-
Knowledge Distillation with the Reused Teacher Classifier论文阅读+代码解析
一. 介绍
给定一个具有大量参数的强大教师模型,知识蒸馏(KD)的目标是帮助另一个参数化较少的学生模型获得与较大的教师模型相似的泛化能力。实现这一目标的一种直接方法是在给定相同输入的情况下对齐它们的logits或类预测。由于KD技术概念简单,实用有效,在各种应用中都取得了巨大的成功。
在知识蒸馏中,学生模型和教师模型的差距成为一项关键性的挑战。
在本文中,我们提出了一个简单的知识蒸馏技术,并证明它可以显著弥合教师和学生模型之间的性能差距,而不需要详细的知识表示。我们提出的“SimKD”技术如下图所示。我们认为,教师模型强大的班级预测能力不仅归功于这些表达特征,而且同样重要的是,一个鉴别分类器。基于这一论点,我们在分类器的上一层通过特征对齐来训练学生模型,并直接复制教师分类器进行学生推理。这样,如果我们能将学生的特征与教师模型的特征完美地对齐,他们的表现差距就会消失。也就是说,单独的特征对齐错误解释了学生推理的准确性,这使得我们的知识转移更容易理解。根据我们的实验结果,单个 l 2 l_2 l2损失的特征对齐已经出奇地好。如此简单的损耗使我们不必像以前的工作那样仔细地调优超参数,以平衡多个损耗的影响。
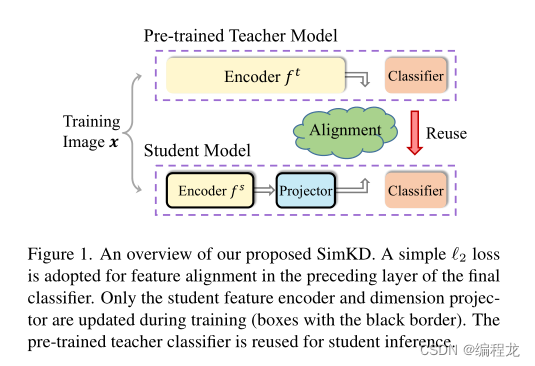
二. 方法
2.1 标准的知识蒸馏模块
一般来说,当前流行的为图像分类任务设计的深度神经网络可以看作是一个具有多个非线性层的特征编码器(特征提取层)与一个通常包含单个具有softmax激活函数的全连接层的分类器进行组合的结构。这两个组件都将通过反向传播算法进行端到端训练。
给定一个训练样本 x \boldsymbol{x} x以及其对应的标签 y \boldsymbol{y} y,我们可以使用特征提取参数进行特征的计算: f s = F s ( x ; θ s ) ∈ R C s \boldsymbol{f}^s=\mathcal{F}^s\left(\boldsymbol{x} ; \boldsymbol{\theta}^s\right) \in \mathbb{R}^{C_s} fs=Fs(x;θs)∈RCs。该特性随后通过权重 W s ∈ R K × C s \boldsymbol{W}^s \in \mathbb{R}^{K \times C_s} Ws∈RK×Cs传递给分类器,从而获得输出: g s = W s f s ∈ R K \boldsymbol{g}^s=\boldsymbol{W}^s \boldsymbol{f}^s \in \mathbb{R}^K gs=Wsfs∈RK,之后使用一个激活函数(softmax)计算类的预测损失 p s = σ ( g s / T ) ∈ R K \boldsymbol{p}^s=\sigma\left(\boldsymbol{g}^s / T\right) \in \mathbb{R}^K ps=σ(gs/T)∈RK,其中计算如下:
p i s = exp ( g i s / T ) ∑ j = 1 K exp ( g j s / T ) , (1) p_i^s=\frac{\exp \left(g_i^s / T\right)}{\sum_{j=1}^K \exp \left(g_j^s / T\right)}, \tag1 pis=∑j=1Kexp(gjs/T)exp(gis/T),(1)
这里的 i i i表示为第 i i i个样本。 T T T为一个温度的超参数负责软化输出结果。
传统的知识蒸馏由两部分组成:一个是交叉熵损失,另一个是KL距离的损失:
L K D = L C E ( y , p s ) ⏟ T = 1 + T 2 L K L ( p t , p s ) ⏟ T > 1 . (2) \mathcal{L}_{\mathrm{KD}}=\underbrace{\mathcal{L}_{\mathrm{CE}}\left(\boldsymbol{y}, \boldsymbol{p}^s\right)}_{T=1}+\underbrace{T^2 \mathcal{L}_{\mathrm{KL}}\left(\boldsymbol{p}^t, \boldsymbol{p}^s\right)}_{T>1} . \tag2 LKD=T=1 LCE(y,ps)+T>1 T2LKL(pt,ps).(2)2.2 简单的知识蒸馏(本文的方法)
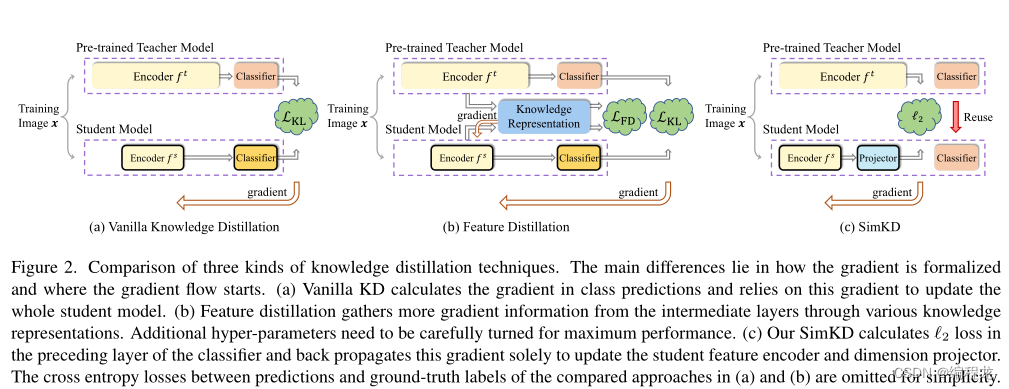
近年来,提出了各种特征蒸馏方法。这些工作主要是从中级师生层对中收集和传输额外的梯度信息,以便更好地训练学生特征编码器(上图(b))。然而,它们的成功在很大程度上依赖于那些特别设计的知识表示,以包含适当的归纳偏差,以及精心选择的超参数来平衡不同损失的影响。两者都是劳动密集型和耗时的。也很难断定某一类型的表征在学生培养中所起的实际作用。
相反,我们提出了一种简单的知识蒸馏技术,称为SimKD,它摆脱了这些严格的要求,同时在大量的实验中仍然获得了最先进的结果。如上图©所示,SimKD的一个关键组成部分是“分类器重用”操作,即我们直接借用预先训练好的教师分类器进行学生推理,而不是训练一个新的分类器。这样就不需要用标签信息来计算交叉熵损失,使得特征对齐损失成为产生梯度的唯一来源。
我们认为教师分类器中包含的鉴别信息很重要,但在KD的文献中很大程度上被忽略了。然后,我们为它的重要作用提供了一个合理的解释。考虑这样一种情况,一个模型被要求处理几个具有不同数据分布的任务,一个基本的做法是冻结或共享一些浅层作为跨不同任务的特征提取器,同时微调最后一层以学习特定于任务的信息。在这种单模型多任务设置中,现有研究认为任务不变信息可以共享,而任务特定信息需要独立识别,通常由最终分类器进行识别。对于在同一数据集上训练具有不同能力的教师和学生模型的KD,类似地,我们可以合理地认为,数据中有一些能力不变的信息很容易通过不同的模型获得,而强大的教师模型可能包含额外的基本的能力特定信息,而简单的学生模型很难获得。此外,我们假设大多数特定于能力的信息包含在深层中,并期望重用这些层,甚至只有最后的分类器将有助于学生的训练。
基于这一假设,我们为学生模型提供了教师分类器进行推理,并强制其提取的特征与下面的这个 l 2 l_2 l2损失函数相匹配:
L SimKD = ∥ f t − P ( f s ) ∥ 2 2 , (3) \mathcal{L}_{\text {SimKD }}=\left\|\boldsymbol{f}^t-\mathcal{P}\left(\boldsymbol{f}^s\right)\right\|_2^2, \tag3 LSimKD =∥ ∥ft−P(fs)∥ ∥22,(3)
其中 P \mathcal{P} P表示为将学生网络的特征输出与教师网络的特征输出进行对齐的函数。
有些令人惊讶的是,通过这种简单的技术,师生压缩中的性能下降将得到极大的缓解。随着高推理精度,这种单损失公式的简单性为我们的SimKD提供了良好的解释性。注意,来自预训练的教师模型的重用部分被允许合并更多的层,但不限于最终的分类器。通常情况下,重用的层数越多,学生的准确率越高,但会增加推理的负担。三. 代码解析
代码地址点这里
(本文的教师网络模型需要进行预训练)
