-
【LeetCode高频100题-2】冲冲冲
文章目录
22. 括号生成
题意
解法1
23. 合并K个升序链表
题意
- 合并k个升序的链表
- 是“合并两个升序链表”的扩展版
解法1 暴力两两合并
转换题目,每次仅合并两个升序链表。
合并两个升序链表:
ListNode* mergeTwoLists(ListNode* a,ListNode* b){ if((!a)||(!b)) return a?a:b; ListNode head,*tail=&head,*aptr=a,*bptr=b; while(aptr&&bptr) { if(aptr->val<bptr->val) { tail->next=aptr;aptr=aptr->next; } else { tail->next=bptr;bptr=bptr->next; } tail=tail->next; } tail->next=(aptr?aptr:bptr); return head.next; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
合并k个升序链表:
/** * Definition for singly-linked list. * struct ListNode { * int val; * ListNode *next; * ListNode() : val(0), next(nullptr) {} * ListNode(int x) : val(x), next(nullptr) {} * ListNode(int x, ListNode *next) : val(x), next(next) {} * }; */ class Solution { public: ListNode* mergeTwoLists(ListNode* a,ListNode* b) { if((!a)||(!b)) return a?a:b; ListNode head; ListNode* aptr=a,*bptr=b,*tail=&head; while(aptr&&bptr) { if(aptr->val<bptr->val) { tail->next=aptr;aptr=aptr->next; } else { tail->next=bptr;bptr=bptr->next; } tail=tail->next; } tail->next=(aptr?aptr:bptr); return head.next; } ListNode* mergeKLists(vector<ListNode*>& lists) { ListNode* ans=NULL; for(int i=0;i<lists.size();i++) ans=mergeTwoLists(ans,lists[i]); return ans; } };- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
解法2 直接获取k个节点中的最小节点(堆)
“合并两个升序链表”每次选择两个链表中最小的节点,那么类比到“合并k个升序链表”,可以每次选择k个链表中最小的节点,这个选择可以靠优先级队列(二叉堆) 来实现。
/** * Definition for singly-linked list. * struct ListNode { * int val; * ListNode *next; * ListNode() : val(0), next(nullptr) {} * ListNode(int x) : val(x), next(nullptr) {} * ListNode(int x, ListNode *next) : val(x), next(next) {} * }; */ class Solution { public: struct Status{ int val; ListNode* ptr; bool operator < (const Status &rhs) const{ return val > rhs.val; } }; priority_queue<Status> q; ListNode* mergeKLists(vector<ListNode*>& lists) { for(auto node:lists) { if(node) q.push({node->val,node}); } ListNode head,*tail=&head; while(!q.empty()) { auto f=q.top();q.pop(); //取根 tail->next=f.ptr; tail=tail->next; if(f.ptr->next) q.push({f.ptr->next->val,f.ptr->next}); } return head.next; } };- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
复杂度
优先队列q中元素最多有k个,每次pop和push的复杂度为O(logk),由于所有链表的每一个节点都会push和pop一遍,所以算法的总复杂度为O(nlogk)。
31. 下一个排列
题意
- 相当于找下一个尽可能小的更大的数
- 应当选择最靠右的最左边的较小数与最靠右的尽可能小的数交换,所以选择从右向左遍历寻找目标数。
- 最靠右的最左边的较小数:从右向左寻找第一个升序二元组
tar_i=i。 - 最靠右的尽可能小的数:从右往左第一个大于
nums[tar_i]的数,记为tar_j。
解法1 分析找规律
例如,452631,应当选择2与3交换。
也就是说,从右向左寻找第一个升序二元组
tar_i=i,需要注意的是,此时,i的右边一定是一个降序排列。然后再寻找一个比nums[i]大却又尽可能小的数,由于i右边是一个降序排列,所以从右往左寻找第一个大于nums[tar_i]的数即可,记为tar_j。最后,将tar_i右边的数进行升序重排即可。如果找不到这样一个升序二元组
