-
量子笔记:量子计算 toy python implementation from scratch
目录
numpy.matrix.A, getA(), numpy.matrix.A1, getA1()
0. 概要
量子计算、量子信息、量子编程自学笔记系列。用自己能看懂的方式来表述对于量子计算基础知识的理解。
不求体系完备和逻辑严谨、但求通俗易懂。或能顺便给路过的小伙伴一些参考和启发那是纯属巧合概不认账^-^。当然,这里仅限于轮廓的勾勒和要点的连接,对逻辑体系性和完备性以及细节感兴趣的话还是要自行正儿八经地啃正经的参考书。
到目前为止已经介绍了一大堆理论知识,一直有浮在云端的感觉(我一个老实巴交的码农程序狗整那么多数学干嘛呢^-^)。所以,这一篇来上点代码,看看如何用python来模拟实现量子计算中的处理。这是python实现的第一篇,先介绍一些python实现量子计算的基本编程实现,整到哪算哪。。。
1. 量子比特表示:用二维张量表示
单量子系统的计算基底如下所示:
- qbit[0] = |0〉
- qbit[1] = |1〉
在量子态表示中,我们需要区分左矢量和右矢量,也就是行向量和列向量。当我们在谈论行向量和列向量,其实已经是在谈论二维张量或者说矩阵了(只有把向量当作矩阵来考虑时才产生了所谓的行向量和列向量之分)。由于在量子态的表示中,需要区分左矢(行向量)和右矢(列向量),因此需要用二维张量来表示。另外一个原因是后面要用到的实现张量积的函数scipy.linalg.kron()不接受向量(1阶张量类型的参数),必需是2阶及以上的张量数据类型。
- import numpy as np
- bra0 = np.array([[1,0]])
- bra1 = np.array([[0,1]])
- ket0 = bra0.T
- ket1 = bra1.T
- print(bra0)
- print(bra1)
- print(ket0)
- print(ket1)
- # ket0,1的正交性和幺正性检验
- np.testing.assert_almost_equal(np.squeeze(np.dot(bra0,ket0)), 1)
- np.testing.assert_almost_equal(np.squeeze(np.dot(bra1,ket1)), 1)
- np.testing.assert_almost_equal(np.squeeze(np.dot(bra1,ket0)), 0)
- np.testing.assert_almost_equal(np.squeeze(np.dot(bra0,ket1)), 0)
如上所示,用numpy中的2维数组来表示bra0,1和ket0,1。其中bra是shape(1,2) 的2维数组,ket是shape(2,1) 的2维数组,分别对应于行向量和列向量。运行以上代码可以得到:
[[1 0]] (1, 2) [[0 1]] (1, 2) [[1] [0]] (2, 1) [[0] [1]] (2, 1)
最后4条语句是用于进行幺正性检查的,即检查是否满足正交性以及是否满足“长度”为1。
2. 张量积的实现
2.1 用scipy.linalg.kron()实现张量积
scipy中提供kron()函数用于实现克罗内克积,也就是直积或者说张量积(scipy.linalg.kron(), numpy.kron())。
scipy.linalg.kron(a, b). The same as numpy.kron()
Parameters
a(M, N) : shape为(M,N)的多维输入数组
b(P, Q): shape为(P,Q)的多维输入数组
输出为shape=((MP,NQ))的多维数组
scipy.linalg.kron的输入数组必需为2阶或2阶以上的张量(关于张量的介绍请参考量子笔记:张量、张量的阶数与向量的维数、外积、张量积)。以下为几个张量积计算例,有兴趣的小伙伴可以先笔算一下,然后再运行以下程序段看看计算结果是否一致,这样可以有效地检验对于张量积运算的理解是否正确。
- import numpy as np
- from scipy.linalg import kron
- M = kron(np.array([[1,2],[3,4]]), np.array([[1,1,1]]))
- print(M)
- M = kron(np.array([[1,2],[3,4]]), np.array([[1,1,1],[2,2,2]]))
- print(M)
- M = kron(np.array([[1,2],[3,4]]), np.array([[[1,1,1],[2,2,2]]]))
- print(M)
前两个例子都是2阶张量之间的张量积,应该还是比较容易手写出来。但是第3个例子是一个2阶张量与一个3阶张量之间的张量积,这个要写出来就比较费劲了。更不用说涉及到更高阶张量的张量积运算了。
2.2 用张量积计算双量子系统的基
以下示例用kron()函数计算双量子系统的4个基向量。
- import numpy as np
- from scipy.linalg import kron
- bra0 = np.array([[1,0]])
- bra1 = np.array([[0,1]])
- ket0 = bra0.T
- ket1 = bra1.T
- ket00 = kron(ket0,ket0)
- ket01 = kron(ket0,ket1)
- ket10 = kron(ket1,ket0)
- ket11 = kron(ket1,ket1)
- print(ket00.T) # 为了显示方便,打印成其转置形式,即对应的bra
- print(ket01.T)
- print(ket10.T)
- print(ket11.T)
最后的结果出于打印的遍历经过了转置处理后打印成行向量的形式,打印结果如下。但是严格地来说,用*.T进行转置处理在处理一般的量子态时是不合理的,必需要用*.H(复共轭转置),这个后面会谈到。