在本方法中,教师网络和学生网络直接使用普通的的卷积神经网络即可(如ResNet18),这里没有变化,而本文中我们需要重新利用教师网络的分类器的功能,同时需要保证学生网络和教师网路特征输出大小一致,这里添加了一个新的中间网络层,如下:class SimKD(nn.Module): """CVPR-2022: Knowledge Distillation with the Reused Teacher Classifier""" """ s_n为学生模型输入的特征的大小,t_n为教师模型输出的特征大小""" def __init__(self, *, s_n, t_n, factor=2): super(SimKD, self).__init__() self.avg_pool = nn.AdaptiveAvgPool2d((1,1)) def conv1x1(in_channels, out_channels, stride=1): return nn.Conv2d(in_channels, out_channels, kernel_size=1, padding=0, stride=stride, bias=False) def conv3x3(in_channels, out_channels, stride=1, groups=1): return nn.Conv2d(in_channels, out_channels, kernel_size=3, padding=1, stride=stride, bias=False, groups=groups) # A bottleneck design to reduce extra parameters setattr(self, 'transfer', nn.Sequential( conv1x1(s_n, t_n//factor), nn.BatchNorm2d(t_n//factor), nn.ReLU(inplace=True), conv3x3(t_n//factor, t_n//factor), # depthwise convolution #conv3x3(t_n//factor, t_n//factor, groups=t_n//factor), nn.BatchNorm2d(t_n//factor), nn.ReLU(inplace=True), conv1x1(t_n//factor, t_n), nn.BatchNorm2d(t_n), nn.ReLU(inplace=True), )) def forward(self, feat_s, feat_t, cls_t): # Spatial Dimension Alignment s_H, t_H = feat_s.shape[2], feat_t.shape[2] if s_H > t_H: source = F.adaptive_avg_pool2d(feat_s, (t_H, t_H)) target = feat_t else: source = feat_s target = F.adaptive_avg_pool2d(feat_t, (s_H, s_H)) trans_feat_t=target # Channel Alignment trans_feat_s = getattr(self, 'transfer')(source) # Prediction via Teacher Classifier temp_feat = self.avg_pool(trans_feat_s) temp_feat = temp_feat.view(temp_feat.size(0), -1) pred_feat_s = cls_t(temp_feat) return trans_feat_s, trans_feat_t, pred_feat_s- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