sort即可。class Solution { public: void nextPermutation(vector<int>& nums) { //先不考虑重复数的存在 int n=nums.size(); int tar_i=-1,tar_j=-1; for(int i=n-2;i>=0;i--) { if(nums[i]<nums[i+1]) { tar_i=i; break; } } if(tar_i==-1) { sort(nums.begin(),nums.end()); return ; } for(int i=n-1;i>tar_i;i--) { if(nums[i]>nums[tar_i]) { tar_j=i; break; } } swap(nums[tar_i],nums[tar_j]); sort(nums.begin()+tar_i+1,nums.end()); return ; } };- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
32. 最长有效括号
题意
- 找最长有效的括号子串的长度。(最值问题,考虑动态规划)
解法1 动态规划
- 确定状态:变量是有效括号子串的长度。
- 确定dp函数的意义:
dp[i]表示以s[i]为结尾的最长有效括号子串的长度。即,如果dp[i]不属于有效子串的一部分,则dp[i]=0。 - 确定状态转移方程(自底向上,从最后一步往前推):
s[i]=='(':dp[i]=0。s[i]==')': 分类讨论s[i-1]=='(',那么s[i-1]与s[i]构成一对有效括号,即"xxxxxx( )"有效括号子串长度增加2,即dp[i]=dp[i-2]+2。s[i-dp[i-1]-1]=='(',s[i]之前,以s[i-1]结尾是一个有效括号子串,即"xxxxxx) )",这时候需要考虑s[i]之前的那个有效括号子串的前一个符号。- 把目光放到"xxxxxx"上,此时可表示为"wwww yyyyy",这里"yyyyy"表示以s[i-1]结尾的有效括号子串,它的长度为dp[i-1]。那么它之前那个符号为s[i-dp[i-1]-1],也就是最后一个w,如果这个w是一个’(',那么此时s[i-dp[i-1]-1]与s[i]构成一对有效括号,此时的有效括号子串为s[i-dp[i-1]-1,i],即,
dp[i]=dp[i-1]+2。 - 此时的字符串变成了"www( yyyyy )“,再考虑"www”,此时最后一个w为s[(i-dp[i-1]-1)-1],如果dp[(i-dp[i-1]-1)-1]!=0,则这时候,"www"可以和上一步生成的有效括号子串合并,成为一个更长的新的有效括号子串,即
dp[i]=dp[i-1]+2+dp[(i-dp[i-1]-1)-1]。
- 把目光放到"xxxxxx"上,此时可表示为"wwww yyyyy",这里"yyyyy"表示以s[i-1]结尾的有效括号子串,它的长度为dp[i-1]。那么它之前那个符号为s[i-dp[i-1]-1],也就是最后一个w,如果这个w是一个’(',那么此时s[i-dp[i-1]-1]与s[i]构成一对有效括号,此时的有效括号子串为s[i-dp[i-1]-1,i],即,
- 确定base case:若
s[i]=='(',则dp[i]=0。 - 边界情况:要保证
i-1>=0、i-2>=0、i-dp[i-1]-1>=0、(i-dp[i-1]-1)-1>=0。
最后,比较所有有效括号子串的长度,取最大值返回。
class Solution { public: int longestValidParentheses(string s) { int n=s.size(); vector<int> dp(n+1,0); //vectorvec(n,t); 初始化一个长度为n的数组,每个元素初始化为t。 int ans=0; for(int i=1;i<n;i++) //ensure i-1>=0 { //base case if(s[i]=='(') dp[i]=0; //状态转移方程 if(s[i]==')') { if(s[i-1]=='(') { dp[i]=2; if(i>=2) //ensure i-2>=0 dp[i]+=dp[i-2]; } if((i-dp[i-1]-1)>=0&&s[(i-dp[i-1]-1)]=='(') { dp[i]=dp[i-1]+2; if(i-dp[i-1]-2>=0) //ensure i-dp[i-1]-2>=0 dp[i]+=dp[i-dp[i-1]-2]; } } ans=max(ans,dp[i]); } return ans; } };- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
33. 搜索旋转排序数组
题意
- 一个升序数组,数组中的元素互不重复。
- 在某个下标k上实现了旋转了数组,使数组变成
[nums[k], nums[k+1], ..., nums[n-1], nums[0], nums[1], ..., nums[k-1]](下标从0开始计数)。 - 要求复杂度为O(logn)。
- 要求返回target的下标值,如不存在则返回-1。
解法1 二分搜索
- 很妙的一点是:无论这个数组在哪个下标上旋转,如果从中间将数组分成两部分,那么一定有一部分是有序的,另一部分是无序的。这就是这道题可以二分搜索的基础。
- 将数组分为
[left,mid]和[mid+1,right]两部分,初始状态时left=0,right=n-1。(本质上也可以理解为是分为了[left,mid-1]和[mid+1,right]和[mid]三部分,但是如果不加上mid,代码中会出现mid-1和mid+1的情况,在判断两个边界的时候会出现数组下标越界的情况,所以将min包括到两个部分中,效果相同,但是便于处理。) - 通过判断
target在不在有序部分实现上下界的更新。 - 对于一个数组
nums[left,right],每次取其中值nums[mid],每次都判断nums[mid]是不是我所寻找的target。然后判断左右两部分[left,mid]和[mid,right]。- 如果
