="token punctuation">(</span>file<span class="token punctuation">,</span><span class="token operator">&</span>doc<span class="token punctuation">.</span>url<span class="token punctuation">)</span><span class="token punctuation">)</span><span class="token comment">//提取一个file的url</span> <span class="token punctuation">{<!-- --></span> <span class="token keyword">continue</span><span class="token punctuation">;</span> <span class="token punctuation">}</span> <span class="token comment">//std::cout<<"debug:success push"<<std::endl;</span> <span class="token comment">//std::cout<<doc.url<<std::endl;</span> results<span class="token operator">-></span><span class="token function">push_back</span><span class="token punctuation">(</span>std<span class="token double-colon punctuation">::</span><span class="token function">move</span><span class="token punctuation">(</span>doc<span class="token punctuation">)</span><span class="token punctuation">)</span><span class="token punctuation">;</span><span class="token comment">//移动构造提高效率</span> <span class="token punctuation">}</span> <span class="token keyword">return</span> <span class="token boolean">true</span><span class="token punctuation">;</span> <span class="token punctuation">}</span> <div class="hljs-button signin active" data-title="登录复制" data-report-click="{"spm":"1001.2101.3001.4334"}"></div></code><div class="hide-preCode-box"><span class="hide-preCode-bt" data-report-view="{"spm":"1001.2101.3001.7365"}"><img class="look-more-preCode contentImg-no-view" src="https://1000bd.com/contentImg/2022/06/27/192342369.png" alt="" title=""></span></div><ul class="pre-numbering" style="opacity: 0.269718;"><li style="color: rgb(153, 153, 153);">1</li><li style="color: rgb(153, 153, 153);">2</li><li style="color: rgb(153, 153, 153);">3</li><li style="color: rgb(153, 153, 153);">4</li><li style="color: rgb(153, 153, 153);">5</li><li style="color: rgb(153, 153, 153);">6</li><li style="color: rgb(153, 153, 153);">7</li><li style="color: rgb(153, 153, 153);">8</li><li style="color: rgb(153, 153, 153);">9</li><li style="color: rgb(153, 153, 153);">10</li><li style="color: rgb(153, 153, 153);">11</li><li style="color: rgb(153, 153, 153);">12</li><li style="color: rgb(153, 153, 153);">13</li><li style="color: rgb(153, 153, 153);">14</li><li style="color: rgb(153, 153, 153);">15</li><li style="color: rgb(153, 153, 153);">16</li><li style="color: rgb(153, 153, 153);">17</li><li style="color: rgb(153, 153, 153);">18</li><li style="color: rgb(153, 153, 153);">19</li><li style="color: rgb(153, 153, 153);">20</li><li style="color: rgb(153, 153, 153);">21</li><li style="color: rgb(153, 153, 153);">22</li><li style="color: rgb(153, 153, 153);">23</li><li style="color: rgb(153, 153, 153);">24</li><li style="color: rgb(153, 153, 153);">25</li><li style="color: rgb(153, 153, 153);">26</li><li style="color: rgb(153, 153, 153);">27</li><li style="color: rgb(153, 153, 153);">28</li></ul></pre> <p><code>Save_html</code>:解析doc中内容,将每一个html的数据写入到raw.txt的一行中。</p> <pre data-index="8" class="set-code-hide prettyprint"><code class="prism language-cpp has-numbering" onclick="mdcp.signin(event)" style="position: unset;"><span class="token keyword">bool</span> <span class="token function">Save_html</span><span class="token punctuation">(</span><span class="token keyword">const</span> std<span class="token double-colon punctuation">::</span>vector<span class="token operator"><</span>Doc<span class="token operator">></span> <span class="token operator">&</span>results<span class="token punctuation">,</span> <span class="token keyword">const</span> std<span class="token double-colon punctuation">::</span>string <span class="token operator">&</span>path<span class="token punctuation">)</span> <span class="token punctuation">{<!-- --></span> <span class="token macro property"><span class="token directive-hash">#</span><span class="token directive keyword">define</span> <span class="token macro-name">SEP</span> <span class="token char">'\3'</span></span> std<span class="token double-colon punctuation">::</span>ofstream <span class="token function">out</span><span class="token punctuation">(</span>path<span class="token punctuation">,</span>std<span class="token double-colon punctuation">::</span>ios<span class="token double-colon punctuation">::</span>out<span class="token operator">|</span>std<span class="token double-colon punctuation">::</span>ios<span class="token double-colon punctuation">::</span>binary<span class="token punctuation">)</span><span class="token punctuation">;</span> <span class="token keyword">if</span><span class="token punctuation">(</span><span class="token operator">!</span>out<span class="token punctuation">.</span><span class="token function">is_open</span><span class="token punctuation">(</span><span class="token punctuation">)</span><span class="token punctuation">)</span> <span class="token punctuation">{<!-- --></span> std<span class="token double-colon punctuation">::</span>cerr<span class="token operator"><<</span><span class="token string">"can't open dest file"</span><span class="token operator"><<</span>std<span class="token double-colon punctuation">::</span>endl<span class="token punctuation">;</span> <span class="token keyword">return</span> <span class="token boolean">false</span><span class="token punctuation">;</span> <span class="token punctuation">}</span> std<span class="token double-colon punctuation">::</span>string result<span class="token punctuation">;</span> <span class="token keyword">for</span><span class="token punctuation">(</span><span class="token keyword">auto</span><span class="token operator">&</span> res<span class="token operator">:</span>results<span class="token punctuation">)</span> <span class="token punctuation">{<!-- --></span> result<span class="token operator">+=</span>res<span class="token punctuation">.</span>title<span class="token punctuation">;</span> result<span class="token operator">+=</span>SEP<span class="token punctuation">;</span> result<span class="token operator">+=</span>res<span class="token punctuation">.</span>content<span class="token punctuation">;</span> result<span class="token operator">+=</span>SEP<span class="token punctuation">;</span> result<span class="token operator">+=</span>res<span class="token punctuation">.</span>url<span class="token punctuation">;</span> result<span class="token operator">+=</span><span class="token char">'\n'</span><span class="token punctuation">;</span> <span class="token punctuation">}</span> out<span class="token punctuation">.</span><span class="token function">write</span><span class="token punctuation">(</span>result<span class="token punctuation">.</span><span class="token function">c_str</span><span class="token punctuation">(</span><span class="token punctuation">)</span><span class="token punctuation">,</span>result<span class="token punctuation">.</span><span class="token function">size</span><span class="token punctuation">(</span><span class="token punctuation">)</span><span class="token punctuation">)</span><span class="token punctuation">;</span> out<span class="token punctuation">.</span><span class="token function">close</span><span class="token punctuation">(</span><span class="token punctuation">)</span><span class="token punctuation">;</span> <span class="token keyword">return</span> <span class="token boolean">true</span><span class="token punctuation">;</span> <span class="token punctuation">}</span> <div class="hljs-button signin active" data-title="登录复制" data-report-click="{"spm":"1001.2101.3001.4334"}"></div></code><div class="hide-preCode-box"><span class="hide-preCode-bt" data-report-view="{"spm":"1001.2101.3001.7365"}"><img class="look-more-preCode contentImg-no-view" src="https://1000bd.com/contentImg/2022/06/27/192342369.png" alt="" title=""></span></div><ul class="pre-numbering" style="opacity: 0.269718;"><li style="color: rgb(153, 153, 153);">1</li><li style="color: rgb(153, 153, 153);">2</li><li style="color: rgb(153, 153, 153);">3</li><li style="color: rgb(153, 153, 153);">4</li><li style="color: rgb(153, 153, 153);">5</li><li style="color: rgb(153, 153, 153);">6</li><li style="color: rgb(153, 153, 153);">7</li><li style="color: rgb(153, 153, 153);">8</li><li style="color: rgb(153, 153, 153);">9</li><li style="color: rgb(153, 153, 153);">10</li><li style="color: rgb(153, 153, 153);">11</li><li style="color: rgb(153, 153, 153);">12</li><li style="color: rgb(153, 153, 153);">13</li><li style="color: rgb(153, 153, 153);">14</li><li style="color: rgb(153, 153, 153);">15</li><li style="color: rgb(153, 153, 153);">16</li><li style="color: rgb(153, 153, 153);">17</li><li style="color: rgb(153, 153, 153);">18</li><li style="color: rgb(153, 153, 153);">19</li><li style="color: rgb(153, 153, 153);">20</li><li style="color: rgb(153, 153, 153);">21</li><li style="color: rgb(153, 153, 153);">22</li><li style="color: rgb(153, 153, 153);">23</li></ul></pre> <h2><a name="t11"></a><a id="7indexhpp_250"></a>7.index.hpp</h2> <h3><a name="t12"></a><a id="71__251"></a>7.1 作用</h3> <p>建立正排和倒排索引。</p> <h3><a name="t13"></a><a id="72__253"></a>7.2 正排和倒排索引原理</h3> <ul><li>正排索引:根据文档id找到文档内容。</li><li>倒排索引:根据关键字找到倒排拉链。</li></ul> <pre data-index="9" class="set-code-show prettyprint"><code class="prism language-cpp has-numbering" onclick="mdcp.signin(event)" style="position: unset;"> <span class="token comment">//正排索引</span> <span class="token keyword">struct</span> <span class="token class-name">DocInfo</span> <span class="token punctuation">{<!-- --></span> std<span class="token double-colon punctuation">::</span>string title<span class="token punctuation">;</span> std<span class="token double-colon punctuation">::</span>string content<span class="token punctuation">;</span> std<span class="token double-colon punctuation">::</span>string url<span class="token punctuation">;</span> <span class="token keyword">uint64_t</span> doc_id<span class="token punctuation">;</span> <span class="token punctuation">}</span><span class="token punctuation">;</span> <span class="token comment">//倒排索引</span> <span class="token keyword">struct</span> <span class="token class-name">InvertedElem</span> <span class="token punctuation">{<!