[[1 0 0 0]] [[0 1 0 0]] [[0 0 1 0]] [[0 0 0 1]]
用同样的方式可以计算更多量子比特构成的多量子比特系统的状态空间的基。
3. 多量子系统基向量表示和生成
以下函数实现中,从string的最后1比特开始往前数。但是这个不是必然的。正序往后数也可以得到一组合法的基。但是当前这种实现可以得到比较符合直觉的基的表示。在所生成的基的one-hot表示中,1的位序号恰好等于对应的Qubits的二进制表示的值。比如说|00〉|00〉对应的[1,0,0,0], |01〉|01〉对应的[0,1,0,0],etc
n-Qubits系统有
2 n 2 n 2 n 3.1 Helper function: bin_ext
为了方便后面的实现,先写一个基于python的bin()函数扩展实现的bin_ext函数。Python bin()用于将十进制数转换为二进制字符串,带0b前缀,不保留头上的零(leading zeros)。如下所示:
Python bin() function returns the binary string of a given integer.
Syntax: bin(a)
Parameters : a : an integer to convert
Return Value : A binary string of an integer or int object.
- print(bin(100))
- print(bin(26))
- print(bin(26007))
运行结果:
0b1100100 0b11010 0b110010110010111
本扩展函数bin_ext()通过参数控制是否保留leading zeros,以及是否保留“0b”前缀。
- def bin_ext(num, keep_leading_zeros = True, N=16, keep_prefix = True):
- # Convert num to binary representation
- num_binstr = bin(num)[2:]
- #print(num_binstr)
- if keep_leading_zeros:
- num_binstr = '0'*(N - len(num_binstr)) + num_binstr
- #print(num_binstr)
- if keep_prefix:
- num_binstr = '0b'+num_binstr
- return num_binstr
- print(bin_ext(10))
- print(bin_ext(140, keep_leading_zeros = True, N=10))
- print(bin_ext(10, True, 16, False))
运行结果如下:
0b0000000000001010 0b0010001100 0000000000001010
3.2 多量子系统的基的生成
以下函数用于计算由N个量子比特构成的量子系统的序号为k(从0开始)的计算基的坐标向量(one-hot)表示。当然,所谓序号是人为指定的,如下所述,只不过恰好是表示张量积的二进制字符串所对应的十进制数。虽然,不是必然的,但是却是使用起来最方便的。
以下函数实现中,从bibstr的最后1比特开始往前数(binstr[::-1]表示将字符串倒序)。但是这个不是必然的。正序往后数也可以得到一组合法的基。但是这种实现方式可以得到比较符合直觉的基的表示。在所生成的基的one-hot表示中,1的位序号恰好等于对应的Qubits的二进制表示的数值。比如说|000〉对应的[1,0,0,0,0,0,0,0], |001〉对应的[0,1,0,0,0,0,0,0],|010〉对应的[0,0,1,0,0,0,0,0],...比如说"010"是十进制数2的二进制表示,它的one-hont表示中恰好是bit[2]为1,其余为0,余者以此类推。
- def multi_qbits_basis(k,N):
- """
- N: number of qbits
- k: integer representation of the basis vector
- """
- binstr = bin_ext(k, True, N, False)
- res = np.array([[1]])
- # 从最后一位开始往前数,做直积
- for idx in binstr[::-1]:
- # for idx in string:
- # print(idx, bit[int(idx)], res)
- res = kron(bit[int(idx)],res)
- return np.matrix(res)
- print(multi_qbits_basis(3,4).T)
- print(multi_qbits_basis(13,5).T)
- N = 3
- for k in range(2**N):
- print('basis{0} = {1}'.format(k,multi_qbits_basis(k,N).T))
运行结果如下:
[[0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0]] [[0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0]] basis0 = [[1 0 0 0 0 0 0 0]] basis1 = [[0 1 0 0 0 0 0 0]] basis2 = [[0 0 1 0 0 0 0 0]] basis3 = [[0 0 0 1 0 0 0 0]] basis4 = [[0 0 0 0 1 0 0 0]] basis5 = [[0 0 0 0 0 1 0 0]] basis6 = [[0 0 0 0 0 0 1 0]] basis7 = [[0 0 0 0 0 0 0 1]]
3.3 numpy.matrix
在以上multi_qbits_basis实现中,最后输出结果转换成numpy.matrix输出了。那numpy matrix是个什么东东呢?