[left,mid]有序,也就是nums[left]<=nums[right],这里的等号表示区间里只有一个元素的情况,可以直接通过该部分有序这个特性判断target在不在该部分中:如果target在该部分中,舍弃[mid,right]部分,即右界更新,right=mid-1;如果target不在该部分中,那么舍弃这个部分,即左界更新,left=mid+1。 - 如果
[left,mid]无序,那么[mid,right]一定有序,同样地,判断target在不在这个有序部分中:如果target在这个部分中,则舍弃[left,mid]部分,即左界更新,left=mid+1;如果target不在这个部分中,那么舍弃这个部分,即右界更新,right=mid-1。
- 如果
- 所以每个循环都将数组分为两个部分,利用其中一部分有序的特性,舍弃一半,最后实现在**O(logn)**的复杂度下寻找nums[mid]==target。
class Solution { public: int search(vector<int>& nums, int target) { int n=nums.size(); int left=0,right=n-1; //[0.mid-1]和[mid+1,n-1]两个部分里一定有一个部分是有序的,根据有序部分来修改上下界(可以判断target是否在有序部分里) //实际上将数组分成了两个部分,[0.mid],[mid],[mid,n-1],mid应当是两个部分共用的 while(left<=right) { int mid=(left+right)/2; //base case if(nums[mid]==target) { return mid; } //如果[0,mid]有序 if(nums[left]<=nums[mid]) //当只有一个元素时,会取等,这也说明是在闭区间[left,mid]中搜索。 { //如果target在这个部分里 if(nums[left]<=target&&target<=nums[mid]) //target exists { //已经判断了nums[mid]!=target right=mid-1; //将另一部分舍弃 } else //target不在有序部分里 { left=mid+1; //将这一部分舍弃 } } else //[mid+1,n-1]有序 { if(target>=nums[mid]&&target<=nums[right]) //在有序部分里 { left=mid+1; //舍弃左边无序的部分 } else //在另一部分 { right=mid-1; //舍弃这个有序的部分 } } } return -1; } };- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
34. 在排序数组中查找元素的第一个和最后一个位置
题意
- 两次二分分别得到左右界即可。
解法1 两次二分搜索(左闭右开)
class Solution { public: vector<int> searchRange(vector<int>& nums, int target) { vector<int> ans; int n=nums.size(); //左界 int left=0,right=n,leftBound=-1; while(left<right) { int mid=left+(right-left)/2; if(nums[mid]==target) { right=mid; } else if(nums[mid]<target) { left=mid+1; } else if(nums[mid]>target) { right=mid; } } if(left<n&&nums[left]==target) leftBound=left; //右界 left=0; right=n; int rightBound=-1; while(left<right) { int mid=left+(right-left)/2; if(nums[mid]==target) { left=mid+1; } else if(nums[mid]<target) { left=mid+1; } else if(nums[mid]>target) { right=mid; } } if(left>=1&&nums[left-1]==target) rightBound=left-1; //这里! left=0时,left-1会溢出! ans.push_back(leftBound); ans.push_back(rightBound); return ans; } };- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
解法2 两次二分搜索(闭区间)
class Solution { public: vector<int> searchRange(vector<int>& nums, int target) { int n=nums.size(); int leftBound=-1,rightBound=-1; //左界 int left=0,right=n-1; while(left<=right) { int mid=left+(right-left)/2; if(nums[mid]==target) { right=mid-1; //向左收缩 } else if(nums[mid]>target) { right=mid-1; } else if(nums[mid]<target) { left=mid+1; } } //出循环条件left=right+1,此时left指向左界。 if(left==n) leftBound=-1; else leftBound=nums[left]==target?left:-1; //右界 left=0; right=n-1; while(left<=right) { int mid=left+(right-left)/2; if(nums[mid]==target) { left=mid+1; //向右收缩 } else if(nums[mid]>target) { right=mid-1; } else if(nums[mid]<target) { left=mid+1; } } //出循环条件left=right+1,此时right指向右界 if(right<0) rightBound=-1; else rightBound=nums[right]==target?right:-1; return vector<int>{leftBound,rightBound}; } };- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