有了这3个部分后,我们依次传入一个module_list(顺序为学生网络,特征转换网络,教师网络),之后就可以开始训练,如下:
def train_distill(epoch, train_loader, module_list, criterion_list, optimizer, opt): """one epoch distillation""" # set modules as train() for module in module_list: module.train() # set teacher as eval() module_list[-1].eval() criterion_cls = criterion_list[0] criterion_div = criterion_list[1] criterion_kd = criterion_list[2] model_s = module_list[0] model_t = module_list[-1] batch_time = AverageMeter() losses = AverageMeter() top1 = AverageMeter() top5 = AverageMeter() n_batch = len(train_loader) if opt.dali is None else (train_loader._size + opt.batch_size - 1) // opt.batch_size end = time.time() for idx, data in enumerate(train_loader): if opt.dali is None: if opt.distill in ['crd']: images, labels, index, contrast_idx = data else: images, labels = data else: images, labels = data[0]['data'], data[0]['label'].squeeze().long() if opt.distill == 'semckd' and images.shape[0] < opt.batch_size: continue if opt.gpu is not None: images = images.cuda(opt.gpu if opt.multiprocessing_distributed else 0, non_blocking=True) if torch.cuda.is_available(): labels = labels.cuda(opt.gpu if opt.multiprocessing_distributed else 0, non_blocking=True) if opt.distill in ['crd']: index = index.cuda() contrast_idx = contrast_idx.cuda() # ===================forward===================== feat_s, logit_s = model_s(images, is_feat=True) with torch.no_grad(): feat_t, logit_t = model_t(images, is_feat=True) feat_t = [f.detach() for f in feat_t] cls_t = model_t.module.get_feat_modules()[-1] if opt.multiprocessing_distributed else model_t.get_feat_modules()[-1] # cls + kl div loss_cls = criterion_cls(logit_s, labels) loss_div = criterion_div(logit_s, logit_t) # other kd loss trans_feat_s, trans_feat_t, pred_feat_s = module_list[1](feat_s[-2], feat_t[-2], cls_t) logit_s = pred_feat_s loss_kd = criterion_kd(trans_feat_s, trans_feat_t) loss = opt.cls * loss_cls + opt.div * loss_div + opt.beta * loss_kd losses.update(loss.item(), images.size(0)) # ===================Metrics===================== metrics = accuracy(logit_s, labels, topk=(1, 5)) top1.update(metrics[0].item(), images.size(0)) top5.update(metrics[1].item(), images.size(0)) batch_time.update(time.time() - end) # ===================backward===================== optimizer.zero_grad() loss.backward() optimizer.step() # print info if idx % opt.print_freq == 0: print('Epoch: [{0}][{1}/{2}]\t' 'GPU {3}\t' 'Time: {batch_time.avg:.3f}\t' 'Loss {loss.avg:.4f}\t' 'Acc@1 {top1.avg:.3f}\t' 'Acc@5 {top5.avg:.3f}'.format( epoch, idx, n_batch, opt.gpu, loss=losses, top1=top1, top5=top5, batch_time=batch_time)) sys.stdout.flush() return top1.avg, top5.avg, losses.avg- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
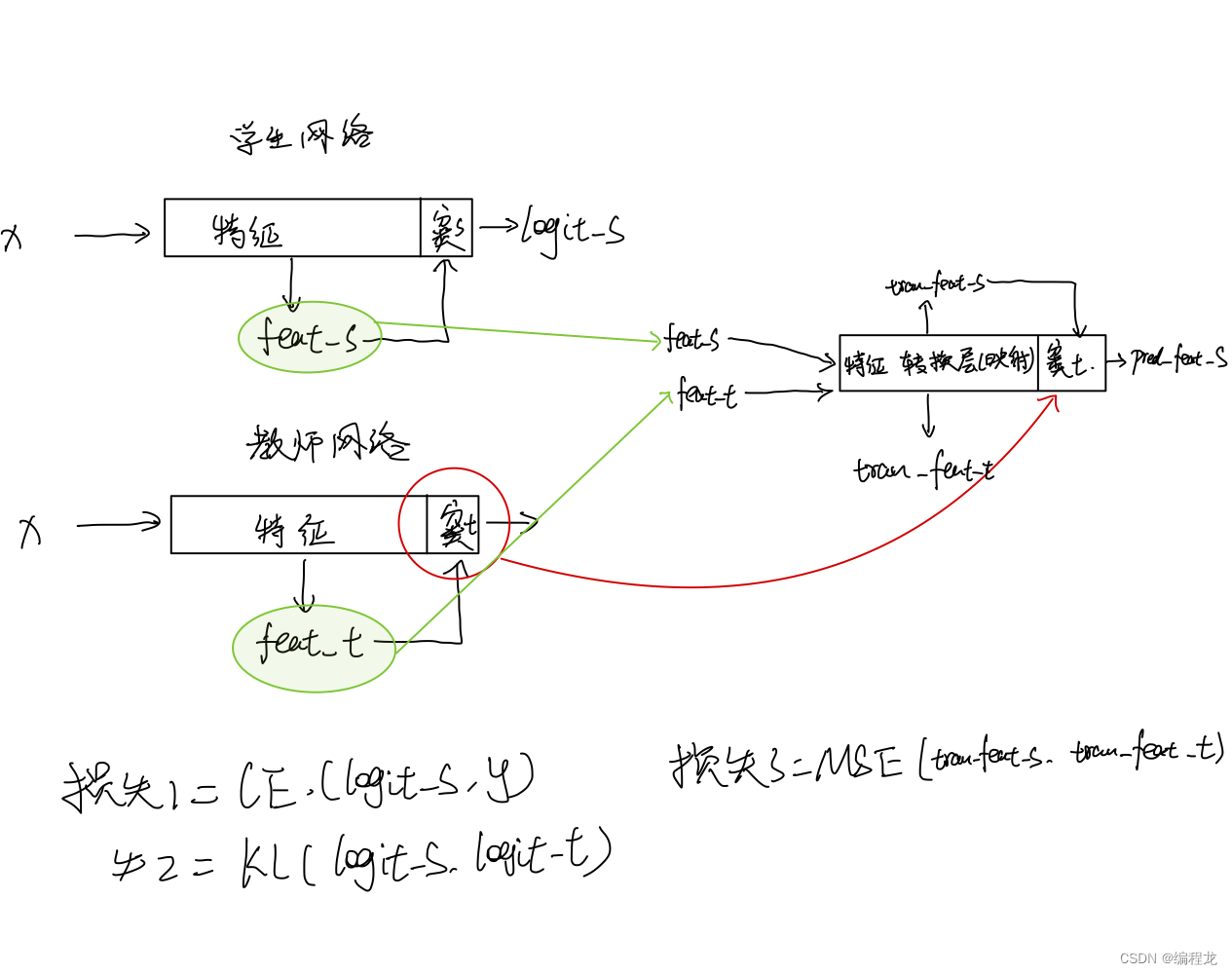
这里我给大家画了个示意图,还是挺清晰的,大家可以自己看看,值得注意的是,在进行学生网络的预测时我们需要使用到学生网络+特征转换网络一起的输出进行预测(也就是pred_feat_s)。
四. 总结
其实本文很简单,通过重用教师网络的分类器以及对学生网络教师网络之间特征的对齐从而能是的学生能向着更好的方向进行发展。
-
相关阅读:
基于Java电动车上牌管理系统计实现(源码+lw+部署文档+讲解等)
易动纷享--测试实习生视频面试
【真题T1】[NOIP2021] 报数
图像处理之图像质量评价指标MSE(均方误差)
猫影视开源!2022年最新点播直播软件!
【游戏客户端】制作节奏大师Like音游(下)
Scala 练习一 将Mysql表数据导入HBase
散文:父亲的家国
C语言,求两个数的二进制表达中,有多少个位数不同
3.2 Android eBPF程序类型
- 原文地址:https://blog.csdn.net/qq_45478482/article/details/127561593
