-
redis之分片集群
写在前面
当redis单实例存储的数据过多时,比如说20G,就会出现因为生成RDB快照较长时间比如500ms阻塞主线程的问题,在这一段时间里,因为主线程被阻塞,所以Redis实例无法正常的对外提供服务,出现这个问题的原因是,需要生成RDB的快照过大,这个时候我们就需要分片,如果是在redis3.0之前我们想要采用这种方案的话,必须使用应用程序实现,但是在redis3.0提供了redis cluster的工具,用来实现基于数据分片方式的集群,本文我们要学习的也正是通过这种方式来实现的,下面我们就开始吧!1:实战
1.1:部署6个Redis实例
先编译安装 ,我本地是在一台机器上部署了6个实例,分别在6个文件夹下,各自配置文件不同,结构如下:
[root@localhost redis-cluster]# ll | grep redis0 drwxr-xr-x. 2 root root 250 Oct 20 16:22 redis01 drwxr-xr-x. 2 root root 253 Oct 20 16:22 redis02 drwxr-xr-x. 2 root root 253 Oct 20 16:22 redis03 drwxr-xr-x. 2 root root 250 Oct 20 16:22 redis04 drwxr-xr-x. 2 root root 250 Oct 20 16:22 redis05 drwxr-xr-x. 2 root root 250 Oct 20 16:22 redis06- 1
- 2
- 3
- 4
- 5
- 6
- 7
各自配置文件如下:
[root@localhost redis-cluster]# cat redis01/redis.conf daemonize yes port 7001 cluster-enabled yes cluster-config-file nodes_1.conf cluster-node-timeout 15000 appendonly yes [root@localhost redis-cluster]# cat redis02/redis.conf daemonize yes port 7002 cluster-enabled yes cluster-config-file nodes_7002.conf cluster-node-timeout 15000 appendonly yes [root@localhost redis-cluster]# cat redis03/redis.conf daemonize yes port 7003 cluster-enabled yes cluster-config-file nodes_7003.conf cluster-node-timeout 15000 appendonly yes [root@localhost redis-cluster]# cat redis04/redis.conf daemonize yes port 7004 cluster-enabled yes cluster-config-file nodes_4.conf cluster-node-timeout 15000 appendonly yes [root@localhost redis-cluster]# cat redis05/redis.conf daemonize yes port 7005 cluster-enabled yes cluster-config-file nodes_5.conf cluster-node-timeout 15000 appendonly yes [root@localhost redis-cluster]# cat redis06/redis.conf daemonize yes port 7006 cluster-enabled yes cluster-config-file nodes_6.conf cluster-node-timeout 15000 appendonly yes- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
注意其中的
port和cluster-config-file不一样,注意其中cluster-config-file配置的文件创建出来即可,不需要填写任何内容(后续会存储分配的哈希槽等信息)。1.2:准备redis-trib工具
复制redis解压文件src下的redis-trib.rb文件到集群目录
(我这里是/root/study/redis-cluster),然后我们需要安装ruby环境,如下:[root@localhost redis-cluster]# yum install ruby [root@localhost redis-cluster]# yum install rubygems- 1
- 2
接着安装redis-trib.rb运行依赖的ruby的包redis-3.2.2.gem,这里 下载,如下:
[root@localhost redis-cluster]# gem install redis-3.2.2.gem- 1
1.3:准备redis实例启动脚本
因为我们这里有6个Redis实例,一个一个启动比较麻烦,所以使用一个脚本来启动,这里如下:
start-all.sh #! /bin/bash cd redis01 ./redis-server redis.conf cd .. cd redis02 ./redis-server redis.conf cd .. cd redis03 ./redis-server redis.conf cd .. cd redis04 ./redis-server redis.conf cd .. cd redis05 ./redis-server redis.conf cd .. cd redis06 ./redis-server redis.conf cd ..- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
可根据实际情况进行调整。接下来使用其来启动redis实例:
[root@localhost redis-cluster]# ./start-all.sh [root@localhost redis-cluster]# ps -ef | grep redis-server root 12560 1 0 16:21 ? 00:00:05 ./redis-server *:7001 [cluster] root 12562 1 0 16:21 ? 00:00:05 ./redis-server *:7002 [cluster] root 12566 1 0 16:21 ? 00:00:05 ./redis-server *:7003 [cluster] root 12570 1 0 16:21 ? 00:00:05 ./redis-server *:7004 [cluster] root 12574 1 0 16:21 ? 00:00:05 ./redis-server *:7005 [cluster] root 12578 1 0 16:21 ? 00:00:05 ./redis-server *:7006 [cluster]- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
这样我们的各个redis实例就启动成功了,接下来就可以使用redis-trib工具来创建分片集群了。
1.4:使用redis-trib.rb创建集群
./redis-trib.rb create --replicas 1 127.0.0.1:7001 127.0.0.1:7002 127.0.0.1:7003 127.0.0.1:7004 127.0.0.1:7005 127.0.0.1:7006- 1
--replicas 1意思是每个分片实例都有一个从节点,这里我们是6个,所以是,3个master,每个 master 1 个slave,如下运行信息:[root@localhost redis-cluster]# ./redis-trib.rb create --replicas 1 127.0.0.1:7001 127.0.0.1:7002 127.0.0.1:7003 127.0.0.1:7004 127.0.0.1:7005 127.0.0.1:7006 >>> Creating cluster >>> Performing hash slots allocation on 6 nodes... Using 3 masters: 127.0.0.1:7001 127.0.0.1:7002 127.0.0.1:7003 Adding replica 127.0.0.1:7004 to 127.0.0.1:7001 Adding replica 127.0.0.1:7005 to 127.0.0.1:7002 Adding replica 127.0.0.1:7006 to 127.0.0.1:7003 M: 72bc0b6333861695f8037e06b834e4efb341af40 127.0.0.1:7001 slots:0-5460 (5461 slots) master M: 64303a6eb5c75659f5f82ad774adba6bc1084dca 127.0.0.1:7002 slots:5461-10922 (5462 slots) master M: 0c0157c84d66d9cbafe01324c5da352a5f15ab31 127.0.0.1:7003 slots:10923-16383 (5461 slots) master S: e5d87ee91b8a9cf440122354fd55521cf51c2548 127.0.0.1:7004 replicates 72bc0b6333861695f8037e06b834e4efb341af40 S: 6f541da782a73c3846fb156de98870ced01364d9 127.0.0.1:7005 replicates 64303a6eb5c75659f5f82ad774adba6bc1084dca S: 09703f108c1794653e7f7f3eaa4c4baa2ded0d49 127.0.0.1:7006 replicates 0c0157c84d66d9cbafe01324c5da352a5f15ab31 Can I set the above configuration? (type 'yes' to accept): yes >>> Nodes configuration updated >>> Assign a different config epoch to each node >>> Sending CLUSTER MEET messages to join the cluster Waiting for the cluster to join.... >>> Performing Cluster Check (using node 127.0.0.1:7001) M: 72bc0b6333861695f8037e06b834e4efb341af40 127.0.0.1:7001 slots:0-5460 (5461 slots) master M: 64303a6eb5c75659f5f82ad774adba6bc1084dca 127.0.0.1:7002 slots:5461-10922 (5462 slots) master M: 0c0157c84d66d9cbafe01324c5da352a5f15ab31 127.0.0.1:7003 slots:10923-16383 (5461 slots) master M: e5d87ee91b8a9cf440122354fd55521cf51c2548 127.0.0.1:7004 slots: (0 slots) master replicates 72bc0b6333861695f8037e06b834e4efb341af40 M: 6f541da782a73c3846fb156de98870ced01364d9 127.0.0.1:7005 slots: (0 slots) master replicates 64303a6eb5c75659f5f82ad774adba6bc1084dca M: 09703f108c1794653e7f7f3eaa4c4baa2ded0d49 127.0.0.1:7006 slots: (0 slots) master replicates 0c0157c84d66d9cbafe01324c5da352a5f15ab31 [OK] All nodes agree about slots configuration. >>> Check for open slots... >>> Check slots coverage... [OK] All 16384 slots covered.- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
如果是输出
[OK] All 16384 slots covered.则说明分片集群创建成功了,接下来我们可以看下集群状态: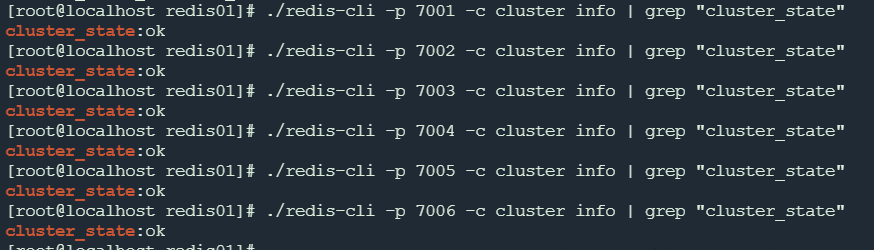