-- --></span> <span class="token keyword">uint64_t</span> doc_id<span class="token punctuation">;</span> std<span class="token double-colon punctuation">::</span>string word<span class="token punctuation">;</span> <span class="token keyword">int</span> weight<span class="token punctuation">;</span> <span class="token punctuation">}</span><span class="token punctuation">;</span> <div class="hljs-button signin active" data-title="登录复制" data-report-click="{"spm":"1001.2101.3001.4334"}"></div></code><ul class="pre-numbering" style="opacity: 0.269718;"><li style="color: rgb(153, 153, 153);">1</li><li style="color: rgb(153, 153, 153);">2</li><li style="color: rgb(153, 153, 153);">3</li><li style="color: rgb(153, 153, 153);">4</li><li style="color: rgb(153, 153, 153);">5</li><li style="color: rgb(153, 153, 153);">6</li><li style="color: rgb(153, 153, 153);">7</li><li style="color: rgb(153, 153, 153);">8</li><li style="color: rgb(153, 153, 153);">9</li><li style="color: rgb(153, 153, 153);">10</li><li style="color: rgb(153, 153, 153);">11</li><li style="color: rgb(153, 153, 153);">12</li><li style="color: rgb(153, 153, 153);">13</li><li style="color: rgb(153, 153, 153);">14</li><li style="color: rgb(153, 153, 153);">15</li></ul></pre> <h3><a name="t14"></a><a id="73__274"></a>7.3 类与方法说明</h3> <ul><li>index<br> <code>BuildForwardIndexLine</code>:建立正排索引,传入raw.txt的每一行,根据分割符构建正排索引,并将构建出来的DocInfo使用forward_list管理起来,将对应的forward_list下标作为文档id,同时返回该正排索引结构,为构建倒排索引做准备。</li></ul> <pre data-index="10" class="set-code-hide prettyprint"><code class="prism language-cpp has-numbering" onclick="mdcp.signin(event)" style="position: unset;"> DocInfo <span class="token operator">*</span><span class="token function">BuildForwardIndexLine</span><span class="token punctuation">(</span><span class="token keyword">const</span> std<span class="token double-colon punctuation">::</span>string <span class="token operator">&</span>res<span class="token punctuation">)</span> <span class="token comment">//正排索引的构建</span> <span class="token punctuation">{<!-- --></span> <span class="token comment">//分割字符串</span> std<span class="token double-colon punctuation">::</span>vector<span class="token operator"><</span>std<span class="token double-colon punctuation">::</span>string<span class="token operator">></span> results<span class="token punctuation">;</span> std<span class="token double-colon punctuation">::</span>string sep <span class="token operator">=</span> <span class="token string">"\3"</span><span class="token punctuation">;</span> ns_util<span class="token double-colon punctuation">::</span><span class="token class-name">StringUtil</span><span class="token double-colon punctuation">::</span><span class="token function">Split</span><span class="token punctuation">(</span>res<span class="token punctuation">,</span> <span class="token operator">&</span>results<span class="token punctuation">,</span> sep<span class="token punctuation">)</span><span class="token punctuation">;</span> <span class="token keyword">if</span> <span class="token punctuation">(</span>results<span class="token punctuation">.</span><span class="token function">size</span><span class="token punctuation">(</span><span class="token punctuation">)</span> <span class="token operator">!=</span> <span class="token number">3</span><span class="token punctuation">)</span> <span class="token punctuation">{<!-- --></span> std<span class="token double-colon punctuation">::</span>cerr <span class="token operator"><<</span> <span class="token string">"failed to cut string"</span> <span class="token operator"><<</span> std<span class="token double-colon punctuation">::</span>endl<span class="token punctuation">;</span> <span class="token keyword">return</span> <span class="token keyword">nullptr</span><span class="token punctuation">;</span> <span class="token punctuation">}</span> <span class="token comment">//将分割后字符串写入doc中</span> DocInfo doc<span class="token punctuation">;</span> doc<span class="token punctuation">.</span>title <span class="token operator">=</span> results<span class="token punctuation">[</span><span class="token number">0</span><span class="token punctuation">]</span><span class="token punctuation">;</span> doc<span class="token punctuation">.</span>content <span class="token operator">=</span> results<span class="token punctuation">[</span><span class="token number">1</span><span class="token punctuation">]</span><span class="token punctuation">;</span> doc<span class="token punctuation">.</span>url <span class="token operator">=</span> results<span class="token punctuation">[</span><span class="token number">2</span><span class="token punctuation">]</span><span class="token punctuation">;</span> doc<span class="token punctuation">.</span>doc_id <span class="token operator">=</span> forward_index<span class="token punctuation">.</span><span class="token function">size</span><span class="token punctuation">(</span><span class="token punctuation">)</span><span class="token punctuation">;</span> <span class="token comment">//正排索引列表插入doc</span> forward_index<span class="token punctuation">.</span><span class="token function">push_back</span><span class="token punctuation">(</span>std<span class="token double-colon punctuation">::</span><span class="token function">move</span><span class="token punctuation">(</span>doc<span class="token punctuation">)</span><span class="token punctuation">)</span><span class="token punctuation">;</span> <span class="token keyword">return</span> <span class="token operator">&</span>forward_index<span class="token punctuation">.</span><span class="token function">back</span><span class="token punctuation">(</span><span class="token punctuation">)</span><span class="token punctuation">;</span> <span class="token punctuation">}</span> <div class="hljs-button signin active" data-title="登录复制" data-report-click="{"spm":"1001.2101.3001.4334"}"></div></code><div class="hide-preCode-box"><span class="hide-preCode-bt" data-report-view="{"spm":"1001.2101.3001.7365"}"><img class="look-more-preCode contentImg-no-view" src="https://1000bd.com/contentImg/2022/06/27/192342369.png" alt="" title=""></span></div><ul class="pre-numbering" style="opacity: 0.269718;"><li style="color: rgb(153, 153, 153);">1</li><li style="color: rgb(153, 153, 153);">2</li><li style="color: rgb(153, 153, 153);">3</li><li style="color: rgb(153, 153, 153);">4</li><li style="color: rgb(153, 153, 153);">5</li><li style="color: rgb(153, 153, 153);">6</li><li style="color: rgb(153, 153, 153);">7</li><li style="color: rgb(153, 153, 153);">8</li><li style="color: rgb(153, 153, 153);">9</li><li style="color: rgb(153, 153, 153);">10</li><li style="color: rgb(153, 153, 153);">11</li><li style="color: rgb(153, 153, 153);">12</li><li style="color: rgb(153, 153, 153);">13</li><li style="color: rgb(153, 153, 153);">14</li><li style="color: rgb(153, 153, 153);">15</li><li style="color: rgb(153, 153, 153);">16</li><li style="color: rgb(153, 153, 153);">17</li><li style="color: rgb(153, 153, 153);">18</li><li style="color: rgb(153, 153, 153);">19</li><li style="color: rgb(153, 153, 153);">20</li><li style="color: rgb(153, 153, 153);">21</li></ul></pre> <p><code>BuildInvertedIndex</code>:建立倒排索引,传入的是一个文档的正排索引</p> <ul><li>首先对标题进行分词,放在title_list中。</li><li>统计title_list中各个词的词频,将每个词放在word_map的first中,将词频放在word_map的second的title_cnt中。</li><li>对内容进行分词,放在content_list中。</li><li>统计content_list中各个词的词频,将每个词放在word_map的first中,将词频放在word_map的second的content_cnt中。</li><li>计算每一个词在该篇文章中所占的权重,并插入到该词对应的倒排拉链中。</li></ul> <pre data-index="11" class="set-code-hide prettyprint"><code class="prism language-cpp has-numbering" onclick="mdcp.signin(event)" style="position: unset;"> <span class="token keyword">void</span> <span class="token function">BuildInvertedIndex</span><span class="token punctuation">(</span><span class="token keyword">const</span> DocInfo <span class="token operator">&</span>doc<span class="token punctuation">)</span> <span class="token comment">//倒排索引的构建</span> <span class="token punctuation">{<!-- --></span> <span class="token comment">//分词</span> <span class="token comment">//统计词频</span> <span class="token comment">//插入</span> <span class="token comment">//通过正排索引的列表中元素构建倒排索引</span> <span class="token keyword">struct</span> <span class="token class-name">word_cnt</span> <span class="token punctuation">{<!-- --></span> <span class="token keyword">int</span> title_cnt<span class="token punctuation">;</span> <span class="token keyword">int</span> content_cnt<span class="token punctuation">;</span> <span class="token function">word_cnt</span><span class="token punctuation">(</span><span class="token punctuation">)</span> <span class="token operator">:</span> <span class="token function">title_cnt</span><span class="token punctuation">(</span><span class="token number">0</span><span class="token punctuation">)</span><span class="token punctuation">,</span> <span class="token function">content_cnt</span><span class="token punctuation">(</span><span class="token number">0</span><span class="token punctuation">)</span> <span class="token punctuation">{<!