Attention
- 左界时,left:0~n,可能右溢出。
- 右界时,right:-1~n-1,可能左溢出。
39. 组合总和
题意
- 寻找和为target的所有组合。
- 元素可以重复使用。
解法1 递归回溯
对于穷举所有可能性才能达到答案的问题,一般都用递归回溯算法。
class Solution { public: void dfs(vector<int>& candidates,int target,vector<vector<int> >& ans,int idx,vector<int>& path) { if(target<0||idx==candidates.size()) return ; if(target==0) { ans.emplace_back(path); return ; } //不选择candicate[idx] dfs(candidates,target,ans,idx+1,path); //选择,选择前加入路径,选择后撤销选择(从路径中撤销) path.emplace_back(candidates[idx]); dfs(candidates,target-candidates[idx],ans,idx,path); path.pop_back(); } vector<vector<int>> combinationSum(vector<int>& candidates, int target) { vector<vector<int> > ans; vector<int> path; dfs(candidates,target,ans,0,path); return ans; } };- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
Attention
- emplace_back()
- push_back() 向容器尾部添加元素时,首先会创建这个元素,然后再将这个元素拷贝或者移动到容器中(如果是拷贝的话,事后会自行销毁先前创建的这个元素);而 emplace_back() 在实现时,则是直接在容器尾部创建这个元素,省去了拷贝或移动元素的过程。
42. 接雨水
题意
- 柱形图接雨水
解法1 暴力获取两边最值
对于height[i]来说,他的雨水储量是由min(leftMax,rightMax)决定的。
一开始考虑的时候只考虑了左边最值,考虑非常不全面:(。
既然明确了这一点,就可以暴力获取height[i]两边的最大值来得到min(leftMax,rightMax),从而计算每一个柱子的储水。
应该是样例比较水,所以 O(n2) 的复杂度也可以ac。
class Solution { public: int trap(vector<int>& height) { int n=height.size(),ans=0; vector<int> leftMax(n),rightMax(n); int tmp=0; for(int i=0;i<n;i++) { leftMax[i]=tmp; tmp=max(tmp,height[i]); } tmp=0; for(int i=n-1;i>=0;i--) { rightMax[i]=tmp; tmp=max(tmp,height[i]); } for(int i=0;i<n;i++) ans=ans+(min(leftMax[i],rightMax[i])>height[i]?min(leftMax[i],rightMax[i])-height[i]:0); return ans; } };- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
46. 全排列
void dfs(vector<vector<int> >& ans,vector<int>& current,vector<int>&nums,int cnt,vector<bool>& flag) { if(cnt==nums.size()) { ans.emplace_back(current); for(int i=0;i<current.size();i++) cout<<current[i]<<" "; cout<<endl; return ; } for(int i=0;i<nums.size();i++) { if(flag[i]==false) { current.emplace_back(nums[i]); flag[i]=true; dfs(ans,current,nums,cnt+1,flag); current.pop_back(); flag[i]=false; } } } vector<vector<int>> permute(vector<int>& nums) { vector<vector<int> > ans; vector<int> current; vector<bool> flag={false}; dfs(ans,current,nums,0,flag); return ans; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
49. 字母异位词分组
题意
- 给定字符串数组strs,将其中的字母异位词集合起来。
- 返回vector
。 - 字母异位词是通过重新排列源单词的字母得到的新的单词,所有源单词的字母只会被使用一次,但是源单词中可能会有重复的字母出现。
解法0 超时解法
复杂度:O(n2)。这种时候,要想到用哈希表加速,也就是unordered_map!
