-
分布式技术材料整理
分布式概念:
分布式系统是指:一个硬件或软件,其组件会分布在不同的计算机上,彼此之间仅仅通过网络消息传递进行通信和协调的系统。简单来说就是一群独立计算机集合起来共同对外提供服务,但是对于系统的用户来说,就像是一台计算机在提供服务一样。
分布式的思维是“拆分“,即不能让一个人承担所有的重任,拆分下,每个人负担一部分,压力均摊。分布式技术的发展历程:
大型网站具备的特点:一是用户多,二是流量大,高并发,三是海量数据,四是安全环境恶劣,易受网络攻击,五是功能多,变更快,频繁发布,六是从小到大,渐进发展。
初代的web服务网站架构往往比较简单,应用程序、数据库、文件等所有的资源都在一台服务器上。

随着业务的扩展,一台服务器已经不能满足性能需求,故将应用程序、数据库、文件各自部署在独立的服务器上,并且根据服务器的用途配置不同的硬件,达到最佳的性能效果。

在硬件优化性能的同时,同时也通过软件进行性能优化,在大部分的网站系统中,都会利用缓存技术改善系统的性能,使用缓存主要源于热点数据的存在,大部分网站访问都遵循28原则(即80%的访问请求,最终落在20%的数据上),所以我们可以对热点数据进行缓存,减少这些数据的访问路径,提高用户体验。

缓存实现常见的方式是本地缓存、分布式缓存。当然还有CDN、反向代理等,这个后面再讲。本地缓存,顾名思义是将数据缓存在应用服务器本地,可以存在内存中,也可以存在文件,OSCache就是常用的本地缓存组件。本地缓存的特点是速度快,但因为本地空间有限所以缓存数据量也有限。分布式缓存的特点是,可以缓存海量的数据,并且扩展非常容易,在门户类网站中常常被使用,速度按理没有本地缓存快,常用的分布式缓存是Memcached、Redis。
后来单套服务难以承担业务请求压力就出现了集群技术,再到后来发展数据库、文件系统服务都采用了分布式策略,如数据库的读写分离、分库分表技术。

随着业务发展到后面会有很多复杂的业务模块,我们发现之前的数据、文件服务、缓存等分布式策略已经满足不了性能需求了。
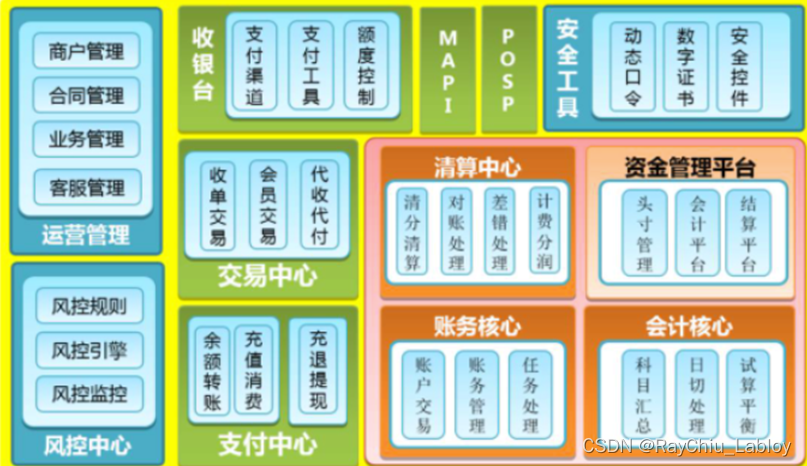
这时候,就需要进行业务拆分了。

