-
07-树(Tree)结构分析
树(Tree)结构分析
什么是树?
树是一种非线性的数据结构,它是由n(n>=0)个有限节点组成一个具有层次关系的集合。把它叫做树是因为它看起来像一棵倒挂的树,也就是说它是根朝上,而叶朝下的。它具有以下的特点:
1.每个节点有零个或多个子节点;
2.没有父节点的节点称为根节点;
3.每一个非根节点有且只有一个父节点;
4.除了根节点外,每个子节点可以分为多个不相交的子树树中的相关名词如何理解?
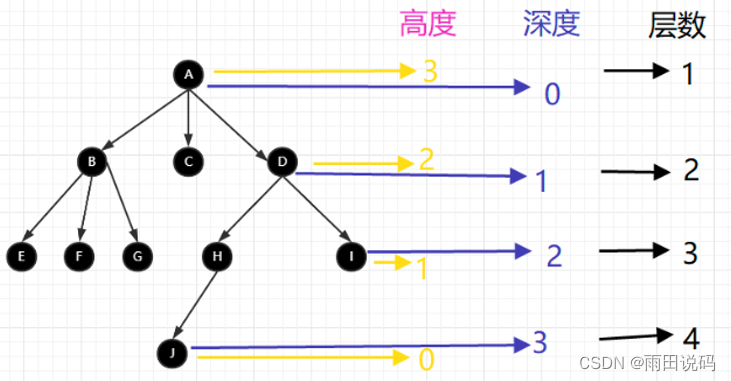
- 高度:当前节点到叶子节点的最长路径
- 深度:根节点到当前节点经过的边数
- 层数:节点的深度+1 树的高度:即根节点的高度(就是根节点到叶子节点的最长路径)
- 父节点:若一个节点含有子节点,则这个节点称为其子节点的父节点
- 子节点:一个节点包含的子树节点
- 兄弟节点:具有相同父节点的节点称为兄弟节点
- 叶节点:没有子节点的节点(也叫页子节点) 以上是关于树的一些常见的概念。
什么是二叉树?
二叉树的每个节点最多有两个子节点。
什么是二叉搜索树?
二叉搜索树其实就是二叉树,只不过又有一些额外的条件限制。其额外条件如下:
① 若它的左子树不为空,那么左子树上面的所有节点的值均小于它的根节点的值
② 若它的右子树不为空,那么右子树上面的所有的节点的值均大于它的根节点的值
③ 它的左右的树叶分别为二叉排序树其中重点强调下二叉搜索树的中序遍历(因为这是最常见的)。中序遍历的规则是:先遍历左子树,再遍历根节点,然后遍历右子树
例如下面这个二叉搜索树的遍历的结果:D-H-B-E-A-F-C-G

二分查找树的最大的缺点是依赖有序数组,而数组的缺点就是不能扩容,还有就是在添加和删除元素的时候需要移动数组,性能不理想。还有就是二叉树的特点就是每个节点的最多只有两个子节点,结合二叉搜索树的特点就是 左子节点 < 根节点 < 右子节点,那么在极端情况下,树可能会变为链表。那时间复杂度就变成了 O(n)。
什么是AVL树?
AVL 树也叫平衡二叉树,他的时间复杂度是 O(logn),AVL 的左右树的高度差也叫平衡因子(平衡因子就是从某个节点开始,他的左右子树的节点数差),即平衡因子不大于 1。
AVL 树在插入数据的时候会不断地调整,因为高度相差不大于 1 真的太严格了。那这样在频繁插入的时候必然需要一直调整树的结构,让其保持平衡。
什么是2-3树?
- 2-3树 是平衡树
- 2 叉节点,有两个分树,节点中有一个元素,左树元素更小,右树元素节点更大
- 3 叉节点,有三个子树,节点中有两个元素,左树元素更小,右树元素更大,中间树介于两个父元素之间?
案例分析:
- 假设现在有一个节点 40,那啥也别说了,第一个节点啥都不做,老实呆着就行;