numpy matrix是numpy ndarray的一个子类。其目的其实就是提供一个matlab matrix的对应物,提供更为直观的矩阵运算,包括矩阵数据的处理,矩阵的计算,以及基本的统计功能,转置,可逆性等等,包括对复数的处理,均在matrix对象中。
关于numpy中矩阵和二维数组的取舍
numpy matrix和numpy array在很多时候都是通用的,matrix的优势就是相对直观的运算处理方式(更符合线性代数课上学到的东西),但官方建议如果两个可以通用,那就选择array,因为array更灵活,速度更快。事实上官网上甚至建议不要使用numpy matrix(numpy.matrix — NumPy v1.23 Manual):
Note
It is no longer recommended to use this class, even for linear algebra. Instead use regular arrays. The class may be removed in the future.
但是本文中还是使用了numpy matrix,原因在于numpy matrix提供了numpy.matrix.H property(Returns the (complex) conjugate transpose of self.),(对于复数域的矩阵运算来说)使用比较方便。
numpy.matrix.A, getA(), numpy.matrix.A1, getA1()
使用属性A或者函数getA()可以将numpy matrix变换为numpy ndarray对象。进一步属性A1和函数getA1()则将矩阵转换为ndarray的同时还将其展平(flattern)为1-D。
如以下代码所示:
- x = np.matrix(np.arange(12).reshape((3,4)));
- print(x, type(x))
- print(x.A, type(x.A))
- print(x.getA(), type(x.getA()))
- print(x.A1, type(x.A1))
- print(x.getA1(), type(x.getA1()))
[[ 0 1 2 3] [ 4 5 6 7] [ 8 9 10 11]]
[[ 0 1 2 3] [ 4 5 6 7] [ 8 9 10 11]] [[ 0 1 2 3] [ 4 5 6 7] [ 8 9 10 11]] [ 0 1 2 3 4 5 6 7 8 9 10 11] [ 0 1 2 3 4 5 6 7 8 9 10 11] 4. 基向量生成器
n个Qbits的系统状态空间可以用希尔伯特空间(Hilbert Space)
C 2 ⊗ n 该希尔伯特空间维数为
2 n 2 n 因为希尔伯特空间的维数为
2 n - def basis_generator(nbit=5):
- """
- Generate binary string representation of hilbert space basis, and return a generator.
- """
- nspace = 2**nbit
- for i in range(nspace):
- yield multi_qbits_basis(i,nbit)
- # Test of basis_generator()
- for k, mi in enumerate(basis_generator(nbit=3)):
- print('basis[{0}] = {1}'.format(k,mi.T), end='\n')
以上测试代码运行结果如下:
basis[0] = [[1 0 0 0 0 0 0 0]] basis[1] = [[0 1 0 0 0 0 0 0]] basis[2] = [[0 0 1 0 0 0 0 0]] basis[3] = [[0 0 0 1 0 0 0 0]] basis[4] = [[0 0 0 0 1 0 0 0]] basis[5] = [[0 0 0 0 0 1 0 0]] basis[6] = [[0 0 0 0 0 0 1 0]] basis[7] = [[0 0 0 0 0 0 0 1]]
5. 构造任意量子叠加态
任意量子系统状态(也称波函数)是各个基向量的线性叠加,系数为复数,称为振幅。复振幅系数的平方则代表坍缩到各基态的概率。
| ψ ⟩ = ∑ i c i | ϕ i ⟩ " role="presentation" style="position: relative;">量子(叠加)态必须满足幺正性,即各复系数绝对值平方和必须等于1。以下函数中最后进行了幺正性检查。其中 s.H 计算了 |𝑠〉 的转置共轭 〈𝑠| ,也称 |𝑠〉 的厄密特,也即右矢对应的左矢(或左矢对应的右矢)。
5.1 superposition1
- def superposition1(coef, nbits):
- '''返回n量子系统中由所有基向量构成的任意量子叠加态。其系数由coef数组指定
- input:
- seqs: sequence of binary string representation of basis vector, shoule be converted to one-hot representation before being used.
