-
【Spark NLP】第 5 章:处理词
🔎大家好,我是Sonhhxg_柒,希望你看完之后,能对你有所帮助,不足请指正!共同学习交流🔎
📝个人主页-Sonhhxg_柒的博客_CSDN博客 📃
🎁欢迎各位→点赞👍 + 收藏⭐️ + 留言📝
📣系列专栏 - 机器学习【ML】 自然语言处理【NLP】 深度学习【DL】

🖍foreword
✔说明⇢本人讲解主要包括Python、机器学习(ML)、深度学习(DL)、自然语言处理(NLP)等内容。
如果你对这个系列感兴趣的话,可以关注订阅哟👋
文章目录
本章重点介绍可用于 NLP 入门的基本文字处理技术,包括标记化、词汇缩减、词袋和 N-gram。您可以使用这些技术以及一些基本的机器学习来解决许多任务。了解如何、何时以及为何使用这些技术将帮助您完成简单和复杂的 NLP 任务。这就是语言学技术的讨论涵盖实现的原因。我们现在将专注于使用英语,尽管我们会提到一些在使用其他语言时应该考虑的事情。我们专注于英语,因为很难在不同语言中深入介绍这些技术。
让我们再次从 mini_newsgroups 加载数据,然后我们将探索标记化。
- import os
- from pyspark.sql.types import *
- from pyspark.ml import Pipeline
- import sparknlp
- from sparknlp import DocumentAssembler, Finisher
- spark = sparknlp.start()
- space_path = os.path.join('data', 'mini_newsgroups', 'sci.space')
- texts = spark.sparkContext.wholeTextFiles(space_path)
- schema = StructType([
- StructField('path', StringType()),
- StructField('text', StringType()),
- ])
- texts = spark.createDataFrame(texts, schema=schema).persist()
- ## 摘自为示例而修改的迷你新闻组
- example = '''
- Nick's right about this. It's always easier to obtian forgiveness than
- permission. Not many poeple remember that Britan's Kng George III
- expressly forbade his american subjects to cross the alleghany/appalachian
- mountains. Said subjects basically said, "Stop us if you can." He
- couldn't.
- '''
- example = spark.createDataFrame([('.', example)], schema=schema).persist()
代币化(Tokenization)
来自文本和语音的语言数据是顺序数据。处理序列数据时,了解序列的组成至关重要。在磁盘和内存中,我们的文本数据是一个字节序列。我们使用 UTF-8 之类的编码将这些字节转换为字符。这是将我们的数据解释为语言的第一步。这几乎总是直截了当的,因为我们已经同意将字符编码为字节的标准。然而,将字节转换为字符并不足以获得我们想要的有用信息。接下来我们需要将我们的字符序列变成单词。这称为标记化。
尽管我们都直观地理解“词”是什么,但从语言上定义它却更加困难。识别一个词对人类来说很容易。让我们看一些例子:
- “monasticism”
- “globglobism”
- “xhbkgerj”
- “-ism”
说英语的人会认出例子 1 是一个单词,例子 2 是一个可能的单词,而例子 3 是一个不可能的单词;示例 4 更棘手。后缀“-ism”是我们附加在一个词上的东西,一个绑定的语素,但它已被用作未绑定的语素。确实,有些语言在写作中传统上没有单词界限,例如中文。所以,虽然我们可以在单独的时候识别出什么是词,什么不是词,但是在一个词的序列中定义什么是词,什么不是词就比较困难了。我们可以使用以下定义:如果将一个词素序列分开或将其与相邻的词素组合会改变句子的含义,那么它就是一个词。
在英语和其他在单词之间使用分隔符的语言中,通常使用正则表达式进行标记。让我们看一些例子。
- from pyspark.ml.feature import RegexTokenizer
- ws_tokenizer = RegexTokenizer()\
- .setInputCol('text')\
- .setOutputCol('ws_tokens')\
- .setPattern('\\s+')\
- .setGaps(True)\
- .setToLowercase(False)
- text, tokens = ws_tokenizer.transform(example)\
- .select("text", "ws_tokens").first()
- print(text)
- Nick's right about this. It's always easier to obtian forgiveness than
- permission. Not many poeple remember that Britan's Kng George III
- expressly forbade his American subjects to cross the alleghany/appalachian
- mountains. Said subjects basically said, "Stop us if you can." He
- couldn't.
print(tokens)- ["Nick's", 'right', 'about', 'this.', "It's", 'always', 'easier', 'to',
- 'obtian', 'forgiveness', 'than', 'permission.', 'Not', 'many', 'poeple',
- 'remember', 'that', "Britan's", 'Kng', 'George', 'III', 'expressly',
- 'forbade', 'his', 'American', 'subjects', 'to', 'cross', 'the',
- 'alleghany/appalachian', 'mountains.', 'Said', 'subjects', 'basically',
- 'said,', '"Stop', 'us', 'if', 'you', 'can."', 'He', "couldn't."]
