-
解决大众D评网站css加密改进说明
前言
取名最新是因为确实目前是最新的,三个月后会去掉最新
找了很多博客代码都过时了,而且不是很好懂
以前是字体库,现在是css加密,大众点评的反爬机制确实强
本篇主要是对https://blog.csdn.net/qq_40235133/article/details/116588731这篇博客的补充说明
建议先食用这篇,大概懂了原理,出bug时再来看我这篇
本篇主要是对原博客三个报错的说明改进代码
import requests import re from lxml import etree import pandas as pd import time def crew(i): """ 爬取第i页的评论 :return: 第i页评论的表格 """ # 首先获取原始网页数据 headers = { 'Cookie': "_lxsdk_cuid=1841c99b9d8c8-0f1e3463ba50be-26021f51-144000-1841c99b9d8c8; _lxsdk=1841c99b9d8c8-0f1e3463ba50be-26021f51-144000-1841c99b9d8c8; _hc.v=7a55c341-cdde-f085-91b9-46cf79b3e9c4.1666927149; fspop=test; cy=5; cye=nanjing; _lx_utm=utm_source%3DBaidu%26utm_medium%3Dorganic; Hm_lvt_602b80cf8079ae6591966cc70a3940e7=1666927149,1666927732,1666934687; WEBDFPID=w7955624006058uxy4x7y89u3076vxu58158w9xxv01979589v3v53uz-1982294689448-1666934689197KSIQKMGfd79fef3d01d5e9aadc18ccd4d0c95075294; dplet=5c64382712747088c3c4439a13928211; dper=d0a6f2f41b6117319faebcb359b0362c20578bb6b4bfbd0f0b7cd0ad09f94b97008071297a9de353aff98bcf2c9fe5906601a93859b5dd80d999ab192ccbba6831a3195d1ff78d000576a2c958289c81a729e2c0d86cc5d6a1a5f12ad1d395d3; ll=7fd06e815b796be3df069dec7836c3df; ua=dpuser_3122839151; ctu=60b777f0958d913f993ce809bf1d930ee786702ba9e11effc2704689466c1d67; s_ViewType=10; Hm_lpvt_602b80cf8079ae6591966cc70a3940e7=1666934731; _lxsdk_s=1841d0cc474-c48-686-a8b%7C%7C177", 'Host': 'www.dianping.com', 'Referer': f'https://www.dianping.com/shop/i2r0VzqmFBkNLQXC/review_all/p{i}', 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/106.0.0.0 Safari/537.36' } response = requests.get(f'https://www.dianping.com/shop/i2r0VzqmFBkNLQXC/review_all/p{i}', headers=headers) with open('01 网页数据_加密.html', mode='w', encoding='utf-8') as f: f.write(response.text) # 获取css文件请求svg内容 css_url = 'http:' + re.findall(r'', response.text)[0] css_response = requests.get(css_url) with open('02 css样式.css', mode='w', encoding='utf-8') as f: f.write(css_response.text) # 获取svg映射表 svg_url ='http:'+ re.findall(r'svgmtsi\[class\^="muv"\].