-
LeetCode刷题复盘笔记——491. 递增子序列(一文搞懂回溯解决递增子序列问题)
今日主要总结一下,491. 递增子序列
题目:491. 递增子序列
题目描述:
给你一个整数数组 nums ,找出并返回所有该数组中不同的递增子序列,递增子序列中 至少有两个元素 。你可以按 任意顺序 返回答案。数组中可能含有重复元素,如出现两个整数相等,也可以视作递增序列的一种特殊情况。
示例 1:
输入:nums = [4,6,7,7]
输出:[[4,6],[4,6,7],[4,6,7,7],[4,7],[4,7,7],[6,7],[6,7,7],[7,7]]示例 2:
输入:nums = [4,4,3,2,1]
输出:[[4,4]]提示:
1 <= nums.length <= 15
-100 <= nums[i] <= 100本题重难点
这个递增子序列比较像是取有序的子集。而且本题也要求不能有相同的递增子序列。
这又是子集,又是去重,是不是不由自主的想起了刚刚讲过的90.子集II
就是因为太像了,更要注意差别所在,要不就掉坑里了!
在90.子集II 中我们是通过排序,再加一个标记数组来达到去重的目的。
而本题求自增子序列,是不能对原数组经行排序的,排完序的数组都是自增子序列了。
所以不能使用之前的去重逻辑!
看一下这道题抽象成的树形图:
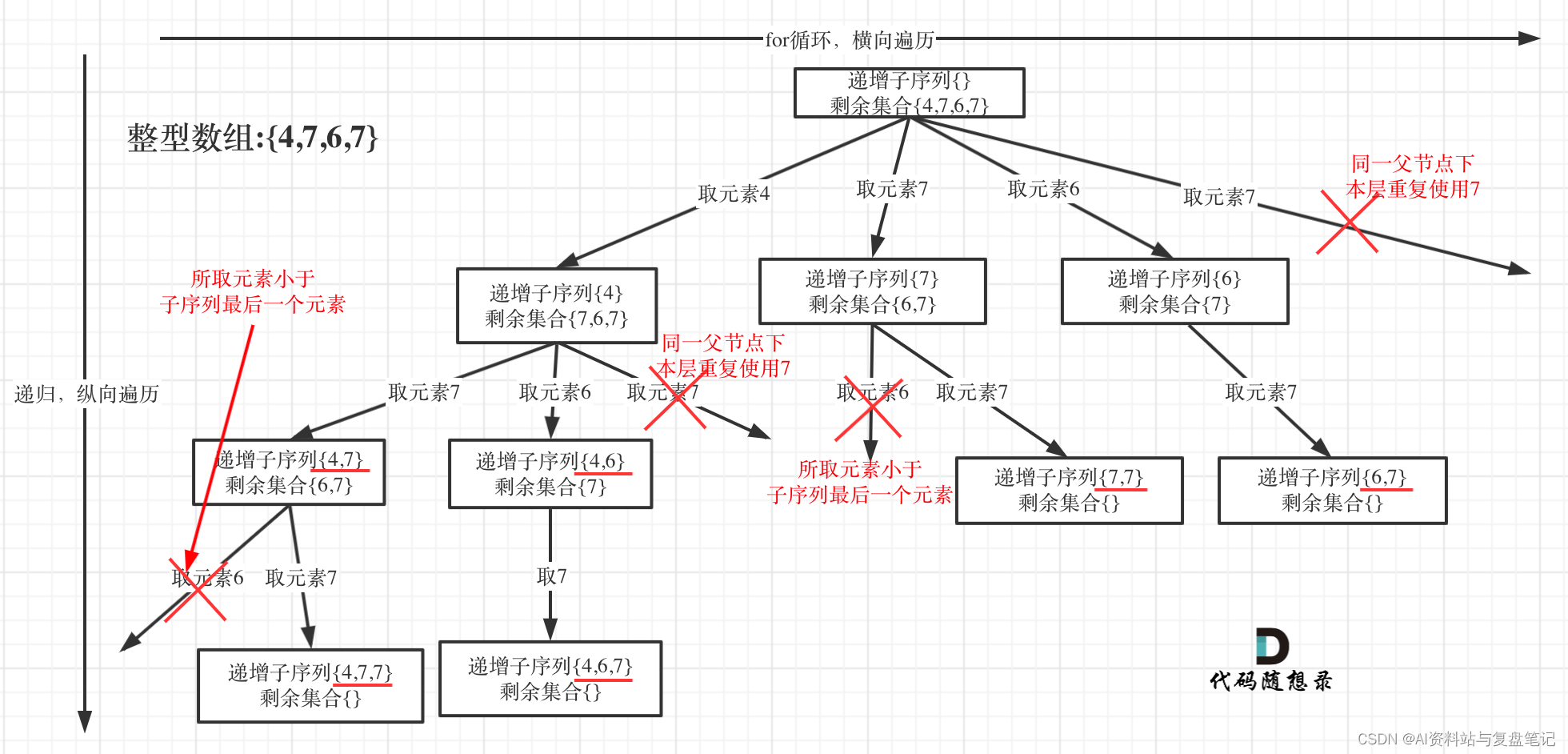
不能对原数组排序时去重方法:
使用unordered_set(或者当数组元素取值范围较小时使用数组来代替set可以优化时间复杂度)来记录上图中每一层的节点元素是否使用过,如果多个节点元素
的数值大小相同,则第二次及之后再次遍历到时需要去重剪枝!(树层剪枝)一、未优化解法
C++代码
class Solution { public: vector<int> path; vector<vector<int>> res; void backtracing(vector<int>& nums, int startIndex){ if(path.size() > 1){ res.push_back(path); } unordered_set<int> uset; for(int i = startIndex; i < nums.size(); i++){ if(!path.empty() && nums[i] < path.back() || uset.find(nums[i]) != uset.end()) continue; uset.insert(nums[i]); path.push_back(nums[i]); backtracing(nums, i + 1); path.pop_back(); } return; } vector<vector<int>> findSubsequences(vector<int>& nums) { path.clear(); res.clear(); backtracing(nums, 0); return res; } };- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
二、优化解法
优化思路