-- --></span> <span class="token punctuation">}</span> <span class="token punctuation">}</span><span class="token punctuation">;</span> <span class="token comment">//标题分词,放在title_list中</span> std<span class="token double-colon punctuation">::</span>vector<span class="token operator"><</span>std<span class="token double-colon punctuation">::</span>string<span class="token operator">></span> title_list<span class="token punctuation">;</span> std<span class="token double-colon punctuation">::</span>unordered_map<span class="token operator"><</span>std<span class="token double-colon punctuation">::</span>string<span class="token punctuation">,</span> word_cnt<span class="token operator">></span> word_map<span class="token punctuation">;</span> ns_util<span class="token double-colon punctuation">::</span><span class="token class-name">JieBa</span><span class="token double-colon punctuation">::</span><span class="token function">CutString</span><span class="token punctuation">(</span>doc<span class="token punctuation">.</span>title<span class="token punctuation">,</span> <span class="token operator">&</span>title_list<span class="token punctuation">)</span><span class="token punctuation">;</span> <span class="token comment">//为标题中每一个词统计词频,放在word_map的second的title_cnt</span> <span class="token keyword">for</span> <span class="token punctuation">(</span><span class="token keyword">auto</span> <span class="token operator">&</span>s <span class="token operator">:</span> title_list<span class="token punctuation">)</span> <span class="token punctuation">{<!-- --></span> boost<span class="token double-colon punctuation">::</span><span class="token function">to_lower</span><span class="token punctuation">(</span>s<span class="token punctuation">)</span><span class="token punctuation">;</span> <span class="token comment">//全部转换成小写</span> word_map<span class="token punctuation">[</span>s<span class="token punctuation">]</span><span class="token punctuation">.</span>title_cnt<span class="token operator">++</span><span class="token punctuation">;</span> <span class="token punctuation">}</span> <span class="token comment">//内容分词,放在content_list中</span> std<span class="token double-colon punctuation">::</span>vector<span class="token operator"><</span>std<span class="token double-colon punctuation">::</span>string<span class="token operator">></span> content_list<span class="token punctuation">;</span> ns_util<span class="token double-colon punctuation">::</span><span class="token class-name">JieBa</span><span class="token double-colon punctuation">::</span><span class="token function">CutString</span><span class="token punctuation">(</span>doc<span class="token punctuation">.</span>content<span class="token punctuation">,</span> <span class="token operator">&</span>content_list<span class="token punctuation">)</span><span class="token punctuation">;</span> <span class="token comment">//为内容中每一个词统计词频,并放在word_map的second的content_cnt中</span> <span class="token keyword">for</span> <span class="token punctuation">(</span><span class="token keyword">auto</span> <span class="token operator">&</span>s <span class="token operator">:</span> content_list<span class="token punctuation">)</span> <span class="token punctuation">{<!-- --></span> boost<span class="token double-colon punctuation">::</span><span class="token function">to_lower</span><span class="token punctuation">(</span>s<span class="token punctuation">)</span><span class="token punctuation">;</span> <span class="token comment">//全部转换成小写</span> word_map<span class="token punctuation">[</span>s<span class="token punctuation">]</span><span class="token punctuation">.</span>content_cnt<span class="token operator">++</span><span class="token punctuation">;</span> <span class="token punctuation">}</span> <span class="token comment">//构建倒排索引</span> <span class="token comment">//将word_map中的每一个词构建一个InvertedElem,计算该词在该篇文章中所占的权重,插入到该词对应的倒排拉链中</span> <span class="token keyword">for</span> <span class="token punctuation">(</span><span class="token keyword">auto</span> <span class="token operator">&</span>word_pair <span class="token operator">:</span> word_map<span class="token punctuation">)</span> <span class="token punctuation">{<!-- --></span> <span class="token macro property"><span class="token directive-hash">#</span><span class="token directive keyword">define</span> <span class="token macro-name">X</span> <span class="token expression"><span class="token number">10</span></span></span> <span class="token macro property"><span class="token directive-hash">#</span><span class="token directive keyword">define</span> <span class="token macro-name">Y</span> <span class="token expression"><span class="token number">1</span></span></span> InvertedElem inv<span class="token punctuation">;</span> inv<span class="token punctuation">.</span>doc_id <span class="token operator">=</span> doc<span class="token punctuation">.</span>doc_id<span class="token punctuation">;</span> inv<span class="token punctuation">.</span>word <span class="token operator">=</span> word_pair<span class="token punctuation">.</span>first<span class="token punctuation">;</span> inv<span class="token punctuation">.</span>weight <span class="token operator">=</span> X <span class="token operator">*</span> <span class="token punctuation">(</span>word_pair<span class="token punctuation">.</span>second<span class="token punctuation">.</span>title_cnt<span class="token punctuation">)</span> <span class="token operator">+</span> Y <span class="token operator">*</span> <span class="token punctuation">(</span>word_pair<span class="token punctuation">.</span>second<span class="token punctuation">.</span>content_cnt<span class="token punctuation">)</span><span class="token punctuation">;</span> inverted_index<span class="token punctuation">[</span>word_pair<span class="token punctuation">.</span>first<span class="token punctuation">]</span><span class="token punctuation">.</span><span class="token function">push_back</span><span class="token punctuation">(</span>std<span class="token double-colon punctuation">::</span><span class="token function">move</span><span class="token punctuation">(</span>inv<span class="token punctuation">)</span><span class="token punctuation">)</span><span class="token punctuation">;</span> <span class="token punctuation">}</span> <span class="token keyword">return</span><span class="token punctuation">;</span> <span class="token punctuation">}</span> <div class="hljs-button signin active" data-title="登录复制" data-report-click="{"spm":"1001.2101.3001.4334"}"></div></code><div class="hide-preCode-box"><span class="hide-preCode-bt" data-report-view="{"spm":"1001.2101.3001.7365"}"><img class="look-more-preCode contentImg-no-view" src="https://1000bd.com/contentImg/2022/06/27/192342369.png" alt="" title=""></span></div><ul class="pre-numbering" style="opacity: 0.269718;"><li style="color: rgb(153, 153, 153);">1</li><li style="color: rgb(153, 153, 153);">2</li><li style="color: rgb(153, 153, 153);">3</li><li style="color: rgb(153, 153, 153);">4</li><li style="color: rgb(153, 153, 153);">5</li><li style="color: rgb(153, 153, 153);">6</li><li style="color: rgb(153, 153, 153);">7</li><li style="color: rgb(153, 153, 153);">8</li><li style="color: rgb(153, 153, 153);">9</li><li style="color: rgb(153, 153, 153);">10</li><li style="color: rgb(153, 153, 153);">11</li><li style="color: rgb(153, 153, 153);">12</li><li style="color: rgb(153, 153, 153);">13</li><li style="color: rgb(153, 153, 153);">14</li><li style="color: rgb(153, 153, 153);">15</li><li style="color: rgb(153, 153, 153);">16</li><li style="color: rgb(153, 153, 153);">17</li><li style="color: rgb(153, 153, 153);">18</li><li style="color: rgb(153, 153, 153);">19</li><li style="color: rgb(153, 153, 153);">20</li><li style="color: rgb(153, 153, 153);">21</li><li style="color: rgb(153, 153, 153);">22</li><li style="color: rgb(153, 153, 153);">23</li><li style="color: rgb(153, 153, 153);">24</li><li style="color: rgb(153, 153, 153);">25</li><li style="color: rgb(153, 153, 153);">26</li><li style="color: rgb(153, 153, 153);">27</li><li style="color: rgb(153, 153, 153);">28</li><li style="color: rgb(153, 153, 153);">29</li><li style="color: rgb(153, 153, 153);">30</li><li style="color: rgb(153, 153, 153);">31</li><li style="color: rgb(153, 153, 153);">32</li><li style="color: rgb(153, 153, 153);">33</li><li style="color: rgb(153, 153, 153);">34</li><li style="color: rgb(153, 153, 153);">35</li><li style="color: rgb(153, 153, 153);">36</li><li style="color: rgb(153, 153, 153);">37</li><li style="color: rgb(153, 153, 153);">38</li><li style="color: rgb(153, 153, 153);">39</li><li style="color: rgb(153, 153, 153);">40</li><li style="color: rgb(153, 153, 153);">41</li><li style="color: rgb(153, 153, 153);">42</li><li style="color: rgb(153, 153, 153);">43</li><li style="color: rgb(153, 153, 153);">44</li><li style="color: rgb(153, 153, 153);">45</li><li style="color: rgb(153, 153, 153);">46</li><li style="color: rgb(153, 153, 153);">47</li></ul></pre> <p><code>GetForwardIndex</code>:通过文档编号,即正排索引数组forward_index的下标,获取正排索引。</p> <pre data-index="12" class="set-code-show prettyprint"><code class="prism language-cpp has-numbering" onclick="mdcp.signin(event)" style="position: unset;"> DocInfo <span class="token operator">*</span><span class="token function">GetForwardIndex</span><span class="token punctuation">(</span><span class="token keyword">uint64_t</span> doc_id<span class="token punctuation">)</span> <span class="token punctuation">{<!-- --></span> <span class="token keyword">if</span> <span class="token punctuation">(</span>doc_id <span class="token operator">>=</span> forward_index<span class="token punctuation">.</span><span class="token function">size</span><span class="token punctuation">(</span><span class="token punctuation">)</span><span class="token punctuation">)</span> <span class="token punctuation">{<!