class Solution { public: vector<vector<string>> groupAnagrams(vector<string>& strs) { int n=strs.size(); vector<vector<string> > ans; vector<bool> outer_flag(n); int cnt=-1; bool flag=false; for(int i=0;i<n;i++) { if(!outer_flag[i]) //这个词没有被归类 { cnt++; flag=false; outer_flag[i]=true; vector<string> vec; ans.emplace_back(vec); ans[cnt].emplace_back(strs[i]); string tmp=strs[i]; sort(tmp.begin(),tmp.end()); for(int j=i+1;j<n;j++) //看后面的有没有同类的 { if(!outer_flag[j]) { string tmp2=strs[j]; sort(tmp2.begin(),tmp2.end()); if(tmp==tmp2) { ans[cnt].emplace_back(strs[j]); flag=true; outer_flag[j]=true; } } } } } return ans; } };- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
解法1 根据字符串的排序判断字母异位词
如果str1与str2是字母异位词,那么他们排序后得到的字符串str1’和str2’应当是一样的。
class Solution { public: vector<vector<string>> groupAnagrams(vector<string>& strs) { map<string,vector<string> > mp; vector<vector<string>> ans; int n=strs.size(); for(int i=0;i<n;i++) { string tmp=strs[i]; sort(tmp.begin(),tmp.end()); map<string,vector<string> >::iterator it=mp.find(tmp); if(it!=mp.end()) { it->second.emplace_back(strs[i]); } else { vector<string> vec; vec.emplace_back(strs[i]); mp[tmp]=vec; } } map<string,vector<string> >::iterator it; for(it=mp.begin();it!=mp.end();it++) { ans.emplace_back(it->second); } return ans; } };- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
//官方实现 class Solution { public: vector<vector<string>> groupAnagrams(vector<string>& strs) { unordered_map<string,vector<string> > mp; for(string& str:strs){ string key=str; sort(key.begin(),key.end()); mp[key].emplace_back(str); } vector<vector<string> >ans; for(auto it=mp.begin();it!=mp.end();it++) ans.emplace_back(it->second); return ans; } }; //根据官方实现修改后 class Solution { public: vector<vector<string>> groupAnagrams(vector<string>& strs) { map<string,vector<string> > mp; vector<vector<string>> ans; for(string& s : strs) { string tmp=s; sort(tmp.begin(),tmp.end()); // auto it=mp.find(tmp); // if(it!=mp.end()) // it->second.emplace_back(s); // else // mp[tmp].emplace_back(s); mp[tmp].emplace_back(s); } for(auto it=mp.begin();it!=mp.end();it++) ans.emplace_back(it->second); return ans; } };- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
Attention
for(auto x : str)和for(auto& x : str)for(auto x : str){}:x是str中每一个对象的复制,对x的操作不会影响原容器中的对象。for(auto& x : str){}:x是str中每个对象的引用,对x的操作会影响到原容器中对应的对象。引用会更快。auto:自动推断变量类型,常用于容器遍历和获取函数返回值。string类型变量的sort:sort(str.begin(),str.end())即可根据字典序对字符串进行排序(sort的头文件为unordered_map是依靠哈希表实现的,速度比map快,头文件是