- output:
- The linear combination of basis vectors
- '''
- res = 0
- for k, basis in enumerate(basis_generator(nbits)):
- res += coef[k] * basis
- np.testing.assert_almost_equal(res.H * res , 1) # unitarity check, 幺正性检验
- return np.matrix(res)
使用该函数可以通过指定系数生成任意n比特量子系统的叠加态(基于计算基底):
- # Test of superposition1()
- coef = [1j/np.sqrt(2), np.sqrt(1/2)]
- nbits = 1
- s = superposition1(coef, nbits)
- print(s)
- coef = [1j/2, 0, 1/2, np.sqrt(1/2)]
- nbits = 2
- s = superposition1(coef, nbits)
- print(s)
运算结果如下:
[[0. +0.70710678j] [0.70710678+0.j ]] [[0. +0.5j] [0. +0.j ] [0.5 +0.j ] [0.70710678+0.j ]]
5.2 superposition2
superposition1()是针对N比特量子系统针对所有的基指定系数序列(即便为0也指定)。但是当N比较大时,如果非零系数个数比较少,可能仅指定非零系数更加方便。以下这个函数用于这种方式的实现,其中basis_vecs指定与coef对应的具有非零系数的基向量序号(以整数方式表示)。
- def superposition2(coef, basis_vecs, nbits):
- '''返回n量子系统中由指定基向量构成的任意量子叠加态。其系数由coef数组指定
- input:
- seqs: sequence of binary string representation of basis vector, shoule be converted to one-hot representation before being used.
- output:
- The linear combination of basis vectors
- '''
- res = 0
- for k, basis in enumerate(basis_vecs):
- res += coef[k] * multi_qbits_basis(basis,nbits)
- np.testing.assert_almost_equal(res.H * res , 1) # unitarity check, 幺正性检验
- return np.matrix(res)
调用示例代码如下:
- # Test of superposition2()
- coef = [1j/np.sqrt(2), np.sqrt(1/2)]
- nbits = 2
- s = superposition2(coef, [1,3], nbits)
- print(s)
- coef = [1j/2, 1/2, np.sqrt(1/2)]
- nbits = 3
- s = superposition2(coef, [1,3,5], nbits)
- print(s, s.H * s)
运行结果如下所示(第2个中,coef包含三个系数,basis_vec=[1,3,5],表示coef指定的系数分别对应于