-- --></span> <span class="token keyword">return</span> <span class="token keyword">nullptr</span><span class="token punctuation">;</span> <span class="token punctuation">}</span> <span class="token keyword">return</span> <span class="token operator">&</span>forward_index<span class="token punctuation">[</span>doc_id<span class="token punctuation">]</span><span class="token punctuation">;</span> <span class="token punctuation">}</span> <div class="hljs-button signin active" data-title="登录复制" data-report-click="{"spm":"1001.2101.3001.4334"}"></div></code><ul class="pre-numbering" style="opacity: 0.269718;"><li style="color: rgb(153, 153, 153);">1</li><li style="color: rgb(153, 153, 153);">2</li><li style="color: rgb(153, 153, 153);">3</li><li style="color: rgb(153, 153, 153);">4</li><li style="color: rgb(153, 153, 153);">5</li><li style="color: rgb(153, 153, 153);">6</li><li style="color: rgb(153, 153, 153);">7</li><li style="color: rgb(153, 153, 153);">8</li></ul></pre> <p><code>GetInvertedList</code>:根据关键词获取该词的倒排拉链。</p> <pre data-index="13" class="set-code-show prettyprint"><code class="prism language-cpp has-numbering" onclick="mdcp.signin(event)" style="position: unset;"> InvertedList <span class="token operator">*</span><span class="token function">GetInvertedList</span><span class="token punctuation">(</span><span class="token keyword">const</span> std<span class="token double-colon punctuation">::</span>string <span class="token operator">&</span>word<span class="token punctuation">)</span> <span class="token punctuation">{<!-- --></span> <span class="token keyword">auto</span> it <span class="token operator">=</span> inverted_index<span class="token punctuation">.</span><span class="token function">find</span><span class="token punctuation">(</span>word<span class="token punctuation">)</span><span class="token punctuation">;</span> <span class="token keyword">if</span> <span class="token punctuation">(</span>it <span class="token operator">==</span> inverted_index<span class="token punctuation">.</span><span class="token function">end</span><span class="token punctuation">(</span><span class="token punctuation">)</span><span class="token punctuation">)</span> <span class="token punctuation">{<!-- --></span> std<span class="token double-colon punctuation">::</span>cerr <span class="token operator"><<</span> <span class="token string">"fail to find key word"</span> <span class="token operator"><<</span> std<span class="token double-colon punctuation">::</span>endl<span class="token punctuation">;</span> <span class="token keyword">return</span> <span class="token keyword">nullptr</span><span class="token punctuation">;</span> <span class="token punctuation">}</span> <span class="token keyword">return</span> <span class="token operator">&</span><span class="token punctuation">(</span>it<span class="token operator">-></span>second<span class="token punctuation">)</span><span class="token punctuation">;</span> <span class="token punctuation">}</span> <div class="hljs-button signin active" data-title="登录复制" data-report-click="{"spm":"1001.2101.3001.4334"}"></div></code><ul class="pre-numbering" style="opacity: 0.269718;"><li style="color: rgb(153, 153, 153);">1</li><li style="color: rgb(153, 153, 153);">2</li><li style="color: rgb(153, 153, 153);">3</li><li style="color: rgb(153, 153, 153);">4</li><li style="color: rgb(153, 153, 153);">5</li><li style="color: rgb(153, 153, 153);">6</li><li style="color: rgb(153, 153, 153);">7</li><li style="color: rgb(153, 153, 153);">8</li><li style="color: rgb(153, 153, 153);">9</li><li style="color: rgb(153, 153, 153);">10</li></ul></pre> <p><code>BuildIndex</code>:传入raw.txt文件,建立正排和倒排索引。</p> <pre data-index="14" class="set-code-hide prettyprint"><code class="prism language-cpp has-numbering" onclick="mdcp.signin(event)" style="position: unset;"> <span class="token comment">//根据去标签后的数据,构建正排和倒排索引</span> <span class="token keyword">bool</span> <span class="token function">BuildIndex</span><span class="token punctuation">(</span><span class="token keyword">const</span> std<span class="token double-colon punctuation">::</span>string <span class="token operator">&</span>input<span class="token punctuation">)</span> <span class="token punctuation">{<!-- --></span> std<span class="token double-colon punctuation">::</span>ifstream <span class="token function">in</span><span class="token punctuation">(</span>input<span class="token punctuation">,</span> std<span class="token double-colon punctuation">::</span>ios<span class="token double-colon punctuation">::</span>in <span class="token operator">|</span> std<span class="token double-colon punctuation">::</span>ios<span class="token double-colon punctuation">::</span>binary<span class="token punctuation">)</span><span class="token punctuation">;</span> <span class="token keyword">if</span> <span class="token punctuation">(</span><span class="token operator">!</span>in<span class="token punctuation">.</span><span class="token function">is_open</span><span class="token punctuation">(</span><span class="token punctuation">)</span><span class="token punctuation">)</span> <span class="token punctuation">{<!-- --></span> std<span class="token double-colon punctuation">::</span>cerr <span class="token operator"><<</span> <span class="token string">"fail to open raw.txt"</span> <span class="token operator"><<</span> std<span class="token double-colon punctuation">::</span>endl<span class="token punctuation">;</span> <span class="token keyword">return</span> <span class="token boolean">false</span><span class="token punctuation">;</span> <span class="token punctuation">}</span> std<span class="token double-colon punctuation">::</span>string res<span class="token punctuation">;</span> <span class="token keyword">int</span> count<span class="token operator">=</span><span class="token number">0</span><span class="token punctuation">;</span><span class="token comment">//用于监控处理文档的数量</span> <span class="token keyword">while</span> <span class="token punctuation">(</span><span class="token function">getline</span><span class="token punctuation">(</span>in<span class="token punctuation">,</span> res<span class="token punctuation">)</span><span class="token punctuation">)</span> <span class="token punctuation">{<!-- --></span> DocInfo <span class="token operator">*</span>doc <span class="token operator">=</span> <span class="token function">BuildForwardIndexLine</span><span class="token punctuation">(</span>res<span class="token punctuation">)</span><span class="token punctuation">;</span> <span class="token keyword">if</span> <span class="token punctuation">(</span>doc <span class="token operator">==</span> <span class="token keyword">nullptr</span><span class="token punctuation">)</span> <span class="token punctuation">{<!-- --></span> std<span class="token double-colon punctuation">::</span>cerr <span class="token operator"><<</span> <span class="token string">"fail to read a line from raw.txt"</span> <span class="token operator"><<</span> std<span class="token double-colon punctuation">::</span>endl<span class="token punctuation">;</span> <span class="token keyword">continue</span><span class="token punctuation">;</span> <span class="token punctuation">}</span> <span class="token function">BuildInvertedIndex</span><span class="token punctuation">(</span><span class="token operator">*</span>doc<span class="token punctuation">)</span><span class="token punctuation">;</span> count<span class="token operator">++</span><span class="token punctuation">;</span> <span class="token keyword">if</span><span class="token punctuation">(</span>count<span class="token operator">%</span><span class="token number">100</span><span class="token operator">==</span><span class="token number">0</span><span class="token punctuation">)</span> <span class="token punctuation">{<!-- --></span> <span class="token comment">// std::cout<<"当前已经处理的索引文档有:"<<count<<std::endl;</span> <span class="token function">LOG</span><span class="token punctuation">(</span>NORMAL<span class="token punctuation">,</span><span class="token string">"当前已经建立索引的文档"</span><span class="token operator">+</span>std<span class="token double-colon punctuation">::</span><span class="token function">to_string</span><span class="token punctuation">(</span>count<span class="token punctuation">)</span><span class="token punctuation">)</span><span class="token punctuation">;</span> <span class="token punctuation">}</span> <span class="token punctuation">}</span> std<span class="token double-colon punctuation">::</span>cout<span class="token operator"><<</span><span class="token string">"建立正排和倒排索引成功"</span><span class="token operator"><<</span>std<span class="token double-colon punctuation">::</span>endl<span class="token punctuation">;</span> in<span class="token punctuation">.</span><span class="token function">close</span><span class="token punctuation">(</span><span class="token punctuation">)</span><span class="token punctuation">;</span> <span class="token keyword">return</span> <span class="token boolean">true</span><span class="token punctuation">;</span> <span class="token punctuation">}</span> <div class="hljs-button signin active" data-title="登录复制" data-report-click="{"spm":"1001.2101.3001.4334"}"></div></code><div class="hide-preCode-box"><span class="hide-preCode-bt" data-report-view="{"spm":"1001.2101.3001.7365"}"><img class="look-more-preCode contentImg-no-view" src="https://1000bd.com/contentImg/2022/06/27/192342369.png" alt="" title=""></span></div><ul class="pre-numbering" style="opacity: 0.269718;"><li style="color: rgb(153, 153, 153);">1</li><li style="color: rgb(153, 153, 153);">2</li><li style="color: rgb(153, 153, 153);">3</li><li style="color: rgb(153, 153, 153);">4</li><li style="color: rgb(153, 153, 153);">5</li><li style="color: rgb(153, 153, 153);">6</li><li style="color: rgb(153, 153, 153);">7</li><li style="color: rgb(153, 153, 153);">8</li><li style="color: rgb(153, 153, 153);">9</li><li style="color: rgb(153, 153, 153);">10</li><li style="color: rgb(153, 153, 153);">11</li><li style="color: rgb(153, 153, 153);">12</li><li style="color: rgb(153, 153, 153);">13</li><li style="color: rgb(153, 153, 153);">14</li><li style="color: rgb(153, 153, 153);">15</li><li style="color: rgb(153, 153, 153);">16</li><li style="color: rgb(153, 153, 153);">17</li><li style="color: rgb(153, 153, 153);">18</li><li style="color: rgb(153, 153, 153);">19</li><li style="color: rgb(153, 153, 153);">20</li><li style="color: rgb(153, 153, 153);">21</li><li style="color: rgb(153, 153, 153);">22</li><li style="color: rgb(153, 153, 153);">23</li><li style="color: rgb(153, 153, 153);">24</li><li style="color: rgb(153, 153, 153);">25</li><li style="color: rgb(153, 153, 153);">26</li><li style="color: rgb(153, 153, 153);">27</li><li style="color: rgb(153, 153, 153);">28</li><li style="color: rgb(153, 153, 153);">29</li><li style="color: rgb(153, 153, 153);">30</li><li style="color: rgb(153, 153, 153);">31</li></ul></pre> <h2><a name="t15"></a><a id="8searcherhpp_413"></a>8.searcher.hpp</h2> <h3><a name="t16"></a><a id="81_414"></a>8.1作用</h3> <p>对搜索内容进行分词,根据分词找到倒排拉链,根据倒排拉链的节点中的文档id找到文档内容,并将文档内容都输入到json_string中。