map的常用操作:【PAT】第六章 C++标准模板库 - map 。
53. 最大子数组和
题意
- 子数组是连续的
解法1 动态规划(这是一道典型的动态规划问题)
这道题求的是最值(不要求获取最大子数组序列),这是典型的动态规划的适用问题。
动态规划解题步骤:
- 确定状态:变量是子数组和。
- 确定dp[i]的意义:表示以nums[i] 结尾的 子数组的和。
如果将dp[i]定义为到nums[i]的最大子数组,即不限制nums[i]包括在子数组中,你会发现,状态转移方程很难列。并且上次也有一道dp题,将nums[i]包括在了dp[i]中。这是一个trick,需要注意! - 确定状态转移方程:dp[i]=max(dp[i-1]+nums[i],nums[i])
注意dp[i]是以nums[i]结尾的最大子数组和,所以如果选择nums[i],则此时子数组和为dp[i-1]+nums[i];而如果不选择nums[i],也就是说最大子数组在nums[i]这里中断了,那么以nums[i]结尾的最大子数组就应当是他自己。
class Solution { public: int maxSubArray(vector<int>& nums) { int n=nums.size(); vector<int> dp(n); dp[0]=nums[0]; int ans=dp[0]; for(int i=1;i<n;i++) { dp[i]=max(nums[i],dp[i-1]+nums[i]); ans=max(ans,dp[i]); } return ans; } };- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
dp[i]可以仅使用一个变量pre存储。
class Solution { public: int maxSubArray(vector<int>& nums) { int pre=0; int ans=nums[0]; for(auto& x : nums) { pre=max(x,pre+x); ans=max(ans,pre); } return ans; } };- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
55. 跳跃游戏
题意
- 数组nums[]的第i个位置可以向后跳0-nums[i]个格子。
解法1 贪心
假设当前格子为pre,那么他可以到达的最大位置maxn是max(pre+i+nums[pre+i]),0<=i<=nums[pre]。
pre的更新,由于每次都在pre~(pre+nums[pre])之间寻找最远距离,所以每次更新pre为pre+pre[nums]+1。因此,如果更新后的pre>maxn,那么就说明,不会再往后走了,此时即可跳出循环。
最后判断maxn与n-1的大小即可。
class Solution { public: bool canJump(vector<int>& nums) { int n=nums.size(); int pre=0; int maxn=0; while(pre<n-1) { for(int i=pre;i<n&&i<=pre+nums[pre];i++) maxn=max(maxn,i+nums[i]); pre+=nums[pre]+1; if(pre>maxn) break; } return maxn>=n-1; } };- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
56. 合并区间
题意
- 合并所有有交集的区间
解法1 排序法
将所有区间按左端点从小到大排序后,你会发现,相邻的两个区间,只有两种情况:
- 两个区间之间有交集,如①和②,直接合并;
- 两个区间之间无交集,如②何③,无法合并;
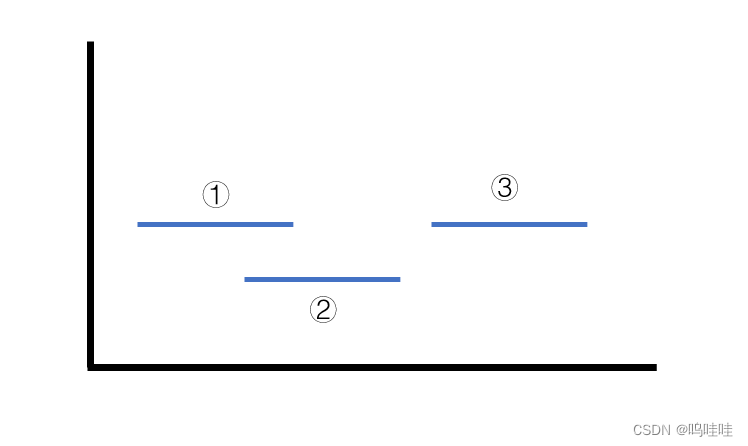
那么问题也就迎刃而解了。class Solution { public: //必须设置成static static bool cmp (const vector<int>& a,const vector<int>& b){ return a[0]<b[0]; } vector<vector<int>> merge(vector<vector<int>>& intervals) { sort(intervals.begin(),intervals.end(),cmp); //按左端点排序 int n=intervals.size(); vector<vector<int> > ans; int cnt=0; bool flag=false; while(cnt<n-1) { int l=intervals[cnt][0],r=intervals[cnt][1]; while(intervals[cnt+1][0]<=r) //下一个区间的左端点比当前区间的右端点小或相等,可以合并 { r=max(r,intervals[cnt+1][1]); //这里容易错,不能想当然地觉得后面那个区间的右端点一定更大 cnt++; if(cnt==n-1) //额外处理最后一个区间 { flag=true; break; } } vector<int> tmp={l,r}; ans.emplace_back(tmp); cnt++; } if(!flag) ans.emplace_back(intervals[n-1]); return ans; } };- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
