-
C++内存管理和模板
目录
内存管理
new T[N]

举一个例子:
- #include
- using namespace std;
- class A
- {
- public:
- A(int a = 0)
- :_a(a)
- {
- cout << "A():" << this << endl;
- }
- ~A()
- {
- cout << "~A():" << this << endl;
- }
- private:
- int _a;
- };
- int main()
- {
- A*p1 = new A;
- A*p2 = new A[10];
- return 0;
- }
我们写一个简单的类A,类A中只有一个成员变量_a和一个构造函数以及一个析构函数,当调用构造函数和析构函数时会出现提示。
接下来,我们进行调试,转到反汇编:
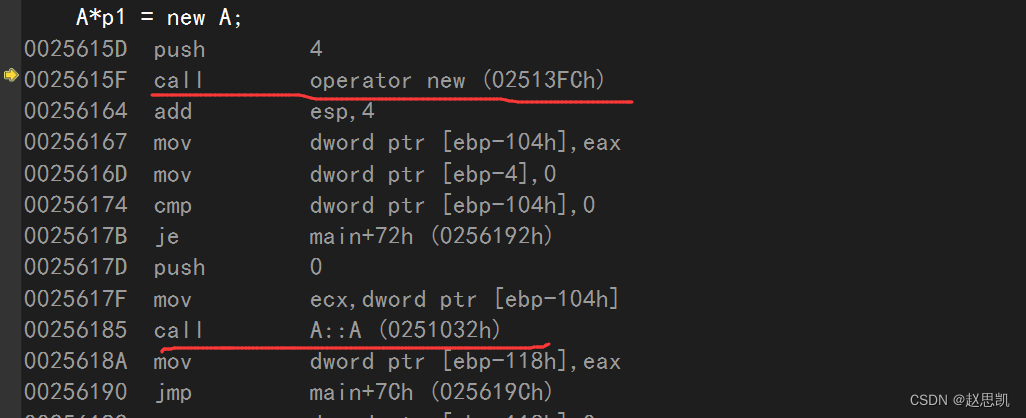
我们用new申请了一个对象的空间,只调用了两个函数:一个是operator new函数,这个函数内部和malloc函数非常相似,不同点在于operator函数申请空间失败的时候会抛异常。
第二个函数是构造函数。
总结:对于自定义类型,new申请空间首先会调用operator new函数,然后调用构造函数。
对于

我们来查看对应的反汇编:
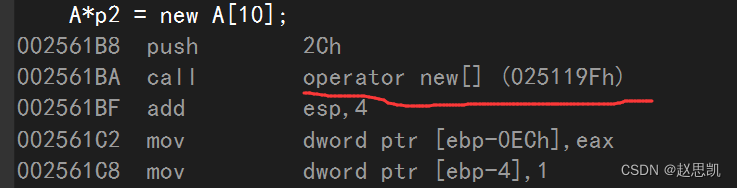
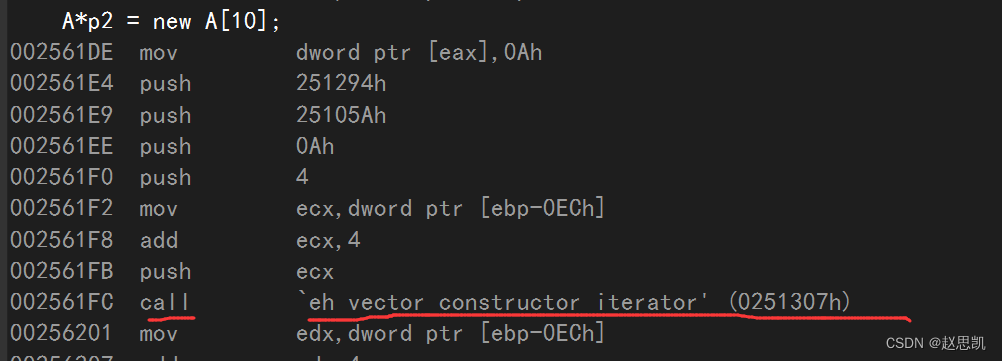
这里同样也是调用了两个函数。
第一个函数operator new[],这个函数又相当于我们调用了10次operator new[]函数,完成申请十个对象。
第二个函数相当于迭代调用构造函数,

