-
DC优化(Optimization)是在做什么?
目录
DC在综合的时候有三步,翻译优化与映射,本文总结优化是在做什么。首先优化有如下三个阶段,结构优化,逻辑优化,门级优化。三种不同阶段的优化有着明显的层次,下面将对其进一步解释。

架构层次的优化
首先先看一个例子,使用该例子引出几种优化方式。
算数操作的几个思考
代码如下所示
- if (int0)
- y <= busa + basb;
- else
- y <= busc + basd;
对于上述的几行代码,可以有如下的思考:1,“+”符号表示那种类型的电路?2,那种类型的加法器应该被综合?3,最后多少加法器将会出现在最后的电路中?
对上述的几个问题,将会有如下的几个方式:DW(DesignWare)的实现的选择,共享公共子表达式,资源共享,运算符重新排序
DesignWare的实现选择
对于DesignWare的实现选择,需要对面积,速度进行权衡来选择一个最佳的实现方式,如下图所示。当然,更快的速度意味着更大的面积~

共享公共子表达式
对于下图所示的算式,DC会进行优化
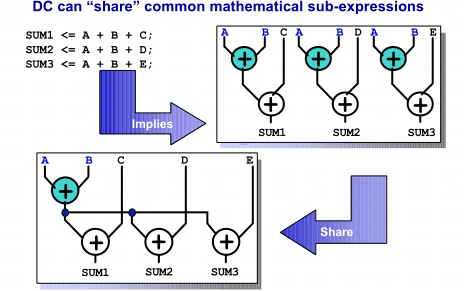
但是HDL的编码方式将会强制性的使得电路综合成特定的拓扑。如下图所示,提前计算出A+B的结果,然后将其作为被加数。

资源共享
资源共享的案例如下所示,提供的代码有两种可能的电路形式。

如下资源可以被共享:*,+,>,>=,<,<=
运算符重新排序
可以设计编译器可以自动重新排序算术运算符,以产生最快的设计

若是输入数据同时到来,将会综合成黄色所示的电路,若是A信号到来时间比较晚一些,则会综合成下面淡紫色所示的电路,同时,和前面一样的是,编码风格也是可以强制指定一个特殊的电路的。
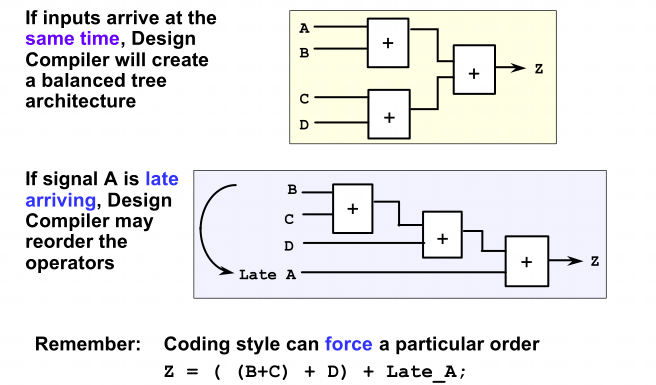
这一部分主要的优化是基于设计的编码风格与设计约束。这一阶段是在未进行映射时候的。
逻辑级优化
经过高层优化后,电路功能由GTECH部件表示,在此阶段进行1,结构化(Structuring)2,扁平化(Flattening)的优化

其中结构化是DC默认的优化策略,主要是面积与速度的选择。可以看到扁平化需要对于面积不敏感~一般的没有特殊要求的设计选择结构化优化即可
门级优化
组合逻辑
使用目标库中的门来生成满足时序和面积目标的设计的过程,一般fab厂商提供的器件种类越多,优化的程度就越大。对于时序逻辑同样如此,将相同功能的逻辑替换成库里提供的性能更优秀的器件。如下图所示

时序逻辑
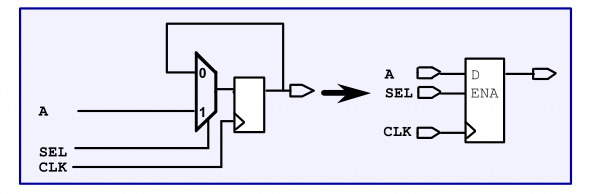
同时DC会自行根据设计,修复设计规则冲突(DRC),通过插入buffer以及调整size的大小以满足供应商提供的设计规则。例如最大的电容(max_capacitance)等
-
相关阅读:
除静电离子风刀的工作原理及应用
CSS3与HTML5
bash上下键选择选项demo脚本
“今天星期五“-SAP SE09/STMS 请求号传输中遇到的错误及解决方案
U盘、FTP等传统文件摆渡方式的7大弊端 你入坑了吗?
java 实现访问者模式
Hi3798MV200 恩兔N2 NS-1 (一): 设备介绍和刷机说明
Innodb底层原理与Mysql日志机制深入剖析
TensorFlow2从磁盘读取图片数据集的示例(tf.keras.utils.image_dataset_from_directory)
Selenium——利用input标签上传文件
- 原文地址:https://blog.csdn.net/qq_41467882/article/details/127552278