程序运行的时候对unordered_set 频繁的insert,unordered_set需要做哈希映射(也就是把key通过hash function映射为唯一的哈希值)相对费时间,而且每次重新定义set,insert的时候其底层的符号表也要做相应的扩充,也是费事的。
所以针对方法一的优化代码就是把unordered_set 用数组来代替,从而优化时间复杂度)
C++代码
class Solution { public: vector<int> path; vector<vector<int>> res; void backtracing(vector<int>& nums, int startIndex){ if(path.size() > 1){ res.push_back(path); } vector<int> used(201, 0); for(int i = startIndex; i < nums.size(); i++){ if(!path.empty() && nums[i] < path.back() || used[nums[i] + 100] == 1) continue; used[nums[i] + 100] = 1; path.push_back(nums[i]); backtracing(nums, i + 1); path.pop_back(); } return; } vector<vector<int>> findSubsequences(vector<int>& nums) { path.clear(); res.clear(); backtracing(nums, 0); return res; } };- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
总结
这个递增子序列比较像是取有序的子集。而且本题也要求不能有相同的递增子序列。
这又是子集,又是去重,是不是不由自主的想起了刚刚讲过的90.子集II
就是因为太像了,更要注意差别所在,要不就掉坑里了!
在90.子集II 中我们是通过排序,再加一个标记数组来达到去重的目的。
而本题求自增子序列,是不能对原数组经行排序的,排完序的数组都是自增子序列了。
所以不能使用之前的去重逻辑!
不能对原数组排序时去重方法:
使用unordered_set(或者当数组元素取值范围较小时使用数组来代替set可以优化时间复杂度)来记录上图中每一层的节点元素是否使用过,如果多个节点元素
的数值大小相同,则第二次及之后再次遍历到时需要去重剪枝!(树层剪枝)
欢迎大家关注本人公众号:编程复盘与思考随笔
(关注后可以免费获得本人在csdn发布的资源源码)
公众号主要记录编程和刷题时的总结复盘笔记和心得!并且分享读书、工作、生活中的一些思考感悟!
-
相关阅读:
Mysql 约束,基本查询,复合查询与函数
MySQL用户也可以是个角色
【SpringBoot】12.SpringBoot整合Dubbo+Zookeeper
指针进阶(一)
Laravel 第七章 回复数据
Git基础(21):GitLab创建组、用户、项目
spring上传文件
vue 本地上传Excel文件并读取内容
某大型建设公司薪酬体系设计项目成功案例纪实
perl use HTTP::Server::Simple 轻量级 http server
- 原文地址:https://blog.csdn.net/qq_43498345/article/details/127562221