这里的vector表示的是顺序表,这里有迭代的意思。
总结:operator new[]:相当于调用了多次operator new函数,并调用了多次构造函数。
new和delete关键字的总结:

定位new表达式(placement-new):
作用:
定位new表达式的作用是在已分配的原始内存空间中调用构造函数初始化一个对象。
使用格式:

使用场景:

实例:
- class A
- {
- public:
- A(int a = 0)
- :_a(a)
- {
- cout << "A():" << this << endl;
- }
- ~A()
- {
- cout << "~A():" << this << endl;
- }
- private:
- int _a;
- };
- int main()
- {
- A*p1 = new A;
- /*A*p2 = new A[10];*/
- A*p3 = (A*)malloc(sizeof(A));
- if (p3 == nullptr)
- {
- perror("malloc fail");
- exit(-1);
- }
- new(p3)A(1);
- return 0;
- }
我们知道,类的构造函数一般不能主动调用,一般是对象在创建的时候自动进行调用,但是这里我们是通过malloc申请的空间,malloc申请空间是不会调用构造函数的。
p3指向我们申请的空间,假如我们想要对动态申请的对象调用构造函数,这里就用到了定位new表达式:
new(p3)A(1);这串代码可以这样翻译:对动态申请的对象p3调用构造函数,初始化的值为1.
我们进行调试,查看是否调用完成构造函数:

调用完成了构造函数。
调用析构函数的两个方法:
方法1:直接使用delete,例如:
delete p3;我们进行编译,假如打印了~A()表示我们调用了析构函数。

方法1是可行的。
方法2:通过p3来调用析构函数。
举一个例子:
- new(p3)A(1);
- p3->~A();
我们可以这样写,进行编译:

成功调用了析构函数。
池化技术:
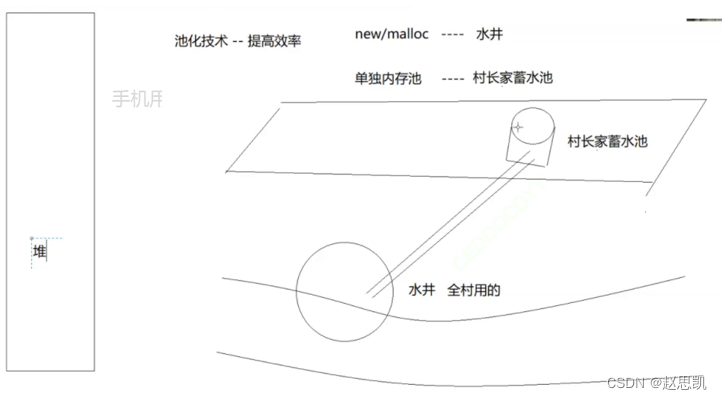
假如我们不断使用malloc和new在堆上申请空间(类比每一次都去水井取水),但是我们想要高效率的申请空间,我们可以准备一个内存池(为了取水方便,我们在家里使用一个蓄水池),当我们想使用堆上的空间,池中的内存就足够我们使用(当我们想要使用水,使用家里蓄水池的水即可),但是内存池的内存没有调用构造函数进行初始化(自家的蓄水池中的水不干净),所以我们就是用定位new的方法来初始化内存(用净水器的方法过滤家里蓄水池中的水)。
总结:定位new表达式的作用就是对已经申请过的没有调用构造函数初始化的动态对象进行初始化。
对于将来要学习的内存池,我们的定位new也能够对内存池哪些没有初始化的内存进行初始化。
面试题:c语言的动态内存申请和c++的有什么不同
1:本身存在不同:
c++的new和delete是操作符,而c语言的malloc和free是函数不同。
2:申请失败的结果不同:
c语言申请失败后返回空指针,c++申请失败后抛异常
3:是否初始化
malloc申请的对象不会被初始化,而new申请的对象可以被初始化。
4:是否需要计算空间的大小
malloc申请时需要我们自己计算所要申请空间的大小,而new申请时,我们只需要输入申请的对象和对象的个数即可。
5:返回值不同:
malloc申请对象的返回值是void*,而new申请对象不需要返回值,因为new后面直接跟的是类的类型。
6:对于自定义类型的处理不同:
对于自定义类型,new申请动态对象(delete释放空间)时,会调用对象的构造函数(对象的析构函数),而malloc则只会申请空间。
内存泄露:

内存泄露是指针丢了还是内存丢了?
答:内存泄露的本质上是指针丢了,失去了指针,我们就找不到那部分没有释放的空间,就造成了内存泄露。
注意:只要程序正常结束了,内存就被回收了,就不存在内存泄露了。
常见的内存泄露的情况:
- void MemoryLeaks()
- {
- //1:内存申请忘记了释放
- int *p1 = (int*)malloc(sizeof(int));
- int*p2 = new int;
- //2:异常安全问题
- int *p3 = new int[10];
- Func();//这里Func()函数抛异常导致delete [] p3未执行,p3未被释放。
- delete[] p3;
- }
模板:
先举例:
- void Swap(int &left, int&right)
- {
- int tmp = left;
- left = right;
- right = tmp;
- }
- int main()
- {
- int a = 1, b = 2;
- Swap(a, b);
- double c = 1.1, d = 2.2;
- Swap(c, d);
- return 0;
- }
如图所示:我们只定义了一个整型的交换函数,对于c语言来说,假如我们想要调用浮点型类型的数据的交换,我们需要额外写一个不同命的函数,例如:
- void Swapd(double &left, double&right)
- {
- double tmp = left;
- left = right;
- right = tmp;
- }
- void Swapi(int &left, int&right)
- {
- int tmp = left;
- left = right;
- right = tmp;
- }
- int main()
- {
- int a = 1, b = 2;
- Swapi(a, b);
- double c = 1.1, d = 2.2;
- Swapd(c, d);
- return 0;
- }
对于c++来说,我们方便了一些,我们可以写函数重载:
- void Swap(double &left, double&right)
- {
- double tmp = left;
- left = right;
- right = tmp;
- }
- void Swap(int &left, int&right)
- {
- int tmp = left;
- left = right;
- right = tmp;
- }
- int main()
- {
- int a = 1, b = 2;
- Swap(a, b);
- double c = 1.1, d = 2.2;
- Swap(c, d);
- return 0;
- }
但是无论是c语言还是c++,我们要实现几种类型数据的交换,我们就需要写几个函数,无论是否重载。
现在我们可以使用模板来让编译器替我们定义函数。
泛型编程:
定义:
写法结构:
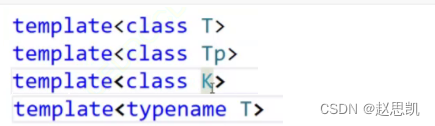
这几种写法都是正确的,相同的。
实例:
- template<typename T>
- void Swap(T &left, T&right)
- {
- T tmp = left;
- left = right;
- right = tmp;
- }
- int main()
- {
- int a = 1, b = 2;
- Swap(a, b);
- double c = 1.1, d = 2.2;
- Swap(c, d);
- return 0;
- }
我们进行调试:
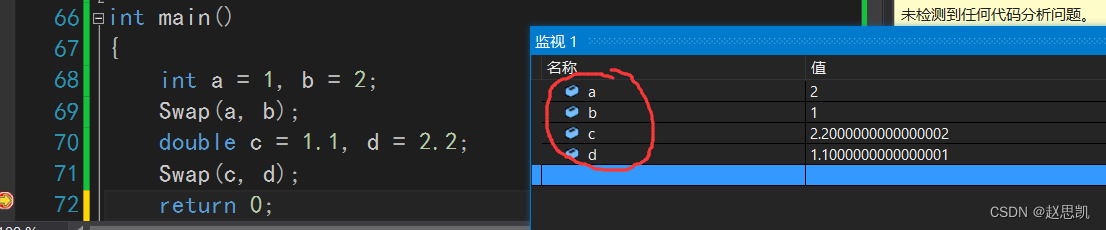
我们可以发现,我们分别完成了整型数据的交换和浮点型数据的交换。
问题1:我们这里写的Swap调用的是下面这个函数吗?