-
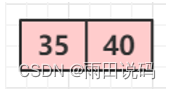
下一个节点 35 ,先从根节点开始,发现 40 > 35 ,此时理论上 35 应该添加到 40 的左子树上,但是对于 2-3 树,并不是你想的那样子,记住核心的一句话对于 2-3 树的添加,永远不会添加到一个空的节点去,只会跟最后找到的叶子节点做融合(不明白也没事,先把这个过程看完),这样变成了一个 3 节点。此时这颗树依旧是平衡的。这个3节点的含义是因为接下来的数据可能是小于 35 ,可能是在 35 到 40 之间,也可能是大于 40 的,所以这个节点能放三个节点。
-
下一个节点是 12 ,按照我们上面解释的 3 节点的含义,12应该在3节点的左侧。那这个时候按照 3 节点的定义,那这个岂不是 4 节点了?其实这个时候答案已经很明显了,就是此时该树会分裂成一个正常的二叉树,也就是这样子的,这棵树依旧是平衡的。

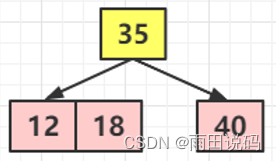
- 继续添加节点 18 ,自己能脑补下该怎么添加吗?这时候就很简单了,18 < 35 ,就添加到左子节点,此时左子节点不为空,那么就可以继续添加,而 18 > 12,理论上应该是添加到 12 的右子节点,但是由于对于 2-3 树的添加,永远不会添加到一个空的节点去,只会跟最后找到的叶子节点做融合。这个的理论指导,又因为此时 12 是一个 2 节点,所以即可进行融合,将18放在12的右侧水平对齐。
- 继续添加 10 ,10 < 35, 到左子树查找,10 < 12 但是12 的左子树为空,所以 10 先临时和 12 做一个融合,
但是这个时候 12 节点已经变成了 4 节点,所以需要拆解。但是这样的话 2-3 树就不是一颗绝对平衡的树了,显然不能这样拆解,或者是需要做其他操作来保持其绝对平衡。此时我们看上面的图,12 节点实际上是 10 和 18 的根节点了,接着往上查找,12 的父节点是 35 而其是一个 2 节点,所以 12 就顺理成章的和 35 融合起来,也就是下面这样子的。

依次类推可以继续添加,然后融合拆分。
什么是红黑树?
- 根节点是【黑色】
- 每个节点要么是【黑色】要么是【红色】
- 每个【红色】节点的两个子节点一定都是【黑色】
- 每个叶子节点(NIL)都是【黑色】
- 任意一个节点的路径到叶子节点所包含的【黑色】节点的数量是相同的—这个也称之为【黑色完美平衡】
- 新插入的节点必须是【红色】->为什么?如果新插入的节点是【黑色】,那不管是在插入到那里,一定会破坏黑色完美平衡的,因为任意一个节点的路径到叶子节点的黑色节点的数量肯定不一样了(第 6 点我自己加的,实际特性的定义是前 5 个)
那红黑树在添加和删除节点的时候是靠什么来维持平衡的呢?那就是左旋、右旋加变色,其含义如下:
左旋:以某个节点作为固定支撑点(围绕该节点旋转),其右子节点变为旋转节点的父节点,右子节点的左子节点变为旋转节点的右子节点,左子节点保持不变右旋: 以某个节点作为固定支撑点(围绕该节点旋转),其左子节点变为旋转节点的父节点,左子节点的右子节点变为旋转节点的左子节点,右子节点保持不变
变色:节点的颜色由红色变成黑色,或者是由黑色变成红色。
总结(Summary)
总之,数据结构和算法是一门相对比较难的学科,有些人刚刚接触可能就放弃了,但是数据结构一旦领会,将终身受益。对于其学习过程我们要学会刻意练习,并在整个学习过程中基于角色的不同,迅速调整我们的思维习惯和方式而非仅仅充实一下知识库。
-
相关阅读:
1秒钟搞懂tee和vim文件的使用命令(超级详细)
基于传统Session的登录
第 46 届国际大学生程序设计竞赛(ICPC)亚洲区域赛(澳门),签到题4题
LINK : fatal error LNK1104: 无法打开文件“python310.lib”解决方案
分析事件监听器注解:@EventListener、@TransactionalEventListener
c++ 内存释放测试
用Python做个学生管理系统,这不简简单单
SaaSBase:什么是有道云笔记?
前端知识之CSS(1)-css语法、css选择器(属性、伪类、伪元素、分组与嵌套)、css组合器
angular的observable
- 原文地址:https://blog.csdn.net/maitian_2008/article/details/127570304