-
RabbitMQ-简述
参考
MQ相关概念
什么是MQ
Message Queue;本质就是一个队列;存放的是一种具有跨进程通信机制的消息;
为什么要用MQ
流量消峰
通过消息队列来缓冲瞬时流量,把同步的直接调用转换成异步的间接推送,中间通过一个队列在一端承接瞬时的流量洪峰,在另一端平滑地将消息推送出去。
MQ相当于一个水坝拦截洪水。应用解耦
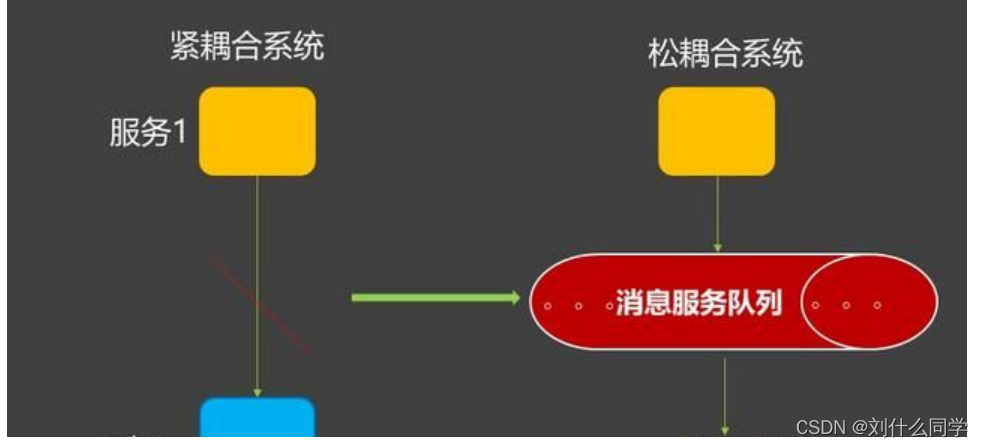
在紧耦合系统中,如果任何一个子系统出现故障,都会造成整个系统的操作异常;而通过消息队列后,则能够相应减少问题的出现,提升系统的可用性。
异步处理
通过消息队列能够让系统按照不同步的程序处理问题,通过多线程达到提高设备利用率的效果。
MQ分类及选择
ActiveMQ
优点:单机吞吐量万级、时效ms级,可用性高,基于主从架构,可靠性较低的概率丢失数据;
缺点:官方对于ActiveMQ的维护越来越少,高吞吐量场景较少使用。Kafka
优点:吞吐量高,时效ms级,分布式,少数机器宕机,不会丢失数据;
缺点:单机超过64个队列/分区的时候,Load会飙升;消息失败不支持重试;社区更新缓慢。RocketMQ
优点:单机吞吐量十万级,可用高;分布式架构,消息0丢失,支持10亿级的消息堆积,源码开源,可以定制自己需要的MQ;
缺点:支持语言少,目前仅仅支持Java,C++不太成熟;社区活跃一般,没有在MQ核心中实现JMS接口等;RabbitMQ
优点:erlang语言的高并发性性能好,吞吐量万级;MQ功能比较完善、健全、跨平台;支持多语言,社区活跃高,更新频率快;
缺点:商业版需要收费、学习成本较高;RabbitMQ
概念
RabbitMQ就是一个消息代理中间件。接收存储并转发消息。
四大核心概念
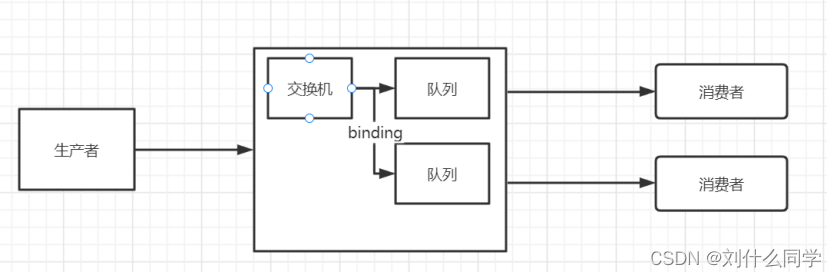
生产者
产生数据发送消息的程序是生产者
消费者
消费与接收具有相似的含义。消费者大多时候是一个等待接收消息的程序。
交换机
交换机是 RabbitMQ 非常重要的一个部件,一方面它接收来自生产者的消息,另一方面它将消息推送到队列中。接收到的消息由交换机决定是推送到特定队列还是多个队列,还是丢弃消息。
队列
队列是 RabbitMQ 内部使用的一种数据结构,尽管消息流经 RabbitMQ 和应用程序,但它们只能存储在队列中。
六大模式
简单模式、工作模式、发布订阅模式、路由模式、主题模式、发布确认模式。

工作原理

名词解释
Connection
publisher/consumer 和 broker 之间的 TCP 连接。
Broker
接收和分发消息的应用,RabbitMQ Server 就是 Message Broker。
Channel
如果每一次访问 RabbitMQ 都建立一个 Connection,在消息量大的时候建立 TCP,Connection 的开销将是巨大的,效率也较低。Channel 是在 connection 内部建立的逻辑连接。
Vitual Host
出于多租户和安全因素设计,类似虚拟机。
Exchange
message到达broker 的第一站,根据分发规则,匹配查询表中的routing key,分发消息到 queue 中去。
Binding
exchange和queue之间的虚拟连接,binding中可以包含routing key,Binding信息被保存到exchange 中的查询表中,用于message的分发依据。
Queue
消息最终被送到这里等待consumer取走。
-
相关阅读:
使用EMD分解进行去噪
A. Knapsack
探索Redis速度之谜
(其他) 剑指 Offer 65. 不用加减乘除做加法 ——【Leetcode每日一题】
认识车载神器-Android Auto
既要又要的正则匹配规则
【Python-Spark(大规模数据)】
springboot集成excel导入导出
shell_38.Linux读取脚本名
一零二零、C语言白菜入门--流程控制
- 原文地址:https://blog.csdn.net/weixin_43217271/article/details/127499859