这还有很多不足之处。我们可以看到我们有许多标记是带有一些标点符号的单词。让我们添加边界模式“\b”。
- b_tokenizer = RegexTokenizer()\
- .setInputCol('text')\
- .setOutputCol('b_tokens')\
- .setPattern('\\s+|\\b')\
- .setGaps(True)\
- .setToLowercase(False)
- text, tokens = b_tokenizer.transform(example)\
- .select("text", "b_tokens").first()
- print(text)
- Nick's right about this. It's always easier to obtian forgiveness than
- permission. Not many poeple remember that Britan's Kng George III
- expressly forbade his American subjects to cross the alleghany/appalachian
- mountains. Said subjects basically said, "Stop us if you can." He
- couldn't.
print(tokens)- ['Nick', "'", 's', 'right', 'about', 'this', '.', 'It', "'", 's',
- 'always', 'easier', 'to', 'obtian', 'forgiveness', 'than', 'permission',
- '.', 'Not', 'many', 'poeple', 'remember', 'that', 'Britan', "'", 's',
- 'Kng', 'George', 'III', 'expressly', 'forbade', 'his', 'American',
- 'subjects', 'to', 'cross', 'the', 'alleghany', '/', 'appalachian',
- 'mountains', '.', 'Said', 'subjects', 'basically', 'said', ',', '"',
- 'Stop', 'us', 'if', 'you', 'can', '."', 'He', 'couldn', "'", 't', '.']
我们将标点符号分开了,但现在所有的缩略词都被分解为三个标记——例如,“It's”变成了“It”、“'”、“s”。这不太理想。
在 Spark NLP 中,分词器比单个正则表达式更复杂。它采用以下参数(除了通常的输入和输出列名参数):
compositeTokens (复合令牌):这些是您可能不想拆分的多标记词(例如,“New York”)。
targetPattern (目标模式):这是定义候选标记的基本模式。
infixPatterns(中缀模式):这些是用于分离候选标记中的标记的模式。
prefixPattern(前缀模式):这是用于分离在候选标记开头找到的标记的模式。
suffixPattern(后缀模式):这是用于分隔在候选标记末尾找到的标记的模式。
该算法按以下步骤工作:
- 保护复合令牌。
- 创建候选令牌。
- 将前缀、中缀和后缀模式分开。
让我们看一个例子。
- from sparknlp.annotator import Tokenizer
- assembler = DocumentAssembler()\
- .setInputCol('text')\
- .setOutputCol('doc')
- tokenizer = Tokenizer()\
- .setInputCols(['doc'])\
- .setOutputCol('tokens_annotations')
- finisher = Finisher()\
- .setInputCols(['tokens_annotations'])\
- .setOutputCols(['tokens'])\
- .setOutputAsArray(True)
- pipeline = Pipeline()\
- .setStages([assembler, tokenizer, finisher])
- text, tokens = pipeline.fit(texts).transform(example)\
- .select("text", "tokens").first()
- print(text)
- Nick's right about this. It's always easier to obtian forgiveness than
- permission. Not many poeple remember that Britan's Kng George III
- expressly forbade his American subjects to cross the alleghany/appalachian
- mountains. Said subjects basically said, "Stop us if you can." He
- couldn't.
print(tokens)- ['Nick', "'s", 'right', 'about', 'this', '.', 'It', "'s", 'always',
- 'easier', 'to', 'obtian', 'forgiveness', 'than', 'permission', '.',
- 'Not', 'many', 'poeple', 'remember', 'that', 'Britan', "'s", 'Kng',
- 'George', 'III', 'expressly', 'forbade', 'his', 'American', 'subjects',
- 'to', 'cross', 'the', 'alleghany/appalachian', 'mountains', '.', 'Said',
- 'subjects', 'basically', 'said', ',', '"', 'Stop', 'us', 'if', 'you',
- 'can', '.', '"', 'He', 'could', "n't", '.']