分布式技术的特点:
随着移动互联网的快速发展,互联网的用户数量越来越多,产生的数据规模也越来越大,对应用系统提出了更高的要求,我们的系统必须支持高并发访问和海量数据处理。分布式系统技术就是用来解决集中式架构的性能瓶颈问题,来适应快速发展的业务规模,一般来说,分布式系统是建立在网络之上的硬件或者软件系统,彼此之间通过消息等方式进行通信和协调。
分布式系统的核心是可扩展性,通过对服务、存储的扩展,来提高系统的处理能力,通过对多台服务器协同工作,来完成单台服务器无法处理的任务,尤其是高并发或者大数据量的任务。除了对可扩展性的需求,分布式系统还有不出现单点故障、服务或者存储无状态等特点。- 单点故障(Single Point Failure)是指在系统中某个组件一旦失效,这会让整个系统无法工作,而不出现单点故障,单点不影响整体,就是分布式系统的设计目标之一;
- 无状态,是因为无状态的服务才能满足部分机器宕机不影响全部,可以随时进行扩展的需求。
由于分布式系统的特点,在分布式环境中更容易出现问题,比如节点之间通信失败、网络分区故障、多个副本的数据不一致等,为了更好的在分布式系统下进行开发,学者们提出了一系列的理论,其中具有代表性的就是 CAP 理论。
CAP 理论可以表述为,一个分布式系统最多只能同时满足一致性(Consistency)、可用性(Availability)和分区容忍性(Partition Tolerance)这三项中的两项。
 * 一致性是指“所有节点同时看到相同的数据”,即更新操作成功并返回客户端完成后,所有节点在同一时间的数据完全一致,等同于所有节点拥有数据的最新版本。
* 一致性是指“所有节点同时看到相同的数据”,即更新操作成功并返回客户端完成后,所有节点在同一时间的数据完全一致,等同于所有节点拥有数据的最新版本。- 可用性是指“任何时候,读写都是成功的”,即服务一直可用,而且是正常响应时间。我们平时会看到一些 IT 公司的对外宣传,比如系统稳定性已经做到 3 个 9、4 个 9,即 99.9%、99.99%,这里的 N 个 9 就是对可用性的一个描述,叫做 SLA,即服务水平协议。比如我们说月度 99.95% 的 SLA,则意味着每个月服务出现故障的时间只能占总时间的 0.05%,如果这个月是 30 天,那么就是 21.6 分钟。
- 分区容错性具体是指“当部分节点出现消息丢失或者分区故障的时候,分布式系统仍然能够继续运行”,即系统容忍网络出现分区,并且在遇到某节点或网络分区之间网络不可达的情况下,仍然能够对外提供满足一致性和可用性的服务。
在分布式系统中,由于系统的各层拆分,P 是确定的,CAP 的应用模型就是 CP 架构和 AP 架构。分布式系统所关注的,就是在 Partition Tolerance 的前提下,如何实现更好的 A,和更稳定的 C。
在通常的分布式系统中,为了保证数据的高可用,通常会将数据保留多个副本(Replica),网络分区是既成的现实,于是只能在可用性和一致性两者间做出选择。CAP理论关注的是在绝对情况下,在工程上,可用性和一致性并不是完全对立的,我们关注的往往是如何在保持相对一致性的前提下,提高系统的可用性。业务上对一致性的要求会直接反映在系统设计中,典型的就是 CP 和 AP 结构。- CP 架构:对于 CP 来说,放弃可用性,追求一致性和分区容错性。
- AP 架构:对于 AP 来说,放弃强一致性,追求分区容错性和可用性,这是很多分布式系统设计时的选择,后面的 Base 也是根据 AP 来扩展的。
分布式技术的分类:
常见的分布式方案体现在应用架构、数据管理架构、计算架构上,具体为:
(一) 分布式应用和服务
将应用和服务进行分层和分割,然后将应用和服务模块进行分布式部署。这样做不仅可以提高并发访问能力、减少数据库连接和资源消耗,还能使不同应用复用共同的服务,使业务易于扩展。比如:分布式服务框架Dubbo。
(二) 分布式数据存储
将数据分类、分层、分块存储,典型的技术如读写分离、分库分表,另外还包括大数据技术应用分布式存储技术,比如Apache Hadoop HDFS。。
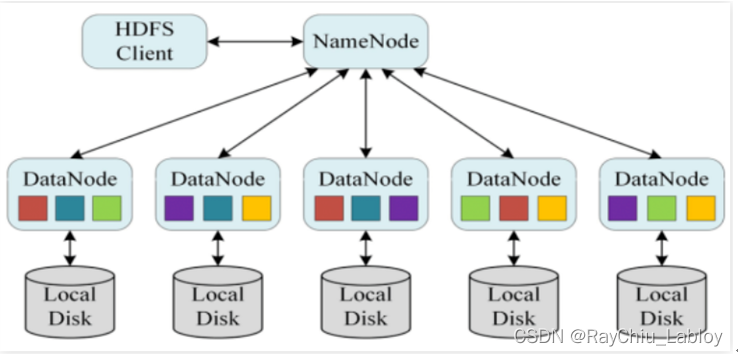
(三) 分布式计算
随着计算技术的发展,有些应用需要非常巨大的计算能力才能完成,如果采用集中式计算,需要耗费相当长的时间来完成。分布式计算将该应用分解成许多小的部分,分配给多台计算机进行处理。这样可以节约整体计算时间,大大提高计算效率。比如Apache Hadoop MapReduce。

引自:
https://blog.csdn.net/zxc_123_789/article/details/106103650
https://mp.weixin.qq.com/s/mdzV8kwqdKB6ypYNQNWDIw
https://mp.weixin.qq.com/s/aFnQp1MKYQOXjqBxHZpJ8w
https://blog.csdn.net/chuixue24/article/details/123483640
https://mp.weixin.qq.com/s/z5Moi6D2btOgeVBw3ZTHCg
https://mp.weixin.qq.com/s/ZFb1hu_IqBrkgGgIDtK-lQ
https://mp.weixin.qq.com/s/G2feps8RdOwQ89hhjm6d9w -
相关阅读:
我要写整个中文互联网界最牛逼的JVM系列教程 | 「类加载子系统」章节:几种类加载器的使用体会
Django--重定向redirect
淘宝API接入说明,Onebound数据
企业网络革命:连接和访问的智慧选项
重写与重载笔记
玩转gRPC—不同编程语言间通信
S波与P波的定义(光波电矢量)(菲涅耳公式)
ACM学习书籍简介
【Maven学习】3.5 实验五:让 Web 工程依赖 Java 工程
Tomcat中间件版本信息泄露
- 原文地址:https://blog.csdn.net/RayChiu757374816/article/details/127555220