<br> 其中InvertedElemPrint的作用是去重。</p> <pre data-index="15" class="set-code-show prettyprint"><code class="prism language-cpp has-numbering" onclick="mdcp.signin(event)" style="position: unset;"> <span class="token keyword">struct</span> <span class="token class-name">InvertedElemPrint</span> <span class="token punctuation">{<!-- --></span> <span class="token keyword">uint64_t</span> doc_id<span class="token punctuation">;</span> <span class="token keyword">int</span> weight<span class="token punctuation">;</span> std<span class="token double-colon punctuation">::</span>vector<span class="token operator"><</span>std<span class="token double-colon punctuation">::</span>string<span class="token operator">></span> words<span class="token punctuation">;</span> <span class="token function">InvertedElemPrint</span><span class="token punctuation">(</span><span class="token punctuation">)</span><span class="token operator">:</span><span class="token function">doc_id</span><span class="token punctuation">(</span><span class="token number">0</span><span class="token punctuation">)</span><span class="token punctuation">,</span><span class="token function">weight</span><span class="token punctuation">(</span><span class="token number">0</span><span class="token punctuation">)</span> <span class="token punctuation">{<!-- --></span><span class="token punctuation">}</span> <span class="token punctuation">}</span><span class="token punctuation">;</span> <div class="hljs-button signin active" data-title="登录复制" data-report-click="{"spm":"1001.2101.3001.4334"}"></div></code><ul class="pre-numbering" style="opacity: 0.269718;"><li style="color: rgb(153, 153, 153);">1</li><li style="color: rgb(153, 153, 153);">2</li><li style="color: rgb(153, 153, 153);">3</li><li style="color: rgb(153, 153, 153);">4</li><li style="color: rgb(153, 153, 153);">5</li><li style="color: rgb(153, 153, 153);">6</li><li style="color: rgb(153, 153, 153);">7</li><li style="color: rgb(153, 153, 153);">8</li></ul></pre> <h3><a name="t17"></a><a id="82__427"></a>8.2 类与方法的说明</h3> <p><code>InitSearcher </code>:对所有文档建立索引。</p> <pre data-index="16" class="set-code-show prettyprint"><code class="prism language-cpp has-numbering" onclick="mdcp.signin(event)" style="position: unset;"><span class="token keyword">void</span> <span class="token function">InitSearcher</span><span class="token punctuation">(</span><span class="token keyword">const</span> std<span class="token double-colon punctuation">::</span>string <span class="token operator">&</span>input<span class="token punctuation">)</span> <span class="token punctuation">{<!-- --></span> <span class="token comment">//建立或者获取索引对象</span> <span class="token comment">//根据索引对象建立索引</span> index <span class="token operator">=</span> ns_index<span class="token double-colon punctuation">::</span>index<span class="token double-colon punctuation">::</span><span class="token function">Getinstance</span><span class="token punctuation">(</span><span class="token punctuation">)</span><span class="token punctuation">;</span> <span class="token function">LOG</span><span class="token punctuation">(</span>NOMAL<span class="token punctuation">,</span><span class="token string">"获取单例成功"</span><span class="token punctuation">)</span><span class="token punctuation">;</span> index<span class="token operator">-></span><span class="token function">BuildIndex</span><span class="token punctuation">(</span>input<span class="token punctuation">)</span><span class="token punctuation">;</span> <span class="token punctuation">}</span> <div class="hljs-button signin active" data-title="登录复制" data-report-click="{"spm":"1001.2101.3001.4334"}"></div></code><ul class="pre-numbering" style="opacity: 0.269718;"><li style="color: rgb(153, 153, 153);">1</li><li style="color: rgb(153, 153, 153);">2</li><li style="color: rgb(153, 153, 153);">3</li><li style="color: rgb(153, 153, 153);">4</li><li style="color: rgb(153, 153, 153);">5</li><li style="color: rgb(153, 153, 153);">6</li><li style="color: rgb(153, 153, 153);">7</li><li style="color: rgb(153, 153, 153);">8</li></ul></pre> <p><code>Search</code>:搜索并写入json串。</p> <ul><li>对query进行分词,并获取每一个词的倒排拉链。</li><li>使用unordered_map,第一个参数为文档id,第二个参数为struct InvertedElemPrint类型,对每一个倒排拉链中的节点进行文档id去重,将每一个倒排拉链节点导入到InvertedElemPrint对象中,并更新InvertedElemPrint对应的文档id的权值。</li><li>将每一个InvertedElemPrint对象插入到Inverted_all列表中,该列表中的元素的文档id就是我们要找到的文档,根据正排索引找到该文档的标题,内容以及url。</li></ul> <pre data-index="17" class="set-code-hide prettyprint"><code class="prism language-cpp has-numbering" onclick="mdcp.signin(event)" style="position: unset;"><span class="token keyword">void</span> <span class="token function">Search</span><span class="token punctuation">(</span><span class="token keyword">const</span> std<span class="token double-colon punctuation">::</span>string <span class="token operator">&</span>query<span class="token punctuation">,</span> std<span class="token double-colon punctuation">::</span>string <span class="token operator">*</span>json_string<span class="token punctuation">)</span> <span class="token punctuation">{<!-- --></span> <span class="token comment">//对query进行分词</span> <span class="token comment">//根据分出来的词进行查找</span> <span class="token comment">//对查找结果进行排序</span> <span class="token comment">//返回一个json串</span> <span class="token comment">//对query进行分词</span> std<span class="token double-colon punctuation">::</span>vector<span class="token operator"><</span>std<span class="token double-colon punctuation">::</span>string<span class="token operator">></span> words<span class="token punctuation">;</span> ns_util<span class="token double-colon punctuation">::</span><span class="token class-name">JieBa</span><span class="token double-colon punctuation">::</span><span class="token function">CutString</span><span class="token punctuation">(</span>query<span class="token punctuation">,</span> <span class="token operator">&</span>words<span class="token punctuation">)</span><span class="token punctuation">;</span> <span class="token comment">//将分词后的每个词的倒排拉链中的内容都保存在InvertedList_all中</span> <span class="token comment">//ns_index::InvertedList InvertedList_all;</span> std<span class="token double-colon punctuation">::</span>vector<span class="token operator"><</span>InvertedElemPrint<span class="token operator">></span> InvertedList_all<span class="token punctuation">;</span> std<span class="token double-colon punctuation">::</span>unordered_map<span class="token operator"><</span><span class="token keyword">uint64_t</span><span class="token punctuation">,</span>InvertedElemPrint<span class="token operator">></span> tokens_map<span class="token punctuation">;</span> <span class="token keyword">for</span> <span class="token punctuation">(</span><span class="token keyword">auto</span> <span class="token operator">&</span>word <span class="token operator">:</span> words<span class="token punctuation">)</span> <span class="token punctuation">{<!-- --></span> boost<span class="token double-colon punctuation">::</span><span class="token function">to_lower</span><span class="token punctuation">(</span>word<span class="token punctuation">)</span><span class="token punctuation">;</span> ns_index<span class="token double-colon punctuation">::</span>InvertedList <span class="token operator">*</span>invertedlist <span class="token operator">=</span> index<span class="token operator">-></span><span class="token function">GetInvertedList</span><span class="token punctuation">(</span>word<span class="token punctuation">)</span><span class="token punctuation">;</span> <span class="token keyword">if</span> <span class="token punctuation">(</span>invertedlist <span class="token operator">==</span> <span class="token keyword">nullptr</span><span class="token punctuation">)</span> <span class="token punctuation">{<!-- --></span> <span class="token keyword">continue</span><span class="token punctuation">;</span> <span class="token punctuation">}</span> <span class="token keyword">for</span> <span class="token punctuation">(</span><span class="token keyword">const</span> <span class="token keyword">auto</span> <span class="token operator">&</span>elem <span class="token operator">:</span> <span class="token operator">*</span>invertedlist<span class="token punctuation">)</span> <span class="token punctuation">{<!-- --></span> <span class="token keyword">auto</span><span class="token operator">&</span> item<span class="token operator">=</span>tokens_map<span class="token punctuation">[</span>elem<span class="token punctuation">.</span>doc_id<span class="token punctuation">]</span><span class="token punctuation">;</span> item<span class="token punctuation">.</span>doc_id <span class="token operator">=</span> elem<span class="token punctuation">.</span>doc_id<span class="token punctuation">;</span> item<span class="token punctuation">.</span>weight <span class="token operator">+=</span> elem<span class="token punctuation">.</span>weight<span class="token punctuation">;</span> item<span class="token punctuation">.