-
redis和mysql缓存一致性
一、单点(推荐先更新数据库,在延时删除缓存)
这也有不一致概率的问题,但是很小
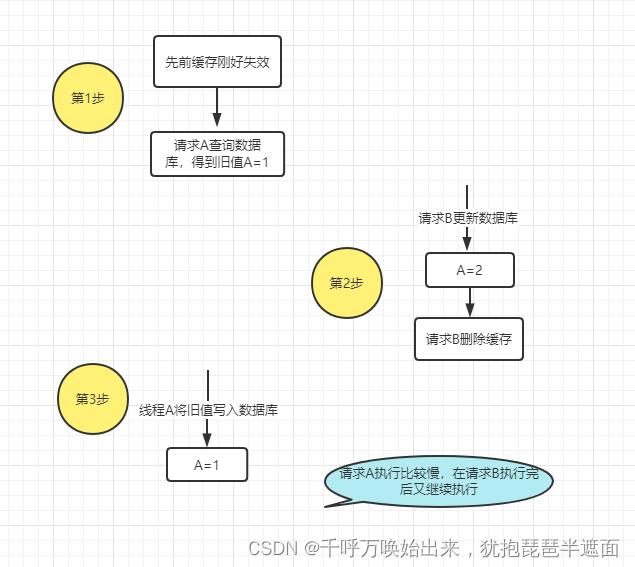
为什么说此方案可行?因为更新请求会给数据库加锁,查询不会,查询请求比更新请求快,很少出现上图情况
大概率流程是下面
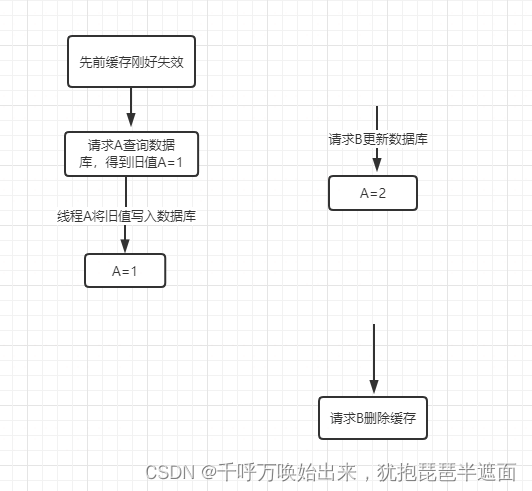
更高保证:请求B更新数据库后,线程B sleep几百毫秒,等请求A将旧值写完之后,让线程B醒过来删除缓存1. 不推荐先更新缓存,在更新数据库
更新缓存成功,更新数据库失败,数据库回滚,还得回滚缓存,而且缓存不是简单的数据,还可能经过复杂的计算结果缓存到redis中。数据库回滚,前面的计算白算啦。此外持久化方面,数据库的持久化做的比缓存好些,而且存储以数据库为中心,先更新数据库,在怎样怎样…
2.不推荐先更新数据库,在更新缓存
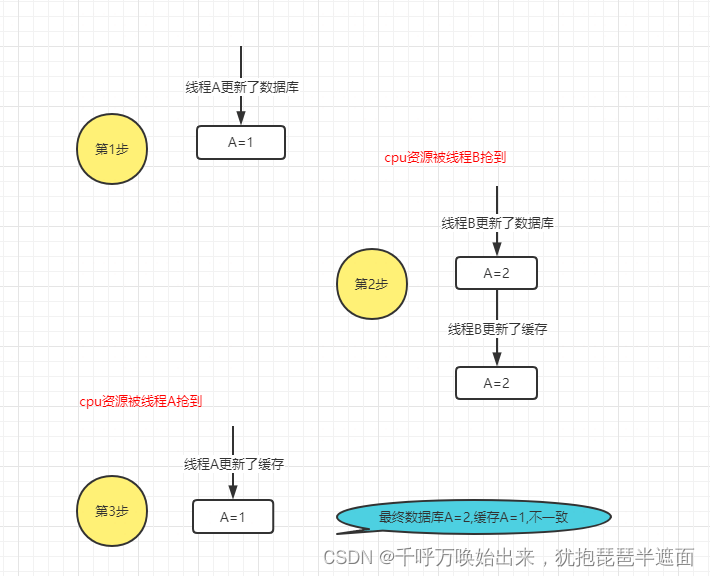
3.不推荐先删除缓存,在更新数据库
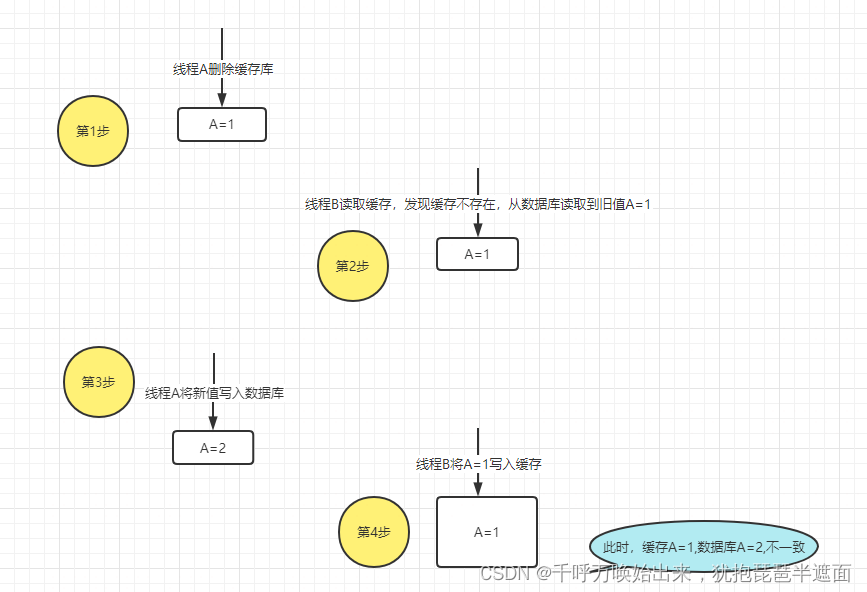
二、读写分离(主从架构模式)
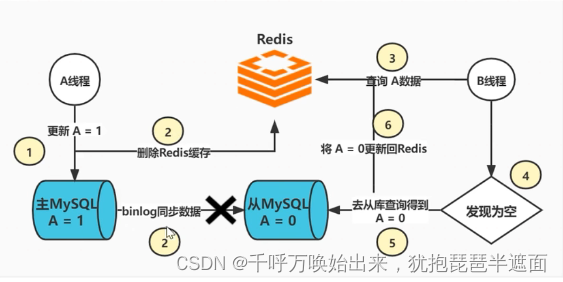