在这里,我们看到标点符号被分离出来,而缩略词被分成两个标记。这与该词的直观定义非常吻合。
词汇减少
大多数 NLP 任务都涉及将文本转换为向量。最初,您的向量将具有与您的词汇量相等的维度。这样做的一个隐含假设是这些词是相互正交的。就词语而言,这意味着“猫”、“狗”和“狗”都被认为是同样不同的。我们想在一个向量空间中表示与它们的含义有某种关联的单词,但这更复杂。我们将在第10章和第11章中介绍这些表示. 然而,有更简单的方法来解决这个问题。如果我们知道两个词几乎相同,或者至少对于我们的目的是等价的,我们可以在向量中用相同的维度来表示它们。这将有助于分类、回归和搜索任务。那么我们该怎么做呢?我们可以使用我们的形态学知识(如何用较小的词和词缀构造词)。我们可以在构造向量之前删除词缀。执行此操作的两种主要技术是词干提取和词形还原。
词干
词干是去除词缀并留下词干的过程。这是根据确定要删除或替换哪些字符的规则集来完成的。首先词干提取算法是由 Julie Beth Lovins 在 1968 年创建的,尽管在这个主题上已经做了更早的工作。1980 年,Martin Porter 创建了 Porter Stemmer。这无疑是最著名的词干提取算法。他后来创建了一种特定领域的语言和相关工具,用于编写称为雪球的词干算法。尽管人们几乎总是使用预定义的词干分析器,但如果您发现有些词缀没有被删除但应该被删除,或者相反,请考虑编写或修改现有算法。
词形还原
词形还原是用它的词替换一个词的过程引理或词头。引理是具有完整字典条目的单词的形式。例如,如果您在字典中查找“oxen”,它可能会将您重定向到“ox”。从算法上讲,这很容易实现,但取决于您用于查找引理的数据。
词干化与词形还原
词干化和词形还原都有利有弊。
- 词干提取的优点是几乎不需要记忆,这与需要字典的词形还原不同。
- 词形还原通常更快,因为它只是一个哈希映射查找。
- 词干可以轻松调整,因为它基于算法而不是数据源。
- 词形还原返回一个实际的单词,这使得检查结果更容易。
您使用哪种方法取决于您的任务和资源限制。
在以下情况下使用词干:
- 您需要调整减少词汇量的程度。
- 您有严格的内存限制和更少的时间限制。
- 你期待许多新的或未知的词。
在以下情况下使用词形还原:
- 您需要向用户公开处理结果。
- 您的时间限制很紧,对内存的限制较少。
让我们看一些在 Spark NLP 中使用词干提取和词形还原的示例。
- from sparknlp.annotator import Stemmer, Lemmatizer, LemmatizerModel
- assembler = DocumentAssembler()\
- .setInputCol('text')\
- .setOutputCol('doc')
- tokenizer = Tokenizer()\
- .setInputCols(['doc'])\
- .setOutputCol('tokens_annotations')
- stemmer = Stemmer()\
- .setInputCols(['tokens_annotations'])\
- .setOutputCol('stems_annotations')
- # The next line downloads lemmatizer "model". Here, "training"
- # is reading the user supplied dictionary
- lemmatizer = LemmatizerModel.pretrained()\
- .setInputCols(['tokens_annotations'])\
- .setOutputCol('lemma_annotations')
- finisher = Finisher()\
- .setInputCols(['stems_annotations', 'lemma_annotations'])\
- .setOutputCols(['stems', 'lemmas'])\
- .setOutputAsArray(True)
- pipeline = Pipeline()\
- .setStages([
- assembler, tokenizer, stemmer, lemmatizer, finisher])
- text, stems, lemmas = pipeline.fit(texts).transform(example)\
- .select("text", "stems", "lemmas").first()
- print(text)
- Nick's right about this. It's always easier to obtian forgiveness than
- permission. Not many poeple remember that Britan's Kng George III
- expressly forbade his American subjects to cross the alleghany/appalachian
- mountains. Said subjects basically said, "Stop us if you can." He
- couldn't.
print(stems)- ['nick', "'", 'right', 'about', 'thi', '.', 'it', "'", 'alwai', 'easier',
- 'to', 'obtian', 'forgiv', 'than', 'permiss', '.', 'not', 'mani', 'poepl',
- 'rememb', 'that', 'britan', "'", 'kng', 'georg', 'iii', 'expressli',
- 'forbad', 'hi', 'american', 'subject', 'to', 'cross', 'the',
- 'alleghany/appalachian', 'mountain', '.', 'said', 'subject', 'basic',
- 'said', ',', '"', 'stop', 'u', 'if', 'you', 'can', '.', '"', 'he',
- 'could', "n't", '.']
print(lemmas)- ['Nick', 'have', 'right', 'about', 'this', '.', 'It', 'have', 'always',
- 'easy', 'to', 'obtian', 'forgiveness', 'than', 'permission', '.', 'Not',
- 'many', 'poeple', 'remember', 'that', 'Britan', 'have', 'Kng', 'George',
- 'III', 'expressly', 'forbid', 'he', 'American', 'subject', 'to', 'cross',
- 'the', 'alleghany/appalachian', 'mountain', '.', 'Said', 'subject',
- 'basically', 'say', ',', '"', 'Stop', 'we', 'if', 'you', 'can', '.', '"',
- 'He', 'could', 'not', '.']