</span>words<span class="token punctuation">.</span><span class="token function">push_back</span><span class="token punctuation">(</span>elem<span class="token punctuation">.</span>word<span class="token punctuation">)</span><span class="token punctuation">;</span> <span class="token punctuation">}</span> <span class="token comment">//InvertedList_all.insert(InvertedList_all.end(), invertedlist->begin(), invertedlist->end());</span> <span class="token punctuation">}</span> <span class="token keyword">for</span><span class="token punctuation">(</span><span class="token keyword">const</span> <span class="token keyword">auto</span><span class="token operator">&</span> item<span class="token operator">:</span>tokens_map<span class="token punctuation">)</span> <span class="token punctuation">{<!-- --></span> InvertedList_all<span class="token punctuation">.</span><span class="token function">push_back</span><span class="token punctuation">(</span>std<span class="token double-colon punctuation">::</span><span class="token function">move</span><span class="token punctuation">(</span>item<span class="token punctuation">.</span>second<span class="token punctuation">)</span><span class="token punctuation">)</span><span class="token punctuation">;</span> <span class="token punctuation">}</span> <span class="token comment">//对InvertedList_all中的每个InvertElem元素按权值进行排序</span> std<span class="token double-colon punctuation">::</span><span class="token function">sort</span><span class="token punctuation">(</span>InvertedList_all<span class="token punctuation">.</span><span class="token function">begin</span><span class="token punctuation">(</span><span class="token punctuation">)</span><span class="token punctuation">,</span> InvertedList_all<span class="token punctuation">.</span><span class="token function">end</span><span class="token punctuation">(</span><span class="token punctuation">)</span><span class="token punctuation">,</span> <span class="token punctuation">[</span><span class="token punctuation">]</span><span class="token punctuation">(</span><span class="token keyword">const</span> InvertedElemPrint <span class="token operator">&</span>e1<span class="token punctuation">,</span> <span class="token keyword">const</span> InvertedElemPrint <span class="token operator">&</span>e2<span class="token punctuation">)</span> <span class="token punctuation">{<!-- --></span> <span class="token keyword">return</span> e1<span class="token punctuation">.</span>weight <span class="token operator">></span> e2<span class="token punctuation">.</span>weight<span class="token punctuation">;</span> <span class="token punctuation">}</span><span class="token punctuation">)</span><span class="token punctuation">;</span> Json<span class="token double-colon punctuation">::</span>Value root<span class="token punctuation">;</span> <span class="token keyword">for</span> <span class="token punctuation">(</span><span class="token keyword">auto</span> <span class="token operator">&</span>e <span class="token operator">:</span> InvertedList_all<span class="token punctuation">)</span> <span class="token punctuation">{<!-- --></span> ns_index<span class="token double-colon punctuation">::</span>DocInfo <span class="token operator">*</span>doc <span class="token operator">=</span> index<span class="token operator">-></span><span class="token function">GetForwardIndex</span><span class="token punctuation">(</span>e<span class="token punctuation">.</span>doc_id<span class="token punctuation">)</span><span class="token punctuation">;</span> <span class="token keyword">if</span> <span class="token punctuation">(</span><span class="token keyword">nullptr</span> <span class="token operator">==</span> doc<span class="token punctuation">)</span> <span class="token punctuation">{<!-- --></span> <span class="token keyword">continue</span><span class="token punctuation">;</span> <span class="token punctuation">}</span> Json<span class="token double-colon punctuation">::</span>Value elem<span class="token punctuation">;</span> elem<span class="token punctuation">[</span><span class="token string">"title"</span><span class="token punctuation">]</span> <span class="token operator">=</span> doc<span class="token operator">-></span>title<span class="token punctuation">;</span> <span class="token comment">// elem["desc"] = doc->content;</span> elem<span class="token punctuation">[</span><span class="token string">"desc"</span><span class="token punctuation">]</span> <span class="token operator">=</span> <span class="token function">GetDesc</span><span class="token punctuation">(</span>doc<span class="token operator">-></span>content<span class="token punctuation">,</span> e<span class="token punctuation">.</span>words<span class="token punctuation">[</span><span class="token number">0</span><span class="token punctuation">]</span><span class="token punctuation">)</span><span class="token punctuation">;</span> <span class="token comment">//摘录内容,待处理</span> elem<span class="token punctuation">[</span><span class="token string">"url"</span><span class="token punctuation">]</span> <span class="token operator">=</span> doc<span class="token operator">-></span>url<span class="token punctuation">;</span> elem<span class="token punctuation">[</span><span class="token string">"id"</span><span class="token punctuation">]</span> <span class="token operator">=</span> <span class="token punctuation">(</span><span class="token keyword">int</span><span class="token punctuation">)</span>doc<span class="token operator">-></span>doc_id<span class="token punctuation">;</span> elem<span class="token punctuation">[</span><span class="token string">"weight"</span><span class="token punctuation">]</span> <span class="token operator">=</span> e<span class="token punctuation">.</span>weight<span class="token punctuation">;</span> root<span class="token punctuation">.</span><span class="token function">append</span><span class="token punctuation">(</span>elem<span class="token punctuation">)</span><span class="token punctuation">;</span> <span class="token punctuation">}</span> Json<span class="token double-colon punctuation">::</span>StyledWriter writer<span class="token punctuation">;</span> <span class="token operator">*</span>json_string <span class="token operator">=</span> writer<span class="token punctuation">.</span><span class="token function">write</span><span class="token punctuation">(</span>root<span class="token punctuation">)</span><span class="token punctuation">;</span> <span class="token punctuation">}</span> <div class="hljs-button signin active" data-title="登录复制" data-report-click="{"spm":"1001.2101.3001.4334"}"></div></code><div class="hide-preCode-box"><span class="hide-preCode-bt" data-report-view="{"spm":"1001.2101.3001.7365"}"><img class="look-more-preCode contentImg-no-view" src="https://1000bd.com/contentImg/2022/06/27/192342369.png" alt="" title=""></span></div><ul class="pre-numbering" style="opacity: 0.269718;"><li style="color: rgb(153, 153, 153);">1</li><li style="color: rgb(153, 153, 153);">2</li><li style="color: rgb(153, 153, 153);">3</li><li style="color: rgb(153, 153, 153);">4</li><li style="color: rgb(153, 153, 153);">5</li><li style="color: rgb(153, 153, 153);">6</li><li style="color: rgb(153, 153, 153);">7</li><li style="color: rgb(153, 153, 153);">8</li><li style="color: rgb(153, 153, 153);">9</li><li style="color: rgb(153, 153, 153);">10</li><li style="color: rgb(153, 153, 153);">11</li><li style="color: rgb(153, 153, 153);">12</li><li style="color: rgb(153, 153, 153);">13</li><li style="color: rgb(153, 153, 153);">14</li><li style="color: rgb(153, 153, 153);">15</li><li style="color: rgb(153, 153, 153);">16</li><li style="color: rgb(153, 153, 153);">17</li><li style="color: rgb(153, 153, 153);">18</li><li style="color: rgb(153, 153, 153);">19</li><li style="color: rgb(153, 153, 153);">20</li><li style="color: rgb(153, 153, 153);">21</li><li style="color: rgb(153, 153, 153);">22</li><li style="color: rgb(153, 153, 153);">23</li><li style="color: rgb(153, 153, 153);">24</li><li style="color: rgb(153, 153, 153);">25</li><li style="color: rgb(153, 153, 153);">26</li><li style="color: rgb(153, 153, 153);">27</li><li style="color: rgb(153, 153, 153);">28</li><li style="color: rgb(153, 153, 153);">29</li><li style="color: rgb(153, 153, 153);">30</li><li style="color: rgb(153, 153, 153);">31</li><li style="color: rgb(153, 153, 153);">32</li><li style="color: rgb(153, 153, 153);">33</li><li style="color: rgb(153, 153, 153);">34</li><li style="color: rgb(153, 153, 153);">35</li><li style="color: rgb(153, 153, 153);">36</li><li style="color: rgb(153, 153, 153);">37</li><li style="color: rgb(153, 153, 153);">38</li><li style="color: rgb(153, 153, 153);">39</li><li style="color: rgb(153, 153, 153);">40</li><li style="color: rgb(153, 153, 153);">41</li><li style="color: rgb(153, 153, 153);">42</li><li style="color: rgb(153, 153, 153);">43</li><li style="color: rgb(153, 153, 153);">44</li><li style="color: rgb(153, 153, 153);">45</li><li style="color: rgb(153, 153, 153);">46</li><li style="color: rgb(153, 153, 153);">47</li><li style="color: rgb(153, 153, 153);">48</li><li style="color: rgb(153, 153, 153);">49</li><li style="color: rgb(153, 153, 153);">50</li><li style="color: rgb(153, 153, 153);">51</li><li style="color: rgb(153, 153, 153);">52</li><li style="color: rgb(153, 153, 153);">53</li><li style="color: rgb(153, 153, 153);">54</li><li style="color: rgb(153, 153, 153);">55</li><li style="color: rgb(153, 153, 153);">56</li><li style="color: rgb(153, 153, 153);">57</li><li style="color: rgb(153, 153, 153);">58</li><li style="color: rgb(153, 153, 153);">59</li><li style="color: rgb(153, 153, 153);">60</li></ul></pre> <p><code>GetDesc</code>:获取文档内容的摘要,并处理查找中大小写问题。</p> <ul><li>传入的是该文档的word列表中的第一个word。</li><li>由于建立倒排拉链的时候就将索引都转化成了小写。所以上面对word进行了tolower操作,而find函数是不区分大小写的。