如果对数据一致性要求很高,此时线程B读取数据的时候,不去从库查,一直去主库查,因为主库始终是最新数据
改进后的流程
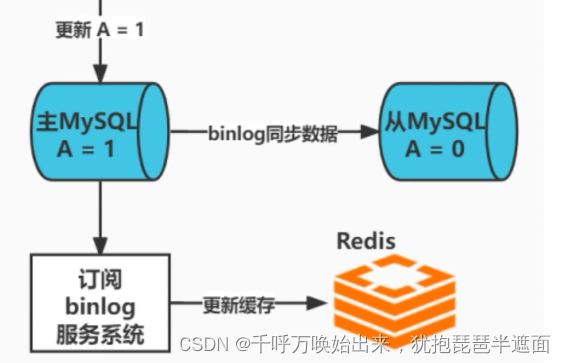
如果网络拥堵或网络中断,更新redis缓存失败如果处理
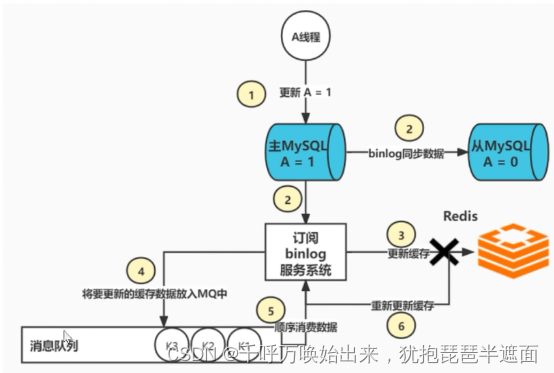
消息队列有持久化机制,保证数据不会丢,顺序不会乱,消费消息队列不成功,还可以重复消费,可以做到系统的高可用,订阅binlog日志顺序性,采用单线程去订阅 -
相关阅读:
react路由介绍、路由的基本使用
大麦网回流票监控,sing参数分析
@AutoConfigurationPackage的使用
400电话怎么办理(申请开通)
Win10电脑经常发出叮咚声音怎么关闭
uniapp中 background-image 设置背景图片不展示问题
Chaes恶意软件的新Python变种以银行和物流业为目标
1035 Password
整数——算法专项刷题(一)
Selenium自动化测试实战之自动化测试基础
- 原文地址:https://blog.csdn.net/zhanlijuan2015/article/details/127537899