-
ZYNQ之路--HLS入门实例
上一节我们介绍了如何建立一个HLS工程以及HLS的工程结构,这一节我们着眼于HLS的优化部分,通过Xilinx官方提供的小示例来宏观了解HLS的优化操作。
建立新的Solution(解决方案)
我们知道,HLS一个工程只能有一个TopFunction,但是却可以有多种硬件实现方式(Solution),为了和不做任何优化的工程进行对比,我们首先新建一个Solution。

我们可以选择是否复制某个Solution的约束。

点击确认后,新的Solution就创建好了。
Step 1 :I/O接口优化
正如咱们写Verilog代码需要先声明module的各个接口一样,因为设计规范包括I/O协议,所以执行的第一个优化是创建正确的I/O协议和端口,这一步越早越好。
我们可以查看综合报告的内容来查看我们模块的端口:

我们的要求是:
- 端口C必须是一个单口RAM
- 端口X必须是一个带有有效信号的输入端口
- 端口Y必须一样一个带有有效信号的输出端口
我们可以从综合报告中看到,端口C已经是一个单端口的RAM。但是,如果不指定RAM访问类型,那么High-Level Synthesis可能使用双端口RAM接口。原因是这样做可能可以创建具有更高吞吐量的设计。如果我们需要一个单端口的RAM,则应该主动地在设计中添加使用单端口RAM的I/O协议指示。- 确保Solution2处于激活状态
- 在右边栏的Directive中找到变量C,右击选择Insert Directive
- Directive的类型选择RESOURCE
- 找到RAM_1PBRAM,点击OK

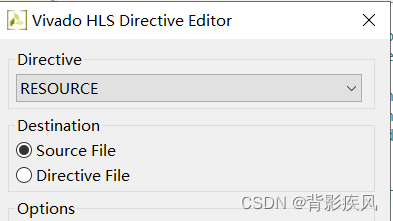

在第二步当中,Destination选项可以选择这条优化的指令是写入C文件还是单独的优化指示文件中。因为I/O协议不太可能更改,所以我们可以将这些优化指令作为pragmas添加到源代码中,以确保在设计中嵌入了正确的I/O协议。
我们可以看到,源文件中出现了下面这个指示:
#pragma HLS RESOURCE variable=c core=RAM_1P_BRAM
本着记录积累的原则,我们现在笔记下我们第一个约束类型:RESOURCE(资源)
RESOURCE指令用于指定特定的库资源(核心),用于实现变量(数组、算术)操作或函数参数)。例如,要指定库中的哪个内存元素用于实现数组,可以使用资源编译指示。
我们在本例子中,指定了变量C实现所使用的RAM类型。因为数组c在函数参数列表中,所以在函数外部,因此我们创建一个数据端口来访问函数外部的单端口块RAM的RTL实现。
同样的步骤,大家可以尝试将X的接口变成带有valid信号的输入端口(Derivative类型为Interface,选择ap_vld)
#pragma HLS RESOURCE variable=c core=RAM_1P_BRAM
(修改后的接口报告)
Step 2 :理解代码(通过 Analysis perspective 窗口)
正所谓“粮草未动,兵马先行”,我们优化未开始,先进行一波分析理解代码是很有必要的!
在之前的文章中展示了如何查看综合报告,然而,Analysis窗口以交互的方式提供更详细的信息,通过这个窗口我们能更加深入地理解算法的实现,这对我们后期的优化十分重要。
如果说优化是在解一个问题,那么分析就是在仔细阅读我们的题干。
我们点开分析视图:

展现在我们面前的窗口如下图所示:

我们首先要理解一下,Analysis Perspective的核心理念:资源 与 调度
我个人理解,其实实现一个功能无非就是干两件事:把数据取出来,然后处理一下,再存回去。
因此流程窗口分为了两个:任务调度的视角 与 资源使用的视角;通过左下角的选项卡进行切换。
那流程窗口是怎么看的呢?
左边是具体的任务,右边看则类似一个状态机,一共有六个状态。我们可以清晰地看到我们的循环是怎么样被组织的,点击任务条,可以跳转到相应的代码,这使得我们可以更好地理解代码的执行过程。
下图是用资源的视角来分析代码的执行流程:

Step 3 :代码优化
代码优化其实就是用资源换速度,在本例中,核心的计算是一个for循环,因此主要影响设计吞吐量的两个因素分别是:
- for循环。默认情况下for语句是循环往复执行的,循环体的核心语句被综合成一个模块,并在每次迭代中重用。这确保了循环的每次迭代都是按顺序执行的。所以我们可以展开for循环让所有操作并行执行。
- BRAM。因为变量shift_reg在C源代码中是一个数组,它在默认情况下被实现为BRAM。然而,它的实际功能是一个移位寄存器。因此,我们可以将这个BRAM分割为单独的寄存器,以提升吞吐量。
这两段话是根据UG871进行翻译的,我个人的理解其实很简单:
首先是for循环的问题,for循环总是执行完一次之后,再执行第二次。如果我要把某个数组的数据都加1或者干其它什么事情,其实我可以把for循环拆开来,第二个元素+1和第一个元素+1同时进行,这就是所谓for循环的并行,使用Unroll命令执行:
其次是BRAM的问题,其实也很好理解,本例中有个关键的代码如下:

shift_reg[i]的值等于shift_reg[i-1],并且还需要把shift_reg[i]的值赋给data,这里由于默认综合的shift_reg只有一个BRAM存储,因此首先需要读取 shift_reg[i-1],然后再写入shift_reg[i],然后再读取shift_reg[i],再赋值给data;如果我们把shift_reg分割成两个数组,例如一个存储1,3,5的数据,一个存储2,4,6的数据,那么我们就可以同时对shift_reg[i]和shift_reg[i-1]进行操作,使用array_partition 命令执行。
这两个命令的详细内容我想写一期新的博客进行记录。
Step 5 :比较和总结
按照如下步骤进行操作:

我们可以清晰地看到各个不同的解决方案之间的比较:

本节到此结束。
-
相关阅读:
分享一下微信投票小游戏怎么做
Vue2与Vue3:深度剖析核心差异与升级亮点
微信小程序之首页-后台交互及WXS的使用
《微服务实战》 第二十章 Redis连接指令 客户端指令 服务器指令
E : DS堆栈--逆序输出(STL栈使用)
淘宝API接口,获取数据
无穿戴人体动捕方案全新上线,创新赋能多领域应用
Linux基础知识与实操-篇二:初识Linux目录管理与操作
解决Qt VS Tools扩展加载预编译Qt库 提示版本不匹配
R语言根据名称排除数据框中的列:使用列名从data.frame中排除指定的数据列
- 原文地址:https://blog.csdn.net/weixin_54358182/article/details/127273805