</li><li>所以我们在查找该word的时候,也是要将文本中的大写的内容转化成小写来进行比较的,这就需要引入search函数。</li><li>获取关键字前100个,后200个字。</li></ul> <pre data-index="18" class="set-code-hide prettyprint"><code class="prism language-cpp has-numbering" onclick="mdcp.signin(event)" style="position: unset;"> std<span class="token double-colon punctuation">::</span>string <span class="token function">GetDesc</span><span class="token punctuation">(</span><span class="token keyword">const</span> std<span class="token double-colon punctuation">::</span>string <span class="token operator">&</span>content<span class="token punctuation">,</span> <span class="token keyword">const</span> std<span class="token double-colon punctuation">::</span>string <span class="token operator">&</span>word<span class="token punctuation">)</span> <span class="token punctuation">{<!-- --></span> <span class="token comment">//取关键字前50个和关键字后50个字节作为摘要</span> <span class="token comment">// int pos=content.find(word);//大小写问题需要进行处理</span> <span class="token keyword">auto</span> iter <span class="token operator">=</span> std<span class="token double-colon punctuation">::</span><span class="token function">search</span><span class="token punctuation">(</span>content<span class="token punctuation">.</span><span class="token function">begin</span><span class="token punctuation">(</span><span class="token punctuation">)</span><span class="token punctuation">,</span> content<span class="token punctuation">.</span><span class="token function">end</span><span class="token punctuation">(</span><span class="token punctuation">)</span><span class="token punctuation">,</span> word<span class="token punctuation">.</span><span class="token function">begin</span><span class="token punctuation">(</span><span class="token punctuation">)</span><span class="token punctuation">,</span> word<span class="token punctuation">.</span><span class="token function">end</span><span class="token punctuation">(</span><span class="token punctuation">)</span><span class="token punctuation">,</span> <span class="token punctuation">[</span><span class="token punctuation">]</span><span class="token punctuation">(</span><span class="token keyword">int</span> x<span class="token punctuation">,</span> <span class="token keyword">int</span> y<span class="token punctuation">)</span> <span class="token punctuation">{<!-- --></span> <span class="token keyword">return</span> <span class="token punctuation">(</span>std<span class="token double-colon punctuation">::</span><span class="token function">tolower</span><span class="token punctuation">(</span>x<span class="token punctuation">)</span> <span class="token operator">==</span> std<span class="token double-colon punctuation">::</span><span class="token function">tolower</span><span class="token punctuation">(</span>y<span class="token punctuation">)</span><span class="token punctuation">)</span><span class="token punctuation">;</span> <span class="token punctuation">}</span><span class="token punctuation">)</span><span class="token punctuation">;</span> <span class="token keyword">if</span> <span class="token punctuation">(</span>iter <span class="token operator">==</span> content<span class="token punctuation">.</span><span class="token function">end</span><span class="token punctuation">(</span><span class="token punctuation">)</span><span class="token punctuation">)</span> <span class="token punctuation">{<!-- --></span> <span class="token keyword">return</span> <span class="token string">"NONE"</span><span class="token punctuation">;</span> <span class="token punctuation">}</span> <span class="token keyword">int</span> pos <span class="token operator">=</span> std<span class="token double-colon punctuation">::</span><span class="token function">distance</span><span class="token punctuation">(</span>content<span class="token punctuation">.</span><span class="token function">begin</span><span class="token punctuation">(</span><span class="token punctuation">)</span><span class="token punctuation">,</span> iter<span class="token punctuation">)</span><span class="token punctuation">;</span> <span class="token comment">// if(pos==std::string::npos)</span> <span class="token comment">// {<!-- --></span> <span class="token comment">// return "NONE";</span> <span class="token comment">// }</span> <span class="token keyword">int</span> start <span class="token operator">=</span> <span class="token number">0</span><span class="token punctuation">;</span> <span class="token keyword">int</span> end <span class="token operator">=</span> content<span class="token punctuation">.</span><span class="token function">size</span><span class="token punctuation">(</span><span class="token punctuation">)</span> <span class="token operator">-</span> <span class="token number">1</span><span class="token punctuation">;</span> <span class="token keyword">if</span> <span class="token punctuation">(</span><span class="token punctuation">(</span>pos <span class="token operator">-</span> start<span class="token punctuation">)</span> <span class="token operator">>=</span> <span class="token number">100</span><span class="token punctuation">)</span> start <span class="token operator">=</span> pos <span class="token operator">-</span> start <span class="token operator">-</span> <span class="token number">100</span><span class="token punctuation">;</span> <span class="token keyword">if</span> <span class="token punctuation">(</span><span class="token punctuation">(</span>end <span class="token operator">-</span> pos<span class="token punctuation">)</span> <span class="token operator">>=</span> <span class="token number">200</span><span class="token punctuation">)</span> end <span class="token operator">=</span> pos <span class="token operator">+</span> <span class="token number">200</span><span class="token punctuation">;</span> <span class="token keyword">if</span> <span class="token punctuation">(</span>start <span class="token operator">></span> end<span class="token punctuation">)</span> <span class="token punctuation">{<!-- --></span> <span class="token keyword">return</span> <span class="token string">"Wrong"</span><span class="token punctuation">;</span> <span class="token punctuation">}</span> <span class="token keyword">return</span> content<span class="token punctuation">.</span><span class="token function">substr</span><span class="token punctuation">(</span>start<span class="token punctuation">,</span> end <span class="token operator">-</span> start<span class="token punctuation">)</span><span class="token punctuation">;</span> <span class="token punctuation">}</span> <div class="hljs-button signin active" data-title="登录复制" data-report-click="{"spm":"1001.2101.3001.4334"}"></div></code><div class="hide-preCode-box"><span class="hide-preCode-bt" data-report-view="{"spm":"1001.2101.3001.7365"}"><img class="look-more-preCode contentImg-no-view" src="https://1000bd.com/contentImg/2022/06/27/192342369.png" alt="" title=""></span></div><ul class="pre-numbering" style="opacity: 0.269718;"><li style="color: rgb(153, 153, 153);">1</li><li style="color: rgb(153, 153, 153);">2</li><li style="color: rgb(153, 153, 153);">3</li><li style="color: rgb(153, 153, 153);">4</li><li style="color: rgb(153, 153, 153);">5</li><li style="color: rgb(153, 153, 153);">6</li><li style="color: rgb(153, 153, 153);">7</li><li style="color: rgb(153, 153, 153);">8</li><li style="color: rgb(153, 153, 153);">9</li><li style="color: rgb(153, 153, 153);">10</li><li style="color: rgb(153, 153, 153);">11</li><li style="color: rgb(153, 153, 153);">12</li><li style="color: rgb(153, 153, 153);">13</li><li style="color: rgb(153, 153, 153);">14</li><li style="color: rgb(153, 153, 153);">15</li><li style="color: rgb(153, 153, 153);">16</li><li style="color: rgb(153, 153, 153);">17</li><li style="color: rgb(153, 153, 153);">18</li><li style="color: rgb(153, 153, 153);">19</li><li style="color: rgb(153, 153, 153);">20</li><li style="color: rgb(153, 153, 153);">21</li><li style="color: rgb(153, 153, 153);">22</li><li style="color: rgb(153, 153, 153);">23</li><li style="color: rgb(153, 153, 153);">24</li><li style="color: rgb(153, 153, 153);">25</li><li style="color: rgb(153, 153, 153);">26</li><li style="color: rgb(153, 153, 153);">27</li></ul></pre> <h2><a name="t18"></a><a id="9http_servercc_539"></a>9.http_server.cc</h2> <h3><a name="t19"></a><a id="91__540"></a>9.1 作用</h3> <p>使用httplib库来进行网络通信,只需要调用searcher中的initSearcher来建立索引,以及Search来查找关键字构建的json串即可。</p> <h3><a name="t20"></a><a id="92__542"></a>9.2 代码</h3> <pre data-index="19" class="set-code-hide prettyprint"><code class="prism language-cpp has-numbering" onclick="mdcp.signin(event)" style="position: unset;"> ns_searcher<span class="token double-colon punctuation">::</span>Searcher search<span class="token punctuation">;</span> search<span class="token punctuation">.</span><span class="token function">InitSearcher</span><span class="token punctuation">(</span>raw_path<span class="token punctuation">)</span><span class="token punctuation">;</span> httplib<span class="token double-colon punctuation">::</span>Server svr<span class="token punctuation">;</span> svr<span class="token punctuation">.</span><span class="token function">set_base_dir</span><span class="token punctuation">(</span>root_path<span class="token punctuation">.</span><span class="token function">c_str</span><span class="token punctuation">(</span><span class="token punctuation">)</span><span class="token punctuation">)</span><span class="token punctuation">;</span> svr<span class="token punctuation">.