一些需要注意的例子:
拼写更正
减少词汇量的一个经常被忽视的方面是拼写错误。在未经作者编辑或校对的文本中,这可能会产生很长的尾巴。更糟糕的是,有一些错误非常常见,以至于拼写错误实际上是一个比较常见的标记,这使得它很难删除。
Spark NLP 中有两种拼写纠正方法。SymmetricDelete需要一组正确的词来搜索。该词汇表可以作为字典提供,也可以通过提供受信任的语料库来提供。它基于 Wolf Garbe 的 SymSpell 项目。另一种方法是Norvig拼写校正算法,它通过创建一个简单的概率模型来工作。这种方法也需要一个正确的词汇表,但它会建议最可能的词——即可信语料库中最常见的词,与给定词有一定的编辑距离。
让我们看一下预训练的 Norvig 拼写校正。
- from sparknlp.annotator import NorvigSweetingModel
- from sparknlp.annotator import SymmetricDeleteModel
- # Norvig pretrained
- assembler = DocumentAssembler()\
- .setInputCol('text')\
- .setOutputCol('doc')
- tokenizer = Tokenizer()\
- .setInputCols(['doc'])\
- .setOutputCol('tokens_annotations')
- norvig_pretrained = NorvigSweetingModel.pretrained()\
- .setInputCols(['tokens_annotations'])\
- .setOutputCol('norvig_annotations')
- finisher = Finisher()\
- .setInputCols(['norvig_annotations'])\
- .setOutputCols(['norvig'])\
- .setOutputAsArray(True)
- pipeline = Pipeline()\
- .setStages([
- assembler, tokenizer, norvig_pretrained, lemmatizer, finisher])
- text, norvig = pipeline.fit(texts).transform(example)\
- .select("text", "norvig").first()
- print(text)
- Nick's right about this. It's always easier to obtian forgiveness than
- permission. Not many poeple remember that Britan's Kng George III
- expressly forbade his American subjects to cross the alleghany/appalachian
- mountains. Said subjects basically said, "Stop us if you can." He
- couldn't.
print(norvig)- ['Nick', "'s", 'right', 'about', 'this', '.', 'It', "'s", 'always',
- 'easier', 'to', 'obtain', 'forgiveness', 'than', 'permission', '.', 'Not',
- 'many', 'people', 'remember', 'that', 'Britain', "'s", 'Kng', 'George',
- 'III', 'expressly', 'forbade', 'his', 'American', 'subjects', 'to',
- 'cross', 'the', 'alleghany/appalachian', 'mountains', '.', 'Said',
- 'subjects', 'basically', 'said', ',', '"', 'Stop', 'us', 'if', 'you',
- 'can', '.', '"', 'He', 'could', "n't", '.']
我们看到“obtian”、“poeple”和“Britan”都被纠正了。然而,“Kng”被遗漏了,“american”被转换为“Americana”。后两个错误很可能是由于大小写造成的,这使得与概率模型的匹配更加困难。
正常化
这是一个更加基于启发式的清理步骤。如果您正在处理从网络上抓取的数据,那么留下 HTML 工件(标签、HTML 编码等)的情况并不少见。摆脱这些伪影可以大大减少你的词汇量。例如,如果您的任务不需要数字或任何非字母的,您也可以使用规范化来删除这些。
- from sparknlp.annotator import Normalizer
- assembler = DocumentAssembler()\
- .setInputCol('text')\
- .setOutputCol('doc')
- tokenizer = Tokenizer()\
- .setInputCols(['doc'])\
- .setOutputCol('tokens_annotations')
- norvig_pretrained = NorvigSweetingModel.pretrained()\
- .setInputCols(['tokens_annotations'])\
- .setOutputCol('norvig_annotations')
- lemmatizer = LemmatizerModel.pretrained()\
- .setInputCols(['norvig_annotations'])\
- .setOutputCol('lemma_annotations')
- normalizer = Normalizer()\
- .setInputCols(['lemma_annotations'])\
- .setOutputCol('normtoken_annotations')\
- .setLowercase(True)
- finisher = Finisher()\
- .setInputCols(['normtoken_annotations'])\
- .setOutputCols(['normtokens'])\
- .setOutputAsArray(True)
- sparknlp_pipeline = Pipeline().setStages([
- assembler, tokenizer, norvig_pretrained,
- lemmatizer, normalizer, finisher
- ])
- pipeline = Pipeline()\
- .setStages([
- assembler, tokenizer, norvig_pretrained,
- lemmatizer, normalizer, finisher])
- text, normalized = pipeline.fit(texts).transform(example)\
- .select("text", "normtokens").first()
- print(text)
- Nick's right about this. It's always easier to obtian forgiveness
- than permission. Not many poeple remember that Britan's Kng
- George III expressly forbade his american subjects to cross the
- alleghany/appalachian mountains. Said subjects basically said,
- "Stop us if you can." He couldn't.