| 001 ⟩ , | 011 ⟩ , | 101 ⟩ " role="presentation" style="position: relative;"> ):[[0. +0.j ] [0. +0.70710678j] [0. +0.j ] [0.70710678+0.j ]] [[0. +0.j ] [0. +0.5j] [0. +0.j ] [0.5 +0.j ] [0. +0.j ] [0.70710678+0.j ] [0. +0.j ] [0. +0.j ]] [[1.+0.j]]
5.3 纠缠态 vs 可分离态
可以分解为各单量子态的张量积形式的多量子态称为可分离态,反之,不能分离的就是纠缠态。 比如说,以下这个三量子系统状态就是一个可分离态:
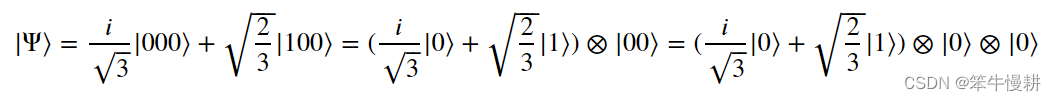
以下这个双量子态也是可分离态:
| ψ ⟩ = 1 2 ( | 00 ⟩ + | 01 ⟩ + | 10 ⟩ + | 11 ⟩ ) = 1 2 ( | 0 ⟩ + | 1 ⟩ ) ⊗ ( | 0 ⟩ + | 1 ⟩ ) ) | 而下面这个双量子态就不能展开为张量积形式,所以是纠缠态:
| ψ ⟩ = 1 2 ( | 01 ⟩ + | 10 ⟩ ) " role="presentation" style="position: relative;">量子力学中两个费米子的纠缠态就可以用以上这个双量子态来表示。费米子的量子态由自旋决定,有两种自旋,一种是向上spin up,另一种是向下spin down。两个纠缠在一起的费米子构成的双量子系统的总自旋为0。但是,没有人知道哪个自旋向上,哪个自旋向下。系统处于纠缠的叠加态。对其中任何一个进行测量,如果得到的结果是自旋向上,那么另一个也必定坍缩到自旋向下(因为自旋守恒);反之如果得到的结果是自旋向下,则另一个必定坍缩到自旋向上。
无论是对哪个进行测量,结果都是这样(测量了其中一个导致其状态坍缩,同时也就知道了另外一个的状态),无论两者相距多远,似乎它们能够跨越遥远的空间以超光速的方式心灵感应。这就是爱因斯坦说的鬼魅般的超距相互作用。
量子系统纠缠与否的判定
前面章节中介绍过双量子系统的叠加态是否是纠缠态的简易判断准则(量子笔记:量子纠缠祛魅,贝尔纠缠态):
对于形如
双量子叠加态是不是属于纠缠态,有一个简单的判决准则是:
如果以上这个等式成立,则该式子是可以进行张量积分解的,即代表可分离态;反之,如果不成立,则说明这个式子是不能进行张量积分解的,也就是属于纠缠态。
那多量子比特(n>=3)的量子系统状态有没有以上这样简易的判决准则呢?
6. 波函数投影和分解、基底变换
通常情况下我们都是以计算基底下的坐标向量的形式来表示量子态(波函数)。
但是有时候也会需要变换到其它基底下去。
6.1 投影和分解
波函数投影到某个指定基底所得的振幅系数可以通过波函数的左矢与该基底的右矢的内积运算而得。如下所示:
c i = ⟨ ϕ i | ψ ⟩ " role="presentation" style="position: relative;">进一步,针对一组基底,分别求得波函数投影到各基底的振幅系数,即得到波函数在该组基底下的分解。如下所示:
| ψ ⟩ = ∑ i c i | ϕ i ⟩ = ∑ i ⟨ ϕ i | ψ ⟩ ⋅ | ϕ i ⟩ " role="presentation" style="position: relative;">注意,也有写做
c i = ⟨ ψ | ϕ i ⟩ " role="presentation" style="position: relative;">,但是将波函数变为左矢(右矢的复共轭转置)使得对应的系数也变成的复共轭,所以计算出来的投影系数为原来的系数的共轭。我们定义以下函数来实现投影和分解。
- def project(psi, basis):
- '''
to get the projected coefficient ''' - return basis.H * psi
- def decompose(psi, basis_mat):
- '''
- 将叠加态波函数针对指定的基底进行分解.