</span><span class="token function">Get</span><span class="token punctuation">(</span><span class="token string">"/s"</span><span class="token punctuation">,</span> <span class="token punctuation">[</span><span class="token operator">&</span>search<span class="token punctuation">]</span><span class="token punctuation">(</span><span class="token keyword">const</span> httplib<span class="token double-colon punctuation">::</span>Request <span class="token operator">&</span>req<span class="token punctuation">,</span> httplib<span class="token double-colon punctuation">::</span>Response <span class="token operator">&</span>res<span class="token punctuation">)</span> <span class="token punctuation">{<!-- --></span> <span class="token comment">//通过Request获得参数</span> <span class="token comment">//通过Reaponse构建响应</span> <span class="token comment">//res.set_content("hello world!","text/plain;charset=utf8");</span> <span class="token keyword">if</span><span class="token punctuation">(</span><span class="token operator">!</span>req<span class="token punctuation">.</span><span class="token function">has_param</span><span class="token punctuation">(</span><span class="token string">"word"</span><span class="token punctuation">)</span><span class="token punctuation">)</span> <span class="token punctuation">{<!-- --></span> res<span class="token punctuation">.</span><span class="token function">set_content</span><span class="token punctuation">(</span><span class="token string">"必须要有搜索关键字!"</span><span class="token punctuation">,</span><span class="token string">"text/plain;charset=utf-8"</span><span class="token punctuation">)</span><span class="token punctuation">;</span><span class="token comment">//设置响应界面</span> <span class="token keyword">return</span><span class="token punctuation">;</span> <span class="token punctuation">}</span> std<span class="token double-colon punctuation">::</span>string word<span class="token operator">=</span>req<span class="token punctuation">.</span><span class="token function">get_param_value</span><span class="token punctuation">(</span><span class="token string">"word"</span><span class="token punctuation">)</span><span class="token punctuation">;</span><span class="token comment">//获取搜索内容</span> std<span class="token double-colon punctuation">::</span>cout<span class="token operator"><<</span><span class="token string">"用户正在搜索"</span><span class="token operator"><<</span>word<span class="token operator"><<</span>std<span class="token double-colon punctuation">::</span>endl<span class="token punctuation">;</span> std<span class="token double-colon punctuation">::</span>string json_string<span class="token punctuation">;</span> search<span class="token punctuation">.</span><span class="token function">Search</span><span class="token punctuation">(</span>word<span class="token punctuation">,</span><span class="token operator">&</span>json_string<span class="token punctuation">)</span><span class="token punctuation">;</span> res<span class="token punctuation">.</span><span class="token function">set_content</span><span class="token punctuation">(</span>json_string<span class="token punctuation">,</span><span class="token string">"application/json"</span><span class="token punctuation">)</span><span class="token punctuation">;</span> <span class="token punctuation">}</span><span class="token punctuation">)</span><span class="token punctuation">;</span> svr<span class="token punctuation">.</span><span class="token function">listen</span><span class="token punctuation">(</span><span class="token string">"0.0.0.0"</span><span class="token punctuation">,</span><span class="token number">8081</span><span class="token punctuation">)</span><span class="token punctuation">;</span> <div class="hljs-button signin active" data-title="登录复制" data-report-click="{"spm":"1001.2101.3001.4334"}"></div></code><div class="hide-preCode-box"><span class="hide-preCode-bt" data-report-view="{"spm":"1001.2101.3001.7365"}"><img class="look-more-preCode contentImg-no-view" src="https://1000bd.com/contentImg/2022/06/27/192342369.png" alt="" title=""></span></div><ul class="pre-numbering" style="opacity: 0.269718;"><li style="color: rgb(153, 153, 153);">1</li><li style="color: rgb(153, 153, 153);">2</li><li style="color: rgb(153, 153, 153);">3</li><li style="color: rgb(153, 153, 153);">4</li><li style="color: rgb(153, 153, 153);">5</li><li style="color: rgb(153, 153, 153);">6</li><li style="color: rgb(153, 153, 153);">7</li><li style="color: rgb(153, 153, 153);">8</li><li style="color: rgb(153, 153, 153);">9</li><li style="color: rgb(153, 153, 153);">10</li><li style="color: rgb(153, 153, 153);">11</li><li style="color: rgb(153, 153, 153);">12</li><li style="color: rgb(153, 153, 153);">13</li><li style="color: rgb(153, 153, 153);">14</li><li style="color: rgb(153, 153, 153);">15</li><li style="color: rgb(153, 153, 153);">16</li><li style="color: rgb(153, 153, 153);">17</li><li style="color: rgb(153, 153, 153);">18</li><li style="color: rgb(153, 153, 153);">19</li><li style="color: rgb(153, 153, 153);">20</li></ul></pre> <h2><a name="t21"></a><a id="11_565"></a>11.遇到的问题</h2> <ul><li>不同的词可能对应相同的文档,使用unordered_map来进行去重操作。</li><li>在查找时,find函数不区分大小写,因此引入std中的search函数来进行查找。</li><li>在使用httplib库的时候要升级gcc</li></ul> <h2><a name="t22"></a><a id="12_569"></a>12.思考与改进</h2> <ul><li>boost搜索引擎,虽然叫boost但是其实任何一批网页,只要得到它的html文件,都可以来进行搜索。</li><li>后序可以再引入竞价排名等操作。</li><li>可以进行热词统计,智能显示搜索的关键词。</li><li>可以引入登录注册等操作,从而引入MySQL。</li></ul> <h2><a name="t23"></a><a id="13_574"></a>13.思维导图</h2> <p><img src="https://1000bd.com/contentImg/2024/05/24/55d2d504e5a85206.png" alt="在这里插入图片描述"></p> <h2><a name="t24"></a><a id="14_576"></a>14.项目地址</h2> <p>https://gitee.com/selling-lonely-little-boys/my-world/tree/master/boost_searcher</p> <h2><a name="t25"></a><a id="15_578"></a>15.项目描述</h2> <h3><a name="t26"></a><a id="1_579"></a>1.整体流程</h3> <p>首先用户向后端输入一个字符串,然后对这个字符串进行分词操作,获取每一个词的倒排拉链,并根据权重进行排序,然后通过倒排拉链进行正排索引找到文档内容,并返回给用户。</p> <h3><a name="t27"></a><a id="2_581"></a>2.建立正排索引的过程</h3> <p>从boost官网获取文档之后,将文档内容放在一个数组中,数组下标代表哪一个文档。</p> <h3><a name="t28"></a><a id="3_583"></a>3.建立倒排索引的过程</h3> <p>将所有文档进行分词操作,因为一个词可以在多个文档中,这些文档就构成了该词的倒排拉链,根据不同文档该词出现的频率进行排序。</p> <h3><a name="t29"></a><a id="4_585"></a>4.权重计算</h3> <p>获取所有词的倒排拉链之后,遍历这些倒排拉链,这样就获取到了所有要返回的文档了,文档的权重就是不同词在该文档的权重之和。然后对这些文档排序,返回给用户。</p> </div> </div> </li> <li class="list-group-item ul-li"> <b>相关阅读:</b><br> <nobr> <a href="/Article/Index/1273786">搞安全开发都是用什么编程语言?</a> <br /> <a href="/Article/Index/1312078">MySQL主从复制与读写分离(附配置实例)</a> <br /> <a href="/Article/Index/947766">HA: VEDAS靶机</a> <br /> <a href="/Article/Index/1286064">【PDF密码】PDF文件打开之后不能打印,怎么解决?</a> <br /> <a href="/Article/Index/684886">强化学习-学习笔记14 | 策略梯度中的 Baseline</a> <br /> <a href="/Article/Index/1343730">安装rockylinux 9.2 版本虚拟机</a> <br /> <a href="/Article/Index/855927">停车场管理系统</a> <br /> <a href="/Article/Index/958939">数据大屏指南 | 一屏看世界,一点选专业</a> <br /> <a href="/Article/Index/1468079">Halcon Solution Guide I basics(1): Guide to Halcon Methods(Halcon解决方案)</a> <br /> <a href="/Article/Index/877420">SSM项目 - Online Music Player(在线音乐播放器)- Java后端框架程序部分 -细节狂魔</a> <br /> </nobr> </li> <li class="list-group-item from-a mb-2"> 原文地址:https://blog.csdn.net/qq_51492202/article/details/127577435 </li> </ul> </div> <div class="col-lg-4 col-sm-12"> <ul class="list-group" style="word-break:break-all;"> <li class="list-group-item ul-li-bg" aria-current="true"> 最新文章 </li> <li class="list-group-item ul-li"> <nobr> <a href="/Article/Index/1906469">【JVM】编译执行与解释执行的区别是什么?JVM 使用哪种方式?</a> <br /> <a href="/Article/Index/1907193">用 Hashids 优雅解决 C 端自增 ID 暴露问题</a> <br /> <a href="/Article/Index/1907195">V8引擎 精品漫游指南--Ignition篇(上) 指令 栈帧 槽位 调用约定 内存布局 基础内容</a> <br /> <a href="/Article/Index/1907196">LLVM Pass快速入门(四):代码插桩</a> <br /> <a href="/Article/Index/1907197">milkup:桌面端 markdown AI续写和即时渲染</a> <br /> <a href="/Article/Index/1907198">基于项目工程构建SBOM(软件物料清单)的研究</a> <br /> <a href="/Article/Index/1907199">鸿蒙应用开发UI基础第二节:鸿蒙应用程序框架核心解析与实操</a> <br /> <a href="/Article/Index/1907200">.NET 中如何快速实现 List 集合去重?</a> <br /> <a href="/Article/Index/1907201">扣子Coze实战:从0到1打造抖音+小红书热点监控智能体</a> <br /> <a href="/Article/Index/1907202">浅谈数据访问层</a> <br /> </nobr> </li> </ul> <ul class="list-group pt-2" style="word-break:break-all;"> <li class="list-group-item ul-li-bg" aria-current="true"> 热门文章 </li> <li class="list-group-item ul-li"> <nobr> <a href="/Article/Index/888177">十款代码表白小特效 一个比一个浪漫 赶紧收藏起来吧!!!</a> <br /> <a href="/Article/Index/797680">奉劝各位学弟学妹们,该打造你的技术影响力了!</a> <br /> <a href="/Article/Index/888183">五年了,我在 CSDN 的两个一百万。</a> <br /> <a href="/Article/Index/888179">Java俄罗斯方块,老程序员花了一个周末,连接中学年代!</a> <br /> <a href="/Article/Index/797730">面试官都震惊,你这网络基础可以啊!</a> <br /> <a href="/Article/Index/797725">你真的会用百度吗?我不信 — 那些不为人知的搜索引擎语法</a> <br /> <a href="/Article/Index/797702">心情不好的时候,用 Python 画棵樱花树送给自己吧</a> <br /> <a href="/Article/Index/797709">通宵一晚做出来的一款类似CS的第一人称射击游戏Demo!原来做游戏也不是很难,连憨憨学妹都学会了!</a> <br /> <a href="/Article/Index/797716">13 万字 C 语言从入门到精通保姆级教程2021 年版</a> <br /> <a href="/Article/Index/888192">10行代码集2000张美女图,Python爬虫120例,再上征途</a> <br /> </nobr> </li> </ul> </div> </div> </div> <!-- 主体 --> <!--body结束--> <!--这里是footer模板--> <!--footer--> <nav class="navbar navbar-inverse navbar-fixed-bottom"> <div class="container"> <div class="row"> <div class="col-md-12 text-center"> <div style="padding:0px 5px;"> <a href="/tools">小工具</a> <a href="https://games.1000bd.com">小游戏</a> </div> <div class="text-muted center foot-height"> Copyright © 2022 侵权请联系<a href="mailto:2656653265@qq.com">2656653265@qq.com</a> <a href="https://beian.miit.gov.cn/" target="_blank">京ICP备2022015340号-1</a> </div> <div style=" padding:5px 0;"> <a target="_blank" href="http://www.beian.gov.cn/portal/registerSystemInfo?recordcode=11010502049817" style="display:inline-block;text-decoration:none;height:20px;line-height:20px;"> <img src="" style="float:left;" /><p style="float:left;height:20px;line-height:20px;margin: 0px 0px 0px 5px; color:#939393;">京公网安备 11010502049817号</p></a> </div> </div> </div> </div> </nav> <!--footer--> <!--footer模板结束--> <script src="/js/plugins/jquery/jquery.js"></script> <script src="/js/bootstrap.min.js"></script> <!--这里是scripts模板--> <!--scripts模板结束--> </body> </html>