print(normalized)- ['nicks', 'right', 'about', 'this', 'itys', 'always', 'easy', 'to',
- 'obtain', 'forgiveness', 'than', 'permission', 'not', 'many',
- 'people', 'remember', 'that', 'britans', 'kng', 'george', 'iii',
- 'expressly', 'forbid', 'he', 'americana', 'subject', 'to', 'cross',
- 'the', 'alleghanyappalachian', 'mountain', 'said', 'subject',
- 'basically', 'say', 'stop', 'we', 'if', 'you', 'can', 'he',
- 'couldnt']
词袋
现在我们通过组合相似和拼写错误的单词并删除 HTML 工件来减少词汇量,我们可以确信我们正在使用的词汇表是我们文档内容的真实反映。下一步是将这些词转换为我们模型的向量。有很多技术可以做到这一点,但我们将从最直接的方法开始,称为词袋。袋子(也称为多重集)是一个集合,其中每个元素都有一个计数。如果您熟悉 Python 集合
Counter,那么这是了解包是什么的好方法。因此,词袋是我们文档中单词的计数。一旦我们有了这些计数,我们通过将每个唯一的单词映射到一个索引来将它们变成一个向量。让我们看一个使用 Python 的简单示例
Counter。- text = "the cat in the hat"
- tokens = text.split()
- tokens
['the', 'cat', 'in', 'the', 'hat']- from collections import Counter
- counts = Counter(tokens)
- counts
Counter({'the': 2, 'cat': 1, 'in': 1, 'hat': 1})- index = {token: ix for ix, token in enumerate(counts.keys())}
- index
{'the': 0, 'cat': 1, 'in': 2, 'hat': 3}- import numpy as np
- vec = np.zeros(len(index))
- for token, count in counts.items():
- vec[index[token]] = count
- vec
array([2., 1., 1., 1.])我们的示例仅适用于一个文档。如果我们正在处理大型语料库,我们的索引将包含比我们预期在单个文档中找到的要多得多的单词。语料库词汇量达到数万或数十万的情况并不少见,即使单个文档通常具有数十到数百个独特的单词。出于这个原因,我们希望我们的向量是稀疏的。
稀疏向量是仅存储非零值的向量。稀疏向量通常实现为从索引到值的关联数组、映射或字典。对于像词袋这样的稀疏数据,这可以节省大量空间。但是,并非所有算法都以与稀疏向量兼容的方式实现。
CountVectorizer
- from pyspark.ml.feature import CountVectorizer
- assembler = DocumentAssembler()\
- .setInputCol('text')\
- .setOutputCol('doc')
- tokenizer = Tokenizer()\
- .setInputCols(['doc'])\
- .setOutputCol('tokens_annotations')
- norvig_pretrained = NorvigSweetingModel.pretrained()\
- .setInputCols(['tokens_annotations'])\
- .setOutputCol('norvig_annotations')
- lemmatizer = LemmatizerModel.pretrained()\
- .setInputCols(['norvig_annotations'])\
- .setOutputCol('lemma_annotations')
- normalizer = Normalizer()\
- .setInputCols(['lemma_annotations'])\
- .setOutputCol('normtoken_annotations')\
- .setLowercase(True)
- finisher = Finisher()\
- .setInputCols(['normtoken_annotations'])\
- .setOutputCols(['normtokens'])\
- .setOutputAsArray(True)
- sparknlp_pipeline = Pipeline().setStages([
- assembler, tokenizer, norvig_pretrained,
- lemmatizer, normalizer, finisher
- ])
- count_vectorizer = CountVectorizer()\
- .setInputCol('normtokens')\
- .setOutputCol('bows')
- pipeline = Pipeline().setStages([sparknlp_pipeline, count_vectorizer])
- model = pipeline.fit(texts)
- processed = model.transform(example)
- text, normtokens, bow = processed\
- .select("text", "normtokens", 'bows').first()
- print(text)
- Nick's right about this. It's always easier to obtian forgiveness than
- permission. Not many poeple remember that Britan's Kng George III
- expressly forbade his American subjects to cross the alleghany/appalachian
- mountains. Said subjects basically said, "Stop us if you can." He
- couldn't.