- psi: 输入叠加态波函数
- basis_mat:
- np.matrix类型。指定的基底集合,以矩阵的形式表示,每一列表示一个基向量
- 注意,由于需要利用*.H的运算,所以必需是np.matrix类型,普通的np.ndarray没有.H的属性。
- psi和basis_mat都是相对计算基底的表示
- '''
- coefs = []
- for k in range(basis_mat.shape[1]):
- #print(k,basis_mat[:,k].H)
- coefs.append(project(psi,basis_mat[:,k]))
- return coefs
以下测试中,先用superposition()函数生成叠加态,然后再用decompose()进行分解。两个函数互为逆处理,两者都工作正确的话,最后应该恢复出原始的系数coef。 当然,这个只是
- # test project() and decompose()
- coef = [1j/np.sqrt(2), 1j/np.sqrt(2)]
- nbits = 2
- s = superposition2(coef, [1,3], nbits)
- print(s)
- computation_basis = np.matrix([[1,0,0,0],[0,1,0,0],[0,0,1,0],[0,0,0,1]]).H
- coef1 = decompose(s,computation_basis)
- print(coef1)
运行结果如下:
[[0.+0.j ] [0.+0.70710678j] [0.+0.j ] [0.+0.70710678j]] [matrix([[0.+0.j]]), matrix([[0.+0.70710678j]]), matrix([[0.+0.j]]), matrix([[0.+0.70710678j]])]
- # random test of project() and decompose()
- nbits = 3
- # 生成2**nbits个随机复系数
- coef = np.random.random([2**nbits,]) + 1j * np.random.random([2**nbits,])
- # 归一化
- norm_factor = np.sqrt(np.sum(np.conj(coef) * coef))
- print(norm_factor)
- coef = coef / norm_factor
- np.testing.assert_almost_equal(1, np.sum(np.conj(coef) * coef)) # 归一化后满足概率和等于1
- print(coef, type(coef))
- # 生成叠加态
- s = superposition1(coef, nbits)
- # 分解
- computation_basis = np.zeros([2**nbits, 2**nbits])
- for k, basis_k in enumerate(basis_generator(nbits)):
- #print(k,basis_k)
- computation_basis[:,k] = np.squeeze(basis_k)
- print(computation_basis)
- coef1 = decompose(s, np.matrix(computation_basis))
- print(coef1)
运行以上测试代码可以得到:
(2.165212496837334+0j) [0.26504767+0.32357524j 0.35633515+0.11254125j 0.26048141+0.33595667j 0.18204604+0.386526j 0.23181745+0.26564862j 0.34037746+0.10183365j 0.18917889+0.07431278j 0.14806314+0.09153582j]
[[1. 0. 0. 0. 0. 0. 0. 0.] [0. 1. 0. 0. 0. 0. 0. 0.] [0. 0. 1. 0. 0. 0. 0. 0.] [0. 0. 0. 1. 0. 0. 0. 0.] [0. 0. 0. 0. 1. 0. 0. 0.] [0. 0. 0. 0. 0. 1. 0. 0.] [0. 0. 0. 0. 0. 0. 1. 0.] [0. 0. 0. 0. 0. 0. 0. 1.]] [matrix([[0.26504767+0.32357524j]]), matrix([[0.35633515+0.11254125j]]), matrix([[0.26048141+0.33595667j]]), matrix([[0.18204604+0.386526j]]), matrix([[0.23181745+0.26564862j]]), matrix([[0.34037746+0.10183365j]]), matrix([[0.18917889+0.07431278j]]), matrix([[0.14806314+0.09153582j]])] 当然,以上测试代码中叠加态的生成以及投影分解都是在相同的计算基底下进行的,叠加态生成和投影分解(在同一基底下)是互逆的,分解的结果与最初用于生成叠加态的系数应该是相同的。这个当然并不是什么很有趣的事情,其目的只是对代码进行一个sanity check。投影分解的更有趣的应用应该是在当基底发生变换时的情况。
6.2 基底变换
如上节的波函数的新的基底下的分解所示,[〈𝜓|𝜙0〉,〈𝜓|𝜙1〉,...].𝑇相当于就是波函数在该新的基底下的坐标向量。从该波函数在原基底下的坐标向量到在新基底下的坐标向量的变换就称为基底变换。同一个波函数在不同基底下的坐标向量是不同的,所以严格地来说,将波函数写成坐标向量的形式是需要表明它对应的基底的。但是一般来说,缺省地认为是采用计算基底,在计算基底下的坐标向量不必特意标明基底,但是在其它基底下的坐标向量表示则需要注明对应基底。
根据线性代数理论,我们知道向量空间的基地变换可以用矩阵来表示。
未完待续。。。coming soon。。。
回到本系列主目录:
量子笔记:量子计算祛魅
 https://chenxiaoyuan.blog.csdn.net/article/details/127251274
https://chenxiaoyuan.blog.csdn.net/article/details/127251274 参考:
-
相关阅读:
keil调试的时候没问题,下载时候没反应
[pwn基础]Linux安全机制
数据中台选型必读(四):要想中台建的好,数据模型得做好
android 校验字符串是否蓝牙地址的方法
HTML基础学习第三课(列表的创建、有序和无序)
window laptop install unbuntu and tensorflow-gpu
力扣:322. 零钱兑换
GCC 学习
OpenCV视频防抖技术解析
使用s3 api访问AWS S3服务
- 原文地址:https://blog.csdn.net/chenxy_bwave/article/details/127555119
