-
不要在Python中使用iterrows()循环
不要在Python中使用iterrows()循环,而是使用这些!
知道如何以31倍的速度迭代pandas DataFrame
你想在Python中快速运行31倍的循环吗?
简介:循环对我们来说是非常自然的。当我们学习任何编程语言时,循环都是重要概念的一个组成部分,而且循环也很容易解释。因此,在Python中,每当我们必须对数据集的行进行迭代时,凭直觉,我们就开始考虑实现循环。
但是,当数据集太大的时候,循环需要花费大量的时间来遍历DataFrame。那么,我们是完全不使用循环呢,还是可以通过一些小技巧来克服这一挑战呢?
幸运的是,有一些小窍门
在这篇博客中,我们将使用pandas中不同的循环方法来研究在一个大的pandas DataFrame中迭代的不同方式(以及相关的运行时间)。在这篇博客结束时,你会知道哪种循环技术对较大的数据集最有效。
创建我们的数据集
我们将使用一个DataFrame df有500万行和4列。每一列都被分配一个0到50之间的随机整数。
import numpy as np
import pandas as pd
df = pd.DataFrame(np.random.randint(0, 50, size=(5000000, 4)), columns=('a','b','c','d'))
df.shape
# (5000000, 5)
df.head()- 1
有500万行和4列的数据框架
选项1:迭行
想象一下,我们想在数据框架df中添加一列'e',基于以下条件。
如果'a'等于0,那么'e'就等于'd'的值。
如果'a'小于或等于25且大于0,那么'e'等于'b'-'c'。
如果不满足上述条件,那么'e'就等于'b'+'c'。
为了实现上述条件,我们将使用pandas iterrows()函数来迭代数据框架df的行。
Iterrows()函数以(index, Series)对的形式遍历数据框架的行。
import time
start = time.time()
# Iterating through DataFrame using iterro
for idx, row in df.iterrows():
if row.a == 0:
df.at[idx,'e'] = row.d
elif (row.a <= 25) & (row.a > 0):
df.at[idx,'e'] = (row.b)-(row.c)
else:
df.at[idx,'e'] = row.b + row.c
end = time.time()
print(end - start)
### Time taken: 666 seconds- 1
所花费的时间666秒
iterrows()函数需要666秒(约11分钟)来实现对500万行的操作。
选项2:迭代数
Itertuples是另一种在pandas DataFrame中迭代的方法。它将DataFrame的行作为命名的图元进行迭代。下面的代码显示了如何使用itertuples访问元素。该行对象有第一个字段作为索引,以下字段作为列。
for row in df[:1].itertuples():
print(row)
print(row.Index)
print(row.a)- 1
输出 使用下面的代码,我们可以在我们的DataFrame df上应用这个操作。
start = time.time()
# Iterating through namedtuples
for row in df.itertuples():
if row.a == 0:
df.at[row.Index,'e'] = row.d
elif (row.a <= 25) & (row.a > 0):
df.at[row.Index,'e'] = (row.b)-(row.c)
else:
df.at[row.Index,'e'] = row.b + row.c
end = time.time()
print(end - start)
## Time taken: 81 seconds- 1
花费的时间:81秒 ** itertuples()函数在DataFrame上执行所需的操作需要~81秒,比iterrows()函数快8倍**。
选项3:字典