print(normtokens)- ['nick', 'have', 'right', 'about', 'this', 'it', 'have', 'always', 'easy',
- 'to', 'obtain', 'forgiveness', 'than', 'permission', 'not', 'many',
- 'people', 'remember', 'that', 'britain', 'have', 'kng', 'george', 'iii',
- 'expressly', 'forbid', 'he', 'american', 'subject', 'to', 'cross', 'the',
- 'alleghanyappalachian', 'mountain', 'said', 'subject', 'basically', 'say',
- 'stop', 'we', 'if', 'you', 'can', 'he', 'could', 'not']
让我们看看词袋。这将是一个稀疏向量,因此元素是词汇表的索引和出现次数。例如,
7: 3.0表示我们词汇表中的第七个单词在本文档中出现了 3 次。bow- SparseVector(5319, {0: 1.0, 3: 2.0, 7: 3.0, 9: 1.0, 10: 1.0, 14: 2.0, 15:
- 1.0, 17: 1.0, 28: 1.0, 30: 1.0, 31: 2.0, 37: 1.0, 52: 1.0, 67: 1.0, 79:
- 2.0, 81: 1.0, 128: 1.0, 150: 1.0, 182: 1.0, 214: 1.0, 339: 1.0, 369: 1.0,
- 439: 1.0, 459: 1.0, 649: 1.0, 822: 1.0, 953: 1.0, 1268: 1.0, 1348: 1.0,
- 1698: 1.0, 2122: 1.0, 2220: 1.0, 3149: 1.0, 3200: 1.0, 3203: 1.0, 3331:
- 1.0, 3611: 1.0, 4129: 1.0, 4840: 1.0})
我们可以从
CountVectorizerModel. 这是单词列表。在前面的示例中,我们说第七个单词在文档中出现了 3 次。查看这个词汇表,这意味着“拥有”出现了 3 次。- count_vectorizer_model = model.stages[-1]
- vocab = count_vectorizer_model.vocabulary
- print(vocab[:20])
- ['the', 'be', 'of', 'to', 'and', 'a', 'in', 'have', 'for', 'it', 'that',
- 'i', 'on', 'from', 'not', 'you', 'space', 'this', 'they', 'as']
这样做的缺点是我们失去了通过单词排列传达的意义——句法。说解析自然语言的语法很困难是轻描淡写的。幸运的是,我们通常不需要语法中编码的所有信息.
N-Gram
使用词袋的主要缺点是我们只使用编码在单个单词和文档范围上下文中的含义。语言也在当地环境中编码了大量的含义。语法很难建模,更不用说解析了。幸运的是,我们可以使用 N-gram 来提取一些上下文,而无需使用复杂的语法解析器。
N-gram,也称为shingles,是一串单词中长度为n的单词的子序列。它们允许我们从上下文的小窗口中提取信息。这为我们提供了可以从语法中收集到的信息的初步近似,因为尽管我们正在查看本地上下文,但仍显式提取了结构信息。在许多应用中,N-gram 足以提取必要的信息。
对于n的低值,有特殊名称。例如,1-gram 称为 unigram,2-gram 称为 bigram,3-gram 称为 trigram。对于高于 3 的值,它们通常称为“数字”+ 克,如 4 克。
让我们看一些示例 N-gram。
- text = "the quick brown fox jumped over the lazy dog"
- tokens = ["the", "quick", "brown", "fox", "jumped", "over", "the", "lazy", "dog"]
- unigrams = [('the',), ('quick',), ('brown',), ('fox',), ('jumped',), ('over',), ('the',), ('lazy',), ('dog',)]
- bigrams = [('the', 'quick'), ('quick', 'brown'), ('brown', 'fox'), ('fox', 'jumped'), ('jumped', 'over'), ('over', 'the'), ('the', 'lazy'), ('lazy', 'dog')]
- trigrams = [('the', 'quick', 'brown'), ('quick', 'brown', 'fox'), ('brown', 'fox', 'jumped'), ('fox', 'jumped', 'over'), ('jumped', 'over', 'the'), ('over', 'the', 'lazy'), ('the', 'lazy', 'dog')]
我们仍然需要确定我们的n。通常,n小于 4。考虑您认为对您的应用程序很重要的最大大小的多词短语。这通常取决于您的文档的长度以及语言的技术含量。在医院病历或技术性很强的长文档中,3、4 甚至 5 克可能很有用。对于带有非正式语言的推文或简短文档,二元组就足够了。
让我们看一些例子。
- from pyspark.ml.feature import NGram
- bigrams = NGram()\
- .setN(2)\
- .setInputCol("normtokens")\
- .setOutputCol("bigrams")
- trigrams = NGram()\
- .setN(3)\
- .setInputCol("normtokens")\
- .setOutputCol("trigrams")
- pipeline = Pipeline().setStages([sparknlp_pipeline, bigrams, trigrams])
- model = pipeline.fit(texts)
- processed = model.transform(example)
- text, normtokens, bigrams, trigrams = processed\
- .select("text", "normtokens", 'bigrams', 'trigrams').first()
- print(text)
- Nick's right about this. It's always easier to obtian forgiveness than
- permission. Not many poeple remember that Britan's Kng George III
- expressly forbade his American subjects to cross the alleghany/appalachian
- mountains. Said subjects basically said, "Stop us if you can." He
- couldn't.