可以看到6个节点都成功加入了分片集群。
1.5:测试数据操作
- 写入数据
[root@localhost redis01]# ./redis-cli -p 7001 -c 127.0.0.1:7001> set key1 value -> Redirected to slot [9189] located at 127.0.0.1:7002 OK 127.0.0.1:7002> set key2 value -> Redirected to slot [4998] located at 127.0.0.1:7001 OK 127.0.0.1:7001> set key3 value OK 127.0.0.1:7001> set key4 value -> Redirected to slot [13120] located at 127.0.0.1:7003 OK- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
可以看到当输出
Redirected to slot...类似的信息时就说明当前写入的数据所属的哈希槽不在当前实例,则内部就会自动重定向到对应哈希槽所在的集群节点,并完成写入,如果是只输出OK则说明当前的写入key对应的哈希槽就在所操作的实例上。- 获取数据
127.0.0.1:7003> get key1 -> Redirected to slot [9189] located at 127.0.0.1:7002 "value" 127.0.0.1:7002> get key2 -> Redirected to slot [4998] located at 127.0.0.1:7001 "value" 127.0.0.1:7001> get key3 "value"- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
同写入。
1.6:测试主节点挂掉的情况
我们先看下当前的集群状态:
[root@localhost redis-cluster]# ./redis-trib.rb check 127.0.0.1:7001 >>> Performing Cluster Check (using node 127.0.0.1:7001) M: 72bc0b6333861695f8037e06b834e4efb341af40 127.0.0.1:7001 slots:0-5460 (5461 slots) master 1 additional replica(s) S: 09703f108c1794653e7f7f3eaa4c4baa2ded0d49 127.0.0.1:7006 slots: (0 slots) slave replicates 0c0157c84d66d9cbafe01324c5da352a5f15ab31 M: 0c0157c84d66d9cbafe01324c5da352a5f15ab31 127.0.0.1:7003 slots:10923-16383 (5461 slots) master 1 additional replica(s) M: 64303a6eb5c75659f5f82ad774adba6bc1084dca 127.0.0.1:7002 slots:5461-10922 (5462 slots) master 1 additional replica(s) S: 6f541da782a73c3846fb156de98870ced01364d9 127.0.0.1:7005 slots: (0 slots) slave replicates 64303a6eb5c75659f5f82ad774adba6bc1084dca S: e5d87ee91b8a9cf440122354fd55521cf51c2548 127.0.0.1:7004 slots: (0 slots) slave replicates 72bc0b6333861695f8037e06b834e4efb341af40 [OK] All nodes agree about slots configuration. >>> Check for open slots... >>> Check slots coverage... [OK] All 16384 slots covered.- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
可以看到此时的master是
127.0.0.1:7001,127.0.0.1:7003,127.0.0.1:7002,此时我们将127.0.0.1:7001停掉:[root@localhost redis-cluster]# ps -ef | grep redis-server | grep 7001 root 12560 1 0 16:21 ? 00:00:06 ./redis-server *:7001 [cluster] [root@localhost redis-cluster]# kill -9 12560- 1
- 2
- 3
此时看下集群状态:
[root@localhost redis-cluster]# ./redis-trib.rb check 127.0.0.1:7002 >>> Performing Cluster Check (using node 127.0.0.1:7002) M: 64303a6eb5c75659f5f82ad774adba6bc1084dca 127.0.0.1:7002 slots:5461-10922 (5462 slots) master 1 additional replica(s) M: e5d87ee91b8a9cf440122354fd55521cf51c2548 127.0.0.1:7004 slots:0-5460 (5461 slots) master 0 additional replica(s) S: 09703f108c1794653e7f7f3eaa4c4baa2ded0d49 127.0.0.1:7006 slots: (0 slots) slave replicates 0c0157c84d66d9cbafe01324c5da352a5f15ab31 S: 6f541da782a73c3846fb156de98870ced01364d9 127.0.0.1:7005 slots: (0 slots) slave replicates 64303a6eb5c75659f5f82ad774adba6bc1084dca M: 0c0157c84d66d9cbafe01324c5da352a5f15ab31 127.0.0.1:7003 slots:10923-16383 (5461 slots) master 1 additional replica(s) [OK] All nodes agree about slots configuration. >>> Check for open slots... >>> Check slots coverage... [OK] All 16384 slots covered.- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
127.0.0.1:7001原来的从节点127.0.0.1:7004已经被提升为主节点了,7001因为停止了,所以已经不在集群中了,当其重新上线后会成为7004的从节点,如下启动7001后查看集群状态:[root@localhost redis-cluster]# cd redis01/ [root@localhost redis01]# ./redis-server redis.conf- 1
- 2
集群状态:

1.7:测试新增节点
如果是新增节点的话就会涉及到哈希槽的重新分配,我们来测试下这种情况如何处理。
1.7.1:部署新节点
- 拷贝一份redis目录redis07
[root@localhost redis-cluster]# pwd /root/study/redis-cluster [root@localhost redis-cluster]# cp -r redis06 redis07 [root@localhost redis-cluster]# ll | grep redis07 drwxr-xr-x. 2 root root 250 Oct 26 14:48 redis07- 1
- 2
- 3
- 4
- 5
- 修改redis.conf
[root@localhost redis-cluster]# cat redis07/redis.conf daemonize yes port 7007 cluster-enabled yes cluster-config-file nodes_7007.conf cluster-node-timeout 15000 appendonly yes- 1
- 2
- 3
- 4
- 5
- 6
- 7
主要修改port和cluster-config-file。
- 启动8007新实例
[root@localhost redis-cluster]# cd redis07/ && ./redis-server redis.conf [root@localhost redis07]# netstat -anp | grep 7007 tcp 0 0 0.0.0.0:7007 0.0.0.0:* LISTEN 1414/./redis-server tcp 0 0 0.0.0.0:17007 0.0.0.0:* LISTEN 1414/./redis-server [root@localhost redis-cluster]# ps -ef | grep 7007 root 1414 1 0 14:53 ? 00:00:00 ./redis-server *:7007 [cluster]- 1
- 2
- 3
- 4
- 5
- 6
此时可以看到信息
:7007 [cluster],这里显示cluster的原因是在redis.conf中配置了cluster-enabled yes,即以Redis cluster模式运行,并不代表已经加到了集群中,如下测试:[root@localhost redis-cluster]# ./redis-trib.rb check 127.0.0.1:7001 | grep 7007 | wc -l 0- 1
- 2
接下来将7007加入到集群中。
1.7.2:7007加入到集群
注意要将db0中的所有信息删除,不然加入集群会提示
[ERR] Node ... is not empty. ... or contains some key in database 0.之类的错误信息。[root@localhost redis-cluster]# ./redis01/redis-cli -p 7007 127.0.0.1:7007> flushdb [root@localhost redis-cluster]# ./redis-trib.rb add-node 127.0.0.1:7007 127.0.0.1:7001 >>> Adding node 127.0.0.1:7007 to cluster 127.0.0.1:7001 >>> Performing Cluster Check (using node 127.0.0.1:7001) S: 72bc0b6333861695f8037e06b834e4efb341af40 127.0.0.1:7001 slots: (0 slots) slave replicates e5d87ee91b8a9cf440122354fd55521cf51c2548 M: e5d87ee91b8a9cf440122354fd55521cf51c2548 127.0.0.1:7004 slots:0-5460 (5461 slots) master 1 additional replica(s) S: 6f541da782a73c3846fb156de98870ced01364d9 127.0.0.1:7005 slots: (0 slots) slave replicates 64303a6eb5c75659f5f82ad774adba6bc1084dca M: 0c0157c84d66d9cbafe01324c5da352a5f15ab31 127.0.0.1:7003 slots:10923-16383 (5461 slots) master 1 additional replica(s) M: 64303a6eb5c75659f5f82ad774adba6bc1084dca 127.0.0.1:7002 slots:5461-10922 (5462 slots) master 1 additional replica(s) S: 09703f108c1794653e7f7f3eaa4c4baa2ded0d49 127.0.0.1:7006 slots: (0 slots) slave replicates 0c0157c84d66d9cbafe01324c5da352a5f15ab31 [OK] All nodes agree about slots configuration. >>> Check for open slots... >>> Check slots coverage... [OK] All 16384 slots covered. >>> Send CLUSTER MEET to node 127.0.0.1:7007 to make it join the cluster. [OK] New node added correctly.- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
当输出信息
[OK] New node added correctly.就是加入集群成功了。此时查看集群状态:[root@localhost redis-cluster]# ./redis-trib.rb check 127.0.0.1:7007 >>> Performing Cluster Check (using node 127.0.0.1:7007) S: a2d36b809a11205a095ce4da3f1b84b42a38f0f2 127.0.0.1:7007 slots: (0 slots) slave replicates 0c0157c84d66d9cbafe01324c5da352a5f15ab31 M: e5d87ee91b8a9cf440122354fd55521cf51c2548 127.0.0.1:7004 slots:0-5460 (5461 slots) master 1 additional replica(s) S: 6f541da782a73c3846fb156de98870ced01364d9 127.0.0.1:7005 slots: (0 slots) slave replicates 64303a6eb5c75659f5f82ad774adba6bc1084dca M: 0c0157c84d66d9cbafe01324c5da352a5f15ab31 127.0.0.1:7003 slots:10923-16383 (5461 slots) master 2 additional replica(s) S: 09703f108c1794653e7f7f3eaa4c4baa2ded0d49 127.0.0.1:7006 slots: (0 slots) slave replicates 0c0157c84d66d9cbafe01324c5da352a5f15ab31 M: 64303a6eb5c75659f5f82ad774adba6bc1084dca 127.0.0.1:7002 slots:5461-10922 (5462 slots) master 1 additional replica(s) S: 72bc0b6333861695f8037e06b834e4efb341af40 127.0.0.1:7001 slots: (0 slots) slave replicates e5d87ee91b8a9cf440122354fd55521cf51c2548 [OK] All nodes agree about slots configuration. >>> Check for open slots... >>> Check slots coverage... [OK] All 16384 slots covered.- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
其中关于7007的信息:
S: a2d36b809a11205a095ce4da3f1b84b42a38f0f2 127.0.0.1:7007 slots: (0 slots) slave replicates 0c0157c84d66d9cbafe01324c5da352a5f15ab31- 1
- 2
- 3
说明其被加入到集群中并分配为slave节点,但不负责处理任何哈希槽数据,接下来看下如何重新分配哈希槽。
1.8:重新分配哈希槽
假定是7003增加了内存,我们想要给7003分配更多的哈希槽,此时可以使用
redis-trib.rb reshard 集群某节点地址(标识集群)来重新分配哈希槽:[root@localhost redis-cluster]# ./redis-trib.rb reshard 127.0.0.1:7003 // 注意这里只是代表了集群,而非确定给7003分配哈希槽 >>> Performing Cluster Check (using node 127.0.0.1:7003) M: 0c0157c84d66d9cbafe01324c5da352a5f15ab31 127.0.0.1:7003 slots:10923-16383 (5461 slots) master 2 additional replica(s) M: e5d87ee91b8a9cf440122354fd55521cf51c2548 127.0.0.1:7004 slots:0-5460 (5461 slots) master 1 additional replica(s) S: 72bc0b6333861695f8037e06b834e4efb341af40 127.0.0.1:7001 slots: (0 slots) slave replicates e5d87ee91b8a9cf440122354fd55521cf51c2548 M: 64303a6eb5c75659f5f82ad774adba6bc1084dca 127.0.0.1:7002 slots:5461-10922 (5462 slots) master 1 additional replica(s) S: 09703f108c1794653e7f7f3eaa4c4baa2ded0d49 127.0.0.1:7006 slots: (0 slots) slave replicates 0c0157c84d66d9cbafe01324c5da352a5f15ab31 S: 6f541da782a73c3846fb156de98870ced01364d9 127.0.0.1:7005 slots: (0 slots) slave replicates 64303a6eb5c75659f5f82ad774adba6bc1084dca S: a2d36b809a11205a095ce4da3f1b84b42a38f0f2 127.0.0.1:7007 slots: (0 slots) slave replicates 0c0157c84d66d9cbafe01324c5da352a5f15ab31 [OK] All nodes agree about slots configuration. >>> Check for open slots... >>> Check slots coverage... [OK] All 16384 slots covered. How many slots do you want to move (from 1 to 16384)?- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
How many slots do you want to move (from 1 to 16384)?这里是询问想要迁移多少个哈希槽,我们为7003在原有哈希槽基础上继续多分配5096个哈希槽,所以输入如下:How many slots do you want to move (from 1 to 16384)? 4096 What is the receiving node ID?- 1
- 2
What is the receiving node ID?是询问接收新哈希槽的实例ID,这里我们是7003,所以输入0c0157c84d66d9cbafe01324c5da352a5f15ab31:How many slots do you want to move (from 1 to 16384)? 5096 What is the receiving node ID? 0c0157c84d66d9cbafe01324c5da352a5f15ab31 Please enter all the source node IDs. Type 'all' to use all the nodes as source nodes for the hash slots. Type 'done' once you entered all the source nodes IDs. Source node #1:- 1
- 2
- 3
- 4
- 5
- 6
询问
Source node #1是从哪里获取这5096个哈希槽,因为我们是重新分配,所以可以输入all代表从集群中的所有节点获取哈希槽,如下:Ready to move 5096 slots. Source nodes: M: e5d87ee91b8a9cf440122354fd55521cf51c2548 127.0.0.1:7004 slots:0-5460 (5461 slots) master 1 additional replica(s) M: 64303a6eb5c75659f5f82ad774adba6bc1084dca 127.0.0.1:7002 slots:5461-10922 (5462 slots) master 1 additional replica(s) Destination node: M: 0c0157c84d66d9cbafe01324c5da352a5f15ab31 127.0.0.1:7003 slots:10923-16383 (5461 slots) master 2 additional replica(s) Resharding plan: Moving slot 5461 from 64303a6eb5c75659f5f82ad774adba6bc1084dca Moving slot 5462 from 64303a6eb5c75659f5f82ad774adba6bc1084dca Moving slot 5463 from 64303a6eb5c75659f5f82ad774adba6bc1084dca ...省略哈希槽移动信息... Do you want to proceed with the proposed reshard plan (yes/no)?- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
最后询问我们是否同意重新分片的方案,输入
yes则开始重新分片,结束后,查看结果:[root@localhost redis-cluster]# ./redis-trib.rb check 127.0.0.1:7001 >>> Performing Cluster Check (using node 127.0.0.1:7001) S: 72bc0b6333861695f8037e06b834e4efb341af40 127.0.0.1:7001 slots: (0 slots) slave replicates e5d87ee91b8a9cf440122354fd55521cf51c2548 S: a2d36b809a11205a095ce4da3f1b84b42a38f0f2 127.0.0.1:7007 slots: (0 slots) slave replicates 0c0157c84d66d9cbafe01324c5da352a5f15ab31 M: e5d87ee91b8a9cf440122354fd55521cf51c2548 127.0.0.1:7004 slots:2547-5460 (2914 slots) master 1 additional replica(s) S: 6f541da782a73c3846fb156de98870ced01364d9 127.0.0.1:7005 slots: (0 slots) slave replicates 64303a6eb5c75659f5f82ad774adba6bc1084dca M: 0c0157c84d66d9cbafe01324c5da352a5f15ab31 127.0.0.1:7003 slots:0-2546,5461-8009,10923-16383 (10557 slots) master 2 additional replica(s) M: 64303a6eb5c75659f5f82ad774adba6bc1084dca 127.0.0.1:7002 slots:8010-10922 (2913 slots) master 1 additional replica(s) S: 09703f108c1794653e7f7f3eaa4c4baa2ded0d49 127.0.0.1:7006 slots: (0 slots) slave replicates 0c0157c84d66d9cbafe01324c5da352a5f15ab31 [OK] All nodes agree about slots configuration. >>> Check for open slots... >>> Check slots coverage... [OK] All 16384 slots covered.- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
其中7003的哈希槽信息是
slots:0-2546,5461-8009,10923-16383 (10557 slots) master,加上之前已经分配的哈希槽,以及新增分配的5096个哈希槽,现在共有10557个哈希槽。1.9:删除节点
我们使用命令
redis-trib.rb del-node {集群任意以实例地址(用来确定集群)} {要删除节点ID},删除节点分为删除master节点和删除slave节点,分别来看下。1.9.1:删除master节点
我们先来看下当前的集群的master节点都有哪些:
[root@localhost redis-cluster]# ./redis-trib.rb check 127.0.0.1:7001 | grep 'M:' M: e5d87ee91b8a9cf440122354fd55521cf51c2548 127.0.0.1:7004 M: 0c0157c84d66d9cbafe01324c5da352a5f15ab31 127.0.0.1:7003 M: 64303a6eb5c75659f5f82ad774adba6bc1084dca 127.0.0.1:7002- 1
- 2
- 3
- 4
我们来测试删除
M: e5d87ee91b8a9cf440122354fd55521cf51c2548 127.0.0.1:7004,如下:[root@localhost redis-cluster]# ./redis-trib.rb del-node 127.0.0.1:7001 e5d87ee91b8a9cf440122354fd55521cf51c2548 >>> Removing node e5d87ee91b8a9cf440122354fd55521cf51c2548 from cluster 127.0.0.1:7001 [ERR] Node 127.0.0.1:7004 is not empty! Reshard data away and try again.- 1
- 2
- 3
提示
[ERR] Node 127.0.0.1:7004 is not empty! Reshard data away and try again.说明,当前该节点还有哈希槽信息,我们需要重哈希移走所有的数据才行,接下来执行操作,将7004(Id:e5d87ee91b8a9cf440122354fd55521cf51c2548)的哈希槽slots:2547-5460 (2914 slots)移动到7003,Id(0c0157c84d66d9cbafe01324c5da352a5f15ab31):[root@localhost redis-cluster]# ./redis-trib.rb reshard 127.0.0.1:7003 >>> Performing Cluster Check (using node 127.0.0.1:7003) ... [OK] All nodes agree about slots configuration. >>> Check for open slots... >>> Check slots coverage... [OK] All 16384 slots covered. How many slots do you want to move (from 1 to 16384)? 2914 # 移动哈希槽的个数 What is the receiving node ID? 0c0157c84d66d9cbafe01324c5da352a5f15ab31 # 接收哈希槽的实例ID Please enter all the source node IDs. Type 'all' to use all the nodes as source nodes for the hash slots. Type 'done' once you entered all the source nodes IDs. Source node #1:e5d87ee91b8a9cf440122354fd55521cf51c2548 # 移除哈希槽的实例ID Source node #2:done # 以上就是所有的移除哈希槽的实例ID ... Moving slot 5458 from e5d87ee91b8a9cf440122354fd55521cf51c2548 Moving slot 5459 from e5d87ee91b8a9cf440122354fd55521cf51c2548 Moving slot 5460 from e5d87ee91b8a9cf440122354fd55521cf51c2548 Do you want to proceed with the proposed reshard plan (yes/no)? yes # 同意移动哈希槽方案 Moving slot 5367 from 127.0.0.1:7004 to 127.0.0.1:7003: ... Moving slot 5369 from 127.0.0.1:7004 to 127.0.0.1:7003:- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
这样,7004的哈希槽就全部移动到7003了,如下:
[root@localhost redis-cluster]# ./redis-trib.rb check 127.0.0.1:7002 >>> Performing Cluster Check (using node 127.0.0.1:7002) ... M: e5d87ee91b8a9cf440122354fd55521cf51c2548 127.0.0.1:7004 slots: (0 slots) master 0 additional replica(s) ... [OK] All nodes agree about slots configuration. >>> Check for open slots... >>> Check slots coverage... [OK] All 16384 slots covered.- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
此时我们就可以删除节点7004了:
[root@localhost redis-cluster]# ./redis-trib.rb del-node 127.0.0.1:7003 e5d87ee91b8a9cf440122354fd55521cf51c2548 >>> Removing node e5d87ee91b8a9cf440122354fd55521cf51c2548 from cluster 127.0.0.1:7003 >>> Sending CLUSTER FORGET messages to the cluster... >>> SHUTDOWN the node. [root@localhost redis-cluster]# ./redis-trib.rb check 127.0.0.1:7003 | grep '7004' | wc -l 0- 1
- 2
- 3
- 4
- 5
- 6
不仅从集群中删除节点,实例也直接停止了:
[root@localhost redis-cluster]# ps -ef | grep redis | grep 7004 | wc -l 0- 1
- 2
1.9.2:删除slave节点
我们先来看下当前的集群的slave节点都有哪些:
[root@localhost redis-cluster]# ./redis-trib.rb check 127.0.0.1:7001 | grep 'S:' S: 72bc0b6333861695f8037e06b834e4efb341af40 127.0.0.1:7001 S: a2d36b809a11205a095ce4da3f1b84b42a38f0f2 127.0.0.1:7007 S: 6f541da782a73c3846fb156de98870ced01364d9 127.0.0.1:7005 S: 09703f108c1794653e7f7f3eaa4c4baa2ded0d49 127.0.0.1:7006- 1
- 2
- 3
- 4
- 5
删除
127.0.0.1:7005,如下:[root@localhost redis-cluster]# ./redis-trib.rb del-node 127.0.0.1:7003 6f541da782a73c3846fb156de98870ced01364d9 >>> Removing node 6f541da782a73c3846fb156de98870ced01364d9 from cluster 127.0.0.1:7003 >>> Sending CLUSTER FORGET messages to the cluster... >>> SHUTDOWN the node.- 1
- 2
- 3
- 4
成功删除,并停止了实例。
2:理论
一般的,使用redis的读写分离主从架构 并配合哨兵 就能满足业务需求了,但是这只是在少量数据的前提下,当redis数据量到达一定程度之后,生成rdb 造成主线程阻塞的时长就会显著增加,此期间,redis集群是无法对外提供服务的,我本地测试,当数据量到达15G时,这个fork生成RDB造成的阻塞时长达到800ms,如下:
[root@localhost redis-cluster]# ./redis01/redis-cli -p 7003 -c info | grep latest latest_fork_usec:812- 1
- 2
这显然是不可接受的,因为在这将近一秒的时间里,会直接影响到用户,出现这种现象根本的原因就是数据量大,我们只需要想办法让数据量变小就行了,那么怎变小呢,将数据分成多份就行了,即采用分片的模式来处理这种问题,单例和分片的架构图对比如下:

但是分片之后也有一些问题需要我们解决,主要如下:
1:如何确定数据应该保存在哪个节点 2:如何知道要保存的数据在哪个节点 3:当新增节点时如何重新划分数据分布,并迁移数据 4:当删除节点时如何迁移被删除节点数据- 1
- 2
- 3
- 4
以上的问题在进行分片之后都需要解决,针对这些问题,redis3.0使用了redis cluster的方案给出了答案,redis cluster定义了0~16383共16384个哈希槽,然后将这些哈希槽分配到集群的节点上,当存储一个key时,通过
crc16(key)%16384,得到的结果就是其对应的哈希槽,哈希槽所分配的节点就是其应该存储的位置,这个关系如下图:
另外客户端程序会维护
slot->node的一个对应关系,这样客户端就可以知道要操作的key是在哪个node,就直接向对应的node发起请求就行了,另外如果是增加节点,删除节点进行reshard导致哈希槽重新分布的话,客户端维护的slot->node的信息就会部分生效,此时如果根据某key获取的node并非最新的node,此时node会返回MOVED {crc16(key)%16384} node地址,然后客户端会向这个新地址重新发起请求(重定向机制),并更新本地的slot->node信息。3:集群规模是越大越好吗?
集群规模并非越大越好,官方建议最大不要超过1000个节点,主要原因就是PING/PONG消息会占用大量的宽带资源,进而直接影响服务器的数据处理性能。1000个节点的PING/PONG消息,包括了自身的状态信息,部分其他实例的状态信息,slot分配信息等,大小大概是在24K左右,每1秒钟就会随机选择十分之一即10台机器来发送PING消息,此时总大小是240K,因为PING/PONG消息的传递是通过gossip 协议的,所以每个实例都会有相同的动作。每秒占用几百k的带宽资源其实还好,毕竟现在带宽一般都是有十几兆,甚至几十兆的,但是还需要考虑另一种情况就是,当PONG消息超时后实例接下来的动作。
因为PONG消息超时
(cluster-node-timeout/2,默认15秒)后,可能意味着目标节点出现问题,甚至是宕机了,如果是真的宕机了,则集群需要迅速发现问题,并对其执行一些动作,如主从切换,来保证集群的高可用性,所以,对于这些节点,实例会以100ms的频率,发送ping消息,如果是此时因为网络波动导致有大量的实例超时的话,则占用宽带的量就会不可预估,发送PING/PONG的频率也会更高。所以在实际应用中我们要控制集群的大小,避免出现PING/PONG消息过多,过大导致网络阻塞,降低服务器性能。
写在后面
参考文章列表:
-
相关阅读:
什么是学习能力?如何提高学习能力?
【附源码】计算机毕业设计JAVA“日进斗金”理财大师系统设计与实现
Java核心篇,二十三种设计模式(十七),行为型——中介者模式
java毕业设计的大学宿舍管理系统mybatis+源码+调试部署+系统+数据库+lw
【系统开发】简易信息管理系统开发
GraphBase基础原理
day10
Java多线程之Thread和Runnable多线程的简单实现(适合小白入门,十分简单)
Java 对象toString()之后转化成json对象
windows2019下安装mysql 8.0.29及解决服务无法启动
- 原文地址:https://blog.csdn.net/wang0907/article/details/127554314