Attention:
- cmp函数与sort函数
//必须设置成static static bool cmp (const vector<int>& a,const vector<int>& b){ return a[0]<b[0]; } ... void f(){ sort(intervals.begin(),intervals.end(),cmp); //按左端点排序 }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
72. 编辑距离
题意
- 给定两个单词,返回将 w o r d 1 word1 word1 转换为 w o r d 2 word2 word2 所需要的最少操作数;
- 有三种操作:插入、删除、替换
解法 动态规划
假设
dp[i][j]表示 将 w o r d 1 word1 word1 的前i个字符转换为 w o r d 2 word2 word2 的前j个字符需要的最少操作数,那么状态转移方程为:dp[i][j] = min(dp[i-1][j] + 1, dp[i][j-1] + 1,, dp[i-1][j-1] + 1), if word1[i] != word[j] dp[i][j] = dp[i-1][j-1], if word1[i] == word2[j]- 1
- 2
其中,
dp[i-1][j] + 1表示插入操作;dp[i][j-1] + 1表示删除操作;dp[i-1][j-1] + 1表示替换操作;- 如果
word1[i] == word2[j],那么不需要做额外操作,就能实现转换,所以此时dp[i][j] = dp[i-1][j-1]。
初始条件为:
dp[0][0] = 0; for(int i = 1; i <= n; i++) dp[i][0] = i; for(int j = 1; j <= m; j++) dp[0][j] = j;- 1
- 2
- 3
也就是说,假如其中一个 w o r d word word 为空,则最少进行 i i i 或 j j j 次插入操作即可实现转换。
因此,为了方便计算,
dp[][]的第 0 0 0 行和第 0 0 0 列拿来存放初始条件,初始化:vector<vector<int> > dp(n + 1, vector<int>(m + 1, maxn));- 1
完整代码为:
class Solution { public: int minDistance(string word1, string word2) { int n = word1.size(), m = word2.size(); int maxn = 1e9; vector<vector<int> > dp(n + 1, vector<int>(m + 1, maxn)); dp[0][0] = 0; for(int i = 1; i <= n; i++) dp[i][0] = i; for(int j = 1; j <= m; j++) dp[0][j] = j; // dp[i][j]:word1 前 i 个字符转换成 word2 前 j 个字符需要的最少操作次数。 for(int i = 1; i <= n; i++) { for(int j = 1; j <= m; j++) { int top = dp[i][j-1] + 1, left = dp[i-1][j] + 1, pre = dp[i-1][j-1]; if(word1[i-1] != word2[j-1]) // dp 的第 1 行/列 对应的才是 word 的 0 { dp[i][j] = min(dp[i][j], min(min(left, top), pre + 1)); } else { dp[i][j] = pre; } } } return dp[n][m]; } };- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
复杂度:
时间复杂度:O( n ∗ m n * m n∗m),其中 n n n 和 m m m 分别为 w o r d 1 word1 word1 和 w o r d 2 word2 word2 的长度。
空间复杂度:O( n ∗ m n * m n∗m),其中 n n n 和 m m m 分别为 w o r d 1 word1 word1 和 w o r d 2 word2 word2 的长度。
-
相关阅读:
腾讯云轻量级服务器和云服务器什么区别?轻量服务器是干什么用的
【Java集合框架】15 ——SortedSet 接口
Springboot+vue的人事管理系统(有报告),Javaee项目,springboot vue前后端分离项目。
【Maven】Unknown lifecycle phase “.skip.test=true“.
在线渲染3d怎么用?3d快速渲染步骤设置
路由懒加载
行为型设计模式之观察者模式
(附源码)springboot自习室座位预约系统 毕业设计 674156
(附源码)ssm考试题库管理系统 毕业设计 069043
liunx各大发行版(centos,rocky,ubuntu,国产麒麟kylinos)网卡配置和包管理方面的区别
- 原文地址:https://blog.csdn.net/weixin_43736572/article/details/127395129