print(normtokens)- ['nick', 'have', 'right', 'about', 'this', 'it', 'have', 'always', 'easy',
- 'to', 'obtain', 'forgiveness', 'than', 'permission', 'not', 'many',
- 'people', 'remember', 'that', 'britain', 'have', 'kng', 'george', 'iii',
- 'expressly', 'forbid', 'he', 'american', 'subject', 'to', 'cross', 'the',
- 'alleghanyappalachian', 'mountain', 'said', 'subject', 'basically', 'say',
- 'stop', 'we', 'if', 'you', 'can', 'he', 'could', 'not']
print(bigrams)- ['nick have', 'have right', 'right about', 'about this', 'this it',
- 'it have', 'have always', 'always easy', 'easy to', 'to obtain',
- 'obtain forgiveness', 'forgiveness than', 'than permission',
- 'permission not', 'not many', 'many people', 'people remember',
- 'remember that', 'that britain', 'britain have', 'have kng', 'kng george',
- 'george iii', 'iii expressly', 'expressly forbid', 'forbid he',
- 'he american', 'american subject', 'subject to', 'to cross', 'cross the',
- 'the alleghanyappalachian', 'alleghanyappalachian mountain',
- 'mountain said', 'said subject', 'subject basically', 'basically say',
- 'say stop', 'stop we', 'we if', 'if you', 'you can', 'can he', 'he could',
- 'could not']
print(trigrams)- ['nick have right', 'have right about', 'right about this',
- 'about this it', 'this it have', 'it have always', 'have always easy',
- 'always easy to', 'easy to obtain', 'to obtain forgiveness',
- 'obtain forgiveness than', 'forgiveness than permission',
- 'than permission not', 'permission not many', 'not many people',
- 'many people remember', 'people remember that', 'remember that britain',
- 'that britain have', 'britain have kng', 'have kng george',
- 'kng george iii', 'george iii expressly', 'iii expressly forbid',
- 'expressly forbid he', 'forbid he american', 'he american subject',
- 'american subject to', 'subject to cross', 'to cross the',
- 'cross the alleghanyappalachian', 'the alleghanyappalachian mountain',
- 'alleghanyappalachian mountain said', 'mountain said subject',
- 'said subject basically', 'subject basically say', 'basically say stop',
- 'say stop we', 'stop we if', 'we if you', 'if you can', 'you can he',
- 'can he could', 'he could not']
可视化:Word 和文档分布
现在我们已经学会了如何提取标记,我们可以看看如何可视化数据集。我们将看两个可视化:来自空间和汽车新闻组的词频和词云。它们代表相同的信息,但方式不同。
- from sparknlp.pretrained import PretrainedPipeline
- space_path = os.path.join('data', 'mini_newsgroups', 'sci.space')
- space = spark.sparkContext.wholeTextFiles(space_path)
- schema = StructType([
- StructField('path', StringType()),
- StructField('text', StringType()),
- ])
- space = spark.createDataFrame(space, schema=schema).persist()
- sparknlp_pipeline = PretrainedPipeline(
- 'explain_document_ml', lang='en').model
- normalizer = Normalizer()\
- .setInputCols(['lemmas'])\