我们也可以通过将 DataFrame 转换为 dictionary(它是一个轻量级的内置数据类型)来迭代 DataFrame 的行,通过 dictionary 迭代来执行操作,然后将更新的 dictionary 转换回 DataFrame。
我们可以使用'to_dict()'函数将 DataFrame 转换为 dictionary
start = time.time()
# converting the DataFrame to a dictionary
df_dict = df.to_dict('records')
# Iterating through the dictionary
for row in df_dict[:]:
if row['a'] == 0:
row['e'] = row['d']
elif row['a'] <= 25 & row['a'] > 0:
row['e'] = row['b']-row['c']
else:
row['e'] = row['b'] + row['c']
# converting back to DataFrame
df4 = pd.DataFrame(df_dict)
end = time.time()
print(end - start)
## Time taken: 25 seconds- 1
花费的时间:25秒
dictionary方法花费了~25秒,比itertuples()函数花费的时间快了~3倍。选项4:数组/列表
这个方法类似于字典方法,我们将把DataFrame转换为数组,在数组中迭代操作每一行(保存在一个列表中),然后将列表转换为DataFrame。
start = time.time()
# 创建一个空的字典
list2 = []
# 初始化有0的列。
df['e'] = 0
# 遍历一个NumPy数组
for row in df.values:
if row[0] == 0:
row[4] = row[3]
elif row[0] <= 25 & row[0] > 0:
row[4] = row[1]-row[2]
else:
row[4] = row[1] + row[2]
#将数值追加到一个列表中
list2.append(row)
#将列表转换为一个数据框架
df2 = pd.DataFrame(list2, columns=['a', 'b', 'c', 'd','e'])
end = time.time()
print(end - start)
#Time Taken: 21 seconds- 1
所花费的时间:21秒
这个方法所花费的时间是~21秒(比iterrows快31倍),这与在字典中迭代所花费的时间非常接近。
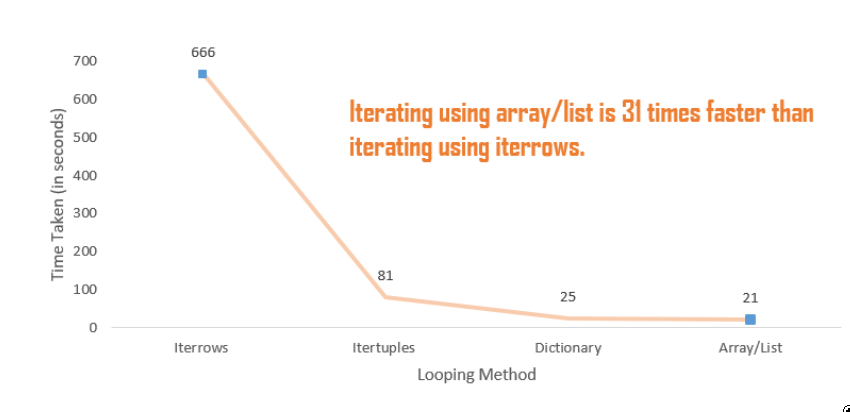
执行时间的比较
字典和数组是内置的轻型数据结构,因此在DataFrame中迭代花费的时间最少。
每当处理大型数据集时,最好的做法是将你的python代码矢量化。它将以闪电般的速度运行。对上述代码进行矢量化后,执行时间减少到0.29秒(比在数组中迭代快72倍)。我们将在接下来的文章中学习矢量化的知识。
总结 我们看了使用循环遍历DataFrame的4种不同方式。
Iterrows函数花费了最大的时间来迭代DataFrame。 使用itertuples函数,我们可以以8倍于iterrows函数的速度遍历DataFrame。 遍历Dictionary和Array需要的时间最少,是使用循环来操作数据的最佳方法。
本文由 mdnice 多平台发布
-
相关阅读:
【力扣1704】判断字符串的两半是否相似
c++ unordered_set
学习笔记10--ASIL分解与冗余功能安全
Rancher 系列文章-Rancher 升级
C#应用程序界面开发基础——窗体控制(2)——MDI窗体
机器视觉兄弟们,新工作之前,不要过度准备
ssm+vue的汽车站车辆运营管理系统(有报告)。Javaee项目,ssm vue前后端分离项目。
字节最新算法题解:在排序数组中查找元素的第一个和最后一个位置
【Linux内核】Linux内核介绍
flink-cdc实时同步mysql数据到elasticsearch
- 原文地址:https://blog.csdn.net/qq_40523298/article/details/127577752