答:并不是,首先,我们的函数开辟的栈帧带线大小就不同,因为对于字符类型的交换函数,一个字符对象只占一个字节,对于整型类型的交换函数来说,一个整型对象占4个字节,所以整型的交换函数天然的就比字符类型的交换函数调用时所开辟的栈帧空间大。
函数调用时开辟的栈帧空间不同,所对应的函数就不同,所以我们肯定不会调用这个函数。
具体的过程是这样的:
上面是我们写的一个模具,假如我们在后面调用了int double类型的交换函数,那编译器就会自定义int double类型的函数来供我们使用。
我们来查看反汇编:
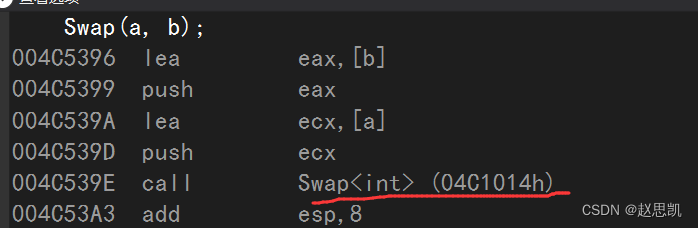
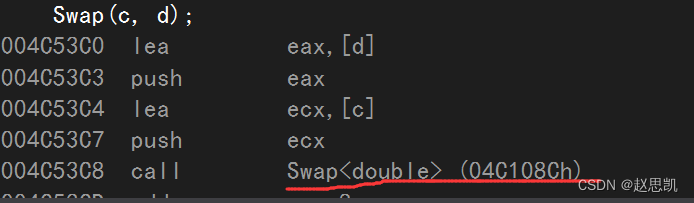
并且我们调用的函数的地址也不相同,所以我们调用的一定不是同一个函数。
函数模板的实例化:
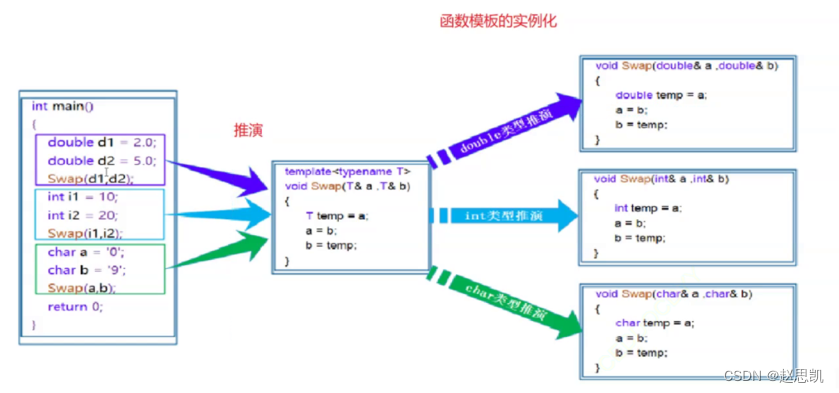
如何实例化对象?
答:根据我们的需求,假如我们调用了int类型的交换函数,我们就实例化int的交换函数。
我们进行证明:
- template<typename T>
- void Swap(T &left, T&right)
- {
- T tmp = left;
- left = right;
- right = tmp;
- }
- int main()
- {
- int a = 1, b = 2;
- Swap(a, b);
- int c=2, d = 1;
- Swap(a, b);
- return 0;
- }
我们转到反汇编:
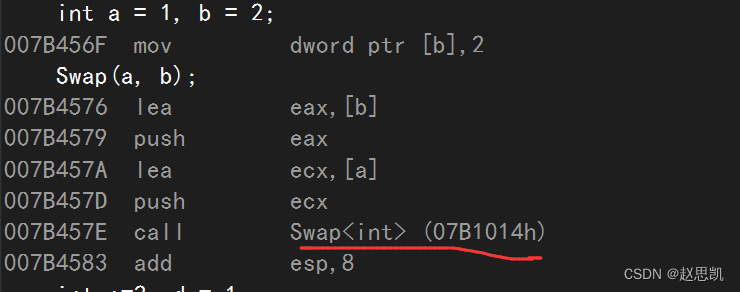
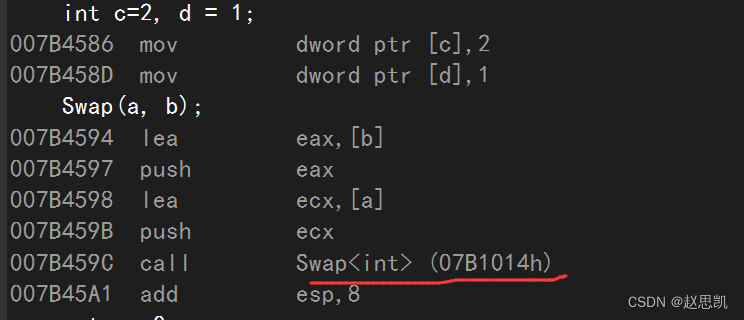
我们调用的函数是相同的。
能不能实现不同类型的数据的交换:
答:我们进行尝试:
- template<typename T>
- void Swap(T &left, T&right)
- {
- T tmp = left;
- left = right;
- right = tmp;
- }
- int main()
- {
- int x = 1, y = 2;
- double c = 1.1, d = 2.2;
- Swap(x, c);
- }
如图所示:
我们的x和c是不同类型的。
我们进行编译:

报错。
原因是什么?
答:因为假如我们传参传了一个整型和浮点型,我们的T类型具体对应的是哪个类型不清楚,所以就会报错。
这里可能发生类型转换吗?
答:不会,只有在传参和赋值的时候才会产生类型转换,我们这里只有类型推断,所以不能发生类型转换。
我们再退出一个问题,以下代码可以调用吗?
- void Swap(double &left, double&right)
- {
- double tmp = left;
- left = right;
- right = tmp;
- }
- int main()
- {
- int a = 1;
- double c = 2.0;
- Swap(a, c);
- }
不可以调用,原因如下:
答:这里是传参没错,传参或赋值的时候会产生类型转换,会产生临时变量,这个临时变量具有常性,所以我们无法用引用接收常数,即使我们用const修饰参数,因为我们的函数是实现交换,所以两个参数值一定发生变化,用const修饰就不能改变了,产生矛盾。
第一种写法:
- template<class T>
- T Add(const T&left, const T&right)
- {
- return left + right;
- }
- int main()
- {
- int a = 1;
- double c = 2.0;
- cout << Add((double)a, c) << endl;
- }
我们可以采用强制类型转换的方法:
我们进行调用:

实现了相加。
这里去掉了const就会报错,原因如下
答:a强制类型转换出来的对象具有常性,引用是无法接收常数的。
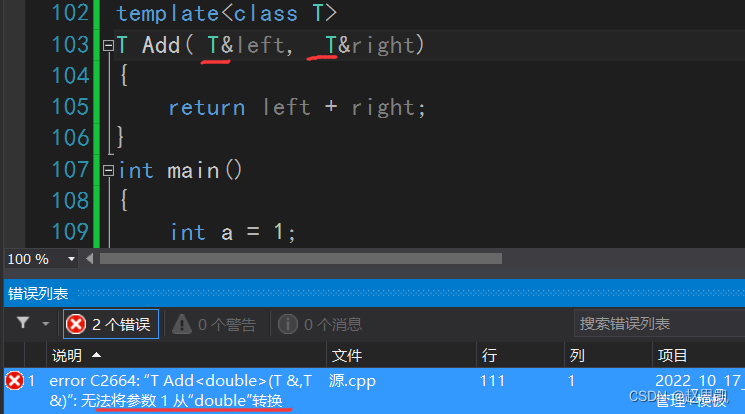
上面的这些都是自动推演实例化。
显示实例化:
例如:
- template<class T>
- T Add(const T&left,const T&right)
- {
- return left + right;
- }
- int main()
- {
- int a = 1;
- double c = 2.0;
- cout << Add<double>(a,c) << endl;
- }
我们在Add后面加上<类型>,这里就相当于隐式类型转化了,相当于把不是double类型的参数隐式雷西那个转换为double。
注意:显示实例化不会经过自动推演,因为我们已经规定了要调用的函数。
模板可以搞多个参数
例如:
- template<class T1,class T2>
- T1 Add(const T1& left, const T2& right)
- {
- return left + right;
- }
- int main()
- {
- int a = 10;
- double b = 20.1;
- cout << Add(a, b) << endl;
- return 0;
- }
因为我们的模板有两个参数,所以我们可以接收两个不同类型的参数的函数的调用:

通用和自定义函数同时出现优先自定义:
例如:
- int Add(int left, int right)
- {
- return left + right;
- }
- template<class T>
- T Add(T left, T right)
- {
- return left + right;
- }
- int main()
- {
- int a = 1, b = 2;
- cout << Add(a, b) << endl;
- }
我们进行调试观察:
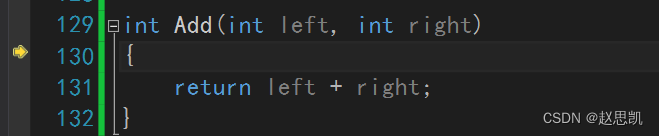
我们发现当通用和自定义同时存在时,调用函数会使用自定义的。
假如我们不想调用自定义的,我们想调用实例化的:
我们可以这样写:
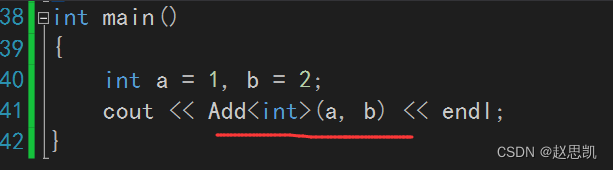
我们这样写之后就会调用实例化了:
实例化栈:
我们先写一个简写的栈:
- class Stack
- {
- public:
- Stack(int capacity = 4)
- {
- cout << "Stack(int capacity = )" <_a = (int*)malloc(sizeof(int)*capacity);if (_a == nullptr){perror("malloc fail");exit(-1);}_top = 0;_capacity = capacity;}// st2(st1)// st1 = st2;// st1 = st1;void Push(int x){// ....// 扩容_a[_top++] = x;}private:int* _a;int _top;int _capacity;};
我们可以发现,我们输入到栈中的元素只会是整型,我们有没有办法输入其他数据类型?
答:我们进行尝试:
typedef int SLDateType;我们先把int替换成为SLDataType,假如我们想要修改数据类型时,我们只需要修改这里的int即可。
假如我们想要输入浮点型数据:
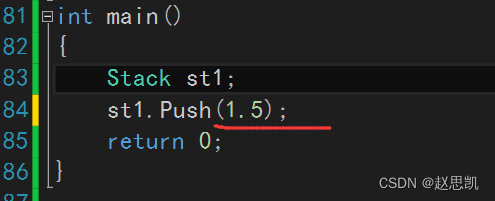
我们进行修改:

我们进行调试:

我们成功输入了浮点型数据。
但是typedef还有一些解决不了的问题:
例如:
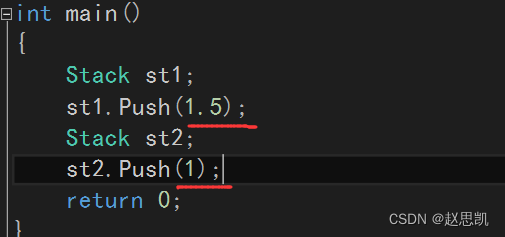
假如我们创建两个栈对象,一个输入浮点型数据,一个输入整形数据,那我们就不能够完成需求。
所以,我们发现,我们这里使用typedef的作用是降低维护成本,而不是泛型。
想解决这个问题,我们有两种思路:
思路1:再创建一个不同名字的栈,对栈的内容进行修改,实现创建两个栈对象。
但是这种方法不够泛型,我们可以写一个更好的。
思路2:模具的方法:
- template<typename T>
- class Stack
- {
- public:
- Stack(int capacity = 4)
- {
- cout << "Stack(int capacity = )" <_a = (T*)malloc(sizeof(T)*capacity);if (_a == nullptr){perror("malloc fail");exit(-1);}_top = 0;_capacity = capacity;}// st2(st1)// st1 = st2;// st1 = st1;void Push(T x){// ....// 扩容_a[_top++] = x;}private:T* _a;int _top;int _capacity;};
但是这里需要注意一个问题:
我们入栈的函数的参数最好用引用:因为对于内置类型,传值传参和传引用没有什么区别,但是对于自定义类型,传值传参就会调用拷贝构造,所以我们这里使用传引用传参。
又因为我们不会对x的值进行修改,所以我们可以在参数类型的上面加上const
我们如何进行初始化呢?
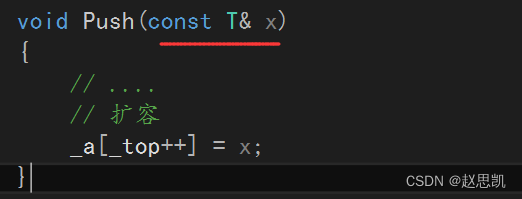
我们知道,函数模板可以推演实例化,因为调用函数就会传递参数,编译器会根据参数的类型来推演对应的实例化,但是对于类模板,我们没有推演的时机。
所以我们可以用显示实例化的方法:
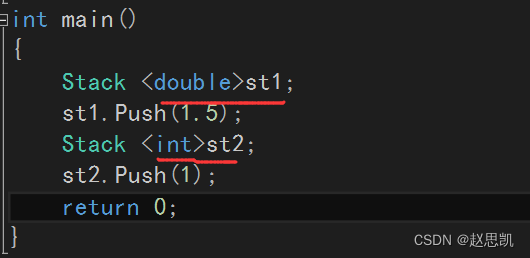
那么,st1和st2对应的类是相同的类吗?
答:不是,这两个类不相同,原因是在这里:

假如我们这里不是指针,而是T _a,实例化的不同就会导致T的不同,T的不同类的大小就不同,大小不同的类是不会相同的。
他们是一个模板实例化出来的
但是模板参数不同,他们就是不同类型。
那允许我们把st2赋给st1吗?
答:不允许,如图:

总结:不仅有函数模板,同样也有类模板,不过类模板不能进行推演实例化,而只能显示实例化。
静态数组:
- #define N 10
- template<class T>
- class Array
- {
- public:
- T& operator[](size_t i)
- {
- return _a[i];
- }
- private:
- T _a[N];
- };
在类Array中,有一个成员变量,该成员变量是一个数组,该成员变量的类型由T来控制,有一个成员函数,该成员函数是符号重载函数,表示把[]进行重载。

这里就表示显示实例化:我们的类型是int类型。
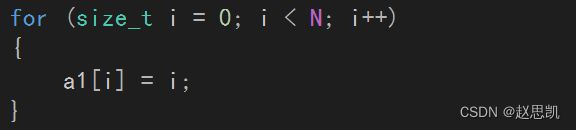
表示对数组进行初始化,a1是Array类型的成员,所以a1[i]就会返回成员变量_a[i]的改变,从而完成初始化。
总结:我们写类的目的是为了通过成员函数或者其他函数完成对类的成员变量进行操作,来获取我们想要的结果
-
相关阅读:
ctf-pikachu-xxe
机器学习----基础理解
说一说 Backscatter communication
实训笔记9.1
论文解读(AutoSSL)《Automated Self-Supervised Learning for Graphs》
深度学习进阶篇-预训练模型[4]:RoBERTa、SpanBERT、KBERT、ALBERT、ELECTRA算法原理模型结构应用场景区别等详解
详解 BAT 面试必问之 ThreadLocal(源码 + 内存)
网络安全(黑客)自学
项目属性:服务类、货物类、工程类项目的区别
MAC 地址简化概念(有线 MAC 地址、无线 MAC 地址、MAC 地址的随机化)
- 原文地址:https://blog.csdn.net/qq_66581313/article/details/127533339