- .setOutputCol('normalized')\
- .setLowercase(True)
- finisher = Finisher()\
- .setInputCols(['normalized'])\
- .setOutputCols(['normalized'])\
- .setOutputAsArray(True)
- count_vectorizer = CountVectorizer()\
- .setInputCol('normalized')\
- .setOutputCol('bows')
- pipeline = Pipeline().setStages([
- sparknlp_pipeline, normalizer, finisher, count_vectorizer])
- model = pipeline.fit(space)
- processed = model.transform(space)
- vocabulary = model.stages[-1].vocabulary
- word_counts = Counter()
- for row in processed.toLocalIterator():
- for ix, count in zip(row['bows'].indices, row['bows'].values):
- word_counts[vocabulary[ix]] += count
- from matplotlib import pyplot as plt
- %matplotlib inline
- y = list(range(20))
- top_words, counts = zip(*word_counts.most_common(20))
- plt.figure(figsize=(10, 8))
- plt.barh(y, counts)
- plt.yticks(y, top_words)
- plt.show()
图 5-1显示了来自空间新闻组的词频。
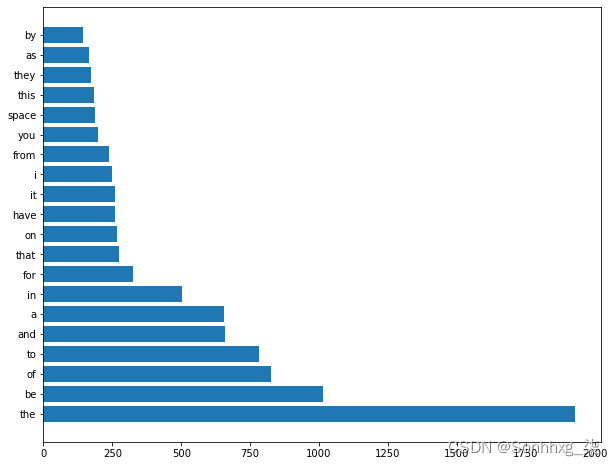
图 5-1。来自空间新闻组的文档的词频
- from wordcloud import WordCloud
- plt.figure(figsize=(10, 8))
- wc = WordCloud(colormap='Greys', background_color='white')
- im = wc.generate_from_frequencies(word_counts)
- plt.imshow(im, interpolation='bilinear')
- plt.axis("off")
- plt.title('sci.space')
- plt.show()
图 5-2显示了来自空间新闻组的词云。

图 5-2。来自空间新闻组的文档的词云
- autos_path = os.path.join('data', 'mini_newsgroups', 'rec.autos')
- autos = spark.sparkContext.wholeTextFiles(autos_path)
- schema = StructType([
- StructField('path', StringType()),
- StructField('text', StringType()),
- ])
- autos = spark.createDataFrame(autos, schema=schema).persist()
- model = pipeline.fit(autos)
- processed = model.transform(autos)
- vocabulary = model.stages[-1].vocabulary
- word_counts = Counter()
- for row in processed.toLocalIterator():
- for ix, count in zip(row['bows'].indices, row['bows'].values):
- word_counts[vocabulary[ix]] += count
- y = list(range(20))
- top_words, counts = zip(*word_counts.most_common(20))
- plt.figure(figsize=(10, 8))
- plt.barh(y, counts)
- plt.yticks(y, top_words)
- plt.show()
图 5-3显示了来自 autos 新闻组的词频。
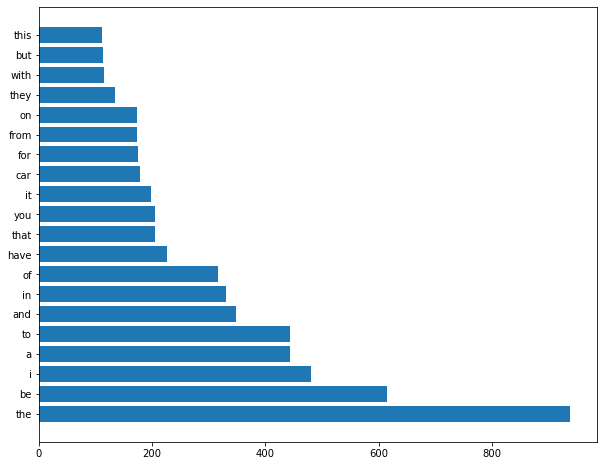
图 5-3。来自汽车新闻组的文档的词频
- from wordcloud import WordCloud
- plt.figure(figsize=(10, 8))
- wc = WordCloud(colormap='Greys', background_color='white')
- im = wc.generate_from_frequencies(word_counts)
- plt.imshow(im, interpolation='bilinear')
- plt.axis("off")
- plt.title('rec.autos')
- plt.show()
图 5-4显示了来自汽车新闻组的词云。

图 5-4。来自汽车新闻组的文档的词云
-
相关阅读:
全球人造丝卫生棉条行业调研及趋势分析报告
【项目】负载均衡OnlineJudge
搭建环境AI画图stable-diffusion
零基础入门学习Web开发:HTML篇(一)
DNS部署与安全
数据库第三章相关习题记录-关系数据库标准语言SQL
Yolov5更换上采样方式
ctfshow-web入门-文件上传(web166、web167)&(web168-web170)免杀绕过
vue中props设置默认值-父组件给子组件传值的写法——简略、带类型、带类型和默认值、带校验
重生奇迹MU游戏的特别之处
- 原文地址:https://blog.csdn.net/sikh_0529/article/details/127567299