*?background-image: url\((.*?)\);',css_response.text)[0] svg_response = requests.get(svg_url) with open('03 svg映射表.svg',mode='w',encoding='utf-8') as f: f.write(svg_response.text) # 获取svg加密字典 import parsel with open('03 svg映射表.svg',mode='r',encoding='utf-8') as f: svg_html = f.read() sel = parsel.Selector(svg_html) paths = sel.css("path") texts = sel.css('textPath') lines = [] for path,textPath in zip(paths,texts): lines.append([int("".join(re.findall("M0 (.*?) H600",path.css('path::attr(d)').get()))),textPath.css('textPath::text').get()]) with open('02 css样式.css',mode='r',encoding='utf-8') as f: css_text = f.read() class_map = re.findall(r'\.(muv\w+)\{background:-(\d+)\.0px -(\d+)\.0px;\}',css_text) class_map = [(cls_name,int(x),int(y)) for cls_name,x,y in class_map] d_map = {} #获取类名与汉字的对应关系 for one_char in class_map: try: cls_name,x,y =one_char for line in lines: if line[0] < y: pass else: index = int(x/14) char = line[1][index] # print(cls_name,char) d_map[cls_name] = char break except Exception as e: print(e) # 替换svg加密字体,还原评论 with open('01 网页数据_加密.html',mode='r',encoding='utf-8') as f: html = f.read() for key,value in d_map.items(): html = html.replace('+ key+'">',value) with open('04 网页数据_解密.html',mode='w',encoding='utf-8') as f: f.write(html) # 去除空格,并存到dataframe中 e = etree.HTML(html) pl = e.xpath("//div[@class='review-words Hide']/text()") dq_list =[] cc_df = pd.DataFrame() for p in pl: if p == '\n\t ' or p == '\n ': pass else: dq_list.append(p) for pp in dq_list: cc_df = cc_df.append({'评论':pp}, ignore_index=True) return cc_df def add_workbook(): with open("out.csv","ab") as f: f.write(open("new_out.csv","rb").read()) return None if __name__ == '__main__': # 设置开始页数和终止界面 start_page = 2 # 默认第一遍从第2页开始 end_page = 100 # 默认爬取200页 df1 = crew(1) # 开始爬虫 try: for i in range(start_page,end_page): df2 = crew(i) df1 = pd.concat([df1,df2],axis=0,ignore_index=True) time.sleep(10) print(f"第{i}页爬取成功") # 存入excel df1.reset_index(inplace=True) df1.to_excel('new_out.xlsx', index=False) except: print(f"当前页数{i}") print("cookie已过期,请重置,并更新开始页数") # print(1)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
说明
cookie
- 这个cookie表示登录状态,可能十分钟就要换

-
点这个网站:https://www.dianping.com/shop/i2r0VzqmFBkNLQXC/review_all
-
用自己的号登陆
-
搜索自己要获取评论的店、记得要点到评论页里
-
右键、选择检查
-
刷新网页
-
按图中四步就能找到cookie,然后复制替换掉原来py脚本里的过期cookie

-
cookie不更新就会报如下错
获取css文件那块 IndexError: list index out of range- 1
- 2
一些说明
-
这两处的muv,只针对这个店,换一家店可能就变了
-
根据自己要访问的店的加密方式改,比如这家店加密的svg是muv
-

-

-
搞错加密方式就会报如下错
-
svg映射表那块 list index out of range- 1
- 2
- 大众点评查找方式就两种,我这里写的是第一种,根据id定位行的,原博客是根据x坐标定位行的,也许会改,看情况用代码就行
- 根据id定位,但用了原博客代码的就会报如下错
lines.append([int(text.css('text::attr(y)').get()) ERROR:int() argument must be a string, a bytes-like object or a number, not 'NoneType'- 1
- 2
- 根据xy定位,但用了我的代码
- 不会报错但生成的excel会有点问题
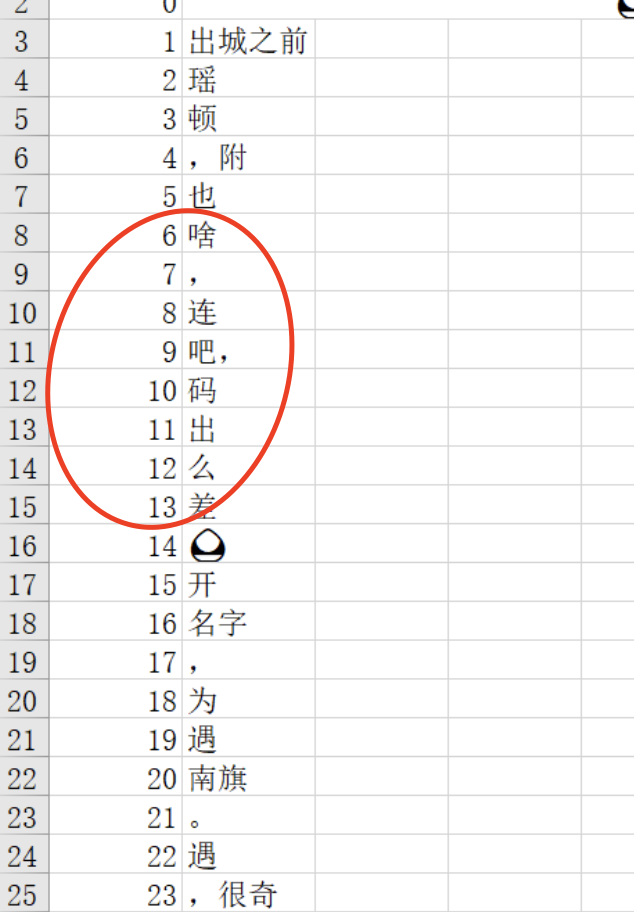
- 解决办法
- 用上面的替换下面这块
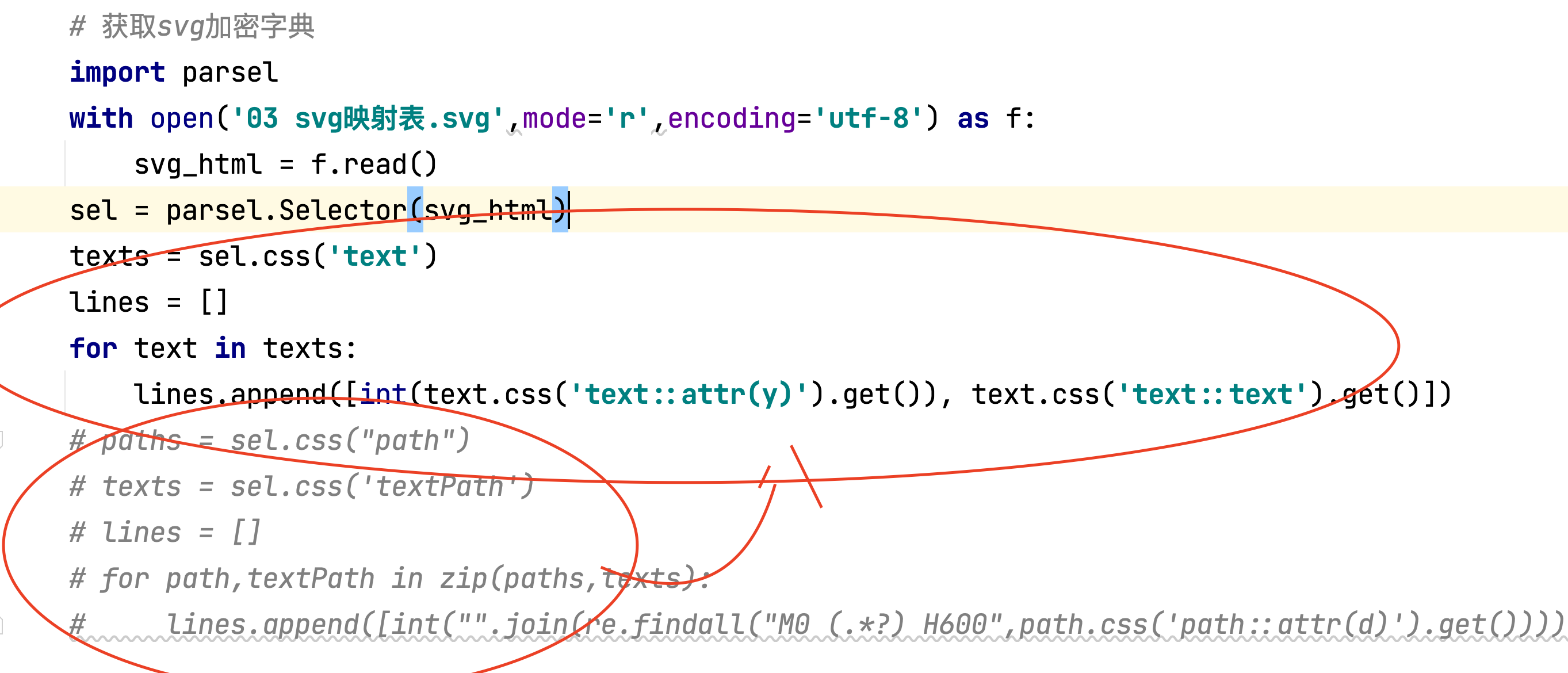
代码
texts = sel.css('text') lines = [] for text in texts: lines.append([int(text.css('text::attr(y)').get()), text.css('text::text').get()])- 1
- 2
- 3
- 4
有什么问题可以在评论区问,趁我对这个还有记忆的时候
-
相关阅读:
STM32CubeMX外部中断
java面试题整理《集合篇》一
关于pycharm打开时一直加载中的解决办法
OSPF邻居关系建立故障排除
一文彻底搞懂Mysql索引优化
SQLAlchemy学习-2.query() 查询数据
深度学习算法
编程团体赛
go语言下载安装
GID:旷视提出全方位的检测模型知识蒸馏 | CVPR 2021
- 原文地址:https://blog.csdn.net/weixin_